Documenti di Didattica
Documenti di Professioni
Documenti di Cultura
Chapter 4 - Function of Random Variables: EE385 Class Notes 7/6/2015 John Stensby
Caricato da
juanTitolo originale
Copyright
Formati disponibili
Condividi questo documento
Condividi o incorpora il documento
Hai trovato utile questo documento?
Questo contenuto è inappropriato?
Segnala questo documentoCopyright:
Formati disponibili
Chapter 4 - Function of Random Variables: EE385 Class Notes 7/6/2015 John Stensby
Caricato da
juanCopyright:
Formati disponibili
EE385 Class Notes 7/6/2015 John Stensby
Chapter 4 - Function of Random Variables
Let X denote a random variable with known density fX(x) and distribution FX(x). Let y =
g(x) denote a real-valued function of the real variable x. Consider the transformation
Y = g(X). (4-1)
This is a transformation of the random variable X into the random variable Y. Random variable
X() is a mapping from the sample space into the real line. But so is g(X()). We are interested
in methods for finding the density fY(y) and the distribution FY(y).
When dealing with Y = g(X()), there are a few technicalities that should be considered.
1. The domain of g should include the range of X.
2. For every y, the set {Y = g(X) y} must be an event. That is, the set { S : Y() = g(X())
y } must be in F (i.e., it must be an event).
3.The events {Y = g(X) = ± } must be assigned a probability of zero.
In practice, these technicalities are assumed to hold, and they do not cause any problems.
Define the indexed set
Iy = { x : g(x) y }, (4-2)
the composition of which changes with y. The distribution of Y can be expressed as
FY(y) = P[ Y y ] = P[g(X) y] = P[ X Iy ]. (4-3)
This provides a practical method for computing the distribution function.
Example 4-1: Consider the function y = g(x) = ax + b, a 0, and b are constants.
I y = {x: g(x) = ax + b y} = {x : x (y - b)/a}
Updates at http://www.ece.uah.edu/courses/ee385/ 4-1
EE385 Class Notes 7/6/2015 John Stensby
y = g(x)=x2
y
x-axis
y y
Figure 4-1: Quadratic transformation used in Example 4-2.
so that
yb yb
Fy (y) P[X I y ] P[X ] Fx ( ).
a a
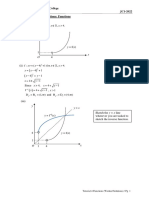
Example 4-2: Given random variable X and function y = g(x) = x2 as shown by Figure 4-1.
Define Y = g(X) = X2, and find FY(y). If y < 0, then there are no values of x such that x2 < y.
Hence
FY y 0, y 0 .
If y 0, then x2 y for y x y . Hence, Iy = {x : g(x) y } = { y x y} , and
FY (y) P y X y FX y FX (
y ) , y 0.
Special Considerations
Special consideration is due for functions g(x) that have “flat spots” and/or jump
discontinuities. These cases are considered next.
Watch for places where g(x) is constant (“flat spots”). Suppose g(x) is constant on the
interval (x0, x1]. That is, g(x) = y1, x0 < x x1, where y1 is a constant, and g(x) y1 off x0 < x
x1. Hence, all of the probability that X has in the interval x0 < x x1 is assigned to the single
value Y = y1 so that
Updates at http://www.ece.uah.edu/courses/ee385/ 4-2
EE385 Class Notes 7/6/2015 John Stensby
P Y y1 P[ x 0 X x1 ] FX x1 FX x 0 . (4-4)
That is, FY(y) has a jump discontinuity at y = y1. The amount of jump is FX(x1) - FX(x0). As an
example, consider the case of a saturating amplifier/limiter transformation.
Example 4-3 (Saturating Amplifier/Limiter): In terms of FX(x), find the distribution FY(y) for
Y = g(X) where
b, x>b
g(x) = x, -b<x b,
b, x -b.
Both Fx and y = g(x) are illustrated by Figure 4-2.
Case: y b
For this case we have g(x) y for all x. Therefore FY(y) =1 for y b.
Case: -b y < b
For -b y < b, we have g(x) y for x y. Hence, FY(y) = P(Y = g(X) y) = FX(y), -b y < b
Case: y < -b
For y < -b, we have g(x) < y for NO x. Hence, FY(y) = 0, y < -b
The result of these cases is shown by Figure 4-3.
FX(x)
y=g(x) 1
b
-b b x-axis
-b b
-b
Figure 4-2: Transformation y = g(x) and distribution Fx(x) used in Ex. 4-3.
Updates at http://www.ece.uah.edu/courses/ee385/ 4-3
EE385 Class Notes 7/6/2015 John Stensby
Watch for points where g(x) has a jump discontinuity Fy(y)
1
As shown by the following two examples, special
1-FX(b-)
care may be required when dealing with functions that
FX(-b)
have jump discontinuities.
-b b y-axis
Example 4-4: In terms of FX(x), find the distribution FY(y)
Figure 4-3: Result for Ex 4-3.
for Y = g(X), where
x c, x0
g(x) y = g(x)
y-axis
x-c, x<0
as depicted by Figure 4-4 to the right.
c
Case y c: If y c then g(x) y for x y-c. Hence,
FY(y) = FX(y-c) for y c. x-axis
Case -c y c: If -c y c then g(x) y for x 0. Hence,
-c
-
FY(y) = P[ X < 0 ] = FX(0 ) for -c y c.
Case y -c: If y -c then g(x) y for x y+c. Hence,
FY(y) = FX(y+c) for y -c.
Figure 4-4: Transformation for
Example 4-4.
Example 4-5: In terms of FX(x), find the distribution FY(y)
for Y = g(X) where
x c, x0
g(x)
x-c, x 0
as depicted by Figure 4-5.
Case y c: If y c then g(x) y for x y-c. Hence,
Updates at http://www.ece.uah.edu/courses/ee385/ 4-4
EE385 Class Notes 7/6/2015 John Stensby
y axis
y = g(x)
FY(y) = FX(y-c) for y c.
Case -c y c: If -c y c then g(x) y for x 0. Hence,
c
FY(y) = P[ X 0 ] = FX(0) for -c y c. x-axis
-c
Case y -c: If y -c then g(x) y for x y+c. Hence,
FY(y) = FX(y+c) for y -c.
Figure 4-5: Transformation for
Notice that there is only a subtle difference between the Example 4-5.
previous two examples. In fact, if FX(x) is continuous at x = 0, then FY(y) is the same for the
previous two examples.
Determination of fy in terms of fx
Determine the density fY(y) of Y = g(X) in terms of the density fX(x) of X. To
accomplish this, we solve the equation y = g(x) for x in terms of y . If g has an inverse, then we
can solve for a unique x in terms of y (x = g-1(y)). Otherwise, we will have to do it in segments.
That is, x1(y), x2(y), ... , xn(y) can be found (as solutions, or roots, of y = g(x) ) such that
y = g(x1(y)) = g(x2(y)) = g(x3(y)) = ... = g(xn(y)). (4-5)
Note that x1 through xn are functions of y. The range of each xi(y) covers part of the domain of
g(x). The union of the ranges of xi(y), 1 i n, covers all, or part of, the domain of g(x). The
desired fY(y) is
f (x ) f (x ) f (x )
f Y (y) X 1 X 2 + + X n , (4-6)
g(x1 ) g(x 2 ) g(x n )
Updates at http://www.ece.uah.edu/courses/ee385/ 4-5
EE385 Class Notes 7/6/2015 John Stensby
y = g(x) = x 2
y
y
x1 x2
x1 x2 x-axis
Figure 4-6: Transformation y = g(x).
where g(x) denotes the derivative of g(x).
