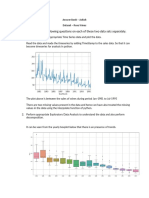
Potrebbero piacerti anche
- 21 Ways To Prevent Hair Loss!Documento10 pagine21 Ways To Prevent Hair Loss!Prateep KandruNessuna valutazione finora
- Project Predictive Modeling PDFDocumento58 pagineProject Predictive Modeling PDFAYUSH AWASTHINessuna valutazione finora
- Predictive Modeling Business Report.Documento31 paginePredictive Modeling Business Report.Paras K100% (1)
- E-Commerce Revenue Management - Python For Data Science - Great LearningDocumento4 pagineE-Commerce Revenue Management - Python For Data Science - Great LearningSuchi S Bahuguna100% (1)
- MySQL - Week 5 QuizDocumento6 pagineMySQL - Week 5 QuizPratyusha Chamarti100% (1)
- SMDM Project Report-Survi GhuraDocumento26 pagineSMDM Project Report-Survi GhuraAshish GuptaNessuna valutazione finora
- A Study On Export of Ayurvedic Products From IndiaDocumento60 pagineA Study On Export of Ayurvedic Products From IndiaUniq Manju100% (3)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Documento11 pagineAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNessuna valutazione finora
- Answer Report: Data MiningDocumento32 pagineAnswer Report: Data MiningChetan SharmaNessuna valutazione finora
- Credit Approval DecisionDocumento7 pagineCredit Approval DecisionMd. Nazibul Islam0% (1)
- Week 7 Online Quiz (Chapter 7) - Attempt Review PDFDocumento3 pagineWeek 7 Online Quiz (Chapter 7) - Attempt Review PDFShaina LolinNessuna valutazione finora
- Narrative Study Experience of An Engineer Pursuing Another CareerDocumento33 pagineNarrative Study Experience of An Engineer Pursuing Another CareerGherbe CastañaresNessuna valutazione finora
- Week 1 QuizDocumento28 pagineWeek 1 QuizMark100% (1)
- Time Series Forecasting of Rose Wine SalesDocumento69 pagineTime Series Forecasting of Rose Wine SalesPriyanka PatilNessuna valutazione finora
- Problem 2 - Survey: Importing Nessceary LibrariesDocumento10 pagineProblem 2 - Survey: Importing Nessceary LibrariesBhagyaSree JNessuna valutazione finora
- Qualitative Research ForDocumento46 pagineQualitative Research ForThanavathi100% (1)
- Marketing & Retail Analytics - Report - Part ADocumento18 pagineMarketing & Retail Analytics - Report - Part AAshish Agrawal100% (2)
- Predictive Modelling Project Report: Sreekrishnan Sirukarumbur MuralikrishnanDocumento16 paginePredictive Modelling Project Report: Sreekrishnan Sirukarumbur Muralikrishnansaarang KNessuna valutazione finora
- SQL Project QuestionsDocumento3 pagineSQL Project QuestionsSachin SinghNessuna valutazione finora
- SecB - Group02 - The Dabbawala SystemDocumento3 pagineSecB - Group02 - The Dabbawala SystemPrateep KandruNessuna valutazione finora
- Case Study Questions CRM CourseDocumento10 pagineCase Study Questions CRM CoursePrateep Kandru50% (2)
- Errors of Regression Models: Bite-Size Machine Learning, #1Da EverandErrors of Regression Models: Bite-Size Machine Learning, #1Nessuna valutazione finora
- Project Report For Problem 2Documento8 pagineProject Report For Problem 2DevNessuna valutazione finora
- Factor-Hair RV PDFDocumento23 pagineFactor-Hair RV PDFRamachandran VenkataramanNessuna valutazione finora
- Predicting Loan Defaults Using Machine LearningDocumento10 paginePredicting Loan Defaults Using Machine LearningRaveendra Babu GaddamNessuna valutazione finora
- Mba Final Reserch PaperDocumento63 pagineMba Final Reserch PaperlulitNessuna valutazione finora
- Decision Making: Clustering States Based on Health and Economic ConditionsDocumento20 pagineDecision Making: Clustering States Based on Health and Economic ConditionsAnkita MishraNessuna valutazione finora
