Documenti di Didattica
Documenti di Professioni
Documenti di Cultura
Estadística Descriptiva Con Excel 2016 y Megastat PDF
Caricato da
JanCa PLTitolo originale
Copyright
Formati disponibili
Condividi questo documento
Condividi o incorpora il documento
Hai trovato utile questo documento?
Questo contenuto è inappropriato?
Segnala questo documentoCopyright:
Formati disponibili
Estadística Descriptiva Con Excel 2016 y Megastat PDF
Caricato da
JanCa PLCopyright:
Formati disponibili
ESTADISTICA DESCRIPTIVA CON
EXCEL 2016 Y EL COMPLEMENTO
MEGASTAT
DAGOBERTO SALGADO HORTA
pág. 1 Dagoberto Salgado Horta
INTRODUCCIÓN
Según Allen (1996), Chao (1996), Yule y Kendal (1986) y Rivas González (1993) la
estadística es una ciencia (otros investigadores la consideran como un conjunto de
métodos) que se encarga de la recolección, clasificación, presentación,
organización, análisis e interpretación de un conjunto de fenómenos, (naturales,
económicos, políticos o sociales) de manera metódica y numérica, que permitan
extraer conclusiones de un hecho, en un momento determinado y así poder tomar
decisiones valederas. De acuerdo con la definición anterior la estadística se encarga
de la recolección, clasificación, análisis e interpretación de un conjunto de datos en
una investigación determinada. Según, algunos investigadores la estadística, es
una rama de las matemáticas que se ocupa de reunir, organizar y analizar datos
numéricos y que ayuda a resolver problemas como el diseño de experimentos y la
toma de decisiones. También, se puede decir que es una rama de las matemáticas
que utilizando un conjunto de métodos y técnicas se encarga de la recolección,
organizar, presentación, analizar e interpretación de datos naturales, económicos,
políticas, sociales, etc, para presentar los resultados obtenidos y sacar conclusiones
válidas basadas en dicho análisis y así poder tomar una decisión. La función
principal de la estadística es elaborar principios y métodos que ayuden a tomar
decisiones frente a la incertidumbre. En realidad, muchos autores definen la
estadística actualmente como un método de toma de decisiones frente a la
incertidumbre. La estadística puede presentar conclusiones referentes únicamente
al grupo estudiado, o puede generalizarlas para grupos mayores.
La estadística es una ciencia que soporta la mayoría de estudios en cualquiera de
los campos particulares de la ciencia. Decisiones empresariales, son apoyadas el
análisis estadístico, inferencias en todo tipo investigaciones de las diferentes áreas
del conocimiento y soporte de muchos análisis financieros, son algunos de sus
aportes. De la misma forma todas las ciencias se benefician del uso de la informática
para tener mayor rapidez en el desarrollo de sus procesos, la estadística como tal
no se escapa de esta influencia por los grandes volúmenes de información que se
manejan y por ello en el mercado se presentan diferentes softwares estadísticos.
No obstante, aun con la existencia de muchos programas estadísticos, la gran
mayoría presentan inconvenientes por altos costos en sus licencias.
Es por ello que se ha pensado en una herramienta de fácil acceso y manejo de
datos como lo es la plantilla cálculo Excel 2016 y el complemento Megastat
programado por el Doctor Orris para solucionar estos inconvenientes.
El libro explica detalladamente la utilización de plantillas de cálculo de Microsoft
Excel en técnicas estadísticas básica en la investigación, como también el manejo
de la macro Megastat como complemento a la misma hoja de cálculo.
En la mayoría de las explicaciones se toma como referencia la base de datos
correspondiente a una encuesta realizada a 500 trabajadores de una empresa que
llamaremos ABC, y que se puede bajar en el siguiente link:
http://www.estadisticacondago.com/index.php/aplicaciones-excel-mainmenu-101
pág. 2 Dagoberto Salgado Horta
Esta base de datos contiene información de 500 empleados de la empresa ABC, en 10
variables como son:
SEXO = sexo del empleado
EDAD = edad del empleado, expresada en años
EDUCACION = años de educación
FUNCION = función que ocupa dentro de la empresa
SALARIO = salario anual (miles de pesos)
SERVICIO = años de servicio
EXPERIENCIA = experiencia (años)
ESTADO = estado civil del empleado
HIJOS = número de hijos del empleado
ESTRATO = estrato social del empleado
pág. 3 Dagoberto Salgado Horta
1. CONCEPTOS FUNDAMENTALES
1.1 CONCEPTO DE ESTADÍSTICA Y SU CLASIFICACION
Estadística: se ocupa de los métodos y procedimientos para recoger, clasificar,
resumir, hallar regularidades y analizar los datos, siempre y cuando la variabilidad
e incertidumbre sea una causa intrínseca de los mismos; así como de realizar
inferencias a partir de ellos, con la finalidad de ayudar a la toma de decisiones y en
su caso formular predicciones.
Podríamos por tanto clasificar la Estadística en descriptiva, cuando los resultados
del análisis no pretenden ir más allá del conjunto de datos, e inferencial cuando el
objetivo del estudio es derivar las conclusiones obtenidas a un conjunto de datos
más amplio.
Clasificación de la Estadística
Estadística Ciencia que recoge y organiza datos de forma
sistemática. Datos numéricos sistemáticamente
recolectados y organizados.
Estadística descriptiva Organización de los datos en tablas y gráficas. Se
encarga de establecer los parámetros que definen
una población.
Estadística matemática Comparación de medidas calculadas mediante
distribuciones de probabilidades:
Estadística no Pruebas estadísticas aplicadas cuando se supone
paramétrica que los datos "no" se distribuyen normalmente.
Estadística paramétrica Pruebas estadísticas aplicadas cuando se supone
que los datos se distribuyen normalmente.
Población: Conjunto de individuos u objetos de interés o medidas obtenidas a partir
de todos los individuos u objetos de interés.
pág. 4 Dagoberto Salgado Horta
Muestra: Porción o parte de la población de interés. También se puede decir que
es una colección de unidades de muestreo seleccionados de un marco muestral o
de varios marcos muestrales. Al número de elementos de la muestra se denota por
“n”. Una muestra tiene las siguientes características:
a. Es representativa.
b. Es adecuada.
Para la determinación del tamaño de muestra se utilizan técnicas de muestreo
donde dependiendo de esta, se utiliza correctamente las fórmulas adecuadas.
Muestreo: Es una técnica estadística por la cual se realizan inferencias o
generalizaciones para una población examinando solo una muestra de ella. Es una
técnica empleada para seleccionar elementos de una población.
Su propósito es proporcionar diferente tipo de información estadística de naturaleza
cuantitativa o cualitativa. Por su gran importancia los investigadores lo utilizan en
los diferentes campos de saber y también lo usamos en la vida diaria.
Unidad de estudio: Es el animal persona o cosa de quien se dice algo. Es el
elemento quien nos va a dar la información. Es el individuo u objeto del cual se
toman las mediciones u observaciones.
Ejemplos: Un docente, un auxiliar de educación, un votante, una factura, una
empresa, una botella de cerveza, una universidad, una vaca, una gota de sangre,
etc.
Observaciones: Estadísticamente son los datos que se recolectan para un estudio.
Una observación o dato es cuando una variable en sí toma un valor específico.
Variables: Las variables son magnitudes que pueden tener un valor cualquiera de
los comprendidos en un conjunto de valores de un estudio o investigación
determinada. Son todos aquellos datos u observaciones que pueden ser
expresados mediante números, es decir, son características de una población
determinada, susceptible de medición.
Tipos de variables: Existen dos tipos básicos de variables: 1) cualitativas y 2)
cuantitativas. Cuando la característica que se estudia es de naturaleza no numérica,
recibe el nombre de variable cualitativa o atributo. Algunos ejemplos de variables
cualitativas son el sexo del empleado, función que ocupa dentro de la empresa,
estado civil del empleado, estrato social del empleado. Cuando la variable que se
estudia aparece en forma numérica, la variable se denomina variable cuantitativa.
Ejemplos de variables cuantitativas son edad del empleado expresada en años,
años de educación, salario anual (miles de pesos), años de servicio, experiencia
(años), número de hijos del empleado. Las variables cuantitativas pueden ser
discretas o continuas. Las variables discretas adoptan sólo ciertos valores y
existen vacíos entre ellos. Ejemplos de variables discretas son años de educación,
número de hijos del empleado. Las observaciones de una variable continua toman
cualquier valor dentro de un intervalo específico. Ejemplos de variables continuas
son edad del empleado expresada en años, salario anual (miles de pesos), años de
servicio, experiencia (años).
pág. 5 Dagoberto Salgado Horta
Niveles de medición: Los datos se clasifican por niveles de medición. El nivel de
medición de los datos rige los cálculos que se llevan a cabo con el fin de resumir y
presentar los datos. También determina las pruebas estadísticas que se deben
realizar. Existen cuatro niveles de medición: nominal, ordinal, de intervalo y de
razón. La medición más baja, o más primaria, corresponde al nivel nominal. La más
alta, o el nivel que proporciona la mayor información relacionada con la observación,
es la medición de razón. En el caso del nivel nominal de medición, las
observaciones acerca de una variable cualitativa sólo se clasifican y cuentan. No
existe una forma particular para ordenar las categorías. El nivel inmediato superior
de datos es el nivel ordinal, sus categorías requieren de un orden, sin embargo, no
es posible distinguir la magnitud de las diferencias entre los grupos. El nivel de
intervalo de medición es el nivel inmediato superior. Incluye todas las
características del nivel ordinal, pero, además, la diferencia entre valores constituye
una magnitud constante, la razón entre dos números no es significativa y el punto
cero no tiene sentido. El nivel de razón es el más alto. Posee todas las
características del nivel de intervalo, aunque, además, el punto 0 tiene sentido y la
razón entre dos números es significativa.
pág. 6 Dagoberto Salgado Horta
2. DISTRIBUCION DE FRECUENCIA
El Análisis Exploratorio de datos, antiguamente llamado Estadística Descriptiva,
constituye lo que la mayoría de las personas entiende como Estadística, e
inconscientemente se usa a diario. Consiste en resumir y organizar los datos
colectados a través de tablas, gráficos o medidas numéricas, y a partir de los datos
resumidos buscar alguna regularidad o patrón en las observaciones (interpretación
de los datos).
2.1. Distribución de Frecuencias
Cuando la información que se tiene es un gran volumen, resulta muy conveniente
ordenar y agrupar los datos para manejarlos de acuerdo a la distribución de
frecuencias la cual consiste en agrupar los datos por categorías para variables
cualitativas o en clases que estarán definidas por un límite mínimo y uno máximo
de variación, mostrando en cada clase el número de elementos que contiene o sea
la frecuencia.
La ordenación de datos en cuadros estadísticos, denominada forma tabular o
tabulación, están constituidos por datos cuantitativos y éstos a su vez están en filas
y columnas de acuerdo con las especificaciones de los datos. La tabulación es una
presentación sistemática de los datos estadísticos de una investigación
determinada, estos se presentan en forma resumida a través de las tablas o cuadros
estadísticos.
Cuadros estadísticos: Son esquemas organizados en los que se registran los
datos estadísticos en forma organizada con la frecuencia de cada uno de estos, los
mismos se observan en columnas y filas con la finalidad de presentar la información
recopilada de una investigación o estudio determinado. Por lo tanto, los cuadros
estadísticos es una ordenación de datos numéricos en filas y columnas con las
especificaciones correspondientes acerca de la naturaleza de los datos. Constituye
una forma útil de presentar los datos estadísticos obtenidos en una investigación a
través de cuadros, tablas y gráficos. Esta puede presentar la información para
referencias generales o para un uso específico o particular.
Los cuadros estadísticos están compuestos por las siguientes partes:
título: ¿Qué son los datos incluidos en el cuerpo de la tabla?, ¿Dónde está el área
representada por los datos?, ¿Cómo están los datos clasificados?, ¿Cuándo
ocurrieron los datos?
Concepto o Columnas Matriz: La descripción en hilera de la tabla son llamados
conceptos; y estos son colocados al lado izquierdo de la tabla. La naturaleza de las
clasificaciones es indicada por los encabezados de las columnas, incluyendo la
columna matriz.
pág. 7 Dagoberto Salgado Horta
Cuerpo del cuadro: El cuerpo del cuadro es la parte que contiene los datos
estadísticos presentados en éste. Cada dato individual ocupa en el cuadro un lugar
que corresponde a la intersección de una fila y una columna dada; por tanto, el
significado de los datos en un lugar está indicado por las especificaciones o partidas
combinadas de la columna y la fila que se interceptan.
Fuentes: Las fuentes de datos o simplemente fuentes, es usualmente escrita
debajo de las notas de pie. Si los datos fueron recopilados y presentados por la
misma persona, es costumbre no establecer la fuente en la tabla. El objeto de la
indicación de las fuentes de los datos es el de proporcionar el debido reconocimiento
a la persona u organismo que recopiló y /o publicó los datos, además de indicar, a
quienes deseen ampliar la información, el origen de la misma.
2.2. Representación Gráfica
El patrón de variación de los datos puede apreciarse mejor representando
gráficamente la información contenida en el cuadro. Son expresiones en forma de
figura, de información originada de un conjunto de datos estadísticos, que explican
un fenómeno determinado. Son descripciones de operaciones y demostraciones
que se representan por medio de figuras o signos, los mismos se realizan con los
valores de los cuadros estadísticos. En otras palabras, es una representación de la
relación entre variables, que se realiza en un plano determinado.
El fin que persigue todo gráfico es el de dar una idea rápida de la situación que en
ese momento se está investigando. Por tal motivo, la presentación de los datos por
medio de gráficos debe ser de una forma simple y de una compresión fácil. Es
preferible construir un conjunto de gráficos en donde cada uno de ellos presente un
aspecto sencillo de una situación determinada, que presentar un solo gráfico en el
cual se observen demasiadas relaciones que se haga difícil estudiar de una forma
efectiva. Por lo tanto, no debe sobrecargarse un gráfico para tratar de mostrar
demasiadas categorías, ya que, la simplicidad es una de la característica básica de
estos.
Partes de un gráfico estadístico
• Numeración.
• Título: Aquí se señala la población en estudio y la variable de interés.
• Diagrama: está dado por el propio dibujo, el cual representa el
comportamiento de los datos.
• Escalas y/o leyendas: Son indicadores donde se precisa la correspondencia
entre los elementos del gráfico y la naturaleza de las medidas representadas.
• Fuente: Aquí se señala el cuadro de frecuencias que permitió obtener el
respectivo gráfico.
pág. 8 Dagoberto Salgado Horta
Criterios para construir gráficos
• No existe una regla específica para la construcción de gráficos, pero si es
posible considerar algunas recomendaciones o criterios.
• Se emplea una diversidad de gráficos, cuya estructura o forma dependerá
del tipo de variable que se está estudiando.
• Este gráfico debe tener rasgos simples y de fácil comprensión.
Existe una gran variedad de tipos de gráficos entre los que se pueden mencionar
los pictogramas, cartogramas, de cuadrados, de triángulos y círculos
proporcionales, de sectores circulares, de barras, lineales, estereogramas, polares,
etc., pero los más utilizados y de interpretación sencilla son los: Los gráficos de
barras, los de sectores circulares y los lineales. Solo se estudiarán las siguientes
gráficas:
1.- Diagrama de Líneas.
2.- Diagrama de Barras.
3.- Diagrama Circular o de Pastel.
4.- Histograma.
5.- Polígono de Frecuencia.
6.- Polígono Acumulativo (OJIVA).
Los diagramas de líneas, el histograma, el polígono de frecuencia y la ojiva son
gráficos cartesianos porque para su construcción requieren del plano cartesiano, a
estos se le denominan en términos generales gráficos de líneas. El diagrama de
barras y el de pastel se les denomina gráficos de sectores, puesto que, no requieren
del plano cartesiano para su construcción.
Cabe aclarar que tanto las tablas como los gráficos deben acatar las órdenes según
el tipo de norma con las que se trabaje, ya sea Icontec, Apa, Vancouver, etc.
El objetivo que corresponde ahora es presentar los principales procedimientos de
Análisis Exploratorio de datos, en cuanto a su parte tabular y gráfica, para algunas
de las distintas variables de la base de datos mencionada anteriormente, tanto en
la plantilla de cálculo Excel, como en el complemento Megastat.
Los procedimientos fueron realizados utilizando Microsoft Excel 2016, aunque son
Muy parecidos a los de otras versiones de esta hoja de cálculo de Microsoft Office.
2.3. Instrucciones para las variables cualitativas
pág. 9 Dagoberto Salgado Horta
Cuando se quiere realizar un análisis descriptivo en donde únicamente se toman
variables cualitativas, lo más habitual es construir tablas de frecuencia para cada
variable individualmente, o tablas de contingencia relacionando dos variables. Los
gráficos pueden ser creados a partir de las tablas. Para las variables cualitativas en
Excel 2016 necesitamos utilizar las tablas dinámicas.
2.3.1. Tabla de frecuencia y gráficos de la variable ESTADO (cualitativa
nominal)
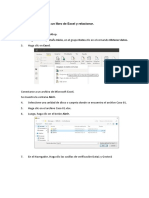
a) en la barra de menú seleccione insertar Tabla dinámica, vea la Figura 1.
Figura 1 Insertar Tabla dinámica
b) escoja la opción Tabla o rango y seleccione toda la base de datos (A1:J501)
incluyendo los nombres de las variables (etiquetas). Figura 2
Figura 2 Crear Tabla dinámica
pág. 10 Dagoberto Salgado Horta
c) Elija dónde desea colocar el informe de tabla dinámica (nueva hoja de cálculo
o hoja de cálculo existente), por defecto escogemos hoja de cálculo existente
y seleccione aceptar, aparece la apariencia de la Figura 3
Figura 3 Campos de la Tabla dinámica
Observe a la derecha los nombres de las variables existentes en el archivo de datos,
y que fueron seleccionados en el paso anterior. Como existe interés únicamente en
la variable ESTADO debemos seleccionarla e inmediatamente aparece en el campo
FILA. Las otras variables no formarán parte de la tabla. Debemos arrastrar también
la variable ESTADO para el campo VALORES. Eso es necesario para especificar la
acción que la tabla deberá ejecutar. La acción a realizar es el conteo de los valores,
tal como es mostrado en la Figura 4.
pág. 11 Dagoberto Salgado Horta
Figura 4 Tabla dinámica de la variable ESTADO
Cabe precisar que esta tabla como su nombre lo indica queda de forma dinámica,
de tal manera que seleccionando la pestaña al lado derecho de la palaba ESTADO,
podemos escoger las categorías que deseemos. Ahora si se quiere a partir de ella
generar una tabla más completa con sus respectivas frecuencias relativas, la
copiamos y la pegamos en otro especio cualquiera de la hoja de cálculo, y se
procede a generar los porcentajes de la siguiente forma:
Seleccionamos la tabla dinámica y la pegamos más abajo (en nuestro ejemplo a
partir de la celda M18). Figura 5, en las celdas N18 y O18, escribimos
respectivamente ni (frecuencia absoluta) y hi% (frecuencia relativa). Ahora en la
celda O19 escribimos la siguiente formula: =N19/$N$24, y la copiamos para las
demás celdas hasta la O24.
pág. 12 Dagoberto Salgado Horta
Figura 5 Generación Tabla de frecuencias variable ESTADO
Finalmente, la tabla de frecuencias para la variable nominal ESTADO con su
respectivo título será:
Tabla No 1: Distribución de frecuencias del estado civil de 500 empleados de
la empresa ABC. Ibagué agosto 2016.
ESTADO ni hi%
Casado 95 19%
Separado 104 21%
Soltero 105 21%
Unión Libre 93 19%
Viudo 103 21%
Total general 500 100%
A partir de los resultados de la tabla dinámica, es posible también construir gráficos.
Para realizar esta actividad, se selecciona la tabla dinámica, parándose en la celda
donde está la palabra ESTADO. En la barra de menú seleccionamos insertar
Columna en 2-D, y en el cuadro de despliegue seleccionamos el gráfico adecuado
(en nuestro caso las barras simples) Figura 6. Parados en la gráfica se puede ir a
diseño rápido y mejorarla. También se puede modificar una serie de aspectos en su
pág. 13 Dagoberto Salgado Horta
apariencia, tales como escala, colores, títulos, entre otras. Se puede cambiar el tipo
de gráfico seleccionando el mismo y escogiendo la herramienta “Cambiar tipo de
gráfico” (por ejemplo, por un diagrama de sectores. Los gráficos generados son los
mostrados en la figura 6 y 7.
Figura 6 Generación de gráficos variable ESTADO
Grafica No 1: Diagrama de barras del estado civil de 500 empleados de la
empresa ABC. Ibagué agosto 2016.
pág. 14 Dagoberto Salgado Horta
Grafica No 2: Diagrama circular del estado civil de 500 empleados de la
empresa ABC. Ibagué agosto 2016.
Se puede de esta forma generar interpretaciones de la variable ESTADO. Por
ejemplo:
• Casi en proporciones iguales, el estado civil de los empleados de la empresa
ABC, se encuentra repartido para cada una de las diferentes categorías.