We establish this result for the function y = g(x) that is depicted by Figure 4-6, a simple
example where n = 2. The extension to the general case is obvious.
y y
P(y Y y y) f Y ()d f Y (y)y
y
for small y (increments x1, x2 and y are defined to be positive). Similarly,
P(x1 -x1 X x1 ) f X (x1 )x1
(4-7)
P(x 2 < X x 2 +x 2 ) f X (x 2 )x 2
This leads to the requirement
P(y < Y y + y) P (x1 -x1 X x1 ) + P (x 2 < X x 2 +x 2 )
f Y (y)y f X (x1 )x1 f X (x 2 )x 2 (4-8)
f (x ) f (x )
f Y (y) X 1 X 2
y y
x x
1 2
Now, let the increments approach zero. The positive quantities y/x1 and y/x2 approach
Updates at http://www.ece.uah.edu/courses/ee385/ 4-6
EE385 Class Notes 7/6/2015 John Stensby
x1 0 x1 0
x 2 0 x 2 0
y dg(x1 )
y 0 y dg(x 2 )
y 0
.
and
.. (4-9)
x1 dx x 2 dx
This leads to the desired result
f X (x1 ) f X (x 2 )
f Y (y) . (4-10)
dg(x1 ) dg(x 2 )
dx dx
Example 4-6: Consider Y = aX2 where a > 0. If y < 0, then y = ax2 has no real solutions and
fY(y) = 0, y < 0. (4-11)
If y > 0, then y = ax2 has solutions x1 y / a and x 2 y / a . Also, note that g(x) = 2ax.
Hence,
f X (x1 ) f X (x 2 )
f Y (y)
dg(x1 ) dg(x 2 )
dx dx
f ( y / a) f ( y / a )
X X , y >0 . (4-12)
2a y / a 2a y / a
=0 y<0
To see a specific example, assume that X is Rayleigh distributed with parameter . The density
for X is given by (2-24); substitute this density into (4-12) to obtain
Updates at http://www.ece.uah.edu/courses/ee385/ 4-7
EE385 Class Notes 7/6/2015 John Stensby
1 y 1 ya
a exp 2 2
2
f Y (y) U(y)
2a y a (4-13)
1 y
exp U(y)
2
2 a 2 2 a
which is the density for an exponential random variable with parameter = 1/(22a), as can be
seen from inspection of (2-27). Hence the square of a Rayleigh random variable produces an
exponential random variable.
Expected Value of Transformed Random Variable
Given random variable X, with density fX(x), and a function g(x), we form the random
variable Y = g(X). We know that
Y E[Y] y f Y (y) dy (4-14)
This requires knowledge of fY(y). We can express Y directly in terms of g(x) and fX(x).
Theorem 4-1: Let X be a random variable and y = g(x) a function. The expected value of Y =
g(X) can be expressed as
Y E[Y] E[g(X)] g(x) f X (x) dx (4-15)
y = g(x) = x 2
y
y
x1 x2
x1 x2 x-axis
Figure 4-7: Transformation used in discussion of Theorem 4-1.
Updates at http://www.ece.uah.edu/courses/ee385/ 4-8
EE385 Class Notes 7/6/2015 John Stensby
To see this, consider the following example that is illustrated by Figure 4-7. Recall that
f Y (y)y f X (x1 )x1 f X (x 2 )x 2 . Multiply this expression by y = g(x1) = g(x2) to obtain
y f Y (y)y g(x1 )f X (x1 )x1 g(x 2 )f X (x 2 )x 2 . (4-16)
Now, partition the y-axis as 0 = y0 < y1 < y2 < ..... , where y = yk+1 - yk, k = 0, 1, 2, ... . By the
mappings x1 y and x 2 y , this leads to a partition x1k, k = 0, 1, 2, ... ,of the negative
axis and a partition x2k, k = 0, 1, 2, ... ,of the positive x-axes. Sum both sides over their
partitions and obtain
y k f Y (y k )y g(x1k )fX (x1k )x1k g(x 2k )f X (x 2k )x 2k . (4-17)
k 0 k 0 k 0
Let y 0, xk1 0 and xk2 0 to obtain
0
0 y f Y (y) dy
g(x)f x (x)dx g(x)f x (x)dx
0
, (4-18)
g(x)f x (x)dx
the desired result. Observe that this argument can be applied to practically any function y = g(x).
Example 4-7: Let X be N(0,) and let Y = Xn. Find E[Y]. For n even (i.e., n = 2k) we
know, from Example 2-10, that E[Xn] = E[Xn] = 1·3·5 (n - 1)n. For odd n (i.e., n = 2k +
1) write
2 2k 1
E[ X 2k 1 ] x
2k 1 f (x)dx
x exp[ x 2 / 22 ] dx . (4-19)
2 0
Updates at http://www.ece.uah.edu/courses/ee385/ 4-9
EE385 Class Notes 7/6/2015 John Stensby
Change variables: let y = x2/22, dy = (x/2)dx and obtain
2k
1 2 k 1 x x dx
E[ X 2k 1 ] (2 ) exp[ x 2 / 22 ]
2 0 (22 )k 2
(4-20)
2 (22 )k 1 k y
2 0 y e dy .
However, from known results on the Gamma function, we have
(k 1) y k e y dy k! . (4-21)
0
Now, use (4-21) in (4-20) to obtain
n 1 n 2 2
E[ X ]
2
-
x exp[ x / 2 ]dx
1 3 5 (n 1) n , n 2k (n even) (4-22)
n21 ! n
n 1
2
2 2
, n 2k 1 (n odd)
for a zero-mean Gaussian random variable X.
Approximate Mean of g(X)
Let X be a random variable and y = g(x) a function. The expected value of g(X) can be
expressed as
E[ g(X) ] g(x) f X (x) dx . (4-23)
To approximate this, expand g(x) in a Taylor's series around the mean to obtain
Updates at http://www.ece.uah.edu/courses/ee385/ 4-10
EE385 Class Notes 7/6/2015 John Stensby
(x )n
g(x) g() g()(x ) +g (n) () . (4-24)
n!
Use this expansion in the expected-value calculation to obtain
E[ g(X) ] g(x) f X (x) dx
(x ) n
g() g()(x ) +g (n) () f X (x) dx (4-25)
n!
g() g() 2 g (3) () 3 + g (n) () n + .
2! 3! n!
An approximation to E[g(X)] can be based on this formula; just compute a finite number of
terms in the expansion.
Characteristic Functions
The characteristic function of a random variable is
() f X (x)e jx dx E[e jX ] . (4-26)
Characteristic function is complex valued with
jx
() f X (x)e dx f (x)dx 1 .
X
(4-27)
Note that is the Fourier transform of fX(x), so we can write
() F[f (x)] , (4-28)
X
replace by -
Updates at http://www.ece.uah.edu/courses/ee385/ 4-11
EE385 Class Notes 7/6/2015 John Stensby
and
1
f X (x) ()e jx dx . (4-29)
2
Definition (4-26) takes the form of a sum when X is a discrete random variable. Suppose
that X takes on the values xi with probabilities pi = P[X = xi] for index i in some index set I (i
I). Then the characteristic function of X is
pi exp[ jxi ] .
() f X (x)e jx dx (4-30)
iI
Due to the delta functions in density fX(x), the integral in (4-30) becomes a sum.
Example 4-8: Consider the Gaussian density function
1 2 2
f X (x) e x /2 . (4-31)
2
The Fourier transform of fX is F [fX(x)] = exp[-22/2], as given in common tables. Hence,
2 2
() F [f (x)] e / 2 . (4-32)
X
-
1 2 2
If f X (x) e (x ) / 2 , then
2
() e j F[(1/ 2)e x /2 ]
2 2 2 2
e j e /2 . (4-33)
fold
Example 4-9: Let random variable N be Poisson with parameter . That is,
Updates at http://www.ece.uah.edu/courses/ee385/ 4-12
EE385 Class Notes 7/6/2015 John Stensby
n
P N = n e , n=0, 1, 2, ... . (4-34)
n!
