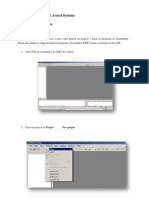
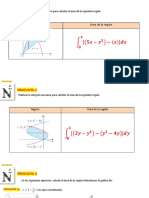
Potrebbero piacerti anche
- Pac Lenguaje de Marcas UF1Documento16 paginePac Lenguaje de Marcas UF1Eneida6736Nessuna valutazione finora
- Garcia - omar.Act.3.Poniendo en Práctica El Pragmatismo Educativo y El Modelo MontessoriDocumento8 pagineGarcia - omar.Act.3.Poniendo en Práctica El Pragmatismo Educativo y El Modelo MontessoriOmaar Gaarciaa Diaaz100% (2)
- Capa de PresentacionDocumento3 pagineCapa de PresentacionBOMJNessuna valutazione finora
- U.2: Lenguajes para visualizar infoDocumento21 pagineU.2: Lenguajes para visualizar infoyeeldeloli502Nessuna valutazione finora
- Shellcoding GNU/LinuxDocumento30 pagineShellcoding GNU/Linuxfelipe_vergara_40100% (1)
- Vulnerabilidad y Generatividad - Rocio OsorioDocumento3 pagineVulnerabilidad y Generatividad - Rocio Osoriojohana100% (1)
- S10 - Hoja de Respuestas CAT - ADocumento6 pagineS10 - Hoja de Respuestas CAT - AJazmín Lozano RiosNessuna valutazione finora
- Ejercicio de Codificación de Caracteres (Práctico)Documento2 pagineEjercicio de Codificación de Caracteres (Práctico)euif ebhjfNessuna valutazione finora
- Practica 01Documento4 paginePractica 01ana merida martinNessuna valutazione finora
- Juegos de CaracteresDocumento8 pagineJuegos de CaracteressimonquispeluzaNessuna valutazione finora
- Introducción a los sistemas informáticos: actividades y ejercicios prácticos de aprendizajeDocumento5 pagineIntroducción a los sistemas informáticos: actividades y ejercicios prácticos de aprendizajeNacho Atienza BravoNessuna valutazione finora
- Sim Ul AdoresDocumento70 pagineSim Ul AdoresMartin Valencia AlejoNessuna valutazione finora
- Practica GeneralDocumento18 paginePractica GeneralGuapo LopezNessuna valutazione finora
- Informatica I - Taller Unidad #1Documento2 pagineInformatica I - Taller Unidad #1Camilo LoaizaNessuna valutazione finora
- La Traducción Desde Un Lenguaje Compilado Como CDocumento2 pagineLa Traducción Desde Un Lenguaje Compilado Como CYosi MejgonNessuna valutazione finora
- Actividad - 9 - EMU8086Documento10 pagineActividad - 9 - EMU8086David A Rodriguez SanchezNessuna valutazione finora
- 1.2.6. La Computadora Personal Ideal para ProgramaciónDocumento4 pagine1.2.6. La Computadora Personal Ideal para ProgramaciónCarlos Eduardo Marcel MoralesNessuna valutazione finora
- Taller Power Point UNIVERSIDAD DE GUAYAQUILDocumento15 pagineTaller Power Point UNIVERSIDAD DE GUAYAQUILAnaCristinaSedeñoJNessuna valutazione finora
- Edu rh03 2021 Exam 591227 Sistemas y Aplicaciones I PDFDocumento8 pagineEdu rh03 2021 Exam 591227 Sistemas y Aplicaciones I PDFsara MvNessuna valutazione finora
- U3 - Reconstruccion de Codigo I Estructuras de DatosDocumento81 pagineU3 - Reconstruccion de Codigo I Estructuras de Datosjaire.alfonsocNessuna valutazione finora
- .SGBD Gratuitos: Sqlite Db2 Express-Capache Derby Mysql SGBD Licenciados: Microsoft Access Microsoft SQL Server Fox Pro OracleDocumento4 pagine.SGBD Gratuitos: Sqlite Db2 Express-Capache Derby Mysql SGBD Licenciados: Microsoft Access Microsoft SQL Server Fox Pro OracleDaniel Lopez UchihaNessuna valutazione finora
- Tarea 1.5 Constantes Variables en Lenguaje C Tareas Del Parcial 1 - 3c 1 - 3cDocumento7 pagineTarea 1.5 Constantes Variables en Lenguaje C Tareas Del Parcial 1 - 3c 1 - 3cWesley GodoyNessuna valutazione finora
- Cómo Se Escribe Una Página Web Bien Estructurada Modulo 5Documento70 pagineCómo Se Escribe Una Página Web Bien Estructurada Modulo 5JULIAN TRUJILLONessuna valutazione finora
- Manejo Interno de DatosDocumento8 pagineManejo Interno de DatosCarlos LunaNessuna valutazione finora