2.3.2. Tabla de frecuencia y gráficos de la variable ESTRATO (cualitativa
ordinal)
Siguiendo los mismos pasos de la variable ESTADO, y teniendo cuidado en ordenar
las categorías (bajo-medio-alto), se tabula y grafica la variable ESTRATO, la única
diferencia es que la tabla de distribución de frecuencia tiene dos nuevas columnas
(Ni y Hi%), frecuencia absoluta acumulada y frecuencia relativa acumulada
respectivamente. Para generar Ni, nos ubicamos para nuestro caso en la celda P21,
y colocamos la fórmula: =N21, luego desde la celda P22, escribimos: =P21+N22,
y arrastramos esta celda hasta la última frecuencia absoluta acumulada (P23), de
igual forma para generar Hi%, nos ubicamos en la celda Q21, y colocamos la
fórmula: =O21, luego desde la celda Q22, escribimos: =Q21+O22, y arrastramos
esta celda hasta la última frecuencia relativa acumulada (Q23). Ver Figura 7
pág. 15 Dagoberto Salgado Horta
Figura 7 Generación Tabla de frecuencias variable ESTRATO
La tabla de frecuencias para la variable nominal ESTRATO con su respectivo título
será:
Tabla No 2: Distribución de frecuencias del estrato social de 500 empleados
de la empresa ABC. Ibagué agosto 2016.
ESTRATO ni hi% Ni Hi%
Bajo 160 32% 160 32%
Medio 184 37% 344 69%
Alto 156 31% 500 100%
Total general 500 100%
Grafica No 3: Diagrama de barras para el estrato social de 500 empleados de
la empresa ABC. Ibagué agosto 2016.
pág. 16 Dagoberto Salgado Horta
184
160
156
Alto Bajo Medio
Grafica No 4: Diagrama de sectores para el estrato social de 500 empleados
de la empresa ABC. Ibagué agosto 2016.
Interpretación:
• Un 37% (184) de los 500 empleados de la empresa ABC de la ciudad de
Ibagué, pertenecen al estrato medio, mientras que aproximadamente por
proporciones iguales, los demás empleados pertenecen a los estratos bajo y
alto. En cuanto a las frecuencias acumuladas podemos decir que 344
empleados que corresponde a un 69%, tiene un estrato social bajo o medio.
pág. 17 Dagoberto Salgado Horta
2.3.3. Tabla de frecuencia y gráficos de la variable EDUCACION (cuantitativa
discreta)
Si la variable a analizar es discreta, por ejemplo, Años de Educación (EDUCACION)
en la planilla “base de datos”, el procedimiento puede ser semejante al utilizado para
la variable ESTRATO, sin embargo, al construir la tabla dinámica, Excel irá a
seleccionar “Suma de EDUCACION” como acción (porque los valores de la variable
son números), y se necesitará modificar eso para conteo de los valores, en
configuración de campo de valor: Cuenta de EDUCACION, siguiendo el
procedimiento que se ilustró en la Figura 4. Luego de realizar los ajustes necesarios,
se obtendrá la siguiente tabla dinámica:
Cuenta de EDUCACION
EDUCACION Total
8 54
12 201
14 6
15 125
16 63
17 11
18 9
19 28
20 2
21 1
Total general 500
Y la siguiente tabla de distribución de frecuencias:
Tabla No 3: Distribución de frecuencias de 500 empleados de la empresa ABC,
según los años que se han educado. Ibagué agosto 2016.
EDUCACION ni hi% Ni Hi%
8 54 10.8% 54 10.8%
12 201 40.2% 255 51.0%
14 6 1.2% 261 52.2%
15 125 25.0% 386 77.2%
16 63 12.6% 449 89.8%
17 11 2.2% 460 92.0%
18 9 1.8% 469 93.8%
19 28 5.6% 497 99.4%
20 2 0.4% 499 99.8%
21 1 0.2% 500 100%
Total general 500 100%
pág. 18 Dagoberto Salgado Horta
Las gráficas adecuadas para una variable cuantitativa discreta son el diagrama de
líneas verticales para las frecuencias no acumuladas (ni y hi%), y el diagrama de
líneas horizontales para las frecuencias acumuladas (Ni y Hi%). En el caso del
diagrama de líneas verticales, se puede generar un diagrama de barras simples,
como se explicó para las anteriores variables, pero por opciones de serie, llevar el
ancho del intervalo al máximo que es del 500%.
Grafica No 5: Diagrama líneas verticales para los años de educación de 500
empleados de la empresa ABC. Ibagué agosto 2016.
Excel no tiene la opción de graficar el diagrama de líneas horizontales para las
frecuencias acumuladas, pero aprovechando, la opción de bordes, un buen
acercamiento a este grafico es el siguiente:
Grafica No 6: Diagrama líneas horizontales para los años de educación de 500
empleados de la empresa ABC. Ibagué agosto 2016.
pág. 19 Dagoberto Salgado Horta
Interpretación:
• Esta variable nos puede informar por ejemplo que el 40.2%, correspondiente
a 201 empleados han tenido 12 años de educación, y tan solo el 6.2% (31
empleados), han estudiado entre 19 y 21 años.
• En cuanto a las frecuencias acumuladas, por ejemplo, el 93.8% (469
empleados), tienen máximo 18 años de educación.
2.3.4. Tabla de frecuencia y gráficos de la variable EDAD (cuantitativa
continua)
La disposición tabular de los datos estadísticos se encuentra ordenados en clases
y con la frecuencia de cada clase; es decir, los datos originales de varios valores
adyacentes del conjunto se combinan para formar un intervalo de clase. No existen
normas establecidas para determinar cuándo es apropiado utilizar datos agrupados
en clases o datos no agrupados en clases; sin embargo, se sugiere que cuando el
número total de datos (n) es igual o superior 50 y además el rango o recorrido de
la serie de datos es mayor de 20, entonces, se utilizará la distribución de frecuencia
para datos agrupados en clases, también se utilizará este tipo de distribución
cuando se requiera elaborar gráficos lineales como el histograma, el polígono de
frecuencia o la ojiva.
La razón fundamental para utilizar la distribución de frecuencia de clases es
proporcionar mejor comunicación acerca del patrón establecido en los datos y
facilitar la manipulación de los mismos. Los datos se agrupan en clases con el fin
de sintetizar, resumir, condensar o hacer que la información obtenida de una
investigación sea manejable con mayor facilidad.
Este tipo de distribución se basa en el principio de que una observación no puede
considerarse diferente de otra por presentar pequeñas diferencias cuantitativas,
como por ejemplo el sueldo mensual de dos empleados que difieran en 500 pesos,
de dos edades de personas adultas que difieran en un año, dos alturas de un edificio
que difieran en un metro, el costo de 2 autos nuevos que difieran en 5000 pesos,
etc.
Al agrupar los datos en una distribución de frecuencia de clase se pierde parte de
la información. La reducción o agrupamiento a que son sometidos los datos de una
serie de valores cuando existen muchos valores diferentes, originan los
denominados errores de agrupamiento; sin embargo, estos errores son en general
muy pequeños, razón por la cual la distribución de frecuencia de clase tiene una
validez estadística práctica.
pág. 20 Dagoberto Salgado Horta
2.3.4.1. Componentes de una distribución de frecuencia de clase
1.- Rango o Amplitud total (recorrido): Es el límite dentro del cual están
comprendidos todos los valores de la serie de datos, en otras palabras, es el número
de diferentes valores que toma la variable en un estudio o investigación dada. Es la
diferencia entre el valor máximo de una variable y el valor mínimo que ésta toma en
una investigación cualquiera. El rango es el tamaño del intervalo en el cual se ubican
todos los valores que pueden tomar los diferentes datos de la serie de valores,
desde el menor de ellos hasta el valor mayor estando incluidos ambos extremos. El
rango de una distribución de frecuencia se designa con la letra R.
Para obtener el rango, se tienen que identificar los extremos del conjunto de datos,
o sea, sus valores máximo y mínimo. Se iniciará por el mínimo. Seleccione una
celda donde desea que el resultado sea colocado: por ejemplo, la celda L2.
Seleccione esta celda con el cursor. Observe que en la barra de herramientas de
Excel hay un botón llamado Insertar función , vea la Figura 8.
Figura 8. Barra de herramientas de Excel: “Insertar función”
Si presiona surgirá la pantalla vista en la Figura 9.
pág. 21 Dagoberto Salgado Horta
Figura 9. Funciones disponibles en Excel
Se puede seleccionar una categoría, y en la parte inferior se encuentran las
funciones disponibles, con una breve descripción de cada una de ellas. Una de las
categorías se llama: “Usadas recientemente”, que registra las últimas funciones
aplicadas por el usuario, en cualquier planilla. Estamos especialmente interesados
en las categorías “Matemáticas y trigonométricas”, “Lógicas” y, obviamente
“Estadísticas”. Las funciones MAX y MIN se encuentran en esta última categoría.
Seleccionando “Estadísticas” vamos a obtener el resultado de la Figura 10.
Figura 10. Funciones Estadísticas
Luego de seleccionar “Estadística”, basta buscar la función MIN: y observe la
descripción en la parte inferior. También se puede pedir ayuda a Excel sobre la
pág. 22 Dagoberto Salgado Horta
descripción detallada de las funciones. Buscando detenidamente, se encontrarán
otras funciones estadísticas muy útiles en el análisis de una variable cuantitativa.
Una vez seleccionada la función y escogida la variable “EDAD”, (B1:B501), basta
presionar ACEPTAR y para el caso de MIN se tendrá:
Figura 11. Función MIN
El mismo resultado podría ser obtenido simplemente digitando la fórmula
directamente en la celda: =MIN(E2:E475) . Pueden ser utilizadas mayúsculas o
minúsculas.
Para encontrar el valor máximo se puede realizar un proceso análogo utilizando la
función MAX, pero colocando el resultado en otra celda, L3 por ejemplo. Para
calcular el rango se puede colar una fórmula en la celda L4, haciendo la sustracción
entre máximo y mínimo. Los resultados pueden observarse a continuación:
EDAD
Mínimo 29.83836
Máximo 71.86575
Rango 42.0274
Figura 12. Rango de la variable EDAD
La menor edad es 29,84 y la mayor de 71,87, resultando en un rango de 42,03
aproximando a dos decimales. Este rango es el que se necesita para la construcción
de la distribución en clases del conjunto de datos.
pág. 23 Dagoberto Salgado Horta
2.- Dividir el rango en un número conveniente de clases: Usualmente se define el
número de clases (m), utilizando la ecuación de Sturges, m = 1+3.33 * log 10 (n), como en
nuestro caso n = 500 empleados, tenemos que el número de clases es aproximadamente
igual a 10. De acuerdo a esto, la amplitud (o ancho de clase) sería igual al cociente entre el
rango y el número de clases (R/m), dando como resultado, A = 4,203, esta amplitud la
aproximamos a dos decimales (con este formato se está trabajando) por exceso, es decir,
4,21. Inmediatamente y para corregir dicha aproximación, redefinimos el rango, el mínimo
y el máximo de la siguiente manera:
R” = A x m = 4,21 x 10 = 42,1
R” – R = 42,1 – 42,03 = 0,07
Esta diferencia la dividimos en dos números los más equitativos, pero con dos decimales,
para mantener el formato, es decir 0,03 y 0,04, uno de estos números lo restamos del
mínimo y el otro se lo sumamos al máximo, lo cual quedaría:
Mínimo redefinido = 29,84 – 0,03 =29,81
Máximo redefinido = 71,87 + 0,04 =71,91
3.- Generación de intervalos, marca de clase y frecuencias: Ahora en Excel
Colocamos las convenciones que aparecen en la tabla. Para ello escogemos unas
celdas vacías, por ejemplo, de K13 a Q13. Figura 14
Li: Límite inferior
Ls: Límite superior
Yi: Marca de clase
ni: Frecuencia absoluta
hi%: Frecuencia relativa
Ni: Frecuencia absoluta acumulada
Hi%: Frecuencia relativa acumulada
En K14, colocamos el mínimo redefinido (29,81) y en L14, escribimos la fórmula
=K14+4.21 que es el valor de la amplitud, luego en la celda K15 escribimos =L14,
posteriormente arrastramos las celdas K15 y L15, hasta K23 y L23, completando de
esta manera las diez clases donde se distribuirán las edades de los 500 empleados.
Ahora las marcas de clase utilizan la siguiente fórmula: Yi = (Li + Ls)/2. Desde la
celda M14, escribimos: =(K14+L14)/2, y ubicados en la misma celda, la arrastramos
Hasta M23.
pág. 24 Dagoberto Salgado Horta
Figura 12. Función frecuencia
Para la frecuencia absoluta (ni), se selecciona el rango desde la celda N14 a N23,
se presiona y surgirá la pantalla vista en la Figura 12. Escogemos la función
frecuencias, y damos aceptar. Aparece el cuadro de la figura 13 “Argumentos de
función”.
Figura 13. Argumentos de la función frecuencia
En datos seleccionamos la variable EDAD (B1:B501), y en grupos el rango de los límites
superiores del intervalo (L14:L23), no oprimimos aceptar, se oprimen las teclas
CTRL+MAYÚS+Entrar a la vez, de lo contrario solo se mostrará el valor de la celda
N14. El mismo resultado podría ser obtenido simplemente digitando la fórmula
pág. 25 Dagoberto Salgado Horta
directamente en la celda: =FRECUENCIA(B1:B501;L14:L23), previa selección del
rango desde la celda N14 a N23 . Pueden ser utilizadas mayúsculas o minúsculas.
Para las demás frecuencias se repite el mismo procedimiento de la variable discreta.
Figura 14. Generación Tabla de frecuencias variable EDAD
Finalmente, la tabla de distribución de frecuencias con su respectivo título será:
Tabla No 4: Distribución de frecuencias de 500 empleados de la empresa ABC,
según la edad en años. Ibagué agosto 2016.
Li Ls Yi ni hi% Ni Hi%
29.81 34.02 31.92 83 16.6% 83 16.6%
34.02 38.23 36.13 142 28.4% 225 45.0%
38.23 42.44 40.34 87 17.4% 312 62.4%
42.44 46.65 44.55 21 4.2% 333 66.6%
46.65 50.86 48.76 27 5.4% 360 72.0%
50.86 55.07 52.97 33 6.6% 393 78.6%
55.07 59.28 57.18 29 5.8% 422 84.4%
59.28 63.49 61.39 29 5.8% 451 90.2%
63.49 67.7 65.60 26 5.2% 477 95.4%
67.7 71.91 69.81 23 4.6% 500 100.0%
TOTAL 500 100.0%
pág. 26 Dagoberto Salgado Horta
Esta tabla puede ser usada para construir un histograma. Seleccionando los
intervalos de la tabla, pero cada intervalo en una sola celda, la frecuencia absoluta
(ni), escogiendo el gráfico de columnas, y reduciendo el ancho del intervalo a cero,
entre otros ajustes, tal como se muestra en la Figura 15.
Intervalos ni
29.81 - 34.02 83
34.02 - 38.23 142
38.23 - 42.44 87
42.44 - 46.65 21
46.65 - 50.86 27
50.86 - 55.07 33
55.07 - 59.28 29
59.28 - 63.49 29
63.49 - 67.70 26
67.70 - 71.91 23
Figura 15. Tabla para generar el histograma de la variable EDAD
Grafica No 7: Histograma de frecuencias para los años de educación de 500
empleados de la empresa ABC. Ibagué agosto 2016.
Si se selecciona el grafico y se escoge la opción Diseño – Cambiar tipo de gráfico
– Gráficos recomendados – Línea, se puede obtener el polígono. Figura 15
pág. 27 Dagoberto Salgado Horta
Figura 16. Generación del polígono de frecuencias para la variable EDAD
Grafica No 8: Polígono de frecuencias para los años de educación de 500
empleados de la empresa ABC. Ibagué agosto 2016.
Ahora con la tabla que se muestra en la Figura 17, se puede construir la ojiva.
Seleccionando los intervalos de la tabla, pero cada intervalo en una sola celda, la
frecuencia absoluta acumulada (Ni), escogiendo el gráfico de líneas con
marcadores, y realizando los ajustes necesarios.
pág. 28 Dagoberto Salgado Horta
Intervalos Ni
29.81 - 34.02 83
34.02 - 38.23 225
38.23 - 42.44 312
42.44 - 46.65 333
46.65 - 50.86 360
50.86 - 55.07 393
55.07 - 59.28 422
59.28 - 63.49 451
63.49 - 67.70 477
67.70 - 71.91 500
Figura 17. Tabla para generar la ojiva de la variable EDAD
Grafica No 9: Ojiva de frecuencias para los años de educación de 500
empleados de la empresa ABC. Ibagué agosto 2016.
Algunas interpretaciones:
• 142 empleados que corresponden al 28.4%, tiene una edad comprendida
entre 34,02 y 38,23 años, con un promedio de 36,13 años.
• 393 empleados que corresponden al 78.6%, tiene una edad máxima de 55,07
años.
2.3.5. Tabla de frecuencia bidimensional (contingencia) y gráfico de la
variable FUNCION vs ESTADO (2 variables cualitativas)
pág. 29 Dagoberto Salgado Horta
El procedimiento es similar al descrito en el inciso 2.3.1, pero ahora serán
utilizadas dos variables, teniendo como propósito construir una tabla de
contingencia. Las instrucciones descritas en las literales a) a la c) del inciso
2.3.1 pueden ser repetidas literalmente. Las diferencias comienzan a aparecer
cuando se hace el diseño de la tabla. Se arrastra una de las dos variables a
FILAS, la otra a COLUMNAS, y cualquiera de las dos a ∑ VALORES, como lo
indica la figura 18.
Figura 18. Tabla dinámica de contingencia para las variables FUNCION vs
ESTADO
La tabla de frecuencias absoluta bidimensional con su respectivo título será:
Tabla No 5: Distribución de frecuencias de la función de desempeño vs el
estado civil de 500 empleados de la empresa ABC. Ibagué agosto 2016.
Cuenta de FUNCION ESTADO
FUNCION Casado Separado Soltero Unión Libre Viudo Total general
Gerencia 9 24 18 20 17 88
Oficina 79 73 80 69 84 385
Servicios Generales 7 7 7 4 2 27
Total general 95 104 105 93 103 500
Si cada celda se divide por el tamaña de muestra (500), y se le da el formato
porcentaje, se obtiene la tabla de frecuencias relativa bidimensional.
pág. 30 Dagoberto Salgado Horta
Tabla No 6: Distribución de frecuencias porcentual de la función de
desempeño vs el estado civil de 500 empleados de la empresa ABC. Ibagué
agosto 2016.
ESTADO
FUNCION Casado Separado Soltero Unión Libre Viudo Total general
Gerencia 1.8% 4.8% 3.6% 4.0% 3.4% 17.6%
Oficina 15.8% 14.6% 16.0% 13.8% 16.8% 77.0%
Servicios Generales 1.4% 1.4% 1.4% 0.8% 0.4% 5.4%
Total general 19.0% 20.8% 21.0% 18.6% 20.6% 100%
Grafica No 10: Diagrama de barras compuestas de la función de desempeño
vs el estado civil de 500 empleados de la empresa ABC. Ibagué agosto 2016.
Grafica No 11: Diagrama de barras apiladas de la función de desempeño vs el
estado civil de 500 empleados de la empresa ABC. Ibagué agosto 2016.
pág. 31 Dagoberto Salgado Horta
Algunas interpretaciones:
• De los 500 empleados de la empresa ABC, 80 que corresponden al 16%,
trabajan en oficina y son solteros.
• De los 500 empleados de la empresa ABC, 17 que corresponden al 3.4%,
son gerentes y actualmente se encuentran viudos.
2.4. Ejercicios
1. Elaborar las tablas y graficas con sus respectivos títulos e interpretaciones,
de las siguientes variables, correspondientes a la plantilla “base de datos”.
SEXO, = edad del empleado, expresada en años
FUNCION = función que ocupa dentro de la empresa
SALARIO = salario anual (miles de pesos)
SERVICIO = años de servicio
EXPERIENCIA = experiencia (años)
ESTRATO = estrato social del empleado
Para el caso bidimensional, cruce las variables FUNCION vs ESTRATO
2. Clasifica las siguientes variables como cualitativas o cuantitativas, y a estas
últimas como continuas o discretas. Identifique su escala de medición.
a) Intención de voto de un colectivo
b) Nº de cartas que se escriben en un mes
c) Número de calzado
pág. 32 Dagoberto Salgado Horta
d) Nº de Km. recorrido en un fin de semana
e) Marcas de cerveza
f) Nº de empleados de una empresa
g) Altura
h) Temperatura de un enfermo
3. Muchas de las personas que invierten en bolsa lo hacen para conseguir
beneficios rápidos, por ello el tiempo en que mantienen las acciones es
relativamente breve. Preguntada una muestra de 40 inversores habituales
sobre el tiempo en meses que han mantenido sus últimas inversiones se
recogieron los siguientes datos
10.5 11.2 9.9 15.0 11.4 12.7 16.5 10.1 12.7 11.4
11.6 6.2 7.9 8.3 10.9 8.1 3.8 10.5 11.7 8.4
12.5 11.2 9.1 10.4 9.1 13.4 12.3 5.9 11.4 8.8
7.4 8.6 13.6 14.7 11.5 11.5 10.9 9.8 12.9 9.9
Construye una tabla de frecuencias que recoja adecuadamente esta información, y
haz también alguna representación gráfica.
