Potrebbero piacerti anche
- Thinking in Pandas: How to Use the Python Data Analysis Library the Right WayDa EverandThinking in Pandas: How to Use the Python Data Analysis Library the Right WayNessuna valutazione finora
- Unit Ii Getting Started With PandasDocumento35 pagineUnit Ii Getting Started With PandasT. SruthiNessuna valutazione finora
- Learning Pandas - Sample ChapterDocumento30 pagineLearning Pandas - Sample ChapterPackt PublishingNessuna valutazione finora
- Data Driven Guide for Python Programming : Master Essentials to Advanced Data StructuresDa EverandData Driven Guide for Python Programming : Master Essentials to Advanced Data StructuresNessuna valutazione finora
- 101 - Introducing DataFrames - PythonDocumento2 pagine101 - Introducing DataFrames - PythonРадомир МутабџијаNessuna valutazione finora
- Learn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesDocumento37 pagineLearn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesJuanito AlimañaNessuna valutazione finora
- Data Handling Python NCERTDocumento36 pagineData Handling Python NCERTAnand RadhakrishnanNessuna valutazione finora
- CH 2Documento36 pagineCH 2Shreya MajumdarNessuna valutazione finora
- Ip Chapter 1Documento36 pagineIp Chapter 1suchitasingh1106Nessuna valutazione finora
- Python Libraries Seminar ReportDocumento16 paginePython Libraries Seminar ReportDrishti Gupta100% (2)
- IP ProjectDocumento9 pagineIP ProjectAshesNessuna valutazione finora
- Learning The Pandas Library Python Tools For Data Munging Analysis and Visual PDFDocumento208 pagineLearning The Pandas Library Python Tools For Data Munging Analysis and Visual PDFAlicia Brett100% (11)
- Unit - V Introduction To Pandas in PythonDocumento21 pagineUnit - V Introduction To Pandas in PythonLindsey WhiteNessuna valutazione finora
- Ip 102Documento36 pagineIp 102TanishkaNessuna valutazione finora
- Learning Pandas LibraryDocumento271 pagineLearning Pandas LibrarySimranNessuna valutazione finora
- Analyzing Data Using Python - Cleaning and Analyzing Data in PandasDocumento81 pagineAnalyzing Data Using Python - Cleaning and Analyzing Data in Pandasmartin napangaNessuna valutazione finora
- Packages in PythonDocumento54 paginePackages in Pythonshabazmohd196Nessuna valutazione finora
- Data Handling Using Pandas and Data Visualization - Assessment1 Class Room NotesDocumento18 pagineData Handling Using Pandas and Data Visualization - Assessment1 Class Room NotesRohan GamerNessuna valutazione finora
- Activity 3 - Pandas ExplorationDocumento4 pagineActivity 3 - Pandas ExplorationAlfaizer CruzaNessuna valutazione finora
- Pandas 2.0 - A Game-Changer For Data Scientists - Towards Data ScienceDocumento18 paginePandas 2.0 - A Game-Changer For Data Scientists - Towards Data Sciencevan maiNessuna valutazione finora
- Machine Learning Python PackagesDocumento9 pagineMachine Learning Python PackagesNandkumar KhachaneNessuna valutazione finora
- Python Data Analysis Sample ChapterDocumento40 paginePython Data Analysis Sample ChapterPackt PublishingNessuna valutazione finora
- Pandas Tutorial 1: Pandas Basics (Reading Data Files, Dataframes, Data Selection)Documento15 paginePandas Tutorial 1: Pandas Basics (Reading Data Files, Dataframes, Data Selection)fernandoNessuna valutazione finora
- Analyzing Data Using Python - Importing, Exporting, Analyzing Data With PandasDocumento50 pagineAnalyzing Data Using Python - Importing, Exporting, Analyzing Data With Pandasmartin napangaNessuna valutazione finora
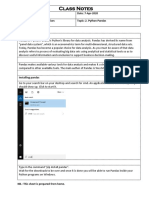
- Class Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasDocumento4 pagineClass Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasRavi RamrakhaniNessuna valutazione finora
- Unit 4 FodDocumento21 pagineUnit 4 Fodit hod100% (1)
