Potrebbero piacerti anche
- Test Bank for Precalculus: Functions & GraphsDa EverandTest Bank for Precalculus: Functions & GraphsValutazione: 5 su 5 stelle5/5 (1)
- Binomial ApproximationDocumento13 pagineBinomial ApproximationMainak DuttaNessuna valutazione finora
- STPM Mathematics T Questions For RevisionDocumento50 pagineSTPM Mathematics T Questions For RevisionKHKwong100% (2)
- AACE Recommended Practice 11R 88 PDFDocumento24 pagineAACE Recommended Practice 11R 88 PDFSanthosh KannanNessuna valutazione finora
- AP Statistics Study GuideDocumento12 pagineAP Statistics Study Guidegeoffreygao1100% (1)
- CS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationDocumento28 pagineCS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationArdiansyah Mochamad NugrahaNessuna valutazione finora
- Dwnload Full Brief Calculus An Applied Approach 9th Edition Larson Solutions Manual PDFDocumento18 pagineDwnload Full Brief Calculus An Applied Approach 9th Edition Larson Solutions Manual PDFporpusnodular1jbrt100% (15)
- Brief Calculus An Applied Approach 9th Edition Larson Solutions ManualDocumento103 pagineBrief Calculus An Applied Approach 9th Edition Larson Solutions Manualbenjaminallenkfycbewzmq100% (16)
- James Tyrone N. LambinoDocumento18 pagineJames Tyrone N. LambinoJerald LavariasNessuna valutazione finora
- Introduction To Matlab Lec 6 - DR - AnwarDocumento37 pagineIntroduction To Matlab Lec 6 - DR - Anwarfutureme20022Nessuna valutazione finora
- A. Illustrate The Graphs of The Following Function. Determine Also Their Domain and RangeDocumento16 pagineA. Illustrate The Graphs of The Following Function. Determine Also Their Domain and RangeRalph Michael CondinoNessuna valutazione finora
- The Graphical Simplex Method: An Example: WWW - Utdallas.edu/ MetinDocumento37 pagineThe Graphical Simplex Method: An Example: WWW - Utdallas.edu/ MetinWilliamDog LiNessuna valutazione finora
- SUMIT22Documento32 pagineSUMIT22Akshay YadavNessuna valutazione finora
- DPP 2Documento3 pagineDPP 2GaganNessuna valutazione finora
- Po Samp SolsDocumento16 paginePo Samp Solsqiratnahraf9074Nessuna valutazione finora
- Actividad en Clase 24 - MA2009-2, Spring 2020 - WebAssignDocumento8 pagineActividad en Clase 24 - MA2009-2, Spring 2020 - WebAssignDanielMalpicaCuevasNessuna valutazione finora
- 222 S22 Midterm1Documento12 pagine222 S22 Midterm1PRERANA SAMPATHNessuna valutazione finora
- 2.2 Exercises With Matlab: 2.2.1 Standard Normal DistributionDocumento9 pagine2.2 Exercises With Matlab: 2.2.1 Standard Normal Distributionabymani004Nessuna valutazione finora
- Lec6 PDFDocumento14 pagineLec6 PDFCoc QuNessuna valutazione finora
- UnconstrainedOptimization IIIDocumento21 pagineUnconstrainedOptimization IIIJyotirmayee AcharyaNessuna valutazione finora
- Hints & Solutions: Paper-2 Part-I MathematicsDocumento6 pagineHints & Solutions: Paper-2 Part-I MathematicsAyushman ParasharNessuna valutazione finora
- Standard Deviation, Standardization and OutliersDocumento9 pagineStandard Deviation, Standardization and Outliersaaryamann guptaNessuna valutazione finora
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021Documento4 pagineChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/14/2021samaneh keshavarziNessuna valutazione finora
- Linear ExercisesDocumento5 pagineLinear ExercisesNguyễn Tương QuỳnhNessuna valutazione finora
- ELEC-E8116 Model-Based Control Systems /exercises and Solutions 3Documento7 pagineELEC-E8116 Model-Based Control Systems /exercises and Solutions 3James KabugoNessuna valutazione finora
- Solution Manual For Calculus An Applied Approach 10Th Edition by Larson Isbn 1305860918 9781305860919 Full Chapter PDFDocumento36 pagineSolution Manual For Calculus An Applied Approach 10Th Edition by Larson Isbn 1305860918 9781305860919 Full Chapter PDFbenjamin.smith112100% (13)