From (4-30), we can write
n
n
() exp[ ]
n!
exp[ j n] exp[ ]
n!
exp[ jn]
n 0 n 0
j n
e
exp[] exp[]exp[e j ] (4-35)
n 0
n!
exp[ e j 1]
as the characteristic function for a Poisson process.
Multiple Dimension Case
The joint characteristic function XY(1,2) of random variables X and Y is defined as
XY (1, 2 ) E exp{j(1X 2 Y)} e j(1x i 2 yk ) P[X = x i , Y y k ] (4-36)
i k
for the discrete case and
XY (1, 2 ) E exp{j(1X 2 Y)} e j(1x 2 y) f XY (x, y) dxdy (4-37)
for the continuous case. Equation (4-37) is recognized as the two dimensional Fourier transform
(with the sign of j reversed) of fXY(x,y). Generalizing these definitions, we can define the joint
characteristic function of n random variables X1, X2, ... , Xn as
X1...X n (1, ... ,n ) E exp{j1X1 ... jn X n } . (4-38)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-13
EE385 Class Notes 7/6/2015 John Stensby
Equation (4-38) can be simplified using vector notation. Define the two vectors
1 X1
X2
2
, X . (4-39)
n X n
Then, we can write the n-dimensional characteristic function in the compact form
T
X () E e j X . (4-40)
Equations (4-38) and (4-40) convey the same information; however, (4-40) is much easier to
write and work with.
Characteristic Function for Multi-dimensional Gaussian Case
Let X = [X1 X2 ... Xn]T be a Gaussian random vector with mean = E[X ]. Let = [
2 ... n]T be a vector of n algebraic variables. Note that
1
2 n
T [1 2 n ] k k (4-41)
k 1
n
is a scalar. The characteristic function of X is given as
T exp[ j
() E exp[ j
T 1 T
] . (4-42)
X] 2
Updates at http://www.ece.uah.edu/courses/ee385/ 4-14
EE385 Class Notes 7/6/2015 John Stensby
Application: Transformation of Random Variables
Sometimes, the characteristic function can be used to determine the density of random
variable Y = g(X) in terms of the density of X. To see this, consider
Y () E[e jY ] E[e jg(X) ] e jg(x) f X (x) dx . (4-43)
If a change of variable y = g(x) can be made (usually, this requires g to have an inverse), this last
integral will have the form
Y () e jy h(y) dy . (4-44)
The desired result fY(y) = h(y) follows (by uniqueness of the Fourier transform).
Example 4-10: Suppose X is N(0;) and Y = aX2. Then
2 2 2 jax 2 x 2 / 22
Y () E[e jY ] E[e jaX ] e jax f X (x) dx e e dx .
2 0
For 0 x < , note that the transformation y = ax2 is one-to-one. Hence, make the change of
variable y = ax2, dy = (2ax)dx = 2 ay dx to obtain
2 jy y/ 2a2 dy
jy e y/ 2a
2
dy .
2 0 2 ay 0
Y () e e e
2ay
Hence, we have
2
e y/ 2a
f Y (y) U(y) .
2ay
Updates at http://www.ece.uah.edu/courses/ee385/ 4-15
EE385 Class Notes 7/6/2015 John Stensby
Other Applications
Sometimes, a characteristic function is used to obtain qualitative results about a random
phenomenon of interest. That is, it is a tool that may be used to obtain qualitative results about a
random quantity of interest. For example, suppose we want to show that some random
phenomenon is Gaussian distributed. We may be able to do this by deriving the characteristic
function that describes the random phenomenon (and showing that the characteristic function has
the form given by (4-33)). In Chapter 9 of these notes, we do this for shot noise. We use
characteristic function theory to show that classical shot noise becomes Gaussian distributed as
its intensity parameter becomes large.
Moment Generating Function
The moment generating function is
sx
(s) f (x)e dx E[esX ] . (4-45)
X
The nth derivative of is
dn
(s) x n f X (x)esx dx E[X n esX ] , (4-46)
n
ds
so that
dn
(s) E[X n ] m n . (4-47)
n s 0
ds
Example 4-11: Suppose X has an exponential density f X (x) e x U(x) . Then the moment
generating function is
Updates at http://www.ece.uah.edu/courses/ee385/ 4-16
EE385 Class Notes 7/6/2015 John Stensby
(s) ex esx dx .
0 s
This can be differentiated to obtain
d
(s) E[X] 1
ds s 0
d2
(s) E[X 2 ] 2 2 .
2
ds s 0
From this, we can compute the variance as
2 2
2 E[X 2 ] E[X] 2 2 1 1 2.
Theorem 4-2
Let X and Y be independent random variables. Let g(x) and h(y) be arbitrary functions. Define
the transformed random variables
Z g(X)
(4-48)
W h(Y).
Random variables Z and W are independent.
Proof: Define
A z [x : g(x) z]
Bw [y : h(y) w].
Updates at http://www.ece.uah.edu/courses/ee385/ 4-17
EE385 Class Notes 7/6/2015 John Stensby
Then the joint distribution of Z and W is
FZW (z, w) P[Z z, W w] P[g(X) z, h(Y) w] P[X A z , Y Bw ] .
However, due to independence of X and Y,
FZW (z, w) P[X A z , Y Bw ] P[X A z ] P[Y Bw ]
P[g(X) z] P[h(Y) w] P[Z z] P[W w] ,
Fz (z)FW (w) ,
so that Z and W are independent.
One Function of Two Random Variables
Given random variables X and Y and a function z = g(x,y), we form the new random
variable
Z = g(X,Y). (4-49)
We want to find the density and distribution of Z in terms of like quantities for X and Y. For
real z, denote Dz as
Dz = {(x,y) : g(x,y) z}. (4-50)
Now, note that Dz satisfies
{Z z} = {g(X,Y) z} = {(X,Y) Dz}, (4-51)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-18
EE385 Class Notes 7/6/2015 John Stensby
so that y-axis
FZ (z) P[Z z] P[(X, Y) D z ] f XY (x, y) dxdy . (4-52)
Dz
x x-axis
x+yz +
y
=
z
Thus, to find FZ it suffices to find region DZ for every z
and then evaluate the above integral.
Example 4-12: Consider the function Z = X + Y. The Figure 4-8: Integrate over the
shaded region to obtain FZ.
distribution FZ can be represented as
FZ (z) f XY (x, y) dxdy .
x yz
In this integral, the region of integration is depicted by the shaded area shown on Figure 4-8.
Now, we can write
z y
FZ (z) f XY (x, y) dxdy .
By using Leibnitz’s rule (see below) for differentiating an integral, we get the density
d d zy
f Z (z) FZ (z) f XY (x, y) dxdy
dz dz
f XY (z y, y) dy .
Leibnitz’s Rule: Consider the function of t defined by
b(t)
F(t) (x, t)dx .
a(t)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-19
EE385 Class Notes 7/6/2015 John Stensby
fX(x) = e-xU(x) fy(y)
1
x-axis -1/2 1/2 y-axis
Figure 4-9: Density functions used in Example 4-13.
Note that the t variable appears in the integrand and limits. Leibnitz’s rule states that
d d b(t) b(t) (x, t) db(t) da(t)
F(t) (x, t)dx dx + (b(t), t) (a(t), t) .
dt dt a(t) a(t) t dt dt
Special Case: X and Y Independent.
Assume that X and Y are independent. Then fXY(z-y,y) = fX(z-y)fY(y), and the previous
result becomes
f Z (z) f X (z y)f Y (y) dy , (4-53)
the convolution of fX and fY.
fX(z-y) 1
Example 4-13: Consider independent random variables fy(y)
X and Y with densities shown by Figure 4-9. Find
density fZ that describes the random variable Z = X + Y. -1/2 1/2 y-axis
CASE I: z < - 1/2 (see Fig 4-10) y=z
Figure 4-10: Case I: z < -½
There is no overlap, so fZ(z) = 0 for z < - 1/2.
