Potrebbero piacerti anche
- Chapter06 FeasibilityDocumento26 pagineChapter06 Feasibilityapi-3759969100% (1)
- Certified Information Security Manager (CISM) : Course AgendaDocumento4 pagineCertified Information Security Manager (CISM) : Course AgendaJose Baez C.Nessuna valutazione finora
- Rexx HandoutDocumento62 pagineRexx HandoutPawan ManandharNessuna valutazione finora
- Information Storage and Management (MR-1CP-ISMV3)Documento2 pagineInformation Storage and Management (MR-1CP-ISMV3)vishvendra1Nessuna valutazione finora
- sSE04 - Full Disk Encryption For IBM DiskDocumento67 paginesSE04 - Full Disk Encryption For IBM DiskChana WaNessuna valutazione finora
- Emc E05 001Documento61 pagineEmc E05 001PrasadValluraNessuna valutazione finora
- E05 001 Information Storage Management ExamDocumento4 pagineE05 001 Information Storage Management ExamYara Tarek ElmaghrabyNessuna valutazione finora
- Business Analytics Foundation With Tools: Lesson 0Documento8 pagineBusiness Analytics Foundation With Tools: Lesson 0PhaniNessuna valutazione finora
- QMF Assignment-3: 046 Sameer Jadhav 106 Chetan Patil 120 Jayraj Patil 150 Sagar JadhavDocumento8 pagineQMF Assignment-3: 046 Sameer Jadhav 106 Chetan Patil 120 Jayraj Patil 150 Sagar JadhavSagar JadhavNessuna valutazione finora
- Lesson 4 - PMP - Prep - Integration Management - V2-1 PDFDocumento31 pagineLesson 4 - PMP - Prep - Integration Management - V2-1 PDFJohn ChibweNessuna valutazione finora
- Professional and Social Responsibility: Based On PMBOK® Guide - Fifth EditionDocumento17 pagineProfessional and Social Responsibility: Based On PMBOK® Guide - Fifth EditionJohn ChibweNessuna valutazione finora
- Project Management Processes: Based On PMBOK® Guide - Fifth EditionDocumento25 pagineProject Management Processes: Based On PMBOK® Guide - Fifth EditionAbhishekParvataneniNessuna valutazione finora
- Cloud Computing in DepthDocumento79 pagineCloud Computing in DepthBiplab ParidaNessuna valutazione finora
- Great Dakota Bank Case StudyDocumento11 pagineGreat Dakota Bank Case StudyItsCjNessuna valutazione finora
- Practical Case Implementing COBIT Processes - 2016-04Documento14 paginePractical Case Implementing COBIT Processes - 2016-04Greet VoldersNessuna valutazione finora
- Getting Started With IBM Z Cyber VaultDocumento152 pagineGetting Started With IBM Z Cyber VaultcmkgroupNessuna valutazione finora
- White Box Testing v022971Documento14 pagineWhite Box Testing v022971api-26345612Nessuna valutazione finora
- ISO 9001 2015 DraftDocumento37 pagineISO 9001 2015 DraftDipakNessuna valutazione finora
- Blockchains: Architecture, Design and Use CasesDocumento22 pagineBlockchains: Architecture, Design and Use CasesMousumi Paul SamantaNessuna valutazione finora
- Enterprise Database Security & Monitoring: Alfred Horng IBM Software GroupDocumento19 pagineEnterprise Database Security & Monitoring: Alfred Horng IBM Software GroupSean LamNessuna valutazione finora
- CCNP Switch: Network ManagementDocumento83 pagineCCNP Switch: Network ManagementJe RelNessuna valutazione finora
- IIB V10 MQ Flexibility: David Coles IBM Integration Bus Level 3 Technical LeadDocumento34 pagineIIB V10 MQ Flexibility: David Coles IBM Integration Bus Level 3 Technical LeadRichard RichieNessuna valutazione finora
- Natural Language ProcessingDocumento19 pagineNatural Language ProcessingAnonymous jpeHV73mLzNessuna valutazione finora
- Domain 4 - PPT SlidesDocumento70 pagineDomain 4 - PPT SlidessondosNessuna valutazione finora
- Tia 918 PDFDocumento482 pagineTia 918 PDFpzernikNessuna valutazione finora
- C141-Cloud Ecosystem Reference ModelDocumento88 pagineC141-Cloud Ecosystem Reference ModelweeralalithNessuna valutazione finora
- Lesson 9 - PMP - Prep - Human Resource - V2 PDFDocumento29 pagineLesson 9 - PMP - Prep - Human Resource - V2 PDFJohn ChibweNessuna valutazione finora
- Network and Information Security: Unit 1 IntroductionDocumento19 pagineNetwork and Information Security: Unit 1 IntroductionPavan Kumar NNessuna valutazione finora