- Business Report Pradeep Chauhan 11june'23Documento25 pagineBusiness Report Pradeep Chauhan 11june'23Pradeep ChauhanNessuna valutazione finora
- Data ImportDocumento2 pagineData ImportPrashanth MohanNessuna valutazione finora
- Statistical Analysis of Wholesale Customers and CMSU SurveyDocumento21 pagineStatistical Analysis of Wholesale Customers and CMSU Surveyhepzi selvam100% (1)
- Assignment (AutoRecovered)Documento31 pagineAssignment (AutoRecovered)Sri Balaji Ram100% (1)
- Election Exit Poll Prediction Using Machine Learning ModelsDocumento46 pagineElection Exit Poll Prediction Using Machine Learning ModelsAnshul Dyundi0% (1)
- Pressure Ulcer ExperiencesDocumento7 paginePressure Ulcer ExperiencesChassie BarberNessuna valutazione finora
- Analytics Center Of Excellence A Complete Guide - 2021 EditionDa EverandAnalytics Center Of Excellence A Complete Guide - 2021 EditionNessuna valutazione finora
- Revised Clustering Business ReportDocumento5 pagineRevised Clustering Business ReportPratigya pathakNessuna valutazione finora
- Rahulsharma - 03 12 23Documento25 pagineRahulsharma - 03 12 23Rahul GautamNessuna valutazione finora
- What is Cluster Analysis? Unsupervised Machine Learning for Customer Segmentation and Stock Market ClusteringDocumento22 pagineWhat is Cluster Analysis? Unsupervised Machine Learning for Customer Segmentation and Stock Market ClusteringNetra RainaNessuna valutazione finora
- CLUSTERING ANALYSIS FOR CUSTOMER SEGMENTATIONDocumento16 pagineCLUSTERING ANALYSIS FOR CUSTOMER SEGMENTATIONrakesh sandhyapoguNessuna valutazione finora
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Documento18 pagineBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya HajareNessuna valutazione finora
- Data Mining Assignment: Sudhanva SaralayaDocumento16 pagineData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Project - Data Mining: Bank - Marketing - Part1 - Data - CSVDocumento4 pagineProject - Data Mining: Bank - Marketing - Part1 - Data - CSVdonnaNessuna valutazione finora
- Predictive ModellingDocumento58 paginePredictive ModellingPranav ViswanathanNessuna valutazione finora
- An Analysis of Salary Data Using ANOVA TechniquesDocumento34 pagineAn Analysis of Salary Data Using ANOVA TechniquesBadazz doodNessuna valutazione finora
- Advanced Statistics-ProjectDocumento16 pagineAdvanced Statistics-Projectvivek rNessuna valutazione finora
- PGP-DSBA Program Delivery ScheduleDocumento3 paginePGP-DSBA Program Delivery ScheduleParthesh Roy TewaryNessuna valutazione finora
- Simple Regression QuizDocumento6 pagineSimple Regression QuizKiranmai GogireddyNessuna valutazione finora
- SMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDocumento16 pagineSMDM STATISTICS PROJECT-MARCH27th - DEEPA CHURIDeepa ChuriNessuna valutazione finora
- Week 1 Graded Quiz On Solution PDFDocumento2 pagineWeek 1 Graded Quiz On Solution PDFlikhith krishnaNessuna valutazione finora
- Rajiv Ranjan 11 Dec 2022Documento18 pagineRajiv Ranjan 11 Dec 2022sayantan mukherjeeNessuna valutazione finora
- PGPBABI Gurgaon April 19 SMDM GADocumento2 paginePGPBABI Gurgaon April 19 SMDM GApiyush0% (1)
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Documento12 pagineBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya Hajare100% (1)
- Clustering ProjectDocumento44 pagineClustering Projectkirti sharmaNessuna valutazione finora
- DSBAProject Oct 2020Documento24 pagineDSBAProject Oct 2020Abhay PoddarNessuna valutazione finora
- Time Series and ForecastingDocumento3 pagineTime Series and ForecastingkaviyapriyaNessuna valutazione finora
- Wholesale CustumerDocumento32 pagineWholesale CustumerAnkita Mishra100% (1)
- Data Mining QuizDocumento4 pagineData Mining QuizJohn EdNessuna valutazione finora