1
CASE II: - 1/2 < z < 1/2 (see Fig 4-11) fy(y)
fX(z-y)
z
f z (z) e (z y) dy -1/2 1/2 y-axis
1/ 2
y=z
1 e(z 1/ 2) , 1/ 2 z 1/ 2
Figure 4-11: Case II: -½ < z < ½.
Updates at http://www.ece.uah.edu/courses/ee385/ 4-20
EE385 Class Notes 7/6/2015 John Stensby
CASE III: 1/2 < z (see Fig 4-12) 1
fy(y)
fX(z-y)
1/ 2
f z (z) e(z y) dy
1/ 2 y-axis
-1/2 1/2
1
e z [e1/ 2 e1/ 2 ], z y=z
2
Figure 4-12: Case III: ½ < z.
As shown by Figure 4-13, the final result is
0.7
Y-Axis
0.6
f z (z) 0, z 1/ 2
0.5
1 e(z 1/ 2) , 1/ 2 z 1/ 2 0.4
0.3
[e1/ 2 e1/ 2 ]e z , 1/ 2 z
0.2
0.1
Example 4-14: Let X and Y be random variables. 0.0
Consider the transformation -1 0 1 2 3 4 5
X-Axis
Figure 4-13: Final result for Example 4-13.
ZX/Y.
For this transformation, we have
Dz = { (x,y) : x/y z },
the shaded region on the plot depicted by Figure 4-14. Now, compute the distribution
yz 0
Fz (z) f XY (x, y)dxdy + yz f XY (x, y)dxdy .
0
The density fZ(z) is found by differentiating FZ to obtain
Updates at http://www.ece.uah.edu/courses/ee385/ 4-21
EE385 Class Notes 7/6/2015 John Stensby
y
y-axis
Dz is the shaded region
yz
x
x=
Drawn for case z > 0
x-axis
x
y
Figure 4-14: Integrate over shaded region to obtain FZ for Example 4-14.
d 0
f z (z) Fz (z) y f xy (yz, y)dy y f xy (yz, y)dy y f xy (yz, y)dy
dz 0
Example 4-15: Consider the transformation Z X 2 Y 2 . For this transformation, the region
DZ is given by
D z (x, y) : x 2 y 2 z (x, y) : x 2 y 2 z 2 (4-54)
the interior of a circle of radius z > 0. Hence, we can write
Fz (z) P[Z z] P[(x, y) Dz ] f (x, y) dxdy . (4-55)
Dz
Now, suppose X and Y are independent, jointly Gaussian random variables with
1 (x 2 y2 )
f XY (x, y) exp (4-56)
22 22
Updates at http://www.ece.uah.edu/courses/ee385/ 4-22
EE385 Class Notes 7/6/2015 John Stensby
Substitute (4-56) into (4-55) to obtain y-axis
1 (x 2 y 2 )
exp 22 dxdy
r
Fz (z)
22 D
z x-axis
x r cos
To integrated this, use Figure 4-15, and
y r sin
transform from rectangular to polar
coordinates Rectangular-to-Polar Transformation
r x 2 y2 , r0
tan 1 (y / x), d
dA
dA r dr d .
rd
dr
r
The change to polar coordinates yields
1 r2
2 z
Fz (z) 22 r dr d
22 0 0
exp
Cut-away view detailing differential area
dA = rdrd.
The integrand does not depend on so the Figure 4-15: Figures that supports Example 4-15.
integral over is elementary. For the
integral over r, let u = r2/22 and du = (r/2)dr to obtain
z r 2 dr z 2 / 2 2 u
Fz (z) exp r 0 e du
0 2 2 2
2 2
1 e z / 2 , z 0 ,
Updates at http://www.ece.uah.edu/courses/ee385/ 4-23
EE385 Class Notes 7/6/2015 John Stensby
so that
d z z 2 / 2 2
f z (z) Fz (z) e , z0
dz 2
a Rayleigh density with parameter Hence, if X and Y are identically distributed, independent
Gaussian random variables then Z X 2 Y 2 is Rayleigh distributed.
Two Functions of Two Random Variables
Given random variables X and Y and functions z = g(x,y), w = h(x,y), we form the new random
variables
Z = g(X,Y) (4-57)
W = h(X,Y).
Express the joint statistics of Z, W in terms of functions g, h and fXY. To accomplish this, define
Dzw = {(x,y) : g(x,y) z, h(x,y) w }. (4-58)
Then, the joint distribution of Z and W can be expressed as
FZW (z, w) P[(X, Y) D zw ] f XY (x, y)dxdy . (4-59)
Dzw
Example 4-16: Consider independent Gaussian X and Y with the joint density function
1 (x 2 y2 )
f XY (x, y) exp .
22 2 2
Updates at http://www.ece.uah.edu/courses/ee385/ 4-24
EE385 Class Notes 7/6/2015 John Stensby
Define random variables Z and W in terms of X and Y by y-axis
y = xw
the transformations
tan-1(w)
Dzw
Z X2 Y2 Dzw x-axis
W Y/X.
Drawn for case
w>0
Figure 4-16: Integrate over
Find FZW, FZ and FW. First, define region Dzw as shaded region to obtain FZW for
Example 4-16.
DZW = {(x,y) : x2 + y2 z2, y/x w }.
Dzw is the shaded region on Figure 4-16. The figure is drawn for the case w > 0 (the case w < 0
gives results that are identical to those given below). Now, integrate over Dzw to obtain
Tan 1w z 1 r 2 / 22
FZW (z, w) f XY (x, y) dxdy 2 0 22 e r dr d
D zw 2
Tan 1 (w)
z 1 r 2 / 2 2
2
0 2
e r dr ,
which leads to
tan 1 (w)
2 2
FZW (z, w) 2 1 e z / 2 , z 0, w
(4-60)
0, z 0, w
Note that Fzw factors into the product FZFW, where
Updates at http://www.ece.uah.edu/courses/ee385/ 4-25
EE385 Class Notes 7/6/2015 John Stensby
2 2
FZ (z) {1 e z / 2 }U(z)
(4-61)
FW (w) 1 1 Tan 1(w) , w
2
Note that Z and W are independent, Z is Rayleigh distributed and W is Cauchy distributed.
Joint Density Transformations: Determine fZW Directly in Terms of fXY.
Let X and Y be random variables with joint density fXY(x,y). Let
z = g(x,y) (4-62)
w = h(x,y)
be (generally nonlinear) functions that relate algebraic variables x, y to the algebraic variables z,
w. Also, we assume that g and h have continuous first-partial derivatives at the point (x,y) used
below. Now, define the new random variables
Z = g(X,Y) (4-63)
W = h(X,Y).
In this section, we provide a method for determining the joint density fZW(z,w) directly in terms
of the known joint density fXY(x,y).
First, consider the relatively simple case where (4-62) can be inverted. That is, it is
possible to solve (4-62) for unique functions
x (z, w)
(4-64)
y (z, w)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-26
EE385 Class Notes 7/6/2015 John Stensby
that give x, y in terms of z, w. Note that z = g((z,w),(z,w)) and w = h((z,w),(z,w)) since
(4-64) is the inverse of (4-62) . Later, we will consider the general case where the
transformation cannot be inverted.
The quantity P[z < Z z + dz, w < W w + dw] is the probability that random variables
Z and W lie in the infinitesimal rectangle R1 illustrated on Figure 4-17. The area of this
infinitesimal rectangle is AREA(R1) = dzdw. The vertices of the z-w plane rectangle R1 are the
points
P1 = (z, w)
P2 = (z, w+dw)
(4-65)
P3 = (z+dz, w+dw)
P4 = (z+dz, w).
z, w plane x, y plane
dz
w-axis y-axis P 2
P2 P3
R1 dw R2 P 3
P 1
P1 P4
g,h P 4
z-axis x-axis
P1 = (z, w) P1 = (x, y)
P2 = (z, w+dw)
P2 = (x+ dw, y+ dw)
w w
P3 = (z+dz, w+dw)
P4 = (z+dz, w) P3 = (x+ dz+ dw, y+ dz+ dw)
z w z w
P4 = (x+ dz, y+ dz)
z z
Figure 4-17: (z,w) and (x,y) planes used in transformation of two random variables.