- Getting Started With Python Data Analysis - Sample ChapterDocumento17 pagineGetting Started With Python Data Analysis - Sample ChapterPackt Publishing0% (1)
- Data TyDocumento59 pagineData TyInaara RajwaniNessuna valutazione finora
- T - Report Abhishek ChoudaryDocumento17 pagineT - Report Abhishek ChoudaryRaj SinghNessuna valutazione finora
- Viva Questions For Python LabDocumento9 pagineViva Questions For Python Labsweethaa harinishriNessuna valutazione finora
- Scikit-Learn Cookbook Sample ChapterDocumento52 pagineScikit-Learn Cookbook Sample ChapterPackt PublishingNessuna valutazione finora
- Data Analysis - From Data To Dashboard With Python, Dash, and Plotly - by Brad Bartram - Towards Data ScienceDocumento12 pagineData Analysis - From Data To Dashboard With Python, Dash, and Plotly - by Brad Bartram - Towards Data ScienceAlberto Bezerra (Petições Online)Nessuna valutazione finora
- AWP Interview QuestionDocumento4 pagineAWP Interview Questionpratikmovie999Nessuna valutazione finora
- UntitledDocumento61 pagineUntitledJyothi PulikantiNessuna valutazione finora
- Python Pandas TutorialDocumento45 paginePython Pandas TutorialKarim FathallahNessuna valutazione finora
- Unit 5-COURSE MATERIALDocumento66 pagineUnit 5-COURSE MATERIALVani SenthilNessuna valutazione finora
- DSBDA Lab ManualDocumento155 pagineDSBDA Lab Manualharsh.sb03Nessuna valutazione finora
- Pandas A Foundational Python Library For Data AnalDocumento10 paginePandas A Foundational Python Library For Data Analmey287603Nessuna valutazione finora
- PandasDocumento2 paginePandaslarzuwaNessuna valutazione finora
- E-Book Data Cleaning Techniques in PythonDocumento50 pagineE-Book Data Cleaning Techniques in Pythonnourelhoudam49Nessuna valutazione finora
- D P Lab ManualDocumento54 pagineD P Lab Manualsanketwakde100Nessuna valutazione finora
- A Brief Introduction To PySpark. PySpark Is A Great Language For - by Ben Weber - Towards Data ScienceDocumento16 pagineA Brief Introduction To PySpark. PySpark Is A Great Language For - by Ben Weber - Towards Data ScienceJoshua WhiteNessuna valutazione finora
- Pandas OverviewDocumento4 paginePandas Overviewajonas69Nessuna valutazione finora
- PandasDocumento2 paginePandasAkash SinghNessuna valutazione finora
- Puppet Interview QuestionsDocumento5 paginePuppet Interview QuestionsAmitha R HNessuna valutazione finora
- Pandas - Data Analysis PaperDocumento9 paginePandas - Data Analysis PaperVFisaNessuna valutazione finora
- Analyzing Data Using Python Filtering Data in PandasDocumento52 pagineAnalyzing Data Using Python Filtering Data in Pandasmartin napangaNessuna valutazione finora
- Pandas PyDocumento2 paginePandas PyDavid Boateng (10888204)Nessuna valutazione finora
- Pandas PDFDocumento2.573 paginePandas PDFKarim KravchynskiyNessuna valutazione finora
- What Is Python?: Why Python For Data Science?Documento3 pagineWhat Is Python?: Why Python For Data Science?sabari balajiNessuna valutazione finora
- Python Libraries and Packages For Data ScienceDocumento5 paginePython Libraries and Packages For Data ScienceSayyad HabeebNessuna valutazione finora
- All in One CH 1 Data SeriesDocumento10 pagineAll in One CH 1 Data SeriesAshit ModyNessuna valutazione finora
- FDS Lab (Prin Out)Documento23 pagineFDS Lab (Prin Out)akshaya vijayNessuna valutazione finora
- Math 144 Fundamentals of Data Science: Name Score Nathaniel E. Alcancia Course/Section: Math 144/ A52 Date: 6/17/2020Documento3 pagineMath 144 Fundamentals of Data Science: Name Score Nathaniel E. Alcancia Course/Section: Math 144/ A52 Date: 6/17/2020Niel AlcanciaNessuna valutazione finora
- DAL EXT 1 and 2Documento125 pagineDAL EXT 1 and 2sahilNessuna valutazione finora
- Functional ProgrammingDocumento27 pagineFunctional Programmingalejandro gonzalezNessuna valutazione finora
- Numpy-User-1 10 1Documento107 pagineNumpy-User-1 10 1AliasNessuna valutazione finora