4. Investigados los precios por habitación de 50 hoteles de una ciudad se han
obtenido los siguientes resultados
700 300 500 400 500 700 400 750 800 500
500 750 300 700 1000 1500 500 750 1200 800
400 500 300 500 1000 300 400 500 700 500
300 400 700 400 700 500 400 700 1000 750
700 800 750 700 750 800 700 700 1200 800
Determínese:
a) La distribución de frecuencias de los precios.
b) Porcentaje de hoteles con un precio superior a 750.
c) Cuántos hoteles tienen un precio mayor o igual que 500 pero menor o igual
a 1000.
d) Representar gráficamente dichas distribuciones.
pág. 33 Dagoberto Salgado Horta
5. El gobierno desea saber si el número medio de hijos por familia ha
descendido respecto a la década anterior. Para ello ha encuestado a 50
familias respecto al número de hijos y ha obtenido los siguientes datos:
2 4 2 3 1 2 4 2 3 0 2 2 2 3 2 6 2 3 2 2 3 2 3 3 4
3 3 4 5 2 0 3 2 1 2 3 2 2 3 1 4 2 3 2 4 3 3 2 2 1
a) Construye la tabla de frecuencias a partir de estos datos.
b) ¿Cuántas familias tienen exactamente tres hijos?
c) ¿Qué porcentaje de familias tienen exactamente 3 hijos?
d) ¿Qué porcentaje de las familias de la muestra tienen más de dos hijos?
¿Y menos de 3?
e) Construye el grafico que consideres más adecuado con las frecuencias
no acumuladas
f) Construye el gráfico que consideres más adecuado con las frecuencias
acumuladas.
6. En un hospital se desea hacer un estudio sobre los pesos de los recién
nacidos. Para ello, se recogen los datos de 40 bebes y se tiene:
3.2 3.7 4.2 4.6 3.7 3.0 2.9 3.1 3.0 4.5
4.1 3.8 3.9 3.6 3.2 3.5 3.0 2.5 2.7 2.8
3.0 4.0 4.5 3.5 3.5 3.6 2.9 3.2 4.2 4.3
4.1 4.6 4.2 4.5 4.3 3.2 3.7 2.9 3.1 3.5
Se pide:
a) Construir la tabla de frecuencias
b) Si sabemos que los bebes que pesan menos de 3 kilos nacen
prematuramente ¿Qué porcentaje de niños prematuros han nacido entre
estos 40?
c) Normalmente los niños que pesan más de 3 kilos y medio no necesitan
estar en la incubadora ¿Puedes decirme que porcentaje de niños están en
esta situación?
d) Representa gráficamente la información recogida
7. En una finca de apartamentos en el Tolima, se reúne la comunidad de
vecinos para ver si contratan una persona que les lleve la contabilidad. El
resultado de la votación es el siguiente: 25 vecinos a favor de la contratación,
pág. 34 Dagoberto Salgado Horta
15 vecinos en contra y 5 vecinos se abstienen. Construye la tabla de
frecuencias para estos datos y representa gráficamente la información
recogida mediante un diagrama de sectores.
pág. 35 Dagoberto Salgado Horta
3. ESTADISTICOS
Son medidas de resumen que se calculan dentro de las muestras. Se clasifican en:
a) Medidas de posición
b) Medidas de dispersión
c) Medidas de forma
d) Medidas de concentración
3.1. Medidas de posición: El análisis estadístico de una serie de datos se elabora
mediante el cálculo de diferentes estadísticos. Después que los datos han sido
reunidos y tabulados, se inicia el análisis con el fin de calcular un número único, que
represente o resuma todos los datos. Por lo general, las frecuencias de los
intervalos centrales de una serie de datos son mayores que el resto, ese número se
le denomina medida de posición. Una medida de posición es un número que se
escoge como orientación para hacer mención a un grupo de datos. Uno de los
problemas fundamentales que presenta un análisis estadístico, es el de buscar el
valor más representativo de una serie de valores. El primer paso que hay que
realizar para que se entienda una larga serie de valores u observaciones, es el de
resumir los datos en una distribución de frecuencia; esto no es suficiente para fines
practico, puesto que a menudo es necesario una sola medida descriptiva, y en
especial cuando se requiere comparar dos o más serie estadísticas. Es necesario
continuar el proceso de reducción hasta sustituir todos los valores observados por
uno solo que sea representativo, de tal forma que permita una interpretación global
del fenómeno en estudio; para que ese valor sea representativo debe reflejar la
tendencia de los datos individuales de la serie de valores. Un valor o dato de la serie
con estas características recibe el nombre de promedio, media o medida de
posición, esto es debido a su ubicación en la zona central de la distribución. Las
medidas de posición son de gran importancia en el resumen estadístico, ya que
representan un gran número de valores individuales por uno solo.
El valor más representativo de un conjunto de datos por lo general no es el valor
más pequeño ni el más grande, es un número cuyo valor se encuentra en un punto
intermedio de la serie de datos. Por lo tanto, un promedio es con frecuencia un valor
referido que representará la medida de posición de la serie de valores. Las medidas
de posición se emplean con frecuencia como mecanismo para resumir un gran
número de datos o cantidades con la finalidad de obtener un valor que sea
representativo de la serie.
Las Principales Medidas de Posición son:
a) La Media Aritmética, b) La Mediana, c) La Moda, d) Los cuartiles, e) Los
Deciles y f) Los Percentiles.
3.1.1. Características de las medidas de posición
• Deben ser definidas rigurosamente y no ser susceptibles de diversas interpretaciones.
pág. 36 Dagoberto Salgado Horta
• Deben depender de todas las observaciones de la serie, de lo contrario no sería una
característica de la distribución.
• No deben tener un carácter matemático demasiado abstracto.
• Deben ser susceptibles de cálculo algebraico, rápido y fácil.
3.1.2. Media aritmética: La media aritmética ( X ) o simplemente la media es el
parámetro de posición de más importancia en las aplicaciones estadísticas. Se trata
del valor medio de todos los valores que toma la variable estadística de una serie
de datos. Por lo tanto, la medida posicional más utilizada en los estudios
estadísticos viene a ser la media. Por su fácil cálculo e interpretación, es la medida
de posición más conocida y más utilizada en los cálculos estadísticos. La media es
el valor más representativo de la serie de valores, es el punto de equilibrio, es el
centro de gravedad de la serie de datos. La media aritmética por lo general se le
designa con X .
La media aritmética de una serie de N valores de una variable X1, X2, X3;
X4,.........Xn, es el cociente de dividir la sumatoria de todos los valores que toma la
variable Xi, entre el número total de ellos. La fórmula se puede expresar así:
X
n
X i 1
.
N
Desviaciones o desvíos. - Son diferencias algebraicas entre cada valor de la serie
o cada punto medio y la media aritmética de dicha serie, o un valor cualquiera
tomado arbitrariamente. Los desvíos o desviación se designan con la letra di.
Dado una serie de valores X1, X2, X3, .......Xn, se llama desvío a la diferencia entre
un valor cualquiera Xi de la serie y un valor indicado k de esa misma serie. Si el
valor indicado k de la serie corresponde precisamente a la media aritmética de esos
valores dados, se dice entonces que los desvíos son con respecto a la media
aritmética. En símbolo: d i ( X i X ).
Propiedades de la media aritmética
1. La suma de las desviaciones con respecto a la media aritmética es igual a cero.
d i 0.
2. La suma de las desviaciones al cuadrado de los diversos valores con respecto
a la media aritmética es menor que la suma de las desviaciones al cuadrado de
los diversos valores con respecto a cualquier punto K, que no sea la media
aritmética. X i X X i K .
2 2
3. La media aritmética total o conjunta de dos o más serie de datos, se puede
calcular en función de las medias aritméticas parciales y del número de datos de
cada una de ellas, mediante la siguiente formula:
pág. 37 Dagoberto Salgado Horta
n1 X 1 n2 X 2 n3 X 3 ........ nk X k X 1 X 2 X 3 Xk ,
Xt .......
N n1 n2 n3 nk
Donde:
N n1 n2 n3 ...... nk , en esta n1, n2, n3 y nk es el número de datos de cada
serie. Además, X 1 ..,. X 2., .,.. X 3 .,., y.. X k .,..son las medias de cada una de las series.
4. La media del producto de una constante por una variable, es igual al producto
de la constante por la media de la variable.
X
KXi K Xi
KX.
N N
5. La media de la suma de una constante más una variable, es igual a la media de
la variable más la constante. X X i K
X i K X i K X K . ., de
n n n
la misma forma se cumple esta propiedad para la resta.
Características principales de la media aritmética
1. El valor de la media depende de cada una de las medidas que forman la serie
de datos, y se halla afectada excesivamente por los valores extremos de la serie
de datos.
2. La media se calcula con facilidad y es única para cada caso y permite
representar mediante un solo valor la posición de la serie de valores.
3. La media es una medida de posición que se calcula con todos los datos de la
serie de valores y es susceptible de operaciones algebraicas.
Cálculo de la media para datos no agrupados
Para calcular la media de datos no agrupados en clases se aplica la siguiente
formula:
X
Xi
. En donde N es el número total de datos y X i son los valores de
N
la variable.
Ejemplo: Calcule la media aritmética de los siguientes valores:
X i 5,.7,.8,.9.,11.,.14
pág. 38 Dagoberto Salgado Horta
X
X i
5 7 8 9 11 14 54
9. Por lo tanto, la media es 9.
N 6 6
Cálculo de la media para datos agrupados
Cuando se construye una distribución de frecuencia, los datos se agrupan en clases
definidas por unos límites. Cuando se trabaja con la distribución de frecuencia se
parte del supuesto de que todos los datos comprendidos en un intervalo de clase
se distribuyen uniformemente a lo largo de este, entonces se puede tomar la marca
de clase o punto medio ( X ) del intervalo como adecuada representación de los
valores que conforman el mencionado intervalo. El punto medio se designa con la
letra X . Para calcular la media en estas condiciones se pueden utilizar los pasos a
siguientes:
• Se agrupan los datos en clases y se llevan a una columna, se calculan los
puntos medios de cada clase y se colocan en sus respectivas columnas, se
determinan las frecuencias de cada clase y se ubican en sus respectivas
columnas.
• Se multiplican los puntos medios de cada clase por sus respectivas
frecuencias, luego se obtiene la sumatoria de las frecuencias (fi) multiplicadas
por el punto medio ( X ) así: f i X i .
• Luego se calcula la media aritmética aplicando la fórmula:
X
f i X i f X i ...Donde..N es igual al número total de datos. fi representa
fi N N
la frecuencia absoluta, que en el capítulo de distribuciones de frecuencias se ha
denotado como ni.
Ejemplo: Calcule la media de la siguiente distribución de frecuencia correspondiente
al peso en Kg de un grupo de obreros. Realice los cálculos respectivos para
completar el siguiente cuadro.
CLASES fi
75-------79 20
80-------84 40
85-------89 60
90-------94 100
95 ------99 140
f i N =360
pág. 39 Dagoberto Salgado Horta
CLASES X fi f i X
75-------79 77 20 1540
80-------84 82 40 3280
85-------89 87 60 5220
90-------94 92 100 9200
95 ------99 97 140 13580
TOTAL f i N =360 f i X i 32820
Aplicando la formula se tiene:
X
f i X i 32820 91.17. Kg
N 360
3.3.1. La mediana: La mediana (Md) es una medida de posición que divide a la
serie de valores en dos partes iguales, un cincuenta por ciento que es mayor o igual
a esta y otro cincuenta por ciento que es menor o igual que ella. Es por lo tanto, un
estadístico que está en el medio del ordenamiento o arreglo de los datos
organizados, entonces, la mediana divide la distribución en una forma tal que a cada
lado de la misma queda un número igual de datos.
Para encontrar la mediana en una serie de datos no agrupados, lo primero que se
hace es ordenar los datos en una forma creciente o decreciente y luego se ubica la
posición que esta ocupa en esa serie de datos; para ello hay que determinar si la
serie de datos es par o impar. Si el número N de datos es impar, entonces la
N 1
posición de la mediana se determina por la fórmula: p Md , luego el número
2
que se obtiene indica el lugar o posición que ocupa la mediana en la serie de
valores. Para obtener la posición de la mediana en una serie de datos no agrupados,
N
en donde el número N de datos es par, se aplica la formula PMd El
2
resultado obtenido, es la posición que ocupara la mediana, pero en este caso se
ubica la posición de la mediana por ambos extremos de la serie de valores y los dos
valores que se obtengan se le saca la media y esta será la mediana buscada, por
lo tanto la mediana, en este caso, es un número que no se encuentra dentro de la
serie de datos dados. Ejemplos:
• Sean los siguientes datos, 5, 12, 7, 8, 10, 6, y 9, los años de servicios de un
grupo de trabajadores. Determine la mediana. Lo primero que se hace es ordenar
N 1
los datos en forma creciente o decreciente; luego se aplica la formula PMd
2
, para ubicar la posición de la mediana. Los datos ordenados quedaran así: 5, 6,
7 1
7, 8, 9, 10, 12. La posición p Md 4. Esto indica que la mediana ocupa la
2
pág. 40 Dagoberto Salgado Horta
posición 4 en la serie de valores y por lo tanto esa posición corresponde a los
números 8 y 9 que en este caso ocupan la posición por la izquierda y por la derecha,
89
por lo tanto la Md viene a ser la semisuma de ambas posiciones 8.5 en
2
este caso 8.5 es la mediana.
Cuando los valores de los datos brutos de un conjunto de datos se agrupan en una
distribución de frecuencia de clase, cada valor pierde su identidad, por tal motivo la
mediana obtenida de una distribución de frecuencia de datos puede no ser la misma
que la mediana obtenida de los datos sin arreglar en clases, pero el resultado será
una aproximación. Cuando se obtiene la mediana para datos agrupados se utiliza
el método de interpolación. La interpolación parte del supuesto de que los datos de
cada intervalo de la distribución están igualmente distribuidos.
Pasos para determinar la mediana en datos agrupados
• Se elabora la tabla de frecuencia de datos con sus diferentes intervalos de
clases, se ubican las frecuencias fi (ni) y se calculan las frecuencias acumuladas
Fa (Ni)de esa distribución.
• Se determina la ubicación o posición de la mediana en el intervalo de la
N
distribución de frecuencia, mediante la fórmula PMd . El resultado obtenido
2
determinará la clase donde se encuentra ubicada la mediana, lo cual se conseguirá
en la clase donde la frecuencia acumulada Fa sea igual o superior a este resultado.
N
2 Faa
Luego se aplica la fórmula: Md Li Ic , en esta fórmula Md es la
fm
mediana, Li es el límite real inferior de la clase donde se encuentra ubicada la
mediana, Faa es el valor de la frecuencia acumulada anterior a la clase donde se
encuentra la mediana, fm es el valor de la frecuencia fi de la clase donde se
encuentra la mediana, Ic es el valor o longitud del intervalo de clase y N es el
número total de datos de la distribución en estudio.
Ejemplo: Dada la siguiente distribución de frecuencia referida a las horas extras
laboradas por un grupo de obreros. Calcule la mediana. Realice los cálculos
respectivos para completar el siguiente cuadro.
N° de horas Extras Obreros
CLASES fi
55------59 6
60------64 20
65------69 18
70------74 50
75------79 17
80------84 16
pág. 41 Dagoberto Salgado Horta
85------89 5
N = 132
Cuadro con las frecuencias acumuladas:
N° de horas Extras Obreros Obreros
CLASES fi fa
55------59 6 6
60------64 20 26
65------69 18 44
70------74 50 94
75------79 17 111
80------84 16 127
85------89 5 132
N = 132
N
2 Faa
Ahora se aplica la fórmula: Md Li Ic
fm
N 132
N = 132, 66, luego la mediana se encuentra en la clase 70----74, por
2 2
lo tanto el limite real inferior de esa clase es 69.5 = Li. La frecuencia fi de esa clase
es 50 = fm , Faa = 44 y el
Ic = 5. Aplicando la formula se tiene:
66 44 22
Md 69.5 5 69.5 .5 69.5 2.2 71.70.
50 50
Luego la mediana de esa distribución es 71.70. Esto quiere decir que un 50 % de
los obreros trabajaron horas extras por debajo de 71.70 horas y el otro 50 %
trabajaron horas extras por encima de 71.70 horas.
Características de la mediana
• La mediana no es afectada por los valores extremos de una serie de valores,
puesto que la misma no es calculada con todos los valores de la serie.
• La mediana no está definida algebraicamente, ya que para su cálculo no
intervienen todos los valores de la serie.
• La mediana en algunos casos no se puede calcular exactamente y esto
ocurre cuando en una serie de valores para datos no agrupados el número
de datos es par, en este caso la mediana se calcula aproximadamente.
pág. 42 Dagoberto Salgado Horta
• La mediana se puede calcular en aquellas distribuciones de frecuencia de
clases abierta, siempre y cuando los elementos centrales puedan ser
determinados.
• La suma de los valores absolutos de las desviaciones de los datos
individuales con respecto a la mediana siempre es mínima.
3.3.2. La moda: La moda es la medida de posición que indica la magnitud del valor
que se presenta con más frecuencia en una serie de datos; es pues, el valor de la
variable que más se repite en un conjunto de datos. De las medias de posición la
moda es la que se determina con mayor facilidad, ya que se puede obtener por una
simple observación de los datos en estudio, puesto que la moda es el dato que se
observa con mayor frecuencia. La moda se designa con las letras Mo.
En las representaciones gráficas la moda es el punto más alto de la gráfica. La
obtención de la moda para datos agrupados no es un valor exacto, ya que varía con
las diferentes formas de agrupar una distribución de frecuencia.
En algunas distribuciones de frecuencias o serie de datos no agrupados o
agrupados se presentan dos o más modas, en esta casa se habla de serie de datos
bimodales o multimodales, según sea el caso. Estos tipos de distribuciones o series
de valores se deben a la falta de homogeneidad de los datos.
Cuando una serie de valores es simétrica, la media, la mediana y el modo coinciden,
y si la asimetría de la serie es moderada, la mediana estará situada entre la media
y el modo con una separación de un tercio entre ambas. Tomando en cuenta esta
relación, cuando se tengan dos de esta medidas se puede determinar la tercera; sin
embargo es conveniente utilizar esta relación para calcular solamente la moda ya
que para calcular la media y la mediana existen fórmulas matemáticas que dan
resultados más exactos; la fórmula matemática para calcular la moda por medio de
la relación antes mencionada es: Mo X 3 X Md .
Para calcular la moda en datos agrupados existen varios métodos; cada uno de los
métodos puede dar un valor diferente de la moda: Aquí se dará un método el cual
se puede considerar uno de los más precisos en el cálculo de esta. Es un método
matemático que consiste en la interpolación mediante la siguiente formula:
1
Mo Li .Ic , en donde Mo es la moda, Li es el límite real de la clase
1 2
que presenta el mayor número de frecuencia; la clase que presenta el mayor
número de frecuencias fi se le denomina clase modal y a las frecuencias de esa
clases se les denomina frecuencia modal fm, 1 es la diferencia entre la frecuencia
de la clase modal ( fm) y la frecuencia de la clase anterior a la modal, la cual se
designa con fa , entonces, 1 ( fm fa) ; 2 es la diferencia entre la frecuencia
pág. 43 Dagoberto Salgado Horta
de la clase modal (fm) y la frecuencia de la clase siguiente a la modal, esta se
designa con fs , entonces, 2 ( fm fs).
Ejemplo: Dada la siguiente distribución de frecuencia correspondiente al peso en Kg
de un grupo de trabajadores de una empresa, calcule la moda.
CLASES fi
30-----39 2
40-----49 2
50-----59 7
60-----69 11
70-----79 12
80-----89 16
90-----99 2
TOTAL
La clase modal es 80----89, entonces Li = 79.5 y su fm = 16, fa = 12 y fs = 2,
Ic 10 , entonces:
1 f m f a 1 16 12 4;.. 2 f m f s 16 2 14
Aplicando la formula se tiene:
1 4 40
Mo L i Mo 79.5 .10 79.5 79.5 2.22 81.71.
1 2 4 14 18
Este resultado de la moda se interpreta así: La mayoría de los trabajadores tiene un
peso aproximadamente de 81.71 Kg.
Características de la moda
• El valor de la moda puede ser afectado grandemente por el método de
elaboración de los intervalos de clases.
• El valor de la moda no se halla afectado por la magnitud de los valores
extremos de una serie de valores, como sucede en la media aritmética.
• La moda se puede obtener en una forma aproximada muy fácilmente, puesto
que la obtención exacta es algo complicado.
• La moda tiene poca utilidad en una distribución de frecuencia que no posea
suficientes datos y que no ofrezcan una marcada tendencia central.
• No es susceptible de operaciones algebraicas posteriores.
• La moda se utiliza cuando se trabaja con escalas nominales, aunque se
puede utilizar con las otras escalas.
pág. 44 Dagoberto Salgado Horta
• La moda es útil cuando se está interesado en tener una idea aproximada de
la mayor concentración de una serie de datos.