- MDPyPCTP03 - 2021-Introducción A Java Parte 2Documento2 pagineMDPyPCTP03 - 2021-Introducción A Java Parte 2Anahi GODOY PONCENessuna valutazione finora
- Ataques y debilidades DES modo ECBDocumento2 pagineAtaques y debilidades DES modo ECBFermín Tene LópezNessuna valutazione finora
- Guía 1 SDI 115 2013Documento10 pagineGuía 1 SDI 115 2013Estevis MongeNessuna valutazione finora
- EJERCICIOS 4º ESO Sistema BinarioDocumento2 pagineEJERCICIOS 4º ESO Sistema BinariocoviyuNessuna valutazione finora
- EnsambladorDocumento137 pagineEnsambladorYossune Arvez PerezNessuna valutazione finora
- LDC 21 TP8 Vazquezbruno 7018Documento31 pagineLDC 21 TP8 Vazquezbruno 7018BRUNO VAZQUEZNessuna valutazione finora
- LDC 21 TP8 Vazquezbruno 7018Documento32 pagineLDC 21 TP8 Vazquezbruno 7018BRUNO VAZQUEZNessuna valutazione finora
- Rep01 05Documento6 pagineRep01 05Luis AlfredoNessuna valutazione finora
- Codigos ASCIIDocumento5 pagineCodigos ASCIIalvaro sastre lopezNessuna valutazione finora
- Creacion de Exploits 7 Unicode de 0×00410041 A La Calc Por Corelanc0d3r Traducido Por Ivinson PDFDocumento57 pagineCreacion de Exploits 7 Unicode de 0×00410041 A La Calc Por Corelanc0d3r Traducido Por Ivinson PDFStiiven Rodriguez AlvarezNessuna valutazione finora
- Curso - Gratis Iniciacion A OracleDocumento4 pagineCurso - Gratis Iniciacion A OracleMathias Etienne DipauloNessuna valutazione finora
- Cómo Se Escribe Una Página Web Bien EstructuradaDocumento21 pagineCómo Se Escribe Una Página Web Bien EstructuradaJuan AntonioNessuna valutazione finora
- Lenguaje Ensamblador EmbebidoDocumento9 pagineLenguaje Ensamblador EmbebidoArturo AguilarNessuna valutazione finora
- Semana 3Documento50 pagineSemana 3Lenin BMNessuna valutazione finora
- 1 Pract IntroDocumento26 pagine1 Pract IntroNorman CubillaNessuna valutazione finora
- Protocolo Individual #1 de Teoria Automatas y Lenguajes FormalesDocumento5 pagineProtocolo Individual #1 de Teoria Automatas y Lenguajes FormalesJaider JimenezNessuna valutazione finora
- Problemas AnalisisLexicco JFlex 1314Documento4 pagineProblemas AnalisisLexicco JFlex 1314Sizara ZamoraNessuna valutazione finora
- Ejercicios Aplicaciones Ofimáticas 1º SemanaDocumento10 pagineEjercicios Aplicaciones Ofimáticas 1º SemanaAlex Lopez GarciaNessuna valutazione finora
- Guia de TP BDA - 2012Documento22 pagineGuia de TP BDA - 2012Jokerwin09Nessuna valutazione finora
- U4 - Reconstruccion de Codigo II Estructuras de Codigos ComunesDocumento82 pagineU4 - Reconstruccion de Codigo II Estructuras de Codigos Comunesjaire.alfonsocNessuna valutazione finora
- Test MicroprocesadoresDocumento14 pagineTest MicroprocesadoresJean ReyesNessuna valutazione finora
- 1 Escritura Del Primer Código Con C# (Introducción A C#, Parte 1)Documento9 pagine1 Escritura Del Primer Código Con C# (Introducción A C#, Parte 1)Antony AlfaroNessuna valutazione finora
- Tarea 5Documento5 pagineTarea 5manuel.capistran.ponceNessuna valutazione finora
- Preguntas Segundo CorteDocumento10 paginePreguntas Segundo CorteJuan PabloNessuna valutazione finora
- Solucionariaa de MicroprocesadoresDocumento18 pagineSolucionariaa de MicroprocesadorestavuchoNessuna valutazione finora
- 030 - Introduccion A C# V11Documento40 pagine030 - Introduccion A C# V11Mauro CortesNessuna valutazione finora
- Tarea 1 SDI 115 2015Documento11 pagineTarea 1 SDI 115 2015Javiier UmañaNessuna valutazione finora
- 2do PracticoDocumento3 pagine2do Practicocarlos huaytaNessuna valutazione finora
- Formato de Codi Cación de Caracteres PCRE: (Aviso Legal) Leer en InglésDocumento3 pagineFormato de Codi Cación de Caracteres PCRE: (Aviso Legal) Leer en InglésGestión2190 Capital HumanoNessuna valutazione finora