- Lec8 - Risk Mitigation Startegry DevDocumento50 pagineLec8 - Risk Mitigation Startegry DevAlaaNessuna valutazione finora
- DBA Corpppt Mainframes Le370Documento49 pagineDBA Corpppt Mainframes Le370api-3736498Nessuna valutazione finora
- RMF Monitor IIIDocumento23 pagineRMF Monitor IIIsteam86Nessuna valutazione finora
- 1 The Role of Statistics and The Data Analysis ProcessDocumento30 pagine1 The Role of Statistics and The Data Analysis ProcessIT GAMING100% (1)
- CH 02Documento47 pagineCH 02Dicky Witama SuryadiredjaNessuna valutazione finora
- CBAP - Module 01 - V1.1Documento38 pagineCBAP - Module 01 - V1.1rohanlopezNessuna valutazione finora
- StatisticsDocumento101 pagineStatisticsRahul GhosaleNessuna valutazione finora
- Feasibility Study PDFDocumento8 pagineFeasibility Study PDFMachawe KuneneNessuna valutazione finora
- CMMI v1.2 TutorialDocumento121 pagineCMMI v1.2 TutorialkithsyNessuna valutazione finora
- ISO27k ISMS Implementation and Certification Process v4 PDFDocumento1 paginaISO27k ISMS Implementation and Certification Process v4 PDFKokoro NamidaNessuna valutazione finora
- Enterprise Architecture A General OverviewDocumento45 pagineEnterprise Architecture A General OverviewraducooNessuna valutazione finora
- Cbap Module 04 v1Documento26 pagineCbap Module 04 v1rohanlopezNessuna valutazione finora
- PowerCenter Level1 Unit03Documento18 paginePowerCenter Level1 Unit03Christian AcostaNessuna valutazione finora
- PRINCE2.Realtests - prinCE2 Foundation.v2015!03!26.by - Elouise.150qDocumento63 paginePRINCE2.Realtests - prinCE2 Foundation.v2015!03!26.by - Elouise.150qBala RaoNessuna valutazione finora
- Sreekanth Iyer, IBM, Addressing Cloud SecurityDocumento23 pagineSreekanth Iyer, IBM, Addressing Cloud SecurityAjeet Singh RainaNessuna valutazione finora
- Best Practices in Analytics, Business Intelligence and Performance ManagementDocumento8 pagineBest Practices in Analytics, Business Intelligence and Performance ManagementdayooyefugaNessuna valutazione finora
- Web Development Course With PHPDocumento15 pagineWeb Development Course With PHPChetan KelkarNessuna valutazione finora
- WQFTE702 Exercises Getting Started GuideDocumento91 pagineWQFTE702 Exercises Getting Started GuideNarendar ReddyNessuna valutazione finora
- Banking Case StudyDocumento9 pagineBanking Case Studyainesh_mukherjeeNessuna valutazione finora
- MISO-Chapter 6: IT StrategyDocumento36 pagineMISO-Chapter 6: IT StrategyLiibanMaahirNessuna valutazione finora
- Determining System RequirementsDocumento15 pagineDetermining System Requirementsheromiki316Nessuna valutazione finora
- z/OS WLM: The Basics Every Performance Analyst Should Know: Session 10888 Glenn Anderson, IBM Technical TrainingDocumento25 paginez/OS WLM: The Basics Every Performance Analyst Should Know: Session 10888 Glenn Anderson, IBM Technical TrainingAmazon mturkNessuna valutazione finora
- TOGAF Demystified: Course DeliveryDocumento4 pagineTOGAF Demystified: Course DeliveryRajesh SaxenaNessuna valutazione finora
- Python Crash Course ProgrammingDocumento28 paginePython Crash Course ProgrammingpalimariumNessuna valutazione finora
- Sbe10 10 Simple RegressionDocumento100 pagineSbe10 10 Simple RegressionRAMANessuna valutazione finora
- Spice FutureDocumento18 pagineSpice FuturesunitamuduliNessuna valutazione finora
- Cloud Computing Security BreachesDocumento54 pagineCloud Computing Security Breachesleon77bangaNessuna valutazione finora
- 5.3.3.2 Lab - Troubleshoot LAN Traffic Using SPANDocumento6 pagine5.3.3.2 Lab - Troubleshoot LAN Traffic Using SPANYaser Samer0% (6)
- 4aa3 8987enwDocumento53 pagine4aa3 8987enwCésar VieiraNessuna valutazione finora
- 2014-03-25 IBM Storwize and SVC IP Replication-Acceleratewith ATSDocumento39 pagine2014-03-25 IBM Storwize and SVC IP Replication-Acceleratewith ATSNguyen Van HaiNessuna valutazione finora
- DWDM R19 Unit 1Documento27 pagineDWDM R19 Unit 1GAYATHRI KAMMARA 19MIS7006Nessuna valutazione finora
- User Wip GuideDocumento4 pagineUser Wip Guidexieing.et.wltfifiNessuna valutazione finora