3.3.3. Otras medidas posiciónales: Cuando se estudió la mediana se pudo
detectar que esta divide la serie de valores en dos partes iguales, una
generalización de esta medida da origen a unas nuevas medidas de posición
denominadas:
Cuartiles, Deciles y Percentiles. Estas nuevas medidas de posición surgen por la
necesidad de requerir de otras medidas que expresen diferentes situaciones de
orden, aparte de las señaladas por la mediana. Por lo tanto, es interesante ubicar
otras medidas que fraccionen una serie de datos en diferentes partes. Es bueno
destacar que los cuarteles, los Deciles y los Percentiles son unas variantes de la
mediana: De la misma forma los percentiles abarcan tanto a los cuarteles como a
los Deciles.
Los cuartiles: Son medidas posiciónales que dividen la distribución de frecuencia
en cuatro partes iguales. Se designa por el símbolo Qa en la que a corresponde a
los valores 1, 2 y 3., que viene a ser el número de Qa que posee una distribución
de frecuencia de clase. El Q1 divide la distribución de frecuencia en dos partes, una
corresponde a 25 % que está por debajo de Q1 y el otro 75 % por encima de Q1. El
Q2 divide la distribución de frecuencia en dos partes iguales, un 50 % que está por
debajo de los valores de Q2 y otro 50 % que está por encima del valor de Q2. El Q2
es igual a la mediana.
Cálculo de los cuartiles: Para datos no agrupados no tiene ninguna utilidad
práctica calcular los cuartiles. Para el cálculo de los cuartiles en datos agrupados
en una distribución de frecuencia existe un método por análisis gráfico y otro por
determinación numérica, por fines prácticos en esta cátedra se utilizará el último
método. Para calcular los cuartiles por el método numérico se procede de la
siguiente manera:
• Se localiza la posición del cuartil solicitado aplicando la fórmula de posición:
aN
PQa , en donde a viene a ser el número del cuartil solicitado, N
4
corresponde al número total de datos de la distribución y 4 corresponde al
número de cuartiles que presenta una distribución de frecuencia.
• Luego se aplica la fórmula para determinar un cuartil determinado, así:
aN
4 Faa
Qa Li .Ic. En esta fórmula, Qa = El cuartil solicitado, en esta a
fm
corresponde al número del cuartil solicitado; Li = Limite real inferior de la clase
donde se encuentra ubicado el cuartil; Faa = Frecuencia acumulada anterior a la
clase donde se encuentra el cuartil; fm = Frecuencia fi que posee el intervalo de
pág. 45 Dagoberto Salgado Horta
aN
clase donde se encuentra el cuartil; PQa = Posición que ocupa el cuartil en
4
la distribución de frecuencia, este resultado obtenido determinará la clase donde se
encuentra ubicado el cuartil, el mismo se encontrará en la clase donde la frecuencia
acumulada Fa sea igual o superior a este resultado.
Los deciles: Son medidas de posición que dividen la distribución de frecuencia en
diez partes iguales y estas van desde el número uno hasta el número nueve. Los
deciles se les designa con las letras Da, siendo a, el número de los diferentes
deciles, que en este caso son nueve. El D2 es el punto debajo del cual se encuentran
ubicados el 20 % de los valores de la distribución o también el punto por sobre el
cual se encuentra el 80 % de los valores de la serie de datos. La mediana es igual
al D5, puesto que este decil divide la distribución en dos partes iguale tal como lo
hace la mediana, de la misma forma el decil cinco es igual al cuartil dos.
Cálculo de los deciles: El cálculo de los deciles es similar al cálculo de los cuartiles,
solo que en estos varía la posición, la misma se calcula con la fórmula:
aN
PDa , en esta a corresponde al número del decil que se desea calcular, N
10
equivale al número de datos de la distribución y 10 corresponde a las diez partes en
la que se divide la serie de valores de la distribución.
aN
10 Faa
La fórmula para su cálculo es: Da Li .Ic . En este caso se aplica la
fm
fórmula de la misma manera que se hizo para calcular los cuartiles, solo que en esta
fórmula varia la posición de ubicación de la clase donde se encuentra ubicado el
decil.
Los percentiles: Son medidas posicióneles que dividen la distribución de
frecuencia en 100 partes iguales. Con estos se puede calcular cualquier porcentaje
de datos de la distribución de frecuencia. Los percentiles son las medidas más
utilizadas para propósitos de ubicación de valor de una serie de datos ubicados en
una distribución de frecuencia. El número de percentiles de una distribución de
frecuencia es de 99. El percentil 50 es igual a la mediana, al decil 5 y al cuartil 2, es
decir: Md Q2 D5 P50 . 50% por encima y 50 % por debajo de los datos de la
distribución.
Cálculo de los percentiles: es similar al cálculo de los cuartiles y los deciles con
una variante en la posición de ubicación de estos, que viene expresada por la
siguiente formula:
aN
aN 100 Faa
PPa . Con esta posición se aplica la fórmula: Pa Li .Ic .
100 fm
pág. 46 Dagoberto Salgado Horta
Ejemplo: Dada la siguiente distribución correspondiente al salario semanal en
dólares de un grupo de obreros de una empresa petrolera trasnacional. Calcule:
a) Q1, b) Q2, c) Compare los resultados con la mediana D3, d) D5, e) P25, f) P50, g)
P7
SALARIO EN $ fi Fa
200-----299 85 85
300-----399 90 175
400-----499 120 295
500-----599 70 365
600-----699 62 427
700-----799 36 463
Totales = N 463
a) Para calcular Q1, se determina primero la posición así:
1x 463 463
PQ1 115.75.
4 4
PQ1 = 115.75. Con ese valor de la posición encontrado se busca en las
frecuencias acumuladas para ver cuál de esas contiene ese valor. Observando las
frecuencias acumuladas se puede detectar que la posición 115.75 se encuentra en
la clase 300------399, por lo tanto, el Li = 299.5,
fm = 90, y la Faa = 85 y Ic = 100, aplicando la formula se tiene:
115.75 85 3075
Q1 299.5 .100 299.5 299.5 34.17 333.67.
90 90
Este valor de Q1 indica que el 25 % de los obreros en estudio, devengan un salario
semanal por debajo de $ 333.67 y el 75 % restante gana un salario por encima de
$ 333.67.
b) Para calcular Q2=Md se determina primero la posición de este así.
2 x 463
PQ 2 231.5 , ahora se ubica esta posición en las frecuencias acumulados
4
para determinar la posición de Q2, se puede observar en la distribución que esta
posición de Q2 está ubicada en la clase 400----499, entonces, Li = 399.5, fm = 120,
Faa = 175 y Ic = 100, aplicando la formula se tiene:
231.5 175 5650
Q2 399.5 .100 399.5 399.5 47.08 446.58.
120 120
Este resultado de Q2 establece que el 50 % de los obreros de este estudio,
devengan un salario semanal por debajo de $ 446.58 y el otro 50 % devenga un
sueldo por encima de $ 446.58. Calcule la mediana y compárela con este resultado.
pág. 47 Dagoberto Salgado Horta
c) Para determinar D3 = P30 hay primero que calcular la posición de este así:
3x 463
PD 3 138.9 , ahora se ubica esta posición en las frecuencias acumuladas
10
para determinar la posición de D3, en la tabla de la distribución de frecuencia se
observa que D3 se encuentra en la clase 300----399, luego, Li = 299.5, fm = 90,
Faa = 85 y Ic = 100, aplicando la formula se tiene:
138.9 85
D3 299.5 .100 299.5 59.89 359.39 . Esto indica que un 30 % de los
90
obreros ganan un salario semanal por debajo de $ 359.39 y el 70 % restante
devenga un sueldo por encima de $ 359.39.
d) Calcular, D5 = Q2 = P50, además P25 = Q1, la comprobación de estos resultados
se le deja como practica al estudiante.
g) Para calcular P70 lo primero que se hace es determinar la posición,
70x 463
PP 70 324.10 . Ahora se ubica este resultado en la columna de frecuencias
100'
acumuladas para encontrar la posición de P70 en la distribución de frecuencia.
Como se puede observar en la tabla de distribución de frecuencia, P70 se encuentra
ubicado en la clase 500-------599, entonces, Li = 499.5, fm = 70, Faa = 295 y Ic
= 100, aplicando la formula se tiene:
324.10 295 2910
P70 499.5 .100 499.5 499.5 41.57 541.07.
70 70
Esto indica que el 70 % de los obreros devengan un sueldo semanal que está por
debajo de $ 541.07 y que el 30 % de los restantes obreros, ganan un salario por
encima de $ 541.07.
Porcentajes de valores que están por debajo o por encima de un valor
determinado: Muchas veces necesitamos conocer el porcentaje de valores que
están por debajo o por encima de un valor determinado; lo que representa un tipo
de problema contrario al estudiado anteriormente, esto es, dado un cierto valor en
el eje de abscisa (X) del plano cartesiano, determinar en la ordenada (Y) el tanto
por ciento de valores inferiores y superiores al valor dado. Operación que se
resuelve utilizando la siguiente fórmula matemática:
f ( P Li 100
p faa i , donde:
Ic N
p porcentajeque se quiere buscar.
P Valor dado en el eje de las X (valor que se ubica en las clases).
faa Frecuencia acumulada de la clase anterior a la clase donde se encuentra
ubicado P.
f i Frecuencia de la clase donde se encuentra ubicada P.
Li Límite inferior de la clase donde se encuentra ubicada P.
I c Intervalo de clase.
N = Número total de datos o total de frecuencias.
pág. 48 Dagoberto Salgado Horta
Ejemplo: Utilizando los datos de la distribución de frecuencia anterior, Determine
qué porcentaje de obreros ganan un salario semanal inferior a $ 450.
Solución:
Datos:
p?
P 450
faa 175
Li 400
I c 100
N = 463
Ahora se aplica la fórmula:
f ( P Li 100
p faa i , Sustituyendo valores se tiene:
Ic N
120(450 400 100
p 175 463 p 50.75
100
De acuerdo con el resultado se puede afirmar que el 50.75 % de los obreros
devengan un salario inferior a $ 450 y el 49.25 % de los obreros ganan un salario
superior a $ 450.
3.2. Medidas de dispersión: Las medidas de posición central son los valores que
de una manera condensada representan una serie de datos, pero realmente no son
suficientes para caracterizar una distribución de frecuencia. Para describir una
distribución de frecuencia o serie de datos es necesario, por lo menos otra medida
que indique la dispersión o variabilidad de los datos, es decir, su alejamiento de las
medidas de posición central. Estas medidas de posición central no tienen ningún
valor si no se conoce como se acercan o se alejan esos valores con respecto al
promedio, en otras palabras, es conocer cómo se dispersan o varían esos valores
con respecto al promedio de una distribución de frecuencia.
La dispersión o variabilidad: se entiende como el hecho de que los valores de
una serie difieran uno de otro, es decir, como se están dispersando o distribuyendo
en la distribución. De acuerdo con esto es necesario encontrar una medida que
indique hasta qué punto los valores de una variable están dispersos en relación con
el valor típico. Las medidas de variabilidad son números que expresan la forma en
que los valores de una serie de datos cambian alrededor de una medida de posición
central la cual por lo general es la media aritmética.
pág. 49 Dagoberto Salgado Horta
La dispersión puede ser mayor o menor, tomando en cuenta esas diferencias. La
variabilidad es la esencia de la estadística, puesto que las variables y atributos se
caracterizan siempre por diferencias de valores entre observaciones individuales.
Casi siempre en una distribución de frecuencia el promedio obtenido difiere de los
datos de la serie; por esto es importante determinar el grado de variación o
dispersión de los datos de una serie de valores con respecto al promedio. Las
medidas de dispersión se clasifican en dos grandes grupos: a) Las Medidas de
Dispersión Absolutas y las Relativas; las Relativas, vienen expresadas en las
mismas medidas que se identifican la serie de datos, las mismas son: 1) El
Recorrido, 2) La Desviación cuartilica, 3) La Desviación Semicuartilica, 4) La
desviación Media, 5) La Desviación Típica o Estándar 6) La varianza.
Las Medidas de Dispersión relativa. Son relaciones entre medidas de dispersión
absolutas y medidas de tendencia central multiplicadas por 100, por lo tanto, vienen
expresadas en porcentaje, su función es la de encontrar entre varias distribuciones
la dispersión existente entre ellas. La medida de dispersión relativa de mayor
importancia es el Coeficiente de Variación.
Se llama Variación o Dispersión de los datos, el grado en que los valores de una
distribución o serie numérica tiende a acercarse o alejarse alrededor de un
promedio. Cuando la dispersión es baja indica que la serie de valores es
relativamente homogénea mientras que una variabilidad alta indica una serie de
valores heterogénea.
Cuando los valores observados de una serie están muy concentrados alrededor del
promedio, se dice que ese promedio es o será muy representativo; pero si están
muy dispersos con relación al promedio, es decir muy esparcidos con respecto al
promedio, entonces ese promedio es poco representativo de la serie o distribución,
puesto que no representan adecuadamente los datos individuales de esa
distribución. Es importante obtener una medida que indique hasta qué punto las
observaciones de una serie de valores están variando en relación con el valor típico
de la serie.
3.2.1. Rango o Recorrido (R): Es la primera medida de dispersión, no está
relacionada con ningún promedio en particular, ya que este se relaciona con los
datos mismos, puesto que su cálculo se determina restándole al dato mayor de una
serie el dato menor de la misma. El rango es el número de variables diferentes que
posee una serie de valores. Su fórmula se calcula así:
Rango(R) = Dato mayor (XM)Dato Menor (Xm)
R = XM Xm. El rango es la medida de dispersión más sencilla e inexacta dentro de
las medidas de dispersión absoluta.
pág. 50 Dagoberto Salgado Horta
3.2.2. Desviación íntercuartilica (DC): La desviación íntercuartilica es la diferencia
que existe entre el cuartil tres (Q3) y el cuartil uno (Q1) de una distribución de
frecuencia y se expresa así: DC = Q3 Q1.
3.2.3. desviación semi-íntercuartilica (DSC): La desviación semi-íntercuartilica es
la diferencia entre el Q3 y el Q1 dividido entre dos:
Q3 Q1
DSC .
2
Si los valores de la DC o DSC son pequeños indica una alta concentración de los
datos de la distribución en los valores centrales de la serie de datos. Estas medidas
se utilizan para comparar los grados de variación de los valores centrales en
diferentes distribuciones de frecuencias. Los mismos no son afectados por los
valores extremos, no se adaptan a la manipulación algebraica, por tal motivo son de
poca utilidad.
3.2.4. Desviación media: La desviación media de un conjunto de N observaciones
x1, x2, x3, .............xn, es el promedio de los valores absolutos de las desviaciones
(di) con respecto a la media aritmética o la mediana. Si se denomina como DM a la
desviación media, entonces su fórmula matemática será la siguiente:
N N
X i X d i
DM i 1
i 1
N N
Esta fórmula es para datos no agrupados. Se toma el valor absoluto en la ecuación,
debido a que la primera propiedad de la media aritmética establece que los desvíos
(di) de una serie con respecto a la media aritmética siempre son iguales a cero, es
decir: di = 0.
Cuando los datos están en una distribución de clases o agrupados se aplica la
siguiente formula:
f
N N
X f
X di
i i i
DM i 1
i 1
N N
En esta fórmula X es el punto medio de cada clase y fi es la frecuencia de cada
clase. La Desviación Media a pesar de que para su cálculo se toman todas las
observaciones de la serie, por el motivo de no tomar en cuenta los signos de las
desviaciones (di), es de difícil manejo algebraico. Su utilización en estadística es
muy reducida o casi nula, su importancia es meramente histórica, ya que de esta
fórmula es la que da origen a la desviación típica o estándar.
pág. 51 Dagoberto Salgado Horta
3.2.5. Desviación típica o Estándar: Es la medida de dispersión más utilizada en
las investigaciones por ser la más estable de todas, ya que para su cálculo se
utilizan todos los desvíos con respecto a la media aritmética de las observaciones,
y, además, se toman en cuenta los signos de esos desvíos. Se le designa con la
letra castellana S cuando se trabaja con una muestra y con la letra griega minúscula
(Sigma) cuando se trabaja con una población. Es importante destacar que cuando
se hace referencia a la población él número de datos se expresa con N y cuando se
refiere a la muestra él número de datos se expresa con n. La desviación típica se
define como:
“La raíz cuadrada positiva del promedio aritmético de los cuadrados de los desvíos
de las observaciones con respecto a su media aritmética”. La desviación típica es
una forma refinada de la desviación media”.
Características de la Desviación Típica:
• La desviación típica se calcula con cada uno de los valores de una serie de
datos.
• La desviación típica se calcula con respecto a la media aritmética de las
observaciones de una serie de datos, y mide la variación alrededor de la
media.
• La desviación típica es susceptible de operaciones algebraicas, puesto que
para su cálculo se utilizan los signos positivos y negativos de los desvíos de
todas las observaciones de una serie de valores, por lo tanto, es una medida
completamente matemática.
• Es una medida de bastante precisión, que se encarga de medir el promedio
de la dispersión de las observaciones de una muestra estadística. Las
influencias de las fluctuaciones del azar, al momento de seleccionar la
muestra la afectan muy poco. Le da gran significación a la media aritmética
de la serie de valores.
• Es siempre una cantidad positiva.
Interpretación de la desviación típica: La desviación típica como medida absoluta
de dispersión, es la que mejor nos proporciona la variación de los datos con
respecto a la media aritmética, su valor se encuentra en relación directa con la
dispersión de los datos, a mayor dispersión de ellos, mayor desviación típica, y a
menor dispersión, menor desviación típica.
pág. 52 Dagoberto Salgado Horta
Su mayor utilidad se presenta en una distribución normal, ya que en dicha
distribución en el intervalo determinado por X se encuentra el 68. 27% de los
datos de la serie; en el intervalo determinado por la X 2 se encuentra el 95,45%
de los datos y entre la X 3 se encuentra la casi totalidad de los datos, es decir,
el 99,73% de los datos; además, existe una regla general de gran utilidad para la
comprobación de los cálculos que dice: “una oscilación igual a seis veces la ,
centrada en la media comprende aproximadamente el 99% de los datos”. Ver figura
19.
68,27%
95,45%
99,73%
Media
Figura 19. Porcentajes característicos de la distribución normal
A la zona limitada por la X conoce bajo el nombre de zona normal, ya que se
considera a los datos que caen dentro de esa zona, datos normales en relación con
el grupo estudiado; los datos que estén por encima o por debajo de dicho intervalo
se consideran supranormales e infranormales.
Cálculo de la Desviación Típica: La desviación típica para calcularla se procede
de dos formas: a) Para datos no agrupados en clases, b) Para datos agrupados en
clases.
a) Para datos no Agrupados.- Las fórmulas para determinar la desviación
típica de una S y de una son:
(X X )2 d
2
1. .S
i i
n 1 n 1
pág. 53 Dagoberto Salgado Horta
2. .d i2 ( X i X ) 2
( X i ) 2
X i
2
n N X i2 ( X i ) 2
3. .S
n 1 n(n 1)
Es importante recordar que cuando se trabaja con la formula para datos no
agrupados y se trata de una muestra se utilizará como denominador n1, para
corregir el sesgo.
Para caular la desviacián tipica de una poblacián para datos no agrupados, se
utilizan las siguientes formulas:
4. .
(X i X )2
d i
2
N N
X i X
2
2
X 2
5. . i
i
X2
N
N N
Método para calcular la Desviación Típica en datos no agrupados:
• Se calcula la media aritmética.
• Se calculan los desvíos (di) de la serie de valores Xi, con respecto a la media
aritmética.
• Se elevan al cuadrado cada una de las desviaciones (di)2 , y se determina la
sumatoria de esos. De la misma forma se elevan al cuadrado cada uno de
los Xi y se calcula la sumatoria de estos; de igual manera se calcula la
sumatoria de los Xi y se elevan al cuadrado. Despues de hacer todos estos
cálculos se elabora un cuadro estadístico con estos cálculos.
pág. 54 Dagoberto Salgado Horta
• Finalmente se aplica la formula de la desviación típica para datos no
agrupados de la muestra o de la población, según el caso.
Ejemplo: Los siguientes valores corresponden a la edad de ñiños de una muestra
tomada de una población: Xi = 3, 4, 5, 6, 7. Determine la desviación típica.
X
X i
25
5
n 5
Xi (X i X) d i d i2
3 3–5 =-2 4
4 4–5 =-1 1
5 5–5 = 0 0
6 6–5 = 1 1
7 7–5 = 2 4
X i 25 d i 0 d i 10
Este problema se resolverá utilizando la media aritmética y sin utilizar la media,
para ello se utilizarán las formulas 1 y 3
.
1. .S
d i
2
10
2.5 1.58
n 1 4
n X i2 X
2
5(135 625 50
3. .S 1.58
i
n(n 1) 5(4) 20
Interpretación: El resultado obtenido con las formulas 1 y 3 indican que en
promedio, las edades de los ñiños de esa muestra se desvian o varian con respecto
a la media aritmética en una cantidad igual a 1.58 años.