- Aplicaciones lenguaje programación híbridaDocumento6 pagineAplicaciones lenguaje programación híbridaJoshua Velasquez Velasquez100% (1)
- Diagrama de FlujoDocumento4 pagineDiagrama de FlujoKoralae0% (1)
- LECTURA 7. Entornos de Desarrollo y Elementos Del LenguajeDocumento41 pagineLECTURA 7. Entornos de Desarrollo y Elementos Del LenguajeRobe UtreraNessuna valutazione finora
- Reseña Visual Studio 2010Documento35 pagineReseña Visual Studio 2010Yordany Carhuanina SanchesNessuna valutazione finora
- Ejemplos Modo ProtegidoDocumento91 pagineEjemplos Modo Protegidoand205Nessuna valutazione finora
- Relacion Ejercicios PowerShellDocumento3 pagineRelacion Ejercicios PowerShellYasin LopezNessuna valutazione finora
- Tipos de DatosDocumento7 pagineTipos de DatosEidzer Manuel Bravo GomezNessuna valutazione finora
- Lab Semana2Documento5 pagineLab Semana2Angel Torres FlorinNessuna valutazione finora
- ELECDIG Semana2Documento29 pagineELECDIG Semana2Angel Torres FlorinNessuna valutazione finora
- Ge+ht Semana 2 Area Bajo La Curva 2020 1 PDFDocumento11 pagineGe+ht Semana 2 Area Bajo La Curva 2020 1 PDFAngel Torres FlorinNessuna valutazione finora
- Ge+ht Semana 1 Integral Definida 2020 1Documento18 pagineGe+ht Semana 1 Integral Definida 2020 1Angel Torres FlorinNessuna valutazione finora
- Solucionario Cálculo 2 Semana 2Documento21 pagineSolucionario Cálculo 2 Semana 2Angel Torres Florin100% (1)
- STAT 1203 M03 Lectura v12Documento9 pagineSTAT 1203 M03 Lectura v12Angel Torres FlorinNessuna valutazione finora
- Cálculo de áreas de regiones acotadasDocumento26 pagineCálculo de áreas de regiones acotadasAngel Torres FlorinNessuna valutazione finora
- Solucionario de Cálculo 2 Semana1 PDFDocumento24 pagineSolucionario de Cálculo 2 Semana1 PDFAngel Torres FlorinNessuna valutazione finora
- Taller Semana 2 Calc 2 2020 1 - NRC 3907Documento4 pagineTaller Semana 2 Calc 2 2020 1 - NRC 3907Angel Torres Florin100% (1)
- Cálculo de áreas de regiones acotadasDocumento26 pagineCálculo de áreas de regiones acotadasAngel Torres FlorinNessuna valutazione finora
- Semana 1 Integral Definida 2020 1 PDFDocumento19 pagineSemana 1 Integral Definida 2020 1 PDFAngel Torres FlorinNessuna valutazione finora
- Solucionario de Cálculo 2 Semana1 PDFDocumento24 pagineSolucionario de Cálculo 2 Semana1 PDFAngel Torres FlorinNessuna valutazione finora
- 01 Aprenda C++ Como Si Estuviera en PrimeroDocumento87 pagine01 Aprenda C++ Como Si Estuviera en PrimeroPerencito AblNessuna valutazione finora
- Cimu 2Documento2 pagineCimu 2Angel Torres FlorinNessuna valutazione finora
- ProgramcionDocumento2 pagineProgramcionAngel Torres FlorinNessuna valutazione finora
- Regla de CadenaDocumento2 pagineRegla de CadenaAngel Torres FlorinNessuna valutazione finora
- 2 - EjercicioCrapsDocumento2 pagine2 - EjercicioCrapsAngel Torres FlorinNessuna valutazione finora
- Regla de CadenaDocumento2 pagineRegla de CadenaAngel Torres FlorinNessuna valutazione finora
- Fundamentos e Historia de La Psicología PositivaDocumento3 pagineFundamentos e Historia de La Psicología PositivaAlvaro PuertasNessuna valutazione finora
- 01 Reporte Medicion e IncertidumbreDocumento3 pagine01 Reporte Medicion e IncertidumbreAngel Torres FlorinNessuna valutazione finora
- Semana 3 Formas Indeterminadas y Derivacion Implicita Guia + HT Calc 1 PDFDocumento9 pagineSemana 3 Formas Indeterminadas y Derivacion Implicita Guia + HT Calc 1 PDFAngel Torres FlorinNessuna valutazione finora
- TALLER VectoresDocumento9 pagineTALLER VectoresAngel Torres FlorinNessuna valutazione finora
- Semana 2Documento10 pagineSemana 2JoelNessuna valutazione finora