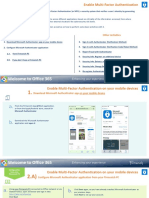
- Quick Card - MFADocumento13 pagineQuick Card - MFAnarayanmbadas_586809Nessuna valutazione finora
- Web API Interview Questions - CodeProjectDocumento5 pagineWeb API Interview Questions - CodeProjectRAKESHIMS36Nessuna valutazione finora
- Testing: Concepts, Issues, and Techniques: Dr. Sohail KhanDocumento46 pagineTesting: Concepts, Issues, and Techniques: Dr. Sohail KhanAli AhmadNessuna valutazione finora
- 1.ITFM Course Outline 2014Documento4 pagine1.ITFM Course Outline 2014swaroop666Nessuna valutazione finora
- Requirements Engineering in The Rational Unified ProcessDocumento16 pagineRequirements Engineering in The Rational Unified ProcessNishtha SinghNessuna valutazione finora
- A Case For Parallelism in Data Warehousing and OLAP: Adatta@loochi - Bpa.arizona - Edu Bkmoon@cs - Arizona.eduDocumento6 pagineA Case For Parallelism in Data Warehousing and OLAP: Adatta@loochi - Bpa.arizona - Edu Bkmoon@cs - Arizona.eduwildflower.out46951Nessuna valutazione finora
- Crystal Reports-XI R2Documento143 pagineCrystal Reports-XI R2amitshenoyNessuna valutazione finora
- Using Blockchain Technology To Ensure Honey Purity - M.A.S. RünzelDocumento11 pagineUsing Blockchain Technology To Ensure Honey Purity - M.A.S. RünzelmaaNessuna valutazione finora
- Oracle Database 12C SQL WORKSHOP 2 - Student Guide Volume 2 PDFDocumento486 pagineOracle Database 12C SQL WORKSHOP 2 - Student Guide Volume 2 PDFenrrichel0% (1)
- Active Directory Migration ChecklistDocumento5 pagineActive Directory Migration ChecklistChinni SNessuna valutazione finora
- Ssrs ArchitectureDocumento4 pagineSsrs ArchitectureSaran Kumar ReddyNessuna valutazione finora
- AVEVA™ E3D Structural Design 3.2.2.1 Fix Full Fix Release 53102 Windows 10Documento8 pagineAVEVA™ E3D Structural Design 3.2.2.1 Fix Full Fix Release 53102 Windows 10Doccon PT SynergyNessuna valutazione finora
- Web TechnologyDocumento26 pagineWeb TechnologyUseless AccountNessuna valutazione finora
- Oracle Database 11g Advanced PLSQL & TuningDocumento3 pagineOracle Database 11g Advanced PLSQL & TuningCharles G GalaxyaanNessuna valutazione finora
- 3.1. Design Goals and ObjectivesDocumento7 pagine3.1. Design Goals and ObjectivesshimelisNessuna valutazione finora
- Student Management System Project ReportDocumento59 pagineStudent Management System Project ReportMurali Vannappan60% (30)
- Citrix-Ready Autocad Map 3D Installation and Setup GuideDocumento18 pagineCitrix-Ready Autocad Map 3D Installation and Setup GuidesyafraufNessuna valutazione finora
- Java Q&aDocumento7 pagineJava Q&aAkella Sivasai Atchyut 19BCE7513Nessuna valutazione finora
- OBIEE Variable TypesDocumento14 pagineOBIEE Variable TypesDevi Vara PrasadNessuna valutazione finora
- Parrot OS ToolsDocumento56 pagineParrot OS ToolstadafiNessuna valutazione finora
- K2.Inc Is Now BruvitiDocumento2 pagineK2.Inc Is Now BruvitiPR.comNessuna valutazione finora
- TIF SIF 401 Week 01Documento66 pagineTIF SIF 401 Week 01Damar Alam RejaNessuna valutazione finora
- Password Cracking: Introduction To Computer SecurityDocumento37 paginePassword Cracking: Introduction To Computer SecurityManav BatraNessuna valutazione finora
- 10 Working With Data Storage and AnimationDocumento31 pagine10 Working With Data Storage and AnimationMarichris VenturaNessuna valutazione finora
- What Is Azure Active Directory - PDFDocumento1.447 pagineWhat Is Azure Active Directory - PDFprasannaerpNessuna valutazione finora
- ISTQB-CTFL Syllabus 2018 V3.1 PDFDocumento93 pagineISTQB-CTFL Syllabus 2018 V3.1 PDFneha vermaNessuna valutazione finora
- Logcat CSC Update LogDocumento661 pagineLogcat CSC Update LogJulian rincon RinconNessuna valutazione finora
- 9746 PlanesHostingEmpCorp Sr. CarlosDocumento12 pagine9746 PlanesHostingEmpCorp Sr. CarlosMiguel Àngel SalazarNessuna valutazione finora
- 11g SQL FUNDAMENTALS II ADDITIONAL PRACTICES AND SOLUTIONSDocumento37 pagine11g SQL FUNDAMENTALS II ADDITIONAL PRACTICES AND SOLUTIONSJawad Ahmed100% (1)