Functions transform from z,w plane to x,y plane. Functions g,h transform from x,y
plane to z,w plane.
Updates at http://www.ece.uah.edu/courses/ee385/ 4-27
EE385 Class Notes 7/6/2015 John Stensby
The z-w plane infinitesimal rectangle R1 gets mapped into the x-y plane, where it shows up as
parallelogram R2. As shown on the x-y plane of Figure 4-17, to first-order in dw and dz,
parallelogram R2 has the vertices
P1 = (x, y) P3 = (x+ dz+ dw, y+ dz+ dw)
z w z w
(4-66)
P2 = (x+ dw, y+ dw) P4 = (x+ dz, y+ dz).
w w z z
The requirement that (4-64) have continuous first-partial derivatives was used to write (4-66).
Note that P1 maps to P1, P2 maps to P2, etc (it is easy to show that P2 - P1 = P3 - P4 and
P4 - P1 = P3 - P2 so that we have a parallelogram in the x-y plane). Denote the area of
x-y plane parallelogram R2 as AREA(R2)
If random variables Z, W fall in the z-w plane infinitesimal square R1, then the random
variables X, Y must in the x-y plane parallelogram R2, and vice-versa. In fact, we can claim
P z < Z z + dz, w < W w + dw P x < X x + dx, y < Y y + dy
f ZW (z, w) dz dw = f XY (x, y) dx dy , (4-67)
R1 R2
f ZW (z, w) AREA(R1 ) f XY (x, y) AREA(R2 )
where the approximation becomes exact as dz and dw approach zero. Since AREA(R1) = dzdw,
Equation (4-67) yields the desired fXY once an expression for AREA(R2) is obtained.
Figure 4-18 depicts the x-y plane parallelogram R2 for which area AREA(R2) must be
obtained. This parallelogram has sides P1 P2 and P1 P4 (shown as vectors with arrow heads on
Fig 4-18) that can be represented as
Updates at http://www.ece.uah.edu/courses/ee385/ 4-28
EE385 Class Notes 7/6/2015 John Stensby
P2
R2 P3
P1
P4
Figure 4-18: Parallelogram in x-y plane.
P1 P4 dz iˆ dz ˆj
z z
, (4-68)
P1 P2 dw iˆ dw ˆj
w w
where iˆ and ĵ are unit vectors in the x and y directions, respectively. Now, the vector cross
product of sides P1 P4 and P1 P2 is denoted as P1 P4 P1 P2 . And, the area of parallelogram R2
is the magnitude P1 P4 P1 P2 sin() = P1 P4 P1 P2 , where is the positive angle between
the vectors. Since iˆ ˆj kˆ , ˆj iˆ kˆ , ˆj ˆj = iˆ iˆ = kˆ kˆ = 0, we write
iˆ ˆj kˆ
z
w
AREA(R2 ) P1 P4 P1 P2 det dz dz 0 det dzdw. (4-69)
z z
z w
dw dw 0
w w
In the literature, the last determinant on the right-hand-side of (4-69) is called the Jacobian of
the transformation (4-64); symbolically, it is denoted as J(xy); instead, the notation
(x,y)/(z,w) may be used. We write
x x
(x, y z w z w
J (x, y) det det . (4-70)
(z w y y
z w z w
Updates at http://www.ece.uah.edu/courses/ee385/ 4-29
EE385 Class Notes 7/6/2015 John Stensby
Finally, substitute (4-69) into (4-67), cancel out the dzdw term that is common to both sides, and
obtain the desired result
(x, y
f ZW (z, w) f XY (x, y) , (4-71)
(z w
x (z,w)
y (z,w)
a formula for the density fZW in terms of the density fXY. It is possible to obtain (4-71) directly
from the change of variable formula in multi-dimensional integrals; this fact is discussed briefly
in Appendix 4A.
It is useful to think of (4-69) as
(x, y
AREA(R2 ) AREA(R1 ) , (4-72)
(z w
a relationship between AREA(R2) and AREA(R1). So, the Jacobian can be thought of as the
“area gain” imposed by the transformation (the Jacobian shows how area is scaled by the
transformation).
By considering the mapping of a rectangle on the x, y plane to a parallelogram on the z,
w plane (i.e., in the argument just given, switch planes so that the rectangle is in the x-y plane
and the parallelogram is in the z-w plane) , it is not difficult to show
(z, w
f XY (x, y) f ZW (z, w) , (4-73)
(x y
where (x,y) and (z,w) are related by (4-62) and (4-64). Now, substitute (4-73) into (4-71) to
obtain
Updates at http://www.ece.uah.edu/courses/ee385/ 4-30
EE385 Class Notes 7/6/2015 John Stensby
(z, w (x, y
f ZW (z, w) f ZW (z, w) , (4-74)
(x y (z w
where (x,y) and (z,w) are related by (4-62) and (4-64).
Equation (4-74) leads to the conclusion
1
(x, y
(z, w , (4-75)
(z w
(x y
where (x,y) and (z,w) are related by (4-62) and (4-64).
Sometimes, the Jacobian (z,w)/(x,y) is easier to compute than the Jacobian
(x,y)/(z,w); Equation (4-75) tells us that the former is the numerical inverse of the latter. In
terms of the Jacobian (z,w)/(x,y), Equation (4-71) becomes
f XY (x, y)
f ZW (z, w) , (4-76)
(z w x (z,w)
(x, y y (z,w)
which may be easier to evaluate than (4-71).
Often, the original transformation (4-62) does not have an inverse. That is, it may not be
possible to find unique functions and as described by (4-64). In this case, we must solve
(4-62) for its real-valued roots xk(z,w), yk(z,w), 1 k n, where n > 1. These n roots depend on
z and w; each of the (xk,yk) “covers” a different part of the x-y plane. Note that
z = g(xk,yk), w = h(xk,yk) (4-77)
for each root, 1 k n. For this case, a simple extension of (4-71) leads to
Updates at http://www.ece.uah.edu/courses/ee385/ 4-31
EE385 Class Notes 7/6/2015 John Stensby
n
(x, y
f ZW (z, w) f XY (x, y)
(z w
, (4-78)
k 1
(x, y) (x k , y k )
and the generalization of (4-76) is
f XY (x, y)
n
f ZW (z, w) (z w . (4-79)
k 1 (x, y
(x, y) (x , y )
k k
That is, to obtain fZW(z,w), we should evaluate the right-hand-side of (4-71) (or (4-76)) at each of
the n roots xk(z,w), yk(z,w), 1 k n, and sum up the results.