- Lecture 02 - Graphical&SimplexIntroDocumento120 pagineLecture 02 - Graphical&SimplexIntroSam TripNessuna valutazione finora
- ProblemsDocumento46 pagineProblemsgaur1234Nessuna valutazione finora
- Week 2Documento7 pagineWeek 2Anurag JoshiNessuna valutazione finora
- Dn1.8: Curve Sketching: Applications of DifferentiationDocumento3 pagineDn1.8: Curve Sketching: Applications of DifferentiationJhofran HidalgoNessuna valutazione finora
- G12 Calc. Sem.2 Ass.1 Answe Revision 22 23Documento52 pagineG12 Calc. Sem.2 Ass.1 Answe Revision 22 23mohamed S alyNessuna valutazione finora
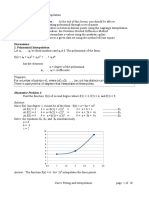
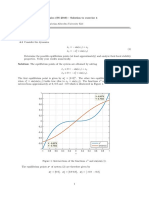
- M5. Curve Fitting and InterpolationDocumento10 pagineM5. Curve Fitting and Interpolationaisen agustinNessuna valutazione finora
- Dr. Alexander Schaum Chair of Automatic Control, Christian-Albrechts-University KielDocumento4 pagineDr. Alexander Schaum Chair of Automatic Control, Christian-Albrechts-University KielkevweNessuna valutazione finora
- Homework DerivativesDocumento5 pagineHomework DerivativesJerry SanchezNessuna valutazione finora
- We Have Next ProblemDocumento5 pagineWe Have Next ProblemKateryna TernovaNessuna valutazione finora
- TFOS22 FEA Och Optimeringsdriven Design Assignment 5Documento3 pagineTFOS22 FEA Och Optimeringsdriven Design Assignment 5Timmy NgoNessuna valutazione finora
- PGP/PGPBA Term 4: Optimization Homework - II: Homework Deadline: Groups: Peer EvaluationDocumento5 paginePGP/PGPBA Term 4: Optimization Homework - II: Homework Deadline: Groups: Peer EvaluationParam ShahNessuna valutazione finora
- Ejercicios Newton SENLDocumento2 pagineEjercicios Newton SENLSALSAVILCA CHAPPA MAYRA GUADALUPENessuna valutazione finora
- 1 Logit - Gam: Generalized Additive Model For Di-Chotomous Dependent VariablesDocumento28 pagine1 Logit - Gam: Generalized Additive Model For Di-Chotomous Dependent VariablesarifNessuna valutazione finora
- Calculus of A Single Variable Early Transcendental Functions 6Th Edition Larson Solutions Manual Full Chapter PDFDocumento36 pagineCalculus of A Single Variable Early Transcendental Functions 6Th Edition Larson Solutions Manual Full Chapter PDFcarol.alvarez992100% (13)
- Calculus of A Single Variable Early Transcendental Functions 6th Edition Larson Solutions Manual 1Documento262 pagineCalculus of A Single Variable Early Transcendental Functions 6th Edition Larson Solutions Manual 1mark100% (33)
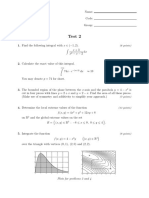
- Test2 ProblemsDocumento1 paginaTest2 ProblemsАндрій СеменовNessuna valutazione finora
- Metro Education District: NorthDocumento13 pagineMetro Education District: NorthChey1242Nessuna valutazione finora
- Main 2021 SoltnDocumento4 pagineMain 2021 SoltnEVIN S MANOJNessuna valutazione finora
- Department of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 3Documento8 pagineDepartment of Electrical Engineering School of Science and Engineering EE514/CS535 Machine Learning Homework 3Muhammad HusnainNessuna valutazione finora
- Ebook Calculus 7Th Edition Stewart Solutions Manual Full Chapter PDFDocumento54 pagineEbook Calculus 7Th Edition Stewart Solutions Manual Full Chapter PDFvoormalizth9100% (12)
- hw1 ML IvanReyesDocumento21 paginehw1 ML IvanReyesIván ReyesNessuna valutazione finora
- Calculus of A Single Variable Hybrid Early Transcendental Functions 6Th Edition Larso Solutions Manual Full Chapter PDFDocumento36 pagineCalculus of A Single Variable Hybrid Early Transcendental Functions 6Th Edition Larso Solutions Manual Full Chapter PDFcarol.alvarez992100% (13)
- Calculus of A Single Variable Hybrid Early Transcendental Functions 6th Edition Larso Solutions Manual 1Documento36 pagineCalculus of A Single Variable Hybrid Early Transcendental Functions 6th Edition Larso Solutions Manual 1lisarodriguezjabyorwmtk100% (24)