- DDI Book Chapter Tools and TechniquesDocumento13 pagineDDI Book Chapter Tools and TechniquesMuhammad AteeqNessuna valutazione finora
- Question AnswersDocumento8 pagineQuestion AnswersArtifical SmartNessuna valutazione finora
- Nothing Lasts Forever - Vish DhamijaDocumento220 pagineNothing Lasts Forever - Vish Dhamijarameshramyb67% (3)
- Bash Notes For ProfessionalsDocumento204 pagineBash Notes For ProfessionalsRichard Armando100% (1)
- Python ModulesDocumento14 paginePython Moduleskamalyeshodharshastry gattuNessuna valutazione finora
- OS BookDocumento72 pagineOS BookAupendu Kar100% (1)
- 6 Sections About 4 Hours of Testing Time: What Does Adaptive by Section Mean?Documento1 pagina6 Sections About 4 Hours of Testing Time: What Does Adaptive by Section Mean?kamalyeshodharshastry gattuNessuna valutazione finora
- 04 0+Introduction+to+MatplotlibDocumento7 pagine04 0+Introduction+to+Matplotlibkamalyeshodharshastry gattuNessuna valutazione finora
- Firebird 1.5 Error Codes: From MSG - Gbak, Release SourcesDocumento26 pagineFirebird 1.5 Error Codes: From MSG - Gbak, Release SourcesCleiton Luan GiehlNessuna valutazione finora
- UNIX NotesDocumento4 pagineUNIX NotesAnil Kumar PatchaNessuna valutazione finora
- Vmax Tdat Hypers CalculationDocumento17 pagineVmax Tdat Hypers Calculationshyco007Nessuna valutazione finora
- Bonus Tutorial Reorder Spec Tree v2Documento29 pagineBonus Tutorial Reorder Spec Tree v2David ChavesNessuna valutazione finora
- Infoblox CLI Guide: NIOS 6.1 For Infoblox Network Core Services AppliancesDocumento118 pagineInfoblox CLI Guide: NIOS 6.1 For Infoblox Network Core Services AppliancesPriyanto UkiNessuna valutazione finora
- 70-532 Sample Question AnswersDocumento10 pagine70-532 Sample Question AnswersbmsaliNessuna valutazione finora
- BA ZG523 Introduction To Data ScienceDocumento12 pagineBA ZG523 Introduction To Data ScienceClitt Orise100% (1)
- WebMethods SAP Adapter User's Guide - Software AG DocumentationDocumento314 pagineWebMethods SAP Adapter User's Guide - Software AG Documentationram GehlotNessuna valutazione finora
- Anurag Joshi: EducationDocumento1 paginaAnurag Joshi: EducationThe Cultural CommitteeNessuna valutazione finora
- Access Practical PolyDocumento2 pagineAccess Practical PolyShibya SamuelNessuna valutazione finora
- Attachment 1632883379Documento50 pagineAttachment 1632883379Om SheraniNessuna valutazione finora
- Structured Query LanguageDocumento48 pagineStructured Query LanguagePavith SinghNessuna valutazione finora
- ISTQB Latest Sample Paper 1Documento9 pagineISTQB Latest Sample Paper 1Kiran KumarNessuna valutazione finora
- Salesforce Admin Exam Study GuideDocumento9 pagineSalesforce Admin Exam Study GuideAferiat Aicha100% (1)
- Bugzilla Installation - LinuxDocumento30 pagineBugzilla Installation - LinuxAbhishek GuptaNessuna valutazione finora
- Oracle Data Integrator (ODI) : Sandrine Riley - Product Management, OracleDocumento51 pagineOracle Data Integrator (ODI) : Sandrine Riley - Product Management, OracleHerbertNessuna valutazione finora
- Env-Ts HectorDocumento2 pagineEnv-Ts HectorHECTOR BLANDONNessuna valutazione finora
- Servicenow: Csa ExamDocumento3 pagineServicenow: Csa ExamArifNessuna valutazione finora
- Business Partner in HANADocumento11 pagineBusiness Partner in HANAdeepankar senguptaNessuna valutazione finora
- ACT 4 Case StudyDocumento2 pagineACT 4 Case StudyoneinamillionnamedlunaNessuna valutazione finora
- Oracle Enterprise Asset ManagementDocumento68 pagineOracle Enterprise Asset ManagementMohmed Badawy100% (1)
- DBMS ProposalDocumento3 pagineDBMS ProposalmanognaNessuna valutazione finora
- ArchievingDocumento92 pagineArchievingKiran KagitapuNessuna valutazione finora
- Final PPT Online PharmacyDocumento22 pagineFinal PPT Online PharmacyPraveena P100% (1)