- Project QuestionsDocumento4 pagineProject Questionsvansh guptaNessuna valutazione finora
- MAY 2021 DATA MINING BUSINESS REPORT CLUSTER ANALYSISDocumento38 pagineMAY 2021 DATA MINING BUSINESS REPORT CLUSTER ANALYSISThaku SinghNessuna valutazione finora
- ML Assignemnt PDFDocumento21 pagineML Assignemnt PDFEric NormanNessuna valutazione finora
- MB-330 Exam - Free Actual Q&As, - ExamTopicsDocumento367 pagineMB-330 Exam - Free Actual Q&As, - ExamTopicsLucas KoplinNessuna valutazione finora
- Predictive Modelling Report - ReshmaDocumento20 paginePredictive Modelling Report - Reshmareshma ajithNessuna valutazione finora
- Anisha SMDMDocumento11 pagineAnisha SMDMAnisha SharmaNessuna valutazione finora
- Code It QuestionsDocumento3 pagineCode It QuestionsNimisha SharmaNessuna valutazione finora
- AS Practice Exercise 3 Model Solution PDFDocumento2 pagineAS Practice Exercise 3 Model Solution PDFRohan KanungoNessuna valutazione finora
- Answer Book - Rose WinesDocumento11 pagineAnswer Book - Rose WinesAshish AgrawalNessuna valutazione finora
- Problem Statement2Documento2 pagineProblem Statement2stephennrobertNessuna valutazione finora
- Business Report: Advanced Statistics Module Project - IIDocumento9 pagineBusiness Report: Advanced Statistics Module Project - IIPrasad MohanNessuna valutazione finora
- Travel Agency PackageDocumento26 pagineTravel Agency PackageKATHIRVEL SNessuna valutazione finora
- Prathamesh Shukla SMDM Project 20.08.23Documento34 paginePrathamesh Shukla SMDM Project 20.08.23Minal Karani100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocumento28 pagineBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNessuna valutazione finora
- 9 Natural Remedies For Hair Loss and Hair ThinningDocumento2 pagine9 Natural Remedies For Hair Loss and Hair ThinningPrateep KandruNessuna valutazione finora
- Customer Relationship Management Processes in Processed Foods IndustryDocumento6 pagineCustomer Relationship Management Processes in Processed Foods IndustryPrateep KandruNessuna valutazione finora
- AssignmentDocumento1 paginaAssignmentPrateep KandruNessuna valutazione finora
- As Section 377 No Longer Remains A Criminal Offense in India, How Is It Going To Impact Workplaces?Documento2 pagineAs Section 377 No Longer Remains A Criminal Offense in India, How Is It Going To Impact Workplaces?Prateep KandruNessuna valutazione finora
- Principles of Data VisualizationDocumento49 paginePrinciples of Data VisualizationPrateep KandruNessuna valutazione finora
- The Informational AdvantageDocumento1 paginaThe Informational AdvantagePrateep KandruNessuna valutazione finora
- Problems in Already Implemented IT SolutionDocumento3 pagineProblems in Already Implemented IT SolutionPrateep KandruNessuna valutazione finora
- Full List of PorterDocumento3 pagineFull List of PorterPrateep KandruNessuna valutazione finora
- Individual Assignment (C&S) GroupB 18PGP095Documento4 pagineIndividual Assignment (C&S) GroupB 18PGP095Prateep KandruNessuna valutazione finora
- Presentation Schedule of Case Studies in SCM - Sec BDocumento1 paginaPresentation Schedule of Case Studies in SCM - Sec BPrateep KandruNessuna valutazione finora
- 1) Identify The Dependent Variable in The Above Data: AnsDocumento2 pagine1) Identify The Dependent Variable in The Above Data: AnsPrateep KandruNessuna valutazione finora
- Solution For CaseDocumento3 pagineSolution For CasePrateep KandruNessuna valutazione finora
- Costs of Merloni's Current Distribution SystemDocumento5 pagineCosts of Merloni's Current Distribution SystemPrateep KandruNessuna valutazione finora
- R Cheat Sheet 3 PDFDocumento2 pagineR Cheat Sheet 3 PDFapakuniNessuna valutazione finora