Example 4-17: Consider the linear transformation
z = ax + by z a b x
,
w = cx + dy w c d y
where ad - bc 0. This transformation has an inverse. It is possible to express
1
x a b z x = Az+ Bw
y c d w y = Cz+Dw,
where A, B, C and D are appropriate constants (can you find A, B, C and D??). Now, compute
a b
(z w ad bc
det
(x, y
c d
Updates at http://www.ece.uah.edu/courses/ee385/ 4-32
EE385 Class Notes 7/6/2015 John Stensby
If X and Y are random variables described by fXY(x,y), the density function for random variables
Z = aX + bY, W = cX + dY is
f XY (Az Bw, Cz+Dw)
f zw (z, w) .
ad-bc
Example 4-18: Consider X, an n1, zero-mean Gaussian random vector with positive definite
covariance matrix x. Define Y = AX, where A is an nn nonsingular matrix. Note that
y1 a11 a1n x1
n
yi a ik x k , 1 i n
k 1
y n a n1 a nn x n
As discussed previously, the density for X is
1
f x (X) exp 1 X T x1 X
(2) n / 2 x
1/ 2 2
Since A is invertable, we can write fY(Y) as
f X (X)
f Y (Y)
(Y)
,
(X) X=A-1 Y
where
Updates at http://www.ece.uah.edu/courses/ee385/ 4-33
EE385 Class Notes 7/6/2015 John Stensby
y1 / x1 y1 / x 2 y1 / x n a11 a12 a1n
(Y) y 2 / x1 y 2 / x 2 y 2 / x n a 21 a 22 a 2n
det det
(X)
y n / x1 y n / x 2 y n / x n a n1 a n2 a nn
det[A]
is the absolute value of the determinant of the matrix A. Note that
T
Y E Y Y T E AX AX A E X X T A T A X A T
T
X A 1 Y A 1
This leads to the result
1
f Y (Y) exp 1 (A 1Y)T x1 A 1Y
(2)n / 2 x
1/ 2
det A 2
T 1 T 1 1 ,
1
exp Y (A ) x A Y
1
(2) n/2
x
1/ 2
det A 2
Y1
1/2
Y
a result rewritten as
1 1 ,
f Y (Y) exp 1 Y T Y Y
1/ 2 2
(2)n / 2 Y
where Y = AxAT is the covariance of Gaussian random vector Y. This example leads to the
Updates at http://www.ece.uah.edu/courses/ee385/ 4-34
EE385 Class Notes 7/6/2015 John Stensby
general, very important result that linear y-axis
transformations of Gaussian random variables
r
produces Gaussian random variables (remember
this!!). x-axis
Example 4-19 (Polar Coordinates): Consider the
transformation
Figure 4-19: Polar coordinate transfor-
mations used in Example 4-19.
r x 2 y2 , 0r
Tan 1 (y / x),
that is illustrated by Figure 4-19. With the limitation of to the ( ] range, the
transformation has the inverse
x = r cos()
y = r sin()
cos r sin
(x, y)
det r
(r, )
sin() r cos
so that
(x, y)
f r (r, ) f XY (x, y)
(r, ) x r cos
y r sin
r f XY (r cos , r sin )
for r > 0 and - < . Suppose that X and Y are independent, jointly Gaussian, zero mean
Updates at http://www.ece.uah.edu/courses/ee385/ 4-35
EE385 Class Notes 7/6/2015 John Stensby
with a common variance 2. For this case, the above result yields
(x, y) r {r cos }2 {r sin }2
f r (r, ) f XY (x, y) r f XY (r cos , r sin ) exp
(r, ) x r cos 22 2 2
y r sin
1 r r 2
exp .
2 2 2
2
f ( )
f r (r)
Note that r and are independent, r is Rayleigh and is uniform over (-].
Example 4-20: Consider the random variables Z = g(X,Y) and W = h(X,Y) where
z = g(x, y) x 2 y 2
. (4-80)
w = h(x, y) y / x
Transformation (4-80) has roots (x1, y1) and (x2, y2) given by
x1 z(1 w 2 ) 1/ 2 , y1 wx1 wz(1 w 2 )1/ 2
(4-81)
x 2 z(1 w 2 ) 1/ 2 , y 2 wx 2 wz(1 w 2 ) 1/ 2
for - < w < and z > 0; the transformation has no real roots for z < 0. A direct evaluation of
the Jacobian leads to
z z
x y x(x 2 y 2 )½ y(x 2 y 2 ) ½
(z w det ,
det
(x, y w w 2
y / x 1/ x
x y
Updates at http://www.ece.uah.edu/courses/ee385/ 4-36
EE385 Class Notes 7/6/2015 John Stensby
which can be expressed as
(z w
(x 2 y 2 )½ 1 y 2 / x 2 . (4-82)
(x, y
When evaluate at both (x1, y1) and (x2, y2), the Jacobian yields
(z w (z w 1 w2
. (4-83)
(x, y x , y ) (x, y x , y ) z
1 1 2 2
Finally, application of (4-78) leads to the desired result
z
f ZW (z, w) f XY (x1, y1) f XY (x 2 , y2 ) , z 0, w , (4-84)
1 w2
where (x1,y1) and (x2,y2) are given by (4-81). If, for example, X and Y are independent, zero-
mean Gaussian random variables with the joint density
1
f XY (x, y) = exp (x 2 + y 2 ) / 22 , (4-85)
2
2
then we obtain the transformed density
z 1/
f ZW (z, w) exp z 2 / 22 U(z) f Z (z)f W (w) (4-86)
2 1 w2
where
Updates at http://www.ece.uah.edu/courses/ee385/ 4-37
EE385 Class Notes 7/6/2015 John Stensby
z
f Z (z) exp z 2 / 22 U(z)
2
(4-87)
1/
f W (w)
1 w2
Thus, random variables Z and W are independent, Z is Rayleigh, and W is Cauchy.
Linear Transformations of Gaussian Random Variables
Let yi, 1 i n, be zero mean, unit variance, independent (which is equivalent to being
uncorrelated in the Gaussian case) Gaussian random variables. Define the Gaussian random
vector Y = [y1 y2 yn]T. Note that E[Y ] = 0 and the covariance matrix is y = E[ Y Y T ] =
I, an n n identity matrix. Hence, we have
1
f (Y) exp 1 Y T Y . (4-88)
(2)n / 2 2
Now, let A be an n n nonsingular, real-valued matrix, and consider the linear transformation
X AY . (4-89)
The transformation is one-to-one. For every Y there is but one X , and for every X there is but
one Y = A-1X . We can express the density of X in terms of the density of Y as
f y (Y)
f x (X) (4-90)
abs[J]
Y A 1X
where
Updates at http://www.ece.uah.edu/courses/ee385/ 4-38
EE385 Class Notes 7/6/2015 John Stensby
x1 y1 x1 y 2 x1 y n
x 2 y1 x 2 y 2 x 2 y n
J det det[A] A 0 . (4-91)
x n y1 x n y 2 x n y n
Hence, we have
1
f x (X) f Y (A 1X)
A
1
exp 1 (A 1X)T A 1X (4-92)
(2) n / 2 A 2
1
exp 1 X T (A 1 )T A 1X ,
(2) n / 2 A 2
which can be written as
1
f x (X) exp 1 X T x1X , (4-93)
(2) n / 2 x
1/ 2 2
where x1 (A 1 )T A 1 , which leads to the requirement that
x = AAT. (4-94)
Since A is nonsingular (a requirement on the selection of A), is positive definite. In this
development, we used x = AAT = AAT = A2 so that A = x1/2
It is important to note that X = A Y is zero mean Gaussian with a covariance matrix
given by x = AAT. Note that a linear transformation of Gaussian random variables produces
Updates at http://www.ece.uah.edu/courses/ee385/ 4-39
EE385 Class Notes 7/6/2015 John Stensby
Gaussian random variables.
Consider the converse problem. Given zero mean Gaussian vector X with positive
definite covariance matrix x. Find a non-singular transformation matrix A so that X = AY,
where Y is zero mean Gaussian with covariance matrix y = I (identity matrix). The implication
is profound: Y = A-1X says that it is possible to transform a Gaussian vector with correlated
entries into a Gaussian vector made with uncorrelated (and independent) random variables. We
can remove correlation by properly transfoming the original vector. Clearly, we must find a
matrix A that satisfies
AAT = x. (4-95)
The solution to this problem comes from linear algebra. Given any positive definite
symmetric matrix x, there exists a nonsingular matrix P such that
PTxP = I, (4-96)
which means that x = (PT)-1P-1 = (P-1)TP-1 (we say that x is congruent to I). Compare this to
the result given above to see that matrix A can be found by using
A = (P-1)T = (PT)-1. (4-97)
The procedure for finding P is simple:
1) Use the given x to write the augmented matrix [ x I ]
2) Do elementary row and column operations until the augmented matrix becomes [ I PT ] .