Si este problema se resuelve ahora, considerando los datos como si fueran de una
población y se aplica la formula 4 y 5, entonces se tiene:
pág. 55 Dagoberto Salgado Horta
4. .
d i
2
10
2 1.41.
N 5
X i
2
2
X 135 625
5. . i
27 25 2 1.41.
N N 5 5
60.83 56.25 4.58 2.14
En la solución del problema con las formula 4 y 5 de la población se observa que
la de la población es menor que la S de la muestra, esto es debido a que la S de
la muestra utilizó n-1, para corregir el error producto del sesgo, y la de la
población no lo utilizó.
b) Para datos Agrupados en Clases.- Para calcular la desviación típica en
datos agrupado existen varios criterios en relacion a la corrección del sesgo que se
produce al tomar una muestra, en este estudio se considerará la formula que corrige
el sesgo de aquellas muestras en estudio; sin embargo, cuando n sea mayor que
50, no es necesario tal corrección. . Existen muchas formulas matemáticas para
calcular la desvición típica, queda a juicio del estudiante utilizar la formula que él
considere más fácil, siempre y cuando su aplicación sea valedera.
Formulas Para calcular la muestra y la población de una desviación típica
con datos agrupados en clases:
1. .S
( X i X )2 fi
d i
2
fi
n 1 n 1
pág. 56 Dagoberto Salgado Horta
X f
2
X i
2
fi
i
n
i
2. .S
n 1
f (X
2
f K 2
Xa )
f K
2 i i
X )2
f i (X
i i
i i
i a
n n
3. .S n 1
n 1
Para calcular la S de la fórmula 1 es necesario calcular el punto medio de cada
una de las clases de la distribución, calcular la media aritmética y luego calcular los
desvíos de los puntos medios con respecto a la media aritmética. En la formula 2
no es necesario calcular la media.
En la fórmula 3, X a es un valor arbitrario que se toma de los X de la distribución,
i
lo más central posible para así facilitar los
es recomrndable que se escoja el X i
calculos posteriores.
El término Ki , en esta formula, viene a ser un desvío arbitrario con respecto a una
X ) . Este método para calcular S en datos
mdia arbitraria X a .Entonces, K i (X a
agrupados, se fundamenta en la propiedad de la desviación típica que establece:
“si a cada una de los valores de una serie de datos se le suma una constante, la
desviación típica no se altera en sus resultados”.
4. . f ( X
i i X )2
fd i i
2
N N
5. .
f Xi i
2
X2
N
f f i X i
2
X i2
6. .
i
N N
pág. 57 Dagoberto Salgado Horta
f K 2
f K
2 i i
2
X )2
f i (X fiX
i
i i
7. .
i a
N
N N N
Método para calcular la Desviación Típica en datos Agrupados
• Se calcula la X
• Se calcula el X i de cada una de las clases que integran la distribución de
frecuencia, se determinan los desvíos di de los X con respecto a la X , i
luego se elevan al cuadrado los di y se multiplican por fi, y se calcula la
f d i
2
i .
• Se calcula la f X , luego se determina la
i
2
i f i X i 2.
• Se elabora un cuadro estadístico y se llevan a este todos los datos
calculados.
• Se aplica la formula necesaria para calcular la desviación típica.
Ejemplo: Los siguientes datos corresponden a las horas extras trabajadas por los
obreros de la empresa FATEXTOL, en un mes (se resolverá considerando los datos
como de una S y ).
CLASES
fi
X i f i X di = X i X f i d i2 f i
X
i
2
1 42 42 - 15.26 232.87 1764
40 — 44
45 — 49 6 47 282 - 10.26 631.60 13254
50 — 54 21 52 1092 - 5.26 581.02 56784
55 — 59 75 57 4275 - 0.26 5.07 243675
60 — 64 23 62 1426 4.74 516.75 88412
65 — 69 7 67 469 9.74 664.07 31423
70 — 74 2 72 144 14.74 434.54 10368
135
f Xi i =7730 d i 1.82 f d i
2
i =3065.92 f Xi
2
i =445680
Para resolver el problema lo primero que se debe hacer es calcular la media
aritmética así:
pág. 58 Dagoberto Salgado Horta
X
f X i
7730
57.26
n 135
Ahora se calculan los diferentes, para determinar los otros parámetros necesarios
(es recomendable que se realice todos los cálculos) para resolver el problema
planteado, en el cuadro de arriba se colocaron los cálculos realizados que son
necesarios para resolver el mismo; este se resolverá aplicando las formulas 1, 2, y
3 de la S, considerando los datos como los de una muestra.
1. S
fd i i
2
3065.92
3065.92
22.88 4.78
n 1 135 1 134
fX
2
7730 2
2 445680
i i
fi X i
n 135 3065.93
2. .S 22.88 4.78.
n 1 135 1 134
Para aplicar la fórmula 3 se toma una media arbitraria X a que en este caso la más
céntrica es 57, luego se calculan los desvíos de los puntos medios con respecto
a la X a así:
Ki = ( X i X a ) se elabora un cuadro estadístico para resumir los datos y finalmente
se procede a buscar la desviación
fi
X i ( X i X a ) =Ki
fi . Ki fi (ki)2
1 42 - 15 - 15 225
6 47 - 10 - 60 600
21 52 - 5 - 105 525
75 57 0 0 0
23 62 5 115 575
7 67 10 70 700
2 72 15 30 450
f i 135 fK i i 35 fK i i
2
3075
pág. 59 Dagoberto Salgado Horta
f K 2
35
2
fK i i
2
i i
3075
3. . N 135
N 135
1225
3075
135 3075 9.07 3065.93 22.71 4.76.
135 135 135
Interpretación: Los resultados obtenidos con las formulas 1, 2, y 3, indican que los
promedios de las horas extras laboradas por los trabajadores se desvían o varían
con respecto a su media aritmética en una cantidad igual a 4.78 y 4.76
respectivamente. La misma interpretación se obtiene con los resultados obtenidos
con las formulas 4, 5 y 6.
4. .
fd i i
2
3065.92
22.71 4.76
N 135
5. .
f Xi i
2
X2
445680
3278.62 22,71 4.76.
N 135
f f i X i
2
X i2 445680 7730
2
6. . 4.76.
i
N N 135 135
La aplicación de la fórmula 7 se deja para que el participante la aplique y resuelva
el mismo problema, el cual tendrá resultados idénticos a los anteriores.
pág. 60 Dagoberto Salgado Horta
Propiedades de la Desviación Típica
• La desviación típica de una constante k es cero. Si se parte de que la media
aritmética de una constante es igual a la constante, esto es así, debida a
que al ser todos los datos iguales no habrá dispersión en la serie de datos
con respecto a la media aritmética, por lo tanto (k) = 0.
• Si a cada uno de los valores de una serie de variables se le suma o se le
resta una constante K, la desviación típica no se altera. Esta se apoya en la
propiedad de la media aritmética que establece “si a cada valor de la serie
se le suma una constante, la media de la nueva serie es igual a la media de
la serie original más la constante”, igual sucede con la resta, la nueva media
(X i K ) (Xi )
vendrá disminuida en el valor de dicha constante.
• Si a cada uno de los términos de la serie de valores se le multiplica por una
constante K, la desviación típica de la serie quedará multiplicada por K, y la
nueva desviación típica será igual a la constante K tomada en valor absoluto
por la desviación típica original. Esta propiedad se apoya en la propiedad del
producto de la media aritmética
(X i .K ) . K .. ( X i ) .
• Para distribuciones normales siempre se cumple que: 68.27 % de los datos
se encuentran en el intervalo ( X ). 95.45 % de los datos se encuentran
en el intervalo ( X 2). 99.73 % de los datos se encuentran en el intervalo
( X 3). Estos valores se cumplen con bastante aproximación, para
distribuciones que son Normales y para las que son ligeramente asimétricas.
• Para dos series de valores, de tamaño n1 y n2, con variaciones S21 y S22,
respectivamente, la varianza
n1 S12 n2 S 22
S
2
n1 n2
T
3.2.5. Varianza: Es otra de las variaciones absolutas y la misma se define como el
cuadrado de la desviación típica; viene expresada con las mismas letras de la
desviación típica pero elevadas al cuadrado, así S2 y 2. Las fórmulas para calcular
la varianza son las mismas utilizadas por la desviación típica, exceptuando las
1. . 2
(X i )2
.., para.datos.no.agrupados.
N
pág. 61 Dagoberto Salgado Horta
respectivas raíces, las cuales desaparecen al estar elevados el primer miembro al
cuadrado.
2. . 2
f i ( X i ) 2
..,. para.datos.agrupados.
N
La varianza general de la muestra se expresa así:
3. .S 2
(X i X )2
..,. para.datos.no.agrupados.
n 1
4. .S 2
f i ( X i X )
..,. para.datos.agrupados.
n 1
3.2.6. Dispersión relativa: Las medidas de variabilidad, estudiadas hasta ahora,
solo permitían medir las dispersiones absolutas de los términos de la muestra. Las
medidas, tomadas en esas condiciones, serán de utilidad, solo cuando se trata de
analizar una sola muestra; pero, cuando hay que establecer comparaciones entre
distintas muestras, será necesario expresar tales medidas en valores relativos, que
pueden ser proporciones o porcentajes.
Las medidas de dispersión relativas permiten comparar grupos de series distintas
en cuanto a su variación, independientemente de las unidades en que se midan las
diferentes características en consideración. Generalmente las medidas de
dispersión relativas se expresan en porcentajes, facilitando así el estudio con
medidas procedentes de otras series de valores La dispersión relativa viene a ser
igual a la dispersión absoluta dividida entre el promedio.
Existen varias medidas de dispersión relativa, pero, la más usada es el coeficiente
de variación de Pearson, este es un índice de variabilidad sin dimensiones, lo que
permite la comparación entre diferentes distribuciones de frecuencias, medidas en
diferentes unidades. El coeficiente de variación de Pearson se designa con las letras
CV. La fórmula matemática es:
CV x100.
X
pág. 62 Dagoberto Salgado Horta
Ejemplo: La venta en el mercado de tres productos, varía de acuerdo al siguiente
cuadro. Determine el CV de cada uno y diga cuál de ellos presenta mayor variación
y cuál la menor.
Producto X S Unidades CV
1 45 5 Bs. 11.11 %
2 450 40 Bs. 8.87 %
3 4500 350 Bs. 7.78 %
Para resolver el problema se calcula el CV de cada producto y luego sé determina
cuál presenta mayor o menor variación
CV = Sx100/ X
CV1 = 5x100/45 = 11.11 %.
CV2 = 40x100/450 = 8.87 %.
CV3 = 350x100/4500 = 7.78 %.
Se puede observar que la menor dispersión la presenta el producto 3, por lo tanto,
de los 3 productos el que menos varia es ese; por otro lado, el de mayor dispersión
o variabilidad es el producto 1.
3.3. Medidas de forma: Hasta ahora, hemos estado analizando y estudiando la
dispersión de una distribución, pero parece evidente que necesitamos conocer más
sobre el comportamiento de una distribución. En esta parte, analizaremos las
medidas de forma, en el sentido de histograma o representación de datos, es decir,
que información nos aporta según la forma que tengan la disposición de datos.
Las medidas de forma de una distribución se pueden clasificar en dos grandes
grupos o bloques: medidas de asimetría y medidas de curtosis.
pág. 63 Dagoberto Salgado Horta
3.3.1. Simetría: Según el Diccionario de la Real Academia Española es la
“Regularidad en la disposición de las partes o puntos de un cuerpo o figura, de modo
que posea un centro, un eje o un plano de referencia”. Es por lo tanto la armonía de
posición de las partes o puntos similares uno respecto de otros y con referencia a
puntos, líneas o planos determinados. Se puede generalizar diciendo que es una
proporción de las partes entre sí y con el todo.
En estadística se dice que una distribución de datos es simétrica si se le puede
doblar a lo largo de un eje vertical de una manera tal que coincidan los dos lados de
la distribución. Las distribuciones que no tienen simetría con respecto al eje vertical
se les llama sesgada o asimétrica. Una distribución sesgada a la derecha tiene una
cola prolongada del lado derecho de la distribución y una cola más corta del lado
izquierdo de la misma; esta asimetría se le denomina positiva, cuando la cola de la
distribución del lado izquierdo es más larga que la del lado derecho, entonces la
asimetría es negativa.
En una distribución simétrica la media, la mediana y la moda son iguales. La simetría
se mide por medio del coeficiente de asimetría. Una distribución simétrica tiene un
coeficiente de asimetría igual a cero. Cuando una distribución de frecuencia es
asimétrica, la media, la mediana y la moda se alejan una de otra, es decir, las tres
medidas de posición son diferente; mientras más se separe la media de la moda,
mayor es la asimetría. Si la distribución de frecuencia es asimétricamente negativa,
la cola de la curva de distribución se encuentra hacia los valores más pequeños de
la escala de las X y si la distribución es asimétricamente positiva la cola de la
distribución se ubica hacia los valores más grandes de la escala de las X.
Karl Pearson un estudioso de la estadística designo el coeficiente de asimetría con
las letras SK y determinó la fórmula para su cálculo, al cual se le denominó primer
coeficiente de asimetría de Pearson
( X Mo)
SK 1
S
Esta fórmula se puede transformar por medio de la relación:
Mo X 3X Md Mo X 3X Md X Mo 3X Md .
X Mo 3X Md , si ahora se sustituye 3( X - Md) en el primer coeficiente de
asimetría de Pearson, se tiene otro coeficiente de asimetría utilizando la mediana
que se le denomina segundo coeficiente de asimetría de Pearson, este es más
preciso que el primero
3( X Md )
SK 2
S
pág. 64 Dagoberto Salgado Horta
Arthur Bowley otro estudioso de la estadística determinó que el coeficiente de
asimetría se podía calcular por medio de los cuartiles y utilizó el coeficiente de
asimetría por medio de cuartiles (skq), y la formula es
Q1 Q3 2Q2
SK q
Q3 Q1
En donde, Q1, Q2 y Q3 son los cuartiles 1, 2 y 3 respectivamente. El valor de SKq
varía entre 1 y 1; según Bowley una distribución de frecuencia con un coeficiente
de asimetría igual a 0.1, se considera como ligeramente asimétrica y con un valor
mayor 0.3 se le considera marcadamente asimétrica.
El coeficiente de asimetría se puede calcular también en función de los momentos,
siendo el momento m3 el parámetro utilizado para tal efecto. El coeficiente de
asimetría según los momentos se designa con las letras SKm y sé calcula mediante
m3
SK m 3
S
la fórmula
En esta fórmula m3 es el momento tres con respecto a la media aritmética y S3 es
la desviación típica elevada a la potencia tres. Este coeficiente es el más confiable
de todos los antes descritos, así que para cualquier cálculo se debería utilizar este,
ya que es un parámetro que utiliza todos los datos de la serie de valores.
Si en una serie de valores la X Md Mo, entonces la distribución de frecuencia
presenta una curva asimétrica positiva; si la X = Md = Mo = 0 , la curva de la
distribución es simétrica y si la distribución presenta una curva en la que el Mo
Md X , entonces se dice que la curva de la distribución asimétrica negativa.
Sí la curva de una distribución de frecuencia es sesgada, la media tratara de
ubicarse hacia el extremo o lado opuesto, de la serie de valores, donde se
concentran los datos. Es bueno hacer referencia que en una asimetría positiva la
X Md y en una asimetría negativa la X Md.
Si en una distribución de frecuencia, los intervalos de las clases que la conforman
presentan frecuencias balanceadas en cada uno de ellos y no presentan ninguna
aglomeración especial en los extremos y, además, presenta una concentración de
los datos en el centro de la distribución, entonces se dice que la distribución de
frecuencia es simétrica. Cuando la curva de una distribución de datos es simétrica
el SK = 0, esta es una de las características de la curva Normal o Campana de
Gauss.
pág. 65 Dagoberto Salgado Horta
Si la mayoría de los datos de una serie de valores están ubicados en el centro de la
distribución y, además existe una dispersión medianamente hacia los extremos
mayores o menores de las variables, entonces se afirma que la curva de la
distribución es Ligeramente Asimétrica. Ejemplo:
CLASES 1 f1 CLASES f2
2
3—5 5 3—5 8
6—8 10 6—8 12
9—11 25 9—11 20
12—14 40 12—14 40
15—17 20 15—17 25
18—20 12 18—20 10
21—23 8 21—23 5
TOTAL 120 TOTAL 120
En este ejemplo la distribución 1 es ligeramente asimétrica positiva y la distribución
2 es ligeramente asimétrica negativa. La mayoría de las distribuciones de casos
reales por lo general son ligeramente asimétricas.
Una distribución de datos es marcadamente asimétrica si la mayoría de los datos
de la misma se encuentran ubicados en los extremos mayores o menores de las
variables que conforman la distribución. Si la mayoría de los de los datos de una
serie de valores se encuentra situados en el extremo de las clases menores de la
distribución, entonces la curva de la distribución de frecuencia presenta una
asimetría positiva, siendo en este caso el SK 0; y si por el contrario esa mayoría
se encuentra en los extremos de las clases mayores de las variables, entonces la
serie de valores presenta una curva con una asimetría negativa, luego el
Coeficiente de asimetría será mayor que cero, es decir, SK0 Ejemplo:
CLASES 3 f3 CLASES 4 f4
3—5 15 3—5 5
6—8 25 6—8 10
9—11 40 9—11 15
12—14 60 12—14 60
15—17 15 15—17 40
18—20 10 18—20 25
21—23 5 21—23 15
TOTAL 170 TOTAL 170
pág. 66 Dagoberto Salgado Horta
En la distribución 3 los datos presentan una curva marcadamente asimétrica positiva
y el caso 4 la curva de la distribución es marcadamente asimétrica negativa.
Existen distribuciones de frecuencias que presentan curvas fuertemente
marcadamente asimétricas y otras que las curvas son ligeramente asimétricas.
Considerar la asimetría de una curva de frecuencia marcadamente o ligeramente
asimétrica, es un asunto de criterio del investigador, puesto que no existen reglas
rígidas establecidas que determinen las líneas divisorias o parámetros entre
ligeramente o marcadamente asimétrica; Sin embargo cuando la mayoría de los
datos de una distribución de frecuencia se ubican en los extremos mayores o
menores de las variables se puede afirmar con certeza que la curva de la
distribución es marcadamente asimétrica.
Algunos investigadores como Arthur Bowley determinaron que si se aplica el SKq y
ese coeficiente de asimetría obtenido es menor que 0.3 (sin considera el signo) se
puede afirmar que la curva de la distribución es ligeramente asimétrica, en caso
contrario la curva de la distribución sería marcadamente asimétrica. Otros
investigadores utilizan el coeficiente de asimetría según los momentos (SK m) para
tales efectos, pero no existe criterio en cual ha de ser el coeficiente especifico que
marque el límite entre ligera y marcadamente. Sin embargo, en este estudio se
considerará que un coeficiente de asimetría según los momentos comprendido
entre 0.30 SKm 0.30, sería un buen límite para considerar una curva de
distribución como ligeramente asimétrica, de lo contrario sería marcadamente
asimétrica. El SKm es el coeficiente de asimetría de mayor precisión y confiabilidad,
puesto que este, utiliza para su cálculo todos los valores de la serie de datos.
Es bueno afirmar que cuando el coeficiente de asimetría de una curva de
distribución es marcadamente asimétrico no se puede utilizar la media aritmética
como medida de tendencia central, puesto que esta es afectada altamente por los
valores extremos de una serie de datos, en su lugar es recomendable utilizar la
mediana como medida de posición.
3.3.2. Kurtosis (Curtosis): Es el grado de apuntamiento o altura de la curva de una
distribución de frecuencia. La finalidad de la Kurtosis es determinar si la distribución
de los términos de una serie de valores responde a una curva normal o no. Se
utiliza para observar el promedio o posición de la distribución, así como la media, la
mediana y la moda, se puede en esta observar la asimetría, el grado de
concentración de los datos, en fin, para observar en forma general el
comportamiento de una serie de datos en una distribución de frecuencia. Por medio
de la Kurtosis se determinará si la distribución de frecuencia es demasiado
puntiaguda, normal o muy achatada.
El grado de apuntamiento o altura de una curva de distribución se determina por
medio del coeficiente de Kurtosis, el cual se calcula utilizando el momento cuatro de
una serie de valores con respecto a su media aritmética. La Kurtosis se designa con
la letra K4 y la fórmula de cálculo es:
pág. 67 Dagoberto Salgado Horta
m4
K4
S4
En esta fórmula m4 es el momento cuatro con respecto a la media aritmética y S 4
es la desviación típica elevada a la cuarta potencia, K4 es el coeficiente de Kurtosis.
Tomando en cuenta la Kurtosis el k4 de una curva de distribución puede ser:
Mesocurtica, Platicurtica y Leptocurtica.
Mesocurtica: Es aquella curva de una distribución de frecuencia que no es ni muy
alta ni muy achatada, es la llamada curva normal. La curva Mesocurtica tiene un
coeficiente de Kurtosis igual a tres, es decir, K4 = 3.
