Potrebbero piacerti anche
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Why EagleBurgmann 29.03.2011Documento15 pagineWhy EagleBurgmann 29.03.2011ybozbasNessuna valutazione finora
- Carestream Imaging Software ManualDocumento2 pagineCarestream Imaging Software ManualTONDERAI0% (1)
- Image Classification Based On Fuzzy Logic: Mapsoft LTD, Zahumska 26 11000 Belgrade, Serbia and MontenegroDocumento6 pagineImage Classification Based On Fuzzy Logic: Mapsoft LTD, Zahumska 26 11000 Belgrade, Serbia and MontenegroDamri BachirNessuna valutazione finora
- Chapter 5 - Analog - TransmissionDocumento6 pagineChapter 5 - Analog - TransmissionMd Saidur Rahman Kohinoor92% (86)
- Session 5. Confidence Interval of The Mean When SD Is Known (18-22)Documento5 pagineSession 5. Confidence Interval of The Mean When SD Is Known (18-22)Roldan Soriano CardonaNessuna valutazione finora
- 3bhs212794 E01 Revn User Manual Acs6000Documento266 pagine3bhs212794 E01 Revn User Manual Acs6000Fernando RamirezNessuna valutazione finora
- Lab Report No 10ADCDocumento4 pagineLab Report No 10ADCIhsan ul HaqNessuna valutazione finora
- GCCM Europe 2016 MagazineDocumento48 pagineGCCM Europe 2016 MagazineVimal OdedraNessuna valutazione finora
- Basic Accounting SyllabusDocumento16 pagineBasic Accounting SyllabusMerdzNessuna valutazione finora
- Quick Help For EDI SEZ IntegrationDocumento2 pagineQuick Help For EDI SEZ IntegrationsrinivasNessuna valutazione finora
- Hanelbrochure11 36Documento26 pagineHanelbrochure11 36Nghĩa Man ĐứcNessuna valutazione finora
- Study of Relay Protection Modeling and SimulationDocumento5 pagineStudy of Relay Protection Modeling and SimulationИван ИвановNessuna valutazione finora
- Exercise 5: 5. QueriesDocumento15 pagineExercise 5: 5. QueriesbirukNessuna valutazione finora
- Using Slic3r With The XYZprinting DaVinci 1.0Documento5 pagineUsing Slic3r With The XYZprinting DaVinci 1.0anonymoose471Nessuna valutazione finora
- How Is The Loyalty Batch EngineDocumento5 pagineHow Is The Loyalty Batch EnginessbnirmaNessuna valutazione finora
- Collatz Conjecture ProofDocumento6 pagineCollatz Conjecture ProofThiago da Silva VieiraNessuna valutazione finora
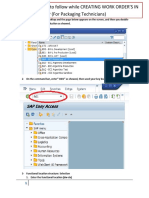
- Creating WO SOP and Teko in SapDocumento10 pagineCreating WO SOP and Teko in SapGeorge AgafinaNessuna valutazione finora
- Lab 1Documento15 pagineLab 1George RybkoNessuna valutazione finora
- Quiz Chapter 2. MASDocumento4 pagineQuiz Chapter 2. MASShiNessuna valutazione finora
- Lc5296-At Lc5248e-At User ManualDocumento44 pagineLc5296-At Lc5248e-At User ManualAtreyo SahaNessuna valutazione finora
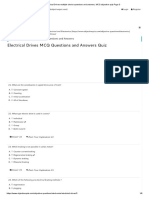
- Electrical Drives Multiple Choice Questions and Answers, MCQ Objective Quiz Page 3 PDFDocumento6 pagineElectrical Drives Multiple Choice Questions and Answers, MCQ Objective Quiz Page 3 PDFsatydeshNessuna valutazione finora
- Migrate MySQL Database To Azure Database For Mysql OnlineDocumento11 pagineMigrate MySQL Database To Azure Database For Mysql Onlinethecoinmaniac hodlNessuna valutazione finora
- Mototrbo Xir P3688 Portable Radio: You'Re Simply More EfficientDocumento4 pagineMototrbo Xir P3688 Portable Radio: You'Re Simply More EfficientIndra GunawanNessuna valutazione finora
- 990k HidraulicDocumento15 pagine990k Hidraulichitler morales gavidiaNessuna valutazione finora
- PG70ABDLDocumento30 paginePG70ABDLAaron PerezNessuna valutazione finora
- RLC Svu01b E4 - 06012006Documento60 pagineRLC Svu01b E4 - 06012006YAIR ANDRES BARON PEÑANessuna valutazione finora
- CMPE 011 Reviewer MidtermsDocumento5 pagineCMPE 011 Reviewer MidtermsJohn Rave Manuel GonzalesNessuna valutazione finora
- Course Syllabus - QMT181 - June - 2016 - Latest PDFDocumento2 pagineCourse Syllabus - QMT181 - June - 2016 - Latest PDFadamNessuna valutazione finora
- Startup Directory PDFDocumento320 pagineStartup Directory PDFbillroberts981Nessuna valutazione finora
- Warehouse Order Creation Process and Its BenefitsDocumento4 pagineWarehouse Order Creation Process and Its Benefitskishore0% (1)