- Costs of Merloni's Current Distribution SystemDocumento5 pagineCosts of Merloni's Current Distribution SystemPrateep KandruNessuna valutazione finora
- Presentation Schedule of Case Studies in SCM - Sec BDocumento1 paginaPresentation Schedule of Case Studies in SCM - Sec BPrateep KandruNessuna valutazione finora
- Econometria HeteroelasticidadDocumento4 pagineEconometria Heteroelasticidadgorell7Nessuna valutazione finora
- 06 05 Adequacy of Regression ModelsDocumento11 pagine06 05 Adequacy of Regression ModelsJohn Bofarull GuixNessuna valutazione finora
- Multinomial Logistic Regression - Spss Data Analysis ExamplesDocumento1 paginaMultinomial Logistic Regression - Spss Data Analysis ExamplesSuravi MalingaNessuna valutazione finora
- Data Mining Project DSBA PCA Report FinalDocumento21 pagineData Mining Project DSBA PCA Report Finalindraneel120Nessuna valutazione finora
- English Preparation Guide DAF 202306Documento12 pagineEnglish Preparation Guide DAF 202306TIexamesNessuna valutazione finora
- Research ProjectDocumento5 pagineResearch ProjectKariuki CharlesNessuna valutazione finora
- Chapter 5 Lab - Bnad 277Documento5 pagineChapter 5 Lab - Bnad 277api-567702028Nessuna valutazione finora
- MRM Module 1 PDFDocumento43 pagineMRM Module 1 PDFShweta YadavNessuna valutazione finora
- Are High Quality Neighbourhoods Socially CohesiveDocumento18 pagineAre High Quality Neighbourhoods Socially CohesiveAlina BalanNessuna valutazione finora
- Artificial Inteligence and Machine LearningDocumento8 pagineArtificial Inteligence and Machine LearningFarhana Sharmin TithiNessuna valutazione finora
- Sta 328.applied Regression Analysis Ii PDFDocumento12 pagineSta 328.applied Regression Analysis Ii PDFKimondo KingNessuna valutazione finora
- A Study On Customers Satisfaction Towards Reliance Jio 4G Service With Special Reference To Coimbatore CityDocumento5 pagineA Study On Customers Satisfaction Towards Reliance Jio 4G Service With Special Reference To Coimbatore CityRanjith SiddhuNessuna valutazione finora
- Weight, Height and Body Measurements DataDocumento3 pagineWeight, Height and Body Measurements DataShinji IkariNessuna valutazione finora
- Business Research Methods: Multivariate AnalysisDocumento34 pagineBusiness Research Methods: Multivariate AnalysisswathravNessuna valutazione finora
- Chapter Fifteen: Frequency Distribution, Cross-Tabulation, and Hypothesis TestingDocumento106 pagineChapter Fifteen: Frequency Distribution, Cross-Tabulation, and Hypothesis TestingpercepshanNessuna valutazione finora
- Criteria For Assessment: Statement of The Problem and ResearchDocumento5 pagineCriteria For Assessment: Statement of The Problem and ResearchDagnachew Amare DagnachewNessuna valutazione finora
- GEA1000 Chapter 2 Review: David - Chew@nus - Edu.sgDocumento14 pagineGEA1000 Chapter 2 Review: David - Chew@nus - Edu.sgHuang ZhanyiNessuna valutazione finora
- BERAC2023 Poster แนวตั้ง BERAC2023384 - A1Documento1 paginaBERAC2023 Poster แนวตั้ง BERAC2023384 - A1AnurakNessuna valutazione finora
- Dependent and Independent Sample TestsDocumento7 pagineDependent and Independent Sample TestsFatimaRaufNessuna valutazione finora
- Chapter One: 1.0 1.1 Background To The StudyDocumento107 pagineChapter One: 1.0 1.1 Background To The StudyAJIBADENessuna valutazione finora
- College Brochure - Cranes VarsityDocumento4 pagineCollege Brochure - Cranes Varsityrvs guruNessuna valutazione finora
- Data-Analytic Syllabus V1Documento18 pagineData-Analytic Syllabus V1Jhe MaejanNessuna valutazione finora
- Computational MetrologyDocumento11 pagineComputational MetrologyS.Abinith NarayananNessuna valutazione finora