Leptocurtica: Es aquella curva de la distribución que presenta un apuntamiento o
altura relativamente más alta que la curva Mesocurtica, en esta los datos se
encuentran más concentrados alrededor del máximo valor. El coeficiente de
Kurtosis para curva Leptocurtica es mayor de tres, es decir, K4 3.
Platicurtica: Es la curva de una distribución de frecuencia que presenta un
achatamiento más pronunciado que la Mesocurtica, encontrándose los datos más
dispersos alrededor del máximo valor de la distribución. En esta curva el coeficiente
de Kurtosis es menor de tres, es decir, K4 3.
En la Figura 20 de Kurtosis se pueden observar los tres tipos de Kurtosis antes
descritos, siendo la primera curva Platicurtica (azul), la segunda Mesocurtica (roja)
y la última es Leptocurtica (amarilla):
pág. 68 Dagoberto Salgado Horta
KURTOSIS
1° PLATIKURTICA
2° MESOKURTICA
3° LEPTOKURTICA
Figura 20. Curvas según su curtosis
Ejemplo: En la siguiente distribución de frecuencia, determine el coeficiente de
asimetría utilizando los métodos de Pearson, de Bowley y el de los momentos,
interprete los resultados y haga un análisis de los diferentes resultados y diga cuál
es el resultado más recomendado en este caso; encuentre la Kurtosis e interprete
los resultados.
CLASES fi
10—12 1
13—15 5
16—18 15
19—21 40
22—24 15
25—27 10
28---30 9
95
Solución: Para resolver el problema lo primero que hay que hacer es calcular la X
y determinar los desvíos di con respecto a la media, luego se elabora un cuadro
estadístico con el resumen de los cálculos necesarios para determinar la asimetría
pág. 69 Dagoberto Salgado Horta
y la curtosis. Además, se tendrá que calcular la mediana, la moda, el Q 1 el Q3, y
después de realizar todos esos cálculos se procede a buscar la asimetría y la
curtosis con las formulas respectivas. En el siguiente cuadro se encuentran
resumidos la mayoría de los cálculos necesarios, el resto se calcularán aparte.
CLASES fi X i f i X i di fi.di fi.d2 fi.d3 fi.d4
10—12 1 11 11 -10.07 -10.07 101.40 -1021.15 10282.95
13—15 5 14 70 -7.07 -35.35 249.92 -1766.97 12492.45
16—18 15 17 255 -4.07 -61.05 248.47 -1011.29 4115.94
19—21 40 20 800 -1.07 -42.80 45.80 -49.00 52.43
22—24 15 23 345 1.93 28.95 55.87 107.84 208.12
25—27 10 26 260 4.93 49.30 243.05 1198.23 5907.28
28---30 9 29 261 7.93 71.37 565.96 4488.10 35590.60
95 2002 0.38 1510.40 1945.76 68649.77
Se recomienda realizar los cálculos de los parámetros, ya que solo aparecen sus
resultados
X = 21.07, Mo = 20.0, Q1 = 18.71, Q2 = Md = 20.49,
Q3 = 23.55, S = 4.41, S2 = 19.46, S3 = 85.82, S4 = 378,82.
X Mo 21.07 20.0 1.07
SK1 0.27
S 3.99 3.99
El resultado indica que la curva de distribución es ligeramente asimétrica positiva.
3( X Md ) 3(21.07 20.49) 1.74
SK 2 0.44
S 3.99 3.99
El resultado indica que la curva de la distribución es marcadamente asimétrica
positiva.
Q1 Q2 2Q2 18.71 23.55 2(20.49) 1.28
SK q o.26.
Q3 Q1 23.55 18.71 4.84
El resultado indica que la curva es ligeramente asimétrica positiva.
pág. 70 Dagoberto Salgado Horta
Para calcular el coeficiente de asimetría según los SKm se cálcula primero el m3
así:
m3
fd i i
3
1945.76
20.48
n 95
m 3 20.48
SK m 0.32
S 3 63.40
El coeficiente SKm indica que la curva de la distribución es marcadamente
asimétrica positiva. Si se observan los diferentes coeficientes de asimetría se puede
notar que el SK2 y el SKm son marcadamente asimétricos y los otros son ligeramente
asimétricos, esto es así por cuanto él valor obtenido con el SK2 y el SKm son más
precisos que los otros, lo que indica que se debe preferir el resultado de estos
últimos por razones obvias. Siempre el SKm será más preciso que cualquier otro
coeficiente de asimetría, ¿Por qué? Los resultados obtenidos con los diferentes
coeficientes de asimetría indican que esta es positiva, es decir, con un sesgo hacia
la cola de la derecha.
Para calcular el K4 se calcula el m4 así:
m4
fd i i
4
68649.77
722.63
n 95
Ahora se procede a calcular el K4 aplicando la formula
m4 722.63
K4 4
2.86.
S 252.8
El resultado indica que el apuntamiento de la curva es achatado, la primera curva
(de color verde), es decir, la curva es platicurtica. Observe la Figura 21, donde se
puede ver la curva normal (de color rojo) y se puede observar la kurtosis y la
simetría. La asimetría positiva se puede observar en la parte derecha de la gráfica.
pág. 71 Dagoberto Salgado Horta
60 KURTOSIS Y ASIMETRÍA
50
40
30
20
10
0
11 14 17 20 23 26 29
1d ASIMETRÍA + 1 5 15 40 15 9 10
CURVA NORMAL 1 5 15 50 15 5 1
Figura 21. Curtosis y Asimetria
Ejemplo: En la siguiente distribución de frecuencia determine el SK1, SK2, SKq y el
skm, interprete los resultados y diga cuál es el más recomendado; encuentre la
curtosis e interprete el resultado.
CLASES fi
10—12 9
13—15 10
16—18 15
19—21 40
22—24 15
25—27 5
28—30 1
95
Solución.- Para resolver este problema se debe calcular la X y los desvíos di con
respecto a esta, también es necesario calcular la Md, el Mo, el Q1, el Q3, la S, el m3,
el m4, elaborar un cuadro estadístico y finalmente aplicar las formulas respectivas.
pág. 72 Dagoberto Salgado Horta
En el siguiente cuadro se resumen los cálculos para tales efectos. Se recomienda
al estudiante realizar todos los cálculos pertinentes.
CLASES fi X i f i X i di fi.di fi.d2 fi.d 3 fi.d4
10—12 9 11 99 -7.93 -71.37 565.96 -4488.10 35590.60
13—15 10 14 140 -4.93 -49.30 243.05 -1198.23 5907.28
16—18 15 17 255 -1.93 -28.95 55.87 -107.84 208.12
49.30
19—21 40 20 800 1.07 42.80 45.80 49.00 52.43
22—24 15 23 345 4.07 61.05 248.47 1011.29 4115.94
25—27 5 26 130 7.07 35.35 249.92 1766.97 12492.45
28—30 1 29 29 10.0 10.07 101.40 1021.15 10282.95
95 1798 7 - 0. 3 5 1510.4 -1945.76 68649.77
Los resultados obtenidos de los diferentes cálculos son:
X = 18.93, Mo = 20.0, Q1 = 16.45, Q2 = Md = 19.91.
S = 3.99, S3 = 63.40, S4 = 252.80, m3 = 20.48, m4 = 722.63
Ahora se procederá a calcular los diferentes coeficientes de asimetría así:
X Mo 18.93 20.0 1.07
SK 1 0.27
S 3.99 3.99
3( X Md ) 3(18.93 19.51) 1.74
SK 2 0.44.
S 3,99 3.99
Si observa puede ver que este problema es casi idéntico al anterior, solo las
m3 20.48
SK m 0.32
S3 63.40
frecuencias fueron cambiadas de la parte alta de las variables hacia la parte baja de
Q1 Q3 2Q2 16.45 21.29 2(19.51) 1.28
SK q 0.26
Q3 Q1 21.29 16.45 4.84
las mismas, por tal razón todos sus cálculos son idénticos en valor absoluto al
pág. 73 Dagoberto Salgado Horta
anterior, lo que indica que ahora la asimetría obtenida es negativa, es decir, con
sesgo hacia la izquierda.
Para calcular la Kurtosis se procede así:
m4 722.63
K4 2.86.
S 4 252.80
La curva de la distribución es platikurtica. La interpretación es idéntica a la del
problema anterior. Se puede ver que la curva más alta es la normal (roja) o
Mesocurtica y la más achatada es la curva de la distribución en estudio, y en este
caso es platikurtica.
3.4. Medidas de concentración: Las medidas de concentración tratan de poner
de relieve el mayor o menor grado de igualdad en el reparto del total de los valores
de la variable, son por tanto indicadores del grado de distribución de la variable.
Denominamos concentración a la mayor o menor equidad en el reparto de la suma
total de los valores de la variable considerada (renta, salarios, etc.).
Las infinitas posibilidades que pueden adoptar los valores, se encuentran entre los
dos extremos:
Concentración máxima, cuando uno solo percibe el total y los demás nada, en
este caso, nos encontraremos ante un reparto no equitativo.
Concentración mínima, cuando el conjunto total de valores de la variable está
repartido por igual, en este caso diremos que estamos ante un reparto equitativo
De las diferentes medidas de concentración que existen nos vamos a centrar en
dos:
Índice de Gini: Coeficiente, por tanto, será un valor numérico.
Curva de Lorenz: gráfico, por tanto, será una representación en ejes coordenados.
Sea una distribución (xi, ni) de la que formaremos una tabla con las siguientes
columnas:
• Los productos xi ni, que nos indicarán la totalidad percibida por los ni
frecuencias de valores individuales xi.
• Las frecuencias absolutas acumuladas Ni.
• Los totales acumulados ui que se calculan de la siguiente forma:
pág. 74 Dagoberto Salgado Horta
u1= x1 n1
u2 = x1 n1 + x2 n2
u3 = x1 n1 + x2 n2 + x3 n3
u4 = x1 n1 + x2 n2 + x3 n3 + x4 n4
un = x1 n1 + x2 n2 + x3 n3 + x4 n4 + …………. + xn nn
n
Por tanto podemos decir que u n x i n i
i 1
• La columna total de frecuencias acumuladas relativas, que expresaremos en
tanto por ciento y que representaremos como pi y que vendrá dada por la
siguiente notación
Ni
pi 100
n
• La renta total de todos los rentistas que será un y que, dada en tanto por
ciento, la cual representaremos como qi y que responderá a la siguiente
notación:
ui
qi 100
un
Por tanto, ya podemos confeccionar la tabla que será la siguiente:
Ni ui pi - qi
pi 100 qi 100
n un
xi ni xi ni Ni ui
x1 n1 x1 n1 N1 u1 p1 q1 p1 - q1
x2 n2 x2 n2 N2 u2 p2 q2 p2 - q2
... ... ... ... ... ... ... ...
xn nn xn nn Nn un pn qn pn - qn
pág. 75 Dagoberto Salgado Horta
Como podemos ver la última columna es la diferencia entre las dos penúltimas, esta
diferencia seria 0 para la concentración mínima ya que pi = qi y por tanto su
diferencia seria cero.
Si esto lo representamos gráficamente obtendremos la curva de concentración o
curva de Lorenz. La manera de representarlo será, en el eje de las X, los valores
pi en % y en el de las Y los valores de qi en %. Al ser un %, el gráfico siempre será
un cuadrado, y la gráfica será una curva que se unirá al cuadrado, por los valores
(0,0), y (100,100), y quedará siempre por debajo de la diagonal.
La manera de interpretarla será: cuanto más cerca se sitúe esta curva de la
diagonal, menor concentración habrá, o más homogeneidad en la distribución.
Cuanto más se acerque a los ejes, por la parte inferior del cuadrado, mayor
concentración.
Los extremos son:
Figura 22. Valores extremos de la concentración
Analíticamente calcularemos el índice de Gini el cual responde a la siguiente
ecuación
k 1
p i q i
i 1
IG k 1
pi
i 1
Este índice tomara los valores de IG = 0 cuando pi = qi concentración mínima y
de Ig = 1 cuando qi = 0 Esto lo veremos mejor con un ejemplo:
pág. 76 Dagoberto Salgado Horta
Frecuencia
marca xin i S un pi = (Ni/n) 100 qi = (u i/u n ) 100 pi - qi
L i-1 - L i xi ni Ni
0 - 50 25 23 23 575 575 8,85 1,48 7,37
50 - 100 75 72 95 5400 5975 36,54 15,38 21,16
100 - 150 125 62 157 7750 13725 60,38 35,33 25,06
150 - 200 175 48 205 8400 22125 78,85 56,95 21,90
200 - 250 225 19 224 4275 26400 86,15 67,95 18,20
250 - 300 275 8 232 2200 28600 89,23 73,62 15,61
300 - 350 325 14 246 4550 33150 94,62 85,33 9,29
350 - 400 375 7 253 2625 35775 97,31 92,08 5,22
400 - 450 425 5 258 2125 37900 99,23 97,55 1,68
450 - 500 475 2 260 950 38850 100,00 100,00 0,00
260 38850 651,15 125,48
Se pide Índice de concentración y Curva de Lorenz correspondiente
a) Índice de concentración de GINI
k 1
p i q i 125 ,48
i 1
IG k 1
0,193
651,15
pi
,
i 1
Observamos que hay poca concentración por encontrarse cerca del 0.
b) Curva de Lorenz
La curva la obtenemos cerca de la diagonal, que indica que hay poca
concentración:
pág. 77 Dagoberto Salgado Horta
Figura 23. Curva de Lorenz
3.5. Ejercicios
1. En un estudio de mercado se ordena encuestas a 20 personas de
determinada población. Se medirá un conjunto de variables entre las cuales
figura el ingreso mensual (I) en miles de pesos y el nivel socioeconómico
(NSE) que se supone fuertemente relacionado con la variable anterior. Los
datos obtenidos se muestran en la siguiente tabla:
Encuesta Sexo Edad Ingreso NSE
1 M 24 123.5 C4
2 M 46 678.8 C2
3 F 24 539.0 C2
4 F 35 234.5 C3
5 F 45 149.9 C4
6 F 89 56.8 E
7 M 58 889.3 C1
pág. 78 Dagoberto Salgado Horta
8 F 25 361.5 C3
9 M 64 548.7 C2
10 M 34 154.5 C4
11 M 72 2630.4 AB
12 F 37 129.5 C4
13 M 59 162.9 C4
14 F 45 516.5 C2
15 F 46 250.6 C3
16 F 45 850.8 C1
17 F 63 57.3 E
18 F 59 409.2 C2
19 F 60 135.0 C4
20 M 34 159.9 E
a) Clasifique las variables del estudio.
b) En que subpoblación, mujeres u hombres, los datos de ingreso mensual son
más homogéneos.
2. Se conocen los puntajes que un grupo de postulantes, no así las
identificaciones de los mismos. Uno de ellos, Andrés quiere conocer su
puntaje y le han dicho que es mayor que el promedio y menor que el percentil
75 Los puntajes son los siguientes
851 344 591 513 744 526 522
684 491 618 750 739 527 765 590
a) Obtenga los posibles puntajes de Andrés.
b) De entre los valores calculados en a), el puntaje de Andrés es aquel que, al
calcular la desviación estándar de los 14 restantes, produce la mayor
variabilidad ¿Cuál es el puntaje de Andrés?
pág. 79 Dagoberto Salgado Horta
3. Si se conoce que el salario medio mensual de 5 hermanos, es de $120.000,
y la mediana es de $100.000.
a) ¿Cuánto dinero llevan mensualmente a la casa los cinco hermanos?
b) Si Juan, el mejor pagado de los cinco recibe un aumento de $10.000; cuál es
la nueva media y cuál es la nueva mediana.
4. Un grupo de 80 estudiantes se compone de 35 hombres. En un test, el
puntaje medio de las mujeres fue de 70 puntos y del grupo completo fue 66.5
puntos.
a) Determine el puntaje medio de los hombres.
b) Si se cambia la escala de puntajes mediante la transformación Yi X i
( X i : puntaje antiguo, Yi puntaje nuevo), determine el nuevo puntaje medio
de hombres, mujeres y el grupo completo.
c) Compruebe que si se aplica la transformación al puntaje medio del grupo
total (66.5) se obtiene el mismo resultado que si se calcula el puntaje medio
del grupo total transformado, como promedio ponderado de los puntajes
transformados de hombres y mujeres (trate de comprobar esta propiedad en
forma general).
5. En una distribución simétrica de 7 intervalos de igual amplitud se conocen los
siguientes datos:
A 10 ; n1 8 ; Y3 n3 1260; n 2 n5 62 ; h3 0.21; H 6 0.96 .
a) Complete la información.
b) Calcule el promedio bajo la transformación lineal y 3x 7 .
6. En un banco comercial se desea estudiar el tiempo de atención necesario
para que un cliente realice una transacción entre las 12:00 horas y las 14:00
horas. Durante una semana se tomaron los tiempos de atención de 10
clientes diariamente, obteniéndose los siguientes datos tabulados:
Tiempo de atención Cantidad de
(min.) Clientes
0.25 - 1.65 17
1.65 - 3.05 11
pág. 80 Dagoberto Salgado Horta
3.05 - 4.45 7
4.45 - 5.85 7
5.85 - 7.25 4
7.25 - 8.65 2
8.65 - 10.05 2
Total 50
a) Determine qué porcentaje de clientes demoraron a lo más 3 minutos en su
atención.
b) Determine cuántas horas a lo más demorará en su transacción el 84% de los
clientes.
c) Construya un gráfico adecuado que permita mostrar (aproximadamente) la
ubicación de la Mediana y el Percentil 75.
7. La distribución de frecuencias observadas, de los sueldos para los
trabajadores del departamento de producción de dos empresas, A y B, para
dos muestras se da a conocer la siguiente tabla:
Sueldo (UF) nA nB
10.5 – 15.5 4 5
15.5 – 20.5 9 8
20.5 – 25.5 12 7
25.5 – 30.5 15 12
30.5 – 35.5 20 18
35.5 – 40.5 17 23
40.5 – 45.5 10 18
45.5 – 50.5 8 17
50.5 – 55.5 5 12
Total 100 120
a) Calcular en cada muestra las medidas de tendencia central.
pág. 81 Dagoberto Salgado Horta
b) Compare la homogeneidad de los datos a partir de los sueldos de la
empresa.
8. Los siguientes datos corresponden a los tiempos (en minutos) que duran 40
llamadas telefónicas recibidas por una central:
2.2 0.8 1.5 1.9 1.3 2.3 2.3 0.9 0.5 1.3 2.0 1.7
1.1 1.1 1.3 1.7 1.1 1.0 2.1 0.7 1.9 2.6 1.7 2.3
1.4 2.4 2.1 1.7 1.2 1.6 1.5 1.4 2.1 2.0 1.0 2.8
1.3 1.1 1.5 1.4
a) Construya una tabla de frecuencias con seis intervalos de igual amplitud.
b) Construya un histograma de frecuencias relativas porcentuales.
c) ¿Qué porcentaje de llamadas se encuentran en el intervalo x s; x s .
9. La media de un grupo de facturas es de $150 y la desviación $20. Utilizando
la regla empírica, construya un intervalo donde se encuentre el 99,7% del
monto de las facturas.
10. Una compañía produce lotes de tubos para gas con un diámetro promedio de
14 milímetros y una desviación de 0,1 milímetros. El gerente de control de
calidad de la compañía piensa que los tubos que no tengan diámetros entre
13,8 y 14,2 milímetros no deben ser puestos a la venta. Usando la regla
empírica, ¿aproximadamente qué porcentaje de tubos se encuentra apto
para la venta?
11. Para cada uno de los ejercicios siguientes, determine: la desviación estándar,
la varianza, el coeficiente de variación y el coeficiente de asimetría.
Establezca, así mismo, al menos una conclusión acerca de la dispersión y
otra acerca de la asimetría.
a) La producción diaria de dos plantas de ensamblado de vehículos se
muestra a continuación.
Planta “A”
49 51 50 48 49 50 50 51 52
pág. 82 Dagoberto Salgado Horta
Planta “B”
50 4 0 47 47 50 60 50 53 53
b) A continuación se presentan las notas de un examen de estadística (sobre
100 puntos).
95 81 59 68 100 92 75 67 85 79 71 88 100 94 87 65 93 72 83 91
c) La siguiente es una muestra de los aportes realizados por un grupo de
empleados al seguro social.
Cantidad (miles de$) Número de empleados
10 - 19 10
20 - 29 33
30 - 39 64
40 - 49 13
12. En un barrio de una gran ciudad se ha constatado que las familias residentes
se han distribuido, según su composición, de la siguiente forma:
Composición 0–2 2–4 4-6 6-8 8-10
Familias 110 200 90 75 25
a) ¿Cuál es el número medio de personas por familia?
b) ¿Cuál es el tipo de familia más usual?
c) Si sólo hubiera plazas de aparcamiento para el 50% de las familias, y
éstas se atendieran de mayor a menor número de miembros, ¿Cuántos
componentes debería tener una familia para entrar en el cupo?
d) Si el coeficiente de variación de Pearson de otro barrio de la misma ciudad
es 1,8, ¿cuál de los dos barrios puede ajustar mejor sus previsiones en
base al diferente número de miembros de las familias que lo habitan?
e) Si el ayuntamiento concede una ayuda de 5.000 ptas. fijas por familia,
más 10.000 ptas. por cada miembro de la unidad familiar, determinar el
importe medio por familia y la desviación típica.
f) Número de miembros que tienen como máximo el 85% de las familias
menos numerosas.
pág. 83 Dagoberto Salgado Horta
13. Las siguientes tablas corresponden a dos muestras representativas de los
créditos concedidos, en millones de pesos, por dos agencias de una entidad
bancaria en el último ejercicio. Comparar la concentración y la homogeneidad
de ambas distribuciones.