- A Typical Series SolutionDocumento9 pagineA Typical Series SolutionPrakharNessuna valutazione finora
- Import As As Import As From Import From Import From Import From Import From Import From Import From Import Import AsDocumento8 pagineImport As As Import As From Import From Import From Import From Import From Import From Import From Import Import AsKEZZIA MAE ABELLANessuna valutazione finora
- Probabilistic Neural Network (PNN)Documento9 pagineProbabilistic Neural Network (PNN)Amjad HussainNessuna valutazione finora
- Complete The Sqare InvestigationDocumento4 pagineComplete The Sqare InvestigationHuong VoNessuna valutazione finora
- Count JuanDocumento2 pagineCount JuanJulia Arabela SantosNessuna valutazione finora
- Class Assignment ProblemDocumento5 pagineClass Assignment ProblemRaghav kNessuna valutazione finora
- Lecture 7Documento28 pagineLecture 7AhmedNessuna valutazione finora
- MIDTERMDocumento12 pagineMIDTERMMarshall james G. RamirezNessuna valutazione finora
- 37 - PDFsam - 01 رياضيات 1-بDocumento2 pagine37 - PDFsam - 01 رياضيات 1-بMina AlbertNessuna valutazione finora
- 1 - Function - 1 To 57Documento57 pagine1 - Function - 1 To 57jitendra mani soniNessuna valutazione finora
- Edexcel GCE Core 4 Mathematics C4 6666 Advanced Subsidiary Jun 2005 Mark SchemeDocumento9 pagineEdexcel GCE Core 4 Mathematics C4 6666 Advanced Subsidiary Jun 2005 Mark Schemerainman875Nessuna valutazione finora
- 1 X X X X : Examples: Example 1: Consider The SystemDocumento16 pagine1 X X X X : Examples: Example 1: Consider The SystemSantiago Garrido BullónNessuna valutazione finora
- LAB 03: MATLAB Graphics: Graph2d Graph3d Specgraph GraphicsDocumento16 pagineLAB 03: MATLAB Graphics: Graph2d Graph3d Specgraph GraphicsMuhammad Massab KhanNessuna valutazione finora
- Q2 AnsDocumento13 pagineQ2 AnsSu YiNessuna valutazione finora
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYDa EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYNessuna valutazione finora
- Problems Chap7Documento13 pagineProblems Chap7Mohamed TahaNessuna valutazione finora
- Problems Chap5Documento2 pagineProblems Chap5Mohamed TahaNessuna valutazione finora
- Problems Chap8Documento22 pagineProblems Chap8Mohamed TahaNessuna valutazione finora
- أفضل 20 أداة اختراق والقرصنة ألاخلاقية مفتوحة المصدر في 2020 - GNU-Linux RevolutionDocumento1.033 pagineأفضل 20 أداة اختراق والقرصنة ألاخلاقية مفتوحة المصدر في 2020 - GNU-Linux RevolutionMohamed TahaNessuna valutazione finora
- Problems Chap4Documento36 pagineProblems Chap4Mohamed TahaNessuna valutazione finora
- Problems Chap3Documento27 pagineProblems Chap3Mohamed TahaNessuna valutazione finora
- Problems Chap1Documento20 pagineProblems Chap1Mohamed TahaNessuna valutazione finora
- Problems Chap2Documento26 pagineProblems Chap2Mohamed TahaNessuna valutazione finora
- Node NDocumento5 pagineNode NMohamed TahaNessuna valutazione finora
- Internet of Things, Smart Spaces, and Next Generation Networks and Systems (2014)Documento729 pagineInternet of Things, Smart Spaces, and Next Generation Networks and Systems (2014)Mohamed Taha100% (1)
- C - An Introductory Guide For - Francis John ThottungalDocumento61 pagineC - An Introductory Guide For - Francis John ThottungalMohamed Taha100% (1)
- Data Structures, Sample Test Questions For The Material After Test 2, With AnswersDocumento12 pagineData Structures, Sample Test Questions For The Material After Test 2, With AnswersMohamed TahaNessuna valutazione finora
- Novel Contrast Enhancement Scheme For Infrared Image Using Detail-Preserving StretchingDocumento11 pagineNovel Contrast Enhancement Scheme For Infrared Image Using Detail-Preserving StretchingMohamed TahaNessuna valutazione finora
- Data Structures - Data Structures - : Lecture 1: IntroductionDocumento55 pagineData Structures - Data Structures - : Lecture 1: IntroductionMohamed TahaNessuna valutazione finora