- JSP Standard Tag LibraryDocumento5 pagineJSP Standard Tag Librarysharkboy1983Nessuna valutazione finora
- Oracle Ebs SQL QueriesDocumento2 pagineOracle Ebs SQL Queriesmutthu_mh100% (1)
- Less04 Instance TB3Documento33 pagineLess04 Instance TB3yairrNessuna valutazione finora
- Cloudera QuickstartDocumento32 pagineCloudera QuickstartGabriel CaneNessuna valutazione finora
- Makerere University: College of Computing and Information ScienceDocumento5 pagineMakerere University: College of Computing and Information ScienceKasiimwe DeniseNessuna valutazione finora
- CH 8 - Desktop and Server OS VulnerabilitesDocumento69 pagineCH 8 - Desktop and Server OS VulnerabilitescoderNessuna valutazione finora
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDa EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldValutazione: 4.5 su 5 stelle4.5/5 (55)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewDa EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewValutazione: 4.5 su 5 stelle4.5/5 (104)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDa EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNessuna valutazione finora
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindDa EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNessuna valutazione finora
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziDa Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNessuna valutazione finora
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDa EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNessuna valutazione finora
- Generative AI: The Insights You Need from Harvard Business ReviewDa EverandGenerative AI: The Insights You Need from Harvard Business ReviewValutazione: 4.5 su 5 stelle4.5/5 (2)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Da EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Valutazione: 5 su 5 stelle5/5 (5)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceDa EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceValutazione: 5 su 5 stelle5/5 (5)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldDa EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldValutazione: 4.5 su 5 stelle4.5/5 (107)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkDa EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkValutazione: 4 su 5 stelle4/5 (7)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Da EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Valutazione: 4 su 5 stelle4/5 (1)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeDa EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeValutazione: 4.5 su 5 stelle4.5/5 (69)
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideDa EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideValutazione: 5 su 5 stelle5/5 (1)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepDa EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepValutazione: 4.5 su 5 stelle4.5/5 (19)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesDa EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesValutazione: 4.5 su 5 stelle4.5/5 (13)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Da EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Valutazione: 4 su 5 stelle4/5 (15)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceDa EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceValutazione: 4 su 5 stelle4/5 (2)
- Artificial Intelligence: A Guide for Thinking HumansDa EverandArtificial Intelligence: A Guide for Thinking HumansValutazione: 4.5 su 5 stelle4.5/5 (30)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceDa EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceValutazione: 4.5 su 5 stelle4.5/5 (38)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsDa EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNessuna valutazione finora