Agencia A Agencia B
Valor crédito Nº créditos Nº créditos
0 - 0,5 3 10
0,5 - 1 4 12
1- 2 6 8
2-4 58 30
4-7 78 12
7 - 12 90 15
12 - 14 20 5
14 - 18 6 6
18 - 20 4 16
pág. 84 Dagoberto Salgado Horta
4. ESTADÍSTICOS EN EXCEL 2016
Aunque podríamos utilizar fórmulas de Excel para obtener información como el valor
máximo, el mínimo, la media, la suma, etc., podremos obtener toda esa información
con solo utilizar la herramienta Estadística descriptiva.
El primer paso es pulsar el botón Análisis de datos de la ficha Datos y seleccionar
la opción Estadística descriptiva.
Figura 22 y 23. Opción Datos y Análisis de datos
Al pulsar el botón Aceptar se mostrará un nuevo cuadro de diálogo que nos permitirá
hacer las configuraciones necesarias para obtener los datos estadísticos de nuestra
información.
pág. 85 Dagoberto Salgado Horta
Figura 24. Estadística descriptiva
Las opciones dentro de este cuadro de diálogo a las que se debe prestar especial
atención son las siguientes:
• Rango de entrada: La columna que contiene los datos numéricos de los
cuales se obtendrán los datos estadísticos.
• Agrupado por: Indica la orientación del rango de entrada. Para el ejemplo
los datos están en una columna.
• Rótulos en la primera columna: Si dentro del rango de entrada está incluida
la celda que contiene el título de la columna, entonces debes marcar esta
caja de selección.
• Opciones de salida. Podrás elegir tres posibles opciones de salida: elegir
un rango dentro de la misma hoja donde se colocarán los resultados, o elegir
que los resultados se coloquen en una hoja nueva o en un libro nuevo.
• Resumen de estadísticas. Es necesario que esta opción esté seleccionada
para obtener los datos estadísticos que necesitamos.
Una vez que has hecho las configuraciones necesarias en el cuadro de
diálogo Estadística descriptiva pulsa el botón Aceptar para ver los resultados.
En muchas ocasiones al pulsar Datos, no aparece la opción de Análisis de datos
(Figura 24), esto se debe a que esta opción es un complemento de Excel, y en ese
momento no está activado o instalado.
pág. 86 Dagoberto Salgado Horta
Figura 25. Opción Datos sin Análisis de datos
Para activarlo, se seleccionan la siguiente secuencia de comandos: Archivo –
Opciones – Complementos – Ir – Herramientas para análisis. Como lo muestran las
figuras de la 26 a la 30
Figura 26. Comando archivo
Figura 27. Comando opciones
pág. 87 Dagoberto Salgado Horta
Figura 28. Comando complementos
Figura 29. Comando ir
pág. 88 Dagoberto Salgado Horta
Figura 30. Comando herramientas para análisis
Ejemplo: Calcular las medidas de resumen de la variable EDAD, correspondiente a
la plantilla: “base de datos”.
Figura 31. Resumen de estadísticas para la variable EDAD
pág. 89 Dagoberto Salgado Horta
EDAD
Media 44.0760219
Error típico 0.5228584
Mediana 38.8465753
Moda 38.4109589
Desviación estándar 11.6914691
Varianza de la muestra 136.690451
Curtosis -0.53532468
Coeficiente de asimetría 0.87473403
Rango 42.0273973
Mínimo 29.8383562
Máximo 71.8657534
Suma 22038.011
Cuenta 500
Figura 31. Medidas de resumen para la variable EDAD
Excel maneja las siguientes expresiones para la asimetría y la curtosis:
• CURTOSIS se define como sigue:
• ecuación para la ASIMETRÍA es la siguiente:
Como se puede observar la curtosis en su fórmula resta una expresión al lado
derecho relacionada con el número 3, luego su interpretación se hace con referencia
al número 0.
CURTOSIS > 0 Leptocurtica
CURTOSIS < 0 Platicurtica
pág. 90 Dagoberto Salgado Horta
CURTOSIS = 0 Mesocurtica
Otra medida que se puede generar a partir de la tabla de la Figura 3, es el coeficiente
de variación, dividiendo la desviación estándar entre la media y expresándola en
formato porcentual. Su resultado es: C.V. = 26.53%.
Los cuartiles, deciles, percentiles, se pueden generar desde cada celda, mediante
las siguientes expresiones:
=CUARTIL(B2:B6;1) para el cuartil 1
=CUARTIL(B2:B6;2) para el cuartil 2
=CUARTIL(B2:B6;3) para el cuartil 3
=PERCENTIL(B1:B501;0.7) para el decil 7
=PERCENTIL(B1:B501;0.89) para el percentil 89
Cuartíl 1 35.54452
Cuartíl 2 38.84658
Cuartíl 3 52.49726
Decil 7 48.97973
Percentil 89 62.81882
Figura 32. Cuartiles, Decil y Percentil para la variable EDAD
Interpretación: La edad promedio de los 500 empleados de la empresa ABC, es
aproximadamente de 44, 08 años. Un 50% de estos empleados tienen una edad
máxima de 38,85 años. La mayoría de los empleados tienen una edad aproximada
de 38,41 años. La distribución de la variable edad es platicurtica y asimétrica
positiva. La edad mínima es de 29,84 y la máxima de 71,87. La variable edad
presenta una leve heterogeneidad. El 25% de los empleados tiene una edad
máxima de 35,54 años, el 75% una edad máxima de 52,5 años, el 70% una edad
máxima de 48.98 años, y el 89% una edad máxima de 62,82 años.
Ejercicio:
1. Calcule e interprete las diferentes medidas de resumen para las siguientes
variables de la plantilla “base de datos”
EDUCACION = años de educación
SALARIO = salario anual (miles de pesos)
SERVICIO = años de servicio
EXPERIENCIA = experiencia (años)
pág. 91 Dagoberto Salgado Horta
2. Calcule e interprete las diferentes medidas de resumen para el ejercicio 8 del
capítulo 3.
pág. 92 Dagoberto Salgado Horta
5. DIAGRAMAS COMPLEMENTARIOS PARA EL ANALISIS EXPLORATORIO
DE DATOS
5.1. Diagrama de tallo y hojas: Un procedimiento semi-gráfico de presentar la
información para variables cuantitativas, que es especialmente útil cuando el
número total de datos es pequeño (menor que 50), es el diagrama de tallo y hojas
de Tukey. Los principios para constituirlo son:
• Redondear los datos a dos o tres cifras significativas, expresándolos en
unidades convenientes.
• Disponerlos en una tabla con dos columnas separadas por una línea como
sigue:
a) Para datos con dos dígitos, escribir a la izquierda de la línea los dígitos de
las decenas (forma el tallo), y a la derecha las unidades (hojas).
b) Para datos con tres dígitos el tallo estará formado por los dígitos de las
centenas y decenas, que se escribirán a la izquierda, separados de las
unidades.
• Cada tallo define una clase, y se escribe sólo una vez. El número de hojas
representa la frecuencia de dicha clase.
Ejemplo:
1. Datos recogidos en cm:
11,357; 12,542; 11,384; 12,431; 14,212: 15,213; 13,300; 11,300; 17,206; 12,710;
13,455; 16,143; 12,162; 12,721; 13,420; 14,698.
2. Datos redondeados expresados en mm:
114; 125; 114; 124; 142; 152; 133; 113; 172; 127; 135; 161; 122, 127; 134; 147.
3. Diagrama de tallo y hojas, datos en mm:
11 443
12 54727
13 354
14 27
15 2
16 1
17 2
decenas unidades
pág. 93 Dagoberto Salgado Horta
Cuando el primer dígito de la clasificación varía poco, la mayoría de los datos
tienden agruparse alrededor de un tallo y el diagrama resultante tiene poco detalle.
En ese caso es conveniente subdividir cada tallo en dos o más partes
introduciendo algún signo arbitrario, como se indica:
• Las pulsaciones por minuto de un grupo de 40 personas se han representado
en el diagrama de tallo y hojas siguiente:
5 2 6
6 0 0 0 0 0 0 4 4 4 4 4 4 8 8 8 8 8 888
7 2 2 2 2 2 2 2 2 6 6 6 6 6
8 0 0 4 4 8 8
9 2
• Podemos obtener más detalle subdividiendo cada tallo en dos partes iguales:
en una colocaremos las hojas 0 a 4 y lo representamos por ( * ) y en la otra las
hojas de 5 a 9 y lo representaremos por ( . ), obteniendo el diagrama:
5 * 2
. 6
6 * 0 0 0 0 0 0 4 4 4 4 4 4
. 8 8 8 8 8 8 8 8
7 * 2 2 2 2 2 2 2 2
. 6 6 6 6 6
8 * 0 0 4 4
. 8 8
9 * 2
.
Observemos que todos los datos son múltiplos de 4, lo que hace sospechar que
se han obtenido midiendo las pulsaciones cada 15 segundos y multiplicando por
cuatro.
pág. 94 Dagoberto Salgado Horta
5.2. Diagrama de cajas y bigotes: Los diagramas de Caja-Bigotes (boxplots o
box and whiskers) son una presentación visual que describe varias características
importantes, al mismo tiempo, tales como la dispersión y simetría. Para su
realización se representan los tres cuartiles y los valores mínimo y máximo de los
datos, sobre un rectángulo, alineado horizontal o verticalmente. Una gráfica de este
tipo consiste en una caja rectangular, donde los lados más largos muestran el
recorrido intercuartílico. Este rectángulo está dividido por un segmento vertical que
indica donde se posiciona la mediana y por lo tanto su relación con los cuartiles
primero y tercero (recordemos que el segundo cuartil coincide con la mediana). Esta
caja se ubica a escala sobre un segmento que tiene como extremos los valores
mínimo y máximo de la variable. Las líneas que sobresalen de la caja se llaman
bigotes. Estos bigotes tienen tienen un límite de prolongación, de modo que
cualquier dato o caso que no se encuentre dentro de este rango es marcado e
identificado individualmente.
Si la distribución es aproximadamente normal, se declaran puntos extremos
(outliers) aquellos que caen por fuera del intervalo X 2.7*S ya que P (-2.7*S < X
< + 2.7*S) = 0.993. Si la distribución es asimétrica, se acostumbra dividir la serie
en áreas o segmentos como se muestra en la siguiente gráfica, llamada gráfica de
Box and Whisker o caja esquemática o diagrama de bigotes:
Donde:
1: Q1 – 3xRq
2: Q1 – 1.5xRq
3: Q3 + 1.5xRq
4: Q3 + 3.xRq
Obsérvese que los puntos a distancias menores de la representación 1 o mayores
de la representación 4, son altos extremos. Los puntos entre la representación 3 y
4 y entre 1 y 2 se consideran como puntos de advertencia o bajos extremos; los
puntos entre la representación 2 y 3 se consideran como puntos normales.
pág. 95 Dagoberto Salgado Horta
Cuando la caja es contrecha, se puede determinar homogeneidad en la variable, en
caso contrario heterogeneidad.
Si el bigote derecho es más largo que el izquierdo, se puede determinar asimetría
positiva, en caso contrario asimetría negativa.
5.3. Diagrama de cajas y bigotes en Excel: Para construir un boxplot
necesitamos determinar el valor del primer y el tercer cuartil, el valor del a mediana,
y los valores mínimo y máximo de la variable analizada.
Todos estos estadísticos son provistos por la opción de estadística descriptiva del
menú de Análisis de Datos de Excel, con excepción del primer y tercer cuartil.
Ejemplo: Vamos a elaborar un diagrama de cajas y bigotes, para la variable EDAD,
de la “base de datos”.
Calculamos los estadísticos que aparecen en la Figura 33:
Figura 33. Algunos estadísticos para la variable EDAD
Seleccione el rango de celda M20 a N24 y luego usando el botón derecho del ratón
seleccione la alternativa Copiar. Manteniendo el rango seleccionado M20 a N24
diríjase al menú principal y elija Edición/Pegado especial. En el cuadro de diálogo
que aparece seleccione la opción valores, como se muestra en la figura 34.
pág. 96 Dagoberto Salgado Horta
Figura 34. Pegado especial - Valores
Presione el botón Aceptar y verá que aparentemente no se opera cambio alguno.
En realidad, acaba de convertir las fórmulas introducidas en el paso anterior en
valores que pueden usarse para cálculos posteriores.
Seleccione el rango M20 a N24 y luego del menú principal elija Insertar/Gráfico. En
tipo de gráfico seleccione Líneas y en subtipo de gráfico Línea con marcadores en
cada valor, generándose el grafico de la figura 34. Se puede agregarle un título al
gráfico
Figura 35. Diagrama de líneas
Parados en la línea azul de la figura 35, damos botón derecho y escogemos
seleccionar datos. Figura 36
pág. 97 Dagoberto Salgado Horta
Figura 36. Seleccionar datos
Seleccionamos el botón “Cambiar fila/columna que aparece en la figura 37
Figura 37. Cambiar fila/columna
El gráfico resultante deberá tener el siguiente aspecto:
Figura 38. Cambiar fila/columna
pág. 98 Dagoberto Salgado Horta
Figura 39. Agregar elemento de gráfico – Diseño rápido
En diseño rápido seleccionamos “Diseño 1”, y en Agregar elemento de gráfico,
seleccionamos Líneas – Líneas de máximos y mínimos y Barras ascendentes y
descendentes. Figura 40.
Figura 40. Líneas máximos y mínimos – Líneas ascendentes y descendentes
Finalmente, el diagrama de cajas y bigotes, con sus respectivos ajustes será:
Diagrama de cajas y bigotes para la EDAD
80
70
60 Primer cuartil
Título del eje
50 Mínimo
40
Mediana
30
20 Máximo
10 Tercer cuartil
0
1
Figura 41. Diagrama de cajas y bigotes para la variable EDAD
pág. 99 Dagoberto Salgado Horta
6. ESTADISTICA DESCRIPTIVA MEDIANTE EL COMPLEMENTO
MEGASTAT
6.1. Que es Megastat: Es un complemento de Microsoft Excel. Creado por J. B.
Orris en la Universidad de Butler. Hasta la versión 9.1 era de uso libre, sin embargo,
hoy en día es distribuido por la editorial McGraw-Hill. MegaStat ofrece herramientas
para efectuar estadística descriptiva, cálculos probabilísticos, estimación por
intervalos, prueba de hipótesis, series de tiempo y control de calidad.
MegaStat 10.3 Release 3.2 y versiones posteriores se ejecutarán en 32 bits o 64
bits Excel 2010, 2013, y 2016. Las versiones anteriores se pueden ejecutar sólo en
32 bits de Excel.
MegaStat 10.2 ha sido probado con las versiones de 32 bits de Microsoft Excel
2010, 2013, y 2016. MegaStat 10.2 y versiones anteriores pueden ejecutarse en
Excel 2007, MegaStat trabajará con 32 y 64 bits de Windows 10, Windows 8,
Windows 7, y Windows Vista Service Pack 2.
Según sea el sistema operativo o la versión de Excel, el ejecutable de Megastat se
puede bajar del siguiente link:
http://www.estadisticacondago.com/index.php/software-aplicativo-superior-89
pág. 100 Dagoberto Salgado Horta
6.2. Instalación y activación de Megastat: Por ser un complemento de Excel, el
ejecutable de Megastat, debe ser descomprimido en la carpeta “Library” o en la
carpeta “AddIns”, según la versión de Excel. Para ir en busca de cualquiera de estas
dos rutas, siga las siguientes instrucciones:
• Abra Excel, y siga la siguiente ruta: Archivo – Opciones – Complementos – Ir
- Examinar
Figura 42. Ruta para el copiado de Megastat
• Copie la ruta que aparece en la Figura 43
pág. 101 Dagoberto Salgado Horta
Figura 43. Carpeta del complemento Megastat
• La ruta definitiva para este PC que tiene instalado el Excel 2016, es la
siguiente: C:\Users\DAGO\AppData\Roaming\Microsoft\AddIns.
• Copie esta dirección en cualquier carpeta del explorador, y pegue la versión
adecuada del Megastat, descomprimiéndola.
Figura 44. Pegado y descomprensión de Megastat
pág. 102 Dagoberto Salgado Horta
• Una vez realizado el paso anterior, vuelva y abra la ruta de la Figura 42 y
active Megastat, como lo indica la Figura 45, finalmente oprima “Aceptar”
Figura 45. Activación de Megastat
Figura 46. Megastat Activado
6.3. Configuración del punto como separador de decimales: Algo muy
importante para trabajar con Megastat, es la configuración del punto y como
tal la coma, por ser una macro programada en otra región. Para ello se abre
el “Panel de control” del PC, y se realiza lo siguiente:
• Escogemos “Reloj, idioma y región” – “Región” y “Configuración adicional…”
Figura 47.
pág. 103 Dagoberto Salgado Horta
Figura 47. Configuración adicional del Panel de control
• En “Símbolo decimal”, escogemos punto “.”, y en “Símbolo de separación
de miles, escogemos coma “,”, y damos “Aceptar” “Aceptar”. Figura 48.
Figura 48. Configuración del punto y la coma
pág. 104 Dagoberto Salgado Horta
6.4. Configuración de rangos en Excel: Una forma para facilitar el trabajo en
Megastat, es configurar los rangos de cada una las variables. Esto se realiza
de la siguiente forma: se selecciona toda la variable, incluyendo su etiqueta,
por ejemplo, en el caso de la variable SEXO, se sombrea desde A1 a A501,
y en el “cuadro de nombres”, reemplazamos su contenido por el nombre de
la variable (para nuestro ejemplo “SEXO”. Figura 49. De la misma forma se
hace el procedimiento para el resto de variables.
Figura 49. Rangos para las varables
6.5. Tabulación y graficación variable cualitativa nominal con Megastat
(ESTADO):
a) En la opción “Datos” – “Filtro”, se puede visualizar las diferentes categorías
y el formato de las mismas, para cada variable. En el caso de la variable
ESTADO, se pude observar que existen 5 categorías: Casado, Separado,
Soltero, Unión Libre, Viudo. Figura 50
pág. 105 Dagoberto Salgado Horta
Figura 50. Filtro para visualizar categorías de las variables
b) En un área libre de la base de datos, por ejemplo, de L3 a L7, se colocan las
diferentes categorías de la variable, respetando el formato original, es decir,
teniendo en cuenta la escritura original en la base datos (respetando
mayúsculas y minúsculas). Figura 51.
Figura 51. Categorías de la variable ESTADO
pág. 106 Dagoberto Salgado Horta
c) Se elige la ruta: “Complementos – Megastat – Freqency Distributions –
Qualitative…”, como la indica la Figura 52.
Figura 52. Selección del comando Qualitative
d) Inmediatamente después, aparece un cuadro de dialogo como el de la Figura
53, donde en la opción “InputRange”, se escribe el nombre de la variable
definida en el rango que se configuro anteriormente (sección 6.4), o se
oprime la pestaña encerrada en el ovalo azul, seleccionando el rango de la
variable ($H$1:$H$501), y en la opción “specification range”, se ubica el
rango de las categorías ($L$3:$L$7). Escogemos la opción “histogram”, para
que se genere la gráfica, que no es un histograma sino un diagrama de barras
Figura 53. Selección del rango y las categorías de la variable ESTADO
El resultado obtenido se muestra en la Figura 54, en una hoja nueva del libro Excel,
llamada “Output”.
pág. 107 Dagoberto Salgado Horta
Figura 54. Output de la variable ESTADO
e) Por último, se edita la tabla y las gráficas como en el apartado 2.3.1.
6.6. Tabulación y graficación variable cualitativa ordinal con Megastat
(ESTRATO):
a) Se repiten los incisos del a) al d), de la sección anterior 6.5, teniendo en
cuenta que las categorías que deben ir en el área en blanco de la base de
datos son: Bajo, Medio y Alto. Estas categorías deben de tener un orden
establecido, por ser una variable Ordinal.
b) Se edita la tabla y las gráficas de la misma forma que en el apartado 2.3.2.
6.7. Tabulación y graficación variable cuantitativa discreta con Megastat
(EDUCACION):
a) Se repiten los incisos del a) al d), de la sección 6.5, teniendo en cuenta que
las categorías que deben ir en el área en blanco de la base de datos son los
números: 8-12-14-15-16-17-18-19-20-21. Estos números deben de ir en
pág. 108 Dagoberto Salgado Horta
orden por ser una variable Discreta. Se aclara que la variable EDUCACION,
es una variable discreta, pero para el tratamiento en Megastat, optamos por
la opción del apartado 6.5.
b) Se edita la tabla y las gráficas de la misma forma que en el apartado 2.3.3.