The
elementary operations are
i) interchange two rows (columns)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-40
EE385 Class Notes 7/6/2015 John Stensby
ii) multiply a row (column) by a scalar
iii) add a multiple of one row (column) to another row (column).
3) Write the desired A as A = (PT)-1.
Example 4-21: Suppose we are given the covariance matrix
1 2
x .
2 5
First, write the augmented matrix
1 2 1 0
x
2 5 0 1
1) Add to 2nd row 2first row to obtain
1 2 1 0
0 1 2 1
2) Add to 2nd column 2first column to obtain
1 0 1 0
= [ I PT]
0 1 2 1
1 0
3) P T
2 1
Updates at http://www.ece.uah.edu/courses/ee385/ 4-41
EE385 Class Notes 7/6/2015 John Stensby
1 0
4) A = (PT )-1
2 1
Check Results: is PTxP = I ? (Yes!) Check Results: is AAT = x? (Yes!)
Example 4-22: Consider the covariance matrix
2 0 3
x 0 1 0
3 0 10
Now, write the augmented matrix
[ x
Add to 3rd row 3/2 times 1st row. Add to 3rd column 3/2 times 1st column
Multiply 1st row by 1/ 2 . Multiply 1st column by 1/ 2
Updates at http://www.ece.uah.edu/courses/ee385/ 4-42
EE385 Class Notes 7/6/2015 John Stensby
Multiply 3rd row by 2 /11 . Multiply 3rd column by 2 /11 .
[ IP T ]
2 2
11 11
Finally, compute
2 0 0
A (PT )1 0 1 0
3 2 0 11
2 2
Check Results: x = AAT ? (YES!)
Updates at http://www.ece.uah.edu/courses/ee385/ 4-43
Potrebbero piacerti anche
- Tues - Opening - Math Guided Interactive Math Notebook Page Solutions To EquationsDocumento6 pagineTues - Opening - Math Guided Interactive Math Notebook Page Solutions To EquationsYeet GodNessuna valutazione finora
- Chapter1-25 9 12-MorpheusDocumento148 pagineChapter1-25 9 12-MorpheushauzhiNessuna valutazione finora
- Solve first-order PDEs using Charpit's methodDocumento85 pagineSolve first-order PDEs using Charpit's methodBarsha RoyNessuna valutazione finora
- 2014 Junior Team Solutions (English)Documento12 pagine2014 Junior Team Solutions (English)-Hendrijk van Romadonn-Nessuna valutazione finora
- CH 02Documento25 pagineCH 02Ng Heng Lim100% (2)
- FUNCTIONS NOTATIONDocumento16 pagineFUNCTIONS NOTATIONMiko2014Nessuna valutazione finora
- Book Shahriar Shahriari AlgebraDocumento699 pagineBook Shahriar Shahriari Algebramehr1384100% (4)
- Exam PDocumento7 pagineExam PCyril SackeyNessuna valutazione finora
- Introduction To Xy - Plane & Xyz-Space: ContinuityDocumento32 pagineIntroduction To Xy - Plane & Xyz-Space: ContinuityNam Phạm HoàngNessuna valutazione finora
- Joint Probability DistributionDocumento4 pagineJoint Probability DistributionAriel Raye RicaNessuna valutazione finora
- Module-19-Partial DifferentiationDocumento10 pagineModule-19-Partial DifferentiationMichiko Calamba-gandahanNessuna valutazione finora
- 2024cal L4 NoteDocumento23 pagine2024cal L4 Notepotato20040927Nessuna valutazione finora
- MATH1.3: Summary of Lectures #4+5+6Documento19 pagineMATH1.3: Summary of Lectures #4+5+6Long NguyễnNessuna valutazione finora
- Lect 2Documento7 pagineLect 2Cosmin M-escuNessuna valutazione finora
- 확률과 통계Documento20 pagine확률과 통계김채호Nessuna valutazione finora
- 9426 - Some Suggestions For Review For Test2-PMT0101 (T3-1415)Documento10 pagine9426 - Some Suggestions For Review For Test2-PMT0101 (T3-1415)YoongHong ChoyNessuna valutazione finora
- MTH101: Calculus I Lecture 1: Functions and Their RepresentationsDocumento34 pagineMTH101: Calculus I Lecture 1: Functions and Their Representationslu cucuNessuna valutazione finora
- Chapter 4: Multiple Random VariablesDocumento34 pagineChapter 4: Multiple Random VariablesMaximiliano OlivaresNessuna valutazione finora
- Partial DerivativesDocumento12 paginePartial DerivativesSatyadeep YadavNessuna valutazione finora
- Module 9. Partial DerivativesDocumento18 pagineModule 9. Partial DerivativesMark Daniel RamiterreNessuna valutazione finora
- MATH 170-LN4-PartialderivativeDocumento47 pagineMATH 170-LN4-PartialderivativeKashif AliNessuna valutazione finora
- Function: Q-Series: Mathematics For BS/MS.C QM Khan Wazir 14Documento10 pagineFunction: Q-Series: Mathematics For BS/MS.C QM Khan Wazir 14Kamran JalilNessuna valutazione finora
- 25 Partial Derivatives PDFDocumento20 pagine25 Partial Derivatives PDFFrederick ImperialNessuna valutazione finora
- Functions of One Random VariableDocumento21 pagineFunctions of One Random Variablehabtemariam mollaNessuna valutazione finora
- Problem Set 2Documento2 pagineProblem Set 2Toby ChengNessuna valutazione finora
- Sample 11Documento5 pagineSample 11AnupamaNessuna valutazione finora
- EE376A/STATS376A Lecture 8 Channel Capacity and Continuous Random VariablesDocumento6 pagineEE376A/STATS376A Lecture 8 Channel Capacity and Continuous Random Variablessanjay singhNessuna valutazione finora
- GenMath ADocumento3 pagineGenMath AMariane Gayle CaballeroNessuna valutazione finora
- Chapter 01Documento83 pagineChapter 01ublehkogeniusNessuna valutazione finora
- Ultivariable Alculus: The Second-Order Partial Derivatives of F (X, Y)Documento3 pagineUltivariable Alculus: The Second-Order Partial Derivatives of F (X, Y)Stephanie ParkNessuna valutazione finora
- MC Ty Linearfns 2009 1Documento7 pagineMC Ty Linearfns 2009 1Hannan SabranNessuna valutazione finora
- L8 Partial DerivativesDocumento14 pagineL8 Partial DerivativesKyle Nikko OrtegaNessuna valutazione finora
- I Hoja3 18 SolDocumento10 pagineI Hoja3 18 SolsempiNessuna valutazione finora
- Section 5Documento3 pagineSection 5Victor RudenkoNessuna valutazione finora
- Problem Solutions - Chapter 4 Joint CDFsDocumento73 pagineProblem Solutions - Chapter 4 Joint CDFsalbertNessuna valutazione finora
- Functions Example 1:: G (X) Under G. X and G (X) 2x. in This Case, H A H A H A FDocumento6 pagineFunctions Example 1:: G (X) Under G. X and G (X) 2x. in This Case, H A H A H A FOGEGA KERUBONessuna valutazione finora
- Calculus IDocumento84 pagineCalculus IAli MaithaNessuna valutazione finora
- Continuity and Differentiability of Multivariable FunctionsDocumento21 pagineContinuity and Differentiability of Multivariable FunctionseouahiauNessuna valutazione finora
- 1 Chain Rule: 1.1 Composition of FunctionsDocumento8 pagine1 Chain Rule: 1.1 Composition of FunctionsSarkhan HashimovNessuna valutazione finora
- Transformations and DistributionsDocumento48 pagineTransformations and DistributionsCatherineNessuna valutazione finora
- 25 Partial DerivativesDocumento20 pagine25 Partial DerivativescuriousdumboNessuna valutazione finora
- Partial Differentiation ExplainedDocumento4 paginePartial Differentiation ExplainedVon Eric DamirezNessuna valutazione finora