- 01 Reporte Medicion e IncertidumbreDocumento3 pagine01 Reporte Medicion e IncertidumbreAngel Torres FlorinNessuna valutazione finora
- DinamicaDocumento1 paginaDinamicaAngel Torres FlorinNessuna valutazione finora
- Sesión 12 - Fund - ProgDocumento21 pagineSesión 12 - Fund - ProgAngel Torres FlorinNessuna valutazione finora
- El Maravillo Walmish y AntañahuiDocumento6 pagineEl Maravillo Walmish y AntañahuiEleonora Pajuelo MelladoNessuna valutazione finora
- Hacedor de Caminos - ADocumento1 paginaHacedor de Caminos - AMarlon ObandoNessuna valutazione finora
- Libro Redaccion JuridicaDocumento3 pagineLibro Redaccion JuridicaSimeon Humberto Velasquez ReyesNessuna valutazione finora
- Anon - Litelantes en EspañaDocumento59 pagineAnon - Litelantes en EspañaEliana Ruth Condor VillegasNessuna valutazione finora
- Probabilidad y Estadística EVD4Documento17 pagineProbabilidad y Estadística EVD4dampro 28Nessuna valutazione finora
- Mapa ConceptualDocumento2 pagineMapa ConceptualHugo Calderon0% (1)
- Glosario de Términos MarinosDocumento21 pagineGlosario de Términos MarinosMario Ramirez100% (1)
- M14 U2 S4 OsccDocumento17 pagineM14 U2 S4 Osccosvaldo80% (5)
- Análisis de Las Prácticas Comunicativas en FacebookDocumento17 pagineAnálisis de Las Prácticas Comunicativas en FacebookJack HenriquezNessuna valutazione finora
- Ritual Arameo de La EsperanzaDocumento2 pagineRitual Arameo de La EsperanzaMaria EdelmiraNessuna valutazione finora
- PerseveremosDocumento2 paginePerseveremosSoldiers of the Cross of Christ in MiamiNessuna valutazione finora
- Minuscalas Magicas DependenciasDocumento6 pagineMinuscalas Magicas DependenciasMayra BernalNessuna valutazione finora
- Las FARC-EP. El PCCC y El Movimiento BolivarianoDocumento17 pagineLas FARC-EP. El PCCC y El Movimiento BolivarianoJorge Andrés Cortés Molina100% (1)
- AUTOESTIMADocumento8 pagineAUTOESTIMAemelysNessuna valutazione finora
- La Perla - Jhon Steinbeck Jueves 19Documento2 pagineLa Perla - Jhon Steinbeck Jueves 19Ana0% (1)
- QuoraDocumento10 pagineQuoracamilo ocampoNessuna valutazione finora
- Los momentos de la prueba en el procesoDocumento24 pagineLos momentos de la prueba en el procesoKristina Kundrotas ANessuna valutazione finora
- ESP - Oración Por Las Vocaciones LQDocumento32 pagineESP - Oración Por Las Vocaciones LQLuis Amado Moreno TapiaNessuna valutazione finora
- La Eucaristía en El Libro Del ApocalipsisDocumento20 pagineLa Eucaristía en El Libro Del Apocalipsisomarjm100% (2)
- Manual de buenas prácticas agencias viajes turismoDocumento81 pagineManual de buenas prácticas agencias viajes turismoTania Dueñas OtoyaNessuna valutazione finora
- La Conversion de Energia ElectromecanicaDocumento7 pagineLa Conversion de Energia ElectromecanicaAlexis TibanNessuna valutazione finora
- Prospecto de Matematica CeprunsaDocumento149 pagineProspecto de Matematica CeprunsawebjuancarlosNessuna valutazione finora
- Propuesta de Esquema de Planificación-Secuencias DidácticasDocumento4 paginePropuesta de Esquema de Planificación-Secuencias DidácticasAustria M Espinosa A.Nessuna valutazione finora
- Socialización ExternaDocumento6 pagineSocialización ExternaNicolas SuasnavasNessuna valutazione finora
- Catalogo de CompetenciasDocumento8 pagineCatalogo de CompetenciasAnonymous 2iB4C2Nessuna valutazione finora
- Jesús nos invita a ser mejores personasDocumento2 pagineJesús nos invita a ser mejores personasJhamil LopezNessuna valutazione finora
- 1 AnestesiaLocalyTecnicasdeBloqueoenlaPracticaEstomatologicaDocumento98 pagine1 AnestesiaLocalyTecnicasdeBloqueoenlaPracticaEstomatologicaChakirou OURO-AGORONessuna valutazione finora