- File Structures: ÷ Öof Ú Êëov FDocumento9 pagineFile Structures: ÷ Öof Ú Êëov FMohamed TahaNessuna valutazione finora
- Classes in C++Documento73 pagineClasses in C++Mohamed TahaNessuna valutazione finora
- Social Media Tools For ResearchersDocumento3 pagineSocial Media Tools For ResearchersMohamed TahaNessuna valutazione finora
- Bio Statistics Test Unit2Documento4 pagineBio Statistics Test Unit2Muhammad ShahidNessuna valutazione finora
- Estimating Population VarianceDocumento26 pagineEstimating Population VarianceThesis Group- Coronado Reyes Zapata UST ChENessuna valutazione finora
- Math 1280 Statistics Final Exam Review Pages 31 36 PDFDocumento6 pagineMath 1280 Statistics Final Exam Review Pages 31 36 PDFCena Manof HonourNessuna valutazione finora
- Preliminary Cost Estimate Model For Culverts: SciencedirectDocumento9 paginePreliminary Cost Estimate Model For Culverts: SciencedirectSUDEESH KUMAR GAUTAMNessuna valutazione finora
- 2-Way-TOS-Reading and WritingDocumento24 pagine2-Way-TOS-Reading and WritingAngelica Velaque Babsa-ay AsiongNessuna valutazione finora
- Statistics IIDocumento13 pagineStatistics IIgambo_dcNessuna valutazione finora
- © Ucles 2017 9709/62/F/M/17Documento3 pagine© Ucles 2017 9709/62/F/M/17Ahmed AliNessuna valutazione finora
- Research Methodology 4Documento33 pagineResearch Methodology 4Patel Rahul RajeshbhaiNessuna valutazione finora
- 1.1 TG For Normal DistributionDocumento5 pagine1.1 TG For Normal DistributionVincere André AlbayNessuna valutazione finora
- A Multivariate Process Capability Index With A Spatial Coffecient (Wang Et Al. (2013) )Documento4 pagineA Multivariate Process Capability Index With A Spatial Coffecient (Wang Et Al. (2013) )Mohamed HamdyNessuna valutazione finora
- Kase Handout On StopsDocumento10 pagineKase Handout On StopsCynthia Ann KaseNessuna valutazione finora
- PS - LS - Chap3 - WPDocumento84 paginePS - LS - Chap3 - WPARYAN CHAVANNessuna valutazione finora
- Biostatistics PDFDocumento24 pagineBiostatistics PDFAnonymous 3xcMImL4100% (1)
- Topic 2Documento55 pagineTopic 2SalmonNessuna valutazione finora
- Assignment No.1 - 8614 - Autumn 2023Documento12 pagineAssignment No.1 - 8614 - Autumn 2023Ali SaboorNessuna valutazione finora
- Tutorial 2 (Common For All Branches ECE & CSE) : FX e XDocumento2 pagineTutorial 2 (Common For All Branches ECE & CSE) : FX e Xritvik tanksalkarNessuna valutazione finora
- Percentage Points, Student'S T-Distribution: Normal Probability FunctionDocumento1 paginaPercentage Points, Student'S T-Distribution: Normal Probability FunctionantonioNessuna valutazione finora
- Statistics For Anal. Chem. - Lecture Notes - Xu Ly So LieuDocumento157 pagineStatistics For Anal. Chem. - Lecture Notes - Xu Ly So LieuLiên Hương100% (1)
- PQRS Manual enDocumento20 paginePQRS Manual enjfmagar-1Nessuna valutazione finora
- Probabilistic Slope Analysis With The Finite Element Method: ARMA 09-149Documento8 pagineProbabilistic Slope Analysis With The Finite Element Method: ARMA 09-149Maria TabaresNessuna valutazione finora
- MML BookDocumento381 pagineMML BookMuhammad RafdiNessuna valutazione finora
- Chapter - 4: Risk and Return: An Overview of Capital Market TheoryDocumento11 pagineChapter - 4: Risk and Return: An Overview of Capital Market TheoryAkash saxenaNessuna valutazione finora
- Chapter6 ExerciesextraDocumento10 pagineChapter6 ExerciesextranikowawaNessuna valutazione finora
- ABPR1103Documento215 pagineABPR1103Thiviya TiyaNessuna valutazione finora
- GE401 MMW Midterm ExamDocumento13 pagineGE401 MMW Midterm ExamBhebz Erin MaeNessuna valutazione finora
- Elastic Stability of Thin - Walled Cylindrical and Conical Shells Under Axial CompressionDocumento10 pagineElastic Stability of Thin - Walled Cylindrical and Conical Shells Under Axial CompressionChandra PrakashNessuna valutazione finora