- Chapter 5: Functio Ns of Several Vari AblesDocumento94 pagineChapter 5: Functio Ns of Several Vari AblesAli HassenNessuna valutazione finora
- Notes 5Documento33 pagineNotes 5RithuNessuna valutazione finora
- F5 - Ch03.4 Transformation WS - 230927 - 085417Documento10 pagineF5 - Ch03.4 Transformation WS - 230927 - 085417s321012Nessuna valutazione finora
- Lecture 7Documento4 pagineLecture 7Iddresia MughalNessuna valutazione finora
- Chapter-1 Functions and Their GraphsDocumento20 pagineChapter-1 Functions and Their GraphsRockSamNessuna valutazione finora
- Partial DeriaDocumento14 paginePartial Deriaprasaad08Nessuna valutazione finora
- 2E02 Partial DerivativesDocumento34 pagine2E02 Partial DerivativesMengistu TageleNessuna valutazione finora
- Functions of Several VariablesDocumento8 pagineFunctions of Several VariablesFerhat YoldasNessuna valutazione finora
- Math2014 ch1Documento24 pagineMath2014 ch1vickychan1222Nessuna valutazione finora
- 1.3 Notes Part 1Documento3 pagine1.3 Notes Part 1吳恩Nessuna valutazione finora
- Section13 8Documento10 pagineSection13 8rozemathNessuna valutazione finora
- MATH1001: (HTTP://WWW - Maths.usyd - edu.au/u/UG/JM/MATH1001/)Documento2 pagineMATH1001: (HTTP://WWW - Maths.usyd - edu.au/u/UG/JM/MATH1001/)sebba3112Nessuna valutazione finora
- 5 - The Bellman EquationDocumento7 pagine5 - The Bellman EquationJoe EmmentalNessuna valutazione finora
- F F F F: Inverse FunctionDocumento2 pagineF F F F: Inverse FunctionplsdontcrydiorNessuna valutazione finora
- Functions of Random VariablesDocumento13 pagineFunctions of Random Variablescharlotte.chua03Nessuna valutazione finora
- Partial DifferentiationDocumento20 paginePartial DifferentiationApoorva PrakashNessuna valutazione finora
- Chap2 3Documento24 pagineChap2 3Jane NdindaNessuna valutazione finora
- Ppt-21mab204t - Unit III Two Dimensional RvsDocumento107 paginePpt-21mab204t - Unit III Two Dimensional Rvsmano17doremonNessuna valutazione finora
- 2022 Tutorial 4 (Selected Solution)Documento5 pagine2022 Tutorial 4 (Selected Solution)laniceNessuna valutazione finora
- Bivariate DistributionsDocumento8 pagineBivariate DistributionsYudha AndrianzahNessuna valutazione finora
- Unit 5 PT 3 To 4 Partial Derivatives Tangent PlanesDocumento7 pagineUnit 5 PT 3 To 4 Partial Derivatives Tangent Planessprinklesdb16Nessuna valutazione finora
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesDa EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNessuna valutazione finora
- Bmat201 PDFDocumento5 pagineBmat201 PDFThaanya sNessuna valutazione finora
- Chuyên Đề Thỉnh Giảng 2023 - Số HọcDocumento5 pagineChuyên Đề Thỉnh Giảng 2023 - Số Họcminhpropvp1023Nessuna valutazione finora
- The Coding Theory Workbook: A Companion To EE 567Documento61 pagineThe Coding Theory Workbook: A Companion To EE 567rahulNessuna valutazione finora
- Problem Set & Solutions: Differential Equation: Ibnu RafiDocumento73 pagineProblem Set & Solutions: Differential Equation: Ibnu RafiAllan Mugisha100% (1)
- Wolfgang Woess-Denumerable Markov Chains - Generating Functions, Boundary Theory, Random Walks On Trees-European Mathematical Society (2009) PDFDocumento369 pagineWolfgang Woess-Denumerable Markov Chains - Generating Functions, Boundary Theory, Random Walks On Trees-European Mathematical Society (2009) PDFAkhendra KumarNessuna valutazione finora
- RD Sharma Class 8 Chapter 4 Cube and Cube RootsDocumento54 pagineRD Sharma Class 8 Chapter 4 Cube and Cube RootsJilay shahNessuna valutazione finora
- College of Foundation and General Studies Putrajaya Campus Final Exam TRIMESTER 1 2012 / 2013Documento4 pagineCollege of Foundation and General Studies Putrajaya Campus Final Exam TRIMESTER 1 2012 / 2013Bernard GohNessuna valutazione finora
- Binary Operations - MathBitsNotebook (A1 - CCSS Math)Documento2 pagineBinary Operations - MathBitsNotebook (A1 - CCSS Math)yelai gutang100% (1)
- Formulas for Pre-Olympiad Math CompetitionsDocumento11 pagineFormulas for Pre-Olympiad Math Competitionsjehovisti100% (1)
- 3 - Partial Derivatives PDFDocumento195 pagine3 - Partial Derivatives PDFNgọc NhânNessuna valutazione finora
- MD COLLEGE MCQ ON NUMERICAL METHODSDocumento5 pagineMD COLLEGE MCQ ON NUMERICAL METHODSMohd SalmanNessuna valutazione finora
- Exerise 4.1: 1. Check Whether The Following Are Quadratic EquationsDocumento20 pagineExerise 4.1: 1. Check Whether The Following Are Quadratic EquationsRekha SinghNessuna valutazione finora
- WHLP Math 9Documento2 pagineWHLP Math 9Kimberly MarasiganNessuna valutazione finora
- Intermediate Algebra ReviewDocumento8 pagineIntermediate Algebra ReviewApril Diana CruzNessuna valutazione finora
- 4038CEM Engineering Mathematics I 4010CEM Mathematics For Physics and EngineeringDocumento20 pagine4038CEM Engineering Mathematics I 4010CEM Mathematics For Physics and EngineeringMicah TamunoNessuna valutazione finora
- New Approach To Modified Schur-Cohn Criterion For Stability Analysis of A Discrete Time SystemDocumento5 pagineNew Approach To Modified Schur-Cohn Criterion For Stability Analysis of A Discrete Time SystemRitesh KeshriNessuna valutazione finora
- Course Instructors: Dr. Victor T. Odumuyiwa Dr. Ufuoma C. Ogude Department of Computer Sciences University of LagosDocumento26 pagineCourse Instructors: Dr. Victor T. Odumuyiwa Dr. Ufuoma C. Ogude Department of Computer Sciences University of LagosOriola KolawoleNessuna valutazione finora
- Unit 4 Algebraic Structures NotesDocumento26 pagineUnit 4 Algebraic Structures NotesSUDHA S100% (3)
- MA1200 Chapter 3 Polynomials and Rational FunctionsDocumento9 pagineMA1200 Chapter 3 Polynomials and Rational FunctionsWai Ho ChoiNessuna valutazione finora
- Examen - SR - Correction 2021Documento7 pagineExamen - SR - Correction 2021Malek JELASSINessuna valutazione finora
- Functional Analysis (Lecture Notes) - Peter PhilipDocumento169 pagineFunctional Analysis (Lecture Notes) - Peter Philipvic1234059Nessuna valutazione finora
- Vena Contracta: Joseph Henry Laboratories, Princeton University, Princeton, NJ 08544Documento6 pagineVena Contracta: Joseph Henry Laboratories, Princeton University, Princeton, NJ 08544aiur111Nessuna valutazione finora
- ESci 11 - Mid Term Exam ADocumento1 paginaESci 11 - Mid Term Exam Aje solarteNessuna valutazione finora
- Solution Guide, Differential EquationDocumento53 pagineSolution Guide, Differential EquationhmbxNessuna valutazione finora
- Ariella 110560649Documento8 pagineAriella 110560649Ravi DixitNessuna valutazione finora