6.8. Tabulación y graficación variable cuantitativa continua con Megastat
(EDAD):
Teniendo en cuenta los incisos del 1 al 3 del apartado 2.3.4.1., para el cálculo de la
amplitud (4,21) y el mínimo redefinido (29,81), se realizan los siguientes pasos:
a) Se elige la ruta: “Complementos – Megastat – Freqency Distributions –
Quantitative…”, como la indica la Figura 55.
Figura 55. Selección del comando Quantitative
b) Aparece un cuadro de dialogo como el de la Figura 56, donde en la opción
“InputRange”, se escribe el nombre de la variable definida en el rango que se
configuro anteriormente (sección 6.4), o se oprime la pestaña encerrada en
el ovalo azul, seleccionando el rango de la variable ($B$1:$B$501). En
“interval width”, escribimos la amplitud (4,21) y en “lower boundary of first
interval”, el límite inferior del primer intervalo (29,81). Seleccionamos las tres
gráficas para las frecuencias acumuladas y las no acumuladas “Histogram,
Polygon y Ogive” y damos “OK”.
pág. 109 Dagoberto Salgado Horta
Figura 56. Selección del rango, amplitud y límite inferior del primer intervalo
de la variable EDAD
El resultado obtenido se muestra en la Figura 57, en una hoja nueva del libro Excel,
llamada “Output”.
Figura 57. Output de la variable EDAD
c) Por último, se edita la tabla y las gráficas con las convenciones como en el
apartado 2.3.4.
pág. 110 Dagoberto Salgado Horta
pág. 111 Dagoberto Salgado Horta
6.9. Estadísticos y análisis exploratorio de datos con Megastat
pág. 112 Dagoberto Salgado Horta
BIBLIOGRAFÍA
• Berenson, Mark. (1.992): Estadística Básica en Administración. Editorial.
Harla. Cuarta Edición. México.
• Best,J. W. (1987): Como Investigar en Educación. Editorial Morata. Madrid
– España.
• Castañeda J., J. (1991): Métodos de Investigación 2. Editorial McGraw-Hill.
México.
• Chao, L.(1993): Estadística para la Ciencia Administrativa. Editorial McGraw
–Hill. 4ta Edición. Colombia
• DANIEL WAYNE, W. y Otros (1993): Estadística con Aplicación a las
Ciencias Sociales y a la Educación Editorial McGraw-Hill Interamericana de
México, S.A. de C.V. México.
• ERKIN KREYSZIA (1978): Introducción a la Estadística Matemática. Editorial
Limusa, S.A. México.
• Gomes Rondón, Francisco (1985): Estadística Metodológica: Ediciones
Fragor. Caracas.
• González, Nijad H. (1986): Métodos estadísticos en Educación. Editorial
Bourgeón, Caracas.
• Mason, Robert (1.992): Estadística para la Administración y Economía.
Ediciones Alfaomega S.A.N. México.
• WALPOLE, R. y Myers, R. (1987): Probabilidad y Estadística para Ingenieros.
Editorial Interamericana. México.
• Webster, Allen L. (1996): Estadística Aplicada a la Empresa y la Economía.
Editorial Irwin. Segunda edición. Barcelona – España.
• Weimer, Richard C. (1996) Estadística. Compañía Editorial Continental, SA
de CV. México.
• Wonnacott, T. H. y Wonnacott, R: J. (1989): Fundamentos de Estadística
para Administración y Economía. Editorial LIMUSA. México.
pág. 113 Dagoberto Salgado Horta
Potrebbero piacerti anche
- Estadística para FinanzasDocumento174 pagineEstadística para FinanzasAlexander TorresNessuna valutazione finora
- Cómo entender estadística fácilmenteDa EverandCómo entender estadística fácilmenteValutazione: 3.5 su 5 stelle3.5/5 (2)
- Ejercicios Informática para EconomistasDocumento3 pagineEjercicios Informática para EconomistasclaudiaNessuna valutazione finora
- Introducción a R y Estadística Descriptiva con menos deDocumento10 pagineIntroducción a R y Estadística Descriptiva con menos deerick ormazaNessuna valutazione finora
- Estadística para Administración y EconomíaDocumento8 pagineEstadística para Administración y EconomíafernandaNessuna valutazione finora
- TALLER Utilidad Total y Marginal DefinitivoDocumento2 pagineTALLER Utilidad Total y Marginal DefinitivoDaniel reyesNessuna valutazione finora
- Ejrcicios Excel Más de 50Documento118 pagineEjrcicios Excel Más de 50kokoxanel50% (2)
- Día 1 - Semana de Power BI PDFDocumento37 pagineDía 1 - Semana de Power BI PDFWilmer CasasNessuna valutazione finora
- Taller Practico ExcelDocumento3 pagineTaller Practico ExcelYami Lujan100% (1)
- Estadística Aplicada - UPCDocumento249 pagineEstadística Aplicada - UPCFabrizio DaHuskyNessuna valutazione finora
- Excel - Todos Los NivelesDocumento7 pagineExcel - Todos Los NivelesHermann Volmar Campos50% (2)
- Estadistica AplicadaDocumento109 pagineEstadistica AplicadaLisbeth PerezNessuna valutazione finora
- Exportar Una Base de Datos en SQL Server A Otro Servidor SQL Server - Videlcloud PDFDocumento6 pagineExportar Una Base de Datos en SQL Server A Otro Servidor SQL Server - Videlcloud PDFJoar RoblesNessuna valutazione finora
- Algoritmo HashingDocumento10 pagineAlgoritmo HashingJulio c ResendizNessuna valutazione finora
- Distribucion LogisticaDocumento3 pagineDistribucion LogisticaYolima VelascoNessuna valutazione finora
- Curso de Eviews GoretacnaDocumento4 pagineCurso de Eviews GoretacnaJuan TonconiNessuna valutazione finora
- Biplot en RDocumento43 pagineBiplot en RLuis BautistaNessuna valutazione finora
- Plan de Negocio para La Creación de Una Empresa de Servicios para El Hogar Por Aplicativo Móvil (App)Documento158 paginePlan de Negocio para La Creación de Una Empresa de Servicios para El Hogar Por Aplicativo Móvil (App)Erland ArredondoNessuna valutazione finora
- Stata 15 Manual para Bases de Enaho 2017 Lns 07819 y 080819Documento57 pagineStata 15 Manual para Bases de Enaho 2017 Lns 07819 y 080819Johann Molina VelardeNessuna valutazione finora
- Diseño Físico de La Base de Datos ACCESSDocumento15 pagineDiseño Físico de La Base de Datos ACCESSJOHAN SEBASTIAN RUEDA NIETONessuna valutazione finora
- Excel Avanzado LauraDocumento120 pagineExcel Avanzado LauraEsmeralda GonzalezNessuna valutazione finora
- RiveraOscar-Consulta Vistas Materializadas en ORACLE PDFDocumento3 pagineRiveraOscar-Consulta Vistas Materializadas en ORACLE PDFÓscar RiveraNessuna valutazione finora
- Tema 1 EconometriaDocumento56 pagineTema 1 EconometriaJesus MoraNessuna valutazione finora
- Tanto Por Ciento-TiDocumento56 pagineTanto Por Ciento-TiSegundo JesusNessuna valutazione finora
- Ejercicios M3Documento8 pagineEjercicios M3Claudia Muñoz0% (2)
- R para profesionales de los datos: una introducción a tablas, vectores, estadística y másDocumento111 pagineR para profesionales de los datos: una introducción a tablas, vectores, estadística y másJuan Pablo Ramirez GallardoNessuna valutazione finora
- FinalDocumento1.604 pagineFinalMiguel Morelos MartinezNessuna valutazione finora
- Practica 1Documento2 paginePractica 1Andres GallardoNessuna valutazione finora
- IPP-Crespo - Métodos Estadísticos - Ejercicios Resueltos y TeoríaDocumento45 pagineIPP-Crespo - Métodos Estadísticos - Ejercicios Resueltos y TeoríaalexandritamibebeNessuna valutazione finora
- Presentación Distribución NormalDocumento25 paginePresentación Distribución NormalSebastian Quispe CapchaNessuna valutazione finora
- Arquitectura DW 8 partesDocumento4 pagineArquitectura DW 8 partesHugo OrdoñezNessuna valutazione finora
- Cómo usar MySQL WorkbenchDocumento8 pagineCómo usar MySQL WorkbenchFabricio IglesiasNessuna valutazione finora
- Analisis de Decisiones 2013 PDFDocumento9 pagineAnalisis de Decisiones 2013 PDFDtriplee EscorpioNessuna valutazione finora
- Ejercicios Funcion SIDocumento2 pagineEjercicios Funcion SIcristhiantavoNessuna valutazione finora
- GE3025 Matemática Comercial - 2010 - Secretariado PDFDocumento88 pagineGE3025 Matemática Comercial - 2010 - Secretariado PDFJuan Jose de LeonNessuna valutazione finora
- Python Ciencia de DatosDocumento3 paginePython Ciencia de DatosPaulNessuna valutazione finora
- Estadística básica actividad 1 datos variables niveles mediciónDocumento6 pagineEstadística básica actividad 1 datos variables niveles mediciónMaría JoséNessuna valutazione finora
- Análisis vs Analítica DatosDocumento4 pagineAnálisis vs Analítica Datoswollydavid tucentramirezNessuna valutazione finora
- Guia Laboratorio - Inteliegencia de NegociosDocumento98 pagineGuia Laboratorio - Inteliegencia de NegociosYanet Sivipaucar Romero100% (1)
- INEI - Metodología para La Elaboración de Un Plan de Sistemas de InformaciónDocumento142 pagineINEI - Metodología para La Elaboración de Un Plan de Sistemas de Informaciónc_chirinosNessuna valutazione finora
- Estadística descriptiva ExcelDocumento10 pagineEstadística descriptiva ExcelWilson JimenezNessuna valutazione finora
- Stata Básico GIDDEADocumento3 pagineStata Básico GIDDEAcgarcia62Nessuna valutazione finora
- Lectura - 2 Gestión de Datos y Gestión Del Cambio OrganizacionalDocumento35 pagineLectura - 2 Gestión de Datos y Gestión Del Cambio OrganizacionalJHEISSON LUIS MEDINA CHANCANessuna valutazione finora
- GUION DE USO DE RDocumento157 pagineGUION DE USO DE RVirginia Huidobro PelayoNessuna valutazione finora
- Evaluación de Power BIDocumento20 pagineEvaluación de Power BIFranz Urb FloNessuna valutazione finora
- Principios Básicos de Internet de Las CosasDocumento34 paginePrincipios Básicos de Internet de Las CosasManuel Azuaje100% (2)
- Estadistica Modulo Del ProfeDocumento102 pagineEstadistica Modulo Del ProfeCelia CáceresNessuna valutazione finora
- Gestión errores RAISERROR SQL y ADO.NETDocumento4 pagineGestión errores RAISERROR SQL y ADO.NETRony OlazabalNessuna valutazione finora
- Trabajo Practico N 1 MatematicaDocumento9 pagineTrabajo Practico N 1 MatematicaJimena Borsatto0% (1)
- Practica SQL PubsDocumento1 paginaPractica SQL PubsRogger Mendo100% (1)
- Capitulo3-Poblar El Data MartDocumento72 pagineCapitulo3-Poblar El Data MartmartinNessuna valutazione finora
- Inteligencia de NegociosDocumento5 pagineInteligencia de NegociosWilliamGuzmánNessuna valutazione finora
- Solucion de Examen 1Documento10 pagineSolucion de Examen 1fernando0% (1)
- Arquitectura ANSI-SPARCDocumento2 pagineArquitectura ANSI-SPARCDiego RoibásNessuna valutazione finora
- tarea1 E1Documento8 paginetarea1 E1Daniel MoreauxNessuna valutazione finora
- Estadística Objetivo Particular: El Estudiante Conocerá Los Conceptos de Estadística, Su Unidad 1: Manejo de DatosDocumento8 pagineEstadística Objetivo Particular: El Estudiante Conocerá Los Conceptos de Estadística, Su Unidad 1: Manejo de DatosEbernaldo Caamal ChanNessuna valutazione finora
- Chino-Estadistica-Descriptiva-2 2Documento10 pagineChino-Estadistica-Descriptiva-2 2api-309389724Nessuna valutazione finora
- Universidad Autónoma Gabriel Rene Moreno Facultad de Ciencias Exactas Y Tecnología Estadística AplicadaDocumento8 pagineUniversidad Autónoma Gabriel Rene Moreno Facultad de Ciencias Exactas Y Tecnología Estadística AplicadaMartha Lucia Gutierrez VelascoNessuna valutazione finora
- Interpretación datos estadísticaDocumento9 pagineInterpretación datos estadísticaHugo Andres Uceda HerreñoNessuna valutazione finora
- De Visita Por Mi BarrioDocumento5 pagineDe Visita Por Mi BarrioJanCa PLNessuna valutazione finora
- AprobadosDocumento3 pagineAprobadosJanCa PLNessuna valutazione finora
- Reloj inteligente palabras claveDocumento4 pagineReloj inteligente palabras claveJanCa PLNessuna valutazione finora
- Fajas MujeresDocumento3 pagineFajas MujeresJanCa PLNessuna valutazione finora
- Seo para TontosDocumento19 pagineSeo para TontosJ Cesar100% (1)
- Sujetadores CargueDocumento4 pagineSujetadores CargueJanCa PLNessuna valutazione finora
- Guía Completa Sobre Buyer Personas y Proceso de CompraDocumento29 pagineGuía Completa Sobre Buyer Personas y Proceso de CompraJanCa PLNessuna valutazione finora
- AprobadosDocumento3 pagineAprobadosJanCa PLNessuna valutazione finora
- Descripcion Apto BmangaDocumento10 pagineDescripcion Apto BmangaJanCa PLNessuna valutazione finora
- Prueba de Busqueda de PalabrasDocumento6 paginePrueba de Busqueda de PalabrasJanCa PLNessuna valutazione finora
- Fajas 2Documento5 pagineFajas 2JanCa PLNessuna valutazione finora
- Palabras Claves para LibrosDocumento5 paginePalabras Claves para LibrosJanCa PLNessuna valutazione finora
- Texto de La QuejaDocumento1 paginaTexto de La QuejaJanCa PLNessuna valutazione finora
- Palanras Cables WebDocumento2 paginePalanras Cables WebJanCa PLNessuna valutazione finora
- Palanras Cables WebDocumento2 paginePalanras Cables WebJanCa PLNessuna valutazione finora
- Palanras Cables WebDocumento2 paginePalanras Cables WebJanCa PLNessuna valutazione finora
- AliExpressDropshippingGuia PDFDocumento26 pagineAliExpressDropshippingGuia PDFEdgar Rodriguez100% (3)
- Truco Filmora Correos Windows y MacDocumento10 pagineTruco Filmora Correos Windows y MacJanCa PLNessuna valutazione finora
- Palabras Claves CursosDocumento6 paginePalabras Claves CursosJanCa PLNessuna valutazione finora
- Palabras Claves 3Documento6 paginePalabras Claves 3JanCa PLNessuna valutazione finora
- Gentilicios Paises 2Documento55 pagineGentilicios Paises 2JanCa PLNessuna valutazione finora
- Formato Pruebas Psicotecnicas y de Personalidad Tecnico V0Documento18 pagineFormato Pruebas Psicotecnicas y de Personalidad Tecnico V0Dayra AyalaNessuna valutazione finora
- Gentilicios Paises 2Documento55 pagineGentilicios Paises 2JanCa PLNessuna valutazione finora
- Palabras Claves Google 2Documento6 paginePalabras Claves Google 2JanCa PLNessuna valutazione finora
- Gentilicios Paises 3Documento2 pagineGentilicios Paises 3JanCa PLNessuna valutazione finora
- Tablas Rapidas y Palabras de TransiciónDocumento13 pagineTablas Rapidas y Palabras de TransiciónJanCa PLNessuna valutazione finora
- Palabras Claves GooglE 1Documento3 paginePalabras Claves GooglE 1JanCa PLNessuna valutazione finora
- Palabras Claves BohoDocumento17 paginePalabras Claves BohoJanCa PLNessuna valutazione finora
- Seo para TontosDocumento19 pagineSeo para TontosJ Cesar100% (1)
- Gestión Del Conocimiento, Ciencia, Tecnología, Sociedad e InnovaciónDocumento4 pagineGestión Del Conocimiento, Ciencia, Tecnología, Sociedad e InnovaciónmarcelaNessuna valutazione finora
- Universidad Central Del Ecuador Facultad de Ciencias Economicas Carrera Estadistica Econometria I Taller: Autocorrelacion Profesor: Nancy Medina CDocumento3 pagineUniversidad Central Del Ecuador Facultad de Ciencias Economicas Carrera Estadistica Econometria I Taller: Autocorrelacion Profesor: Nancy Medina CStalin MNessuna valutazione finora
- sms13 447 MaximoTorrezDocumento3 paginesms13 447 MaximoTorrezMaximo Torrez HuanacuNessuna valutazione finora
- Lab 02 - Excel 2013 - Ingreso y Formato de Datos Operaciones de Edición y Condiguración de PáginaDocumento9 pagineLab 02 - Excel 2013 - Ingreso y Formato de Datos Operaciones de Edición y Condiguración de PáginaAngel Alonso Flores GómezNessuna valutazione finora
- ANÁLISIS NUMÉRICO - Métodos Eliminación Sin Normalizar, Normalizando, Gauss-Jordan, Matriz Inversa, Factorización Lu y Gauss-SeidelDocumento27 pagineANÁLISIS NUMÉRICO - Métodos Eliminación Sin Normalizar, Normalizando, Gauss-Jordan, Matriz Inversa, Factorización Lu y Gauss-SeidelAlex RosasNessuna valutazione finora
- Operaciones Con MatricesDocumento67 pagineOperaciones Con MatricesAndrésNessuna valutazione finora
- 7 hábitos informáticos para mejorar tu productividad y seguridadDocumento2 pagine7 hábitos informáticos para mejorar tu productividad y seguridadLuis VielmanNessuna valutazione finora
- KalfucuraDocumento15 pagineKalfucuraIngridleBrustNessuna valutazione finora
- Capítulo 2 Guía Básica EndurecimientoDocumento57 pagineCapítulo 2 Guía Básica EndurecimientoCrystal BurksNessuna valutazione finora
- Actividad de Aprendizaje 4.3 "Caso Laboratorio Farmacéutico"Documento12 pagineActividad de Aprendizaje 4.3 "Caso Laboratorio Farmacéutico"Jehimy RochaNessuna valutazione finora
- Accionamiento ElectricoDocumento26 pagineAccionamiento ElectricoJuan SotoNessuna valutazione finora
- Taller de ComputacionDocumento55 pagineTaller de ComputacionJésicaMotta100% (1)
- MicrocontroladoresDocumento5 pagineMicrocontroladoresJared DíazNessuna valutazione finora
- 5º Cuaderno de Actividades CompletoDocumento56 pagine5º Cuaderno de Actividades CompletoPaty SotoNessuna valutazione finora
- ReducibilidadDocumento19 pagineReducibilidadAntonio Cardenas GuzmanNessuna valutazione finora
- Circulo Concentrico de La ComunicacionDocumento1 paginaCirculo Concentrico de La ComunicacionKevin Suárez100% (1)
- EasyVista 2008 Brochure SP v2Documento16 pagineEasyVista 2008 Brochure SP v2Joaquin BarreiroNessuna valutazione finora
- Ej 12Documento13 pagineEj 12Katherine Cárdenas100% (1)
- Sistema DRMDocumento22 pagineSistema DRMGanimedesNessuna valutazione finora
- 1 PEC HistoriaAntigua UNED 2019 20Documento10 pagine1 PEC HistoriaAntigua UNED 2019 20José Antonio Diéguez MármolNessuna valutazione finora
- Agente de Call CenterDocumento4 pagineAgente de Call CenterYossi ArabNessuna valutazione finora
- Cuadro ComparativoDocumento5 pagineCuadro ComparativoJUAN ERICK ALEJANDRO PU USNessuna valutazione finora
- ExelenteDocumento37 pagineExelentecristian ariel pinto veizaga100% (1)
- Enrutamiento Dinámico EIGRPDocumento7 pagineEnrutamiento Dinámico EIGRPHector AmayaNessuna valutazione finora
- 4° Unidades y Colegio en CasaDocumento22 pagine4° Unidades y Colegio en CasaMaria Angelica Moreno ChavezNessuna valutazione finora
- (RSH) - Paso A Paso - UMTS+LTE SHARING 1900 - v3 - AMDocumento39 pagine(RSH) - Paso A Paso - UMTS+LTE SHARING 1900 - v3 - AMJuancho SilvaNessuna valutazione finora
- Postgresql ExpoDocumento14 paginePostgresql Expojhoselyn jara espinozaNessuna valutazione finora
- Instrucciones Examen WordDocumento2 pagineInstrucciones Examen WordFran Gimeno100% (2)
- Manejo de Objetos de Autorizacion Modulo de MMDocumento41 pagineManejo de Objetos de Autorizacion Modulo de MMCampo PallaresNessuna valutazione finora
- Trabajo de Teoría de ColasDocumento9 pagineTrabajo de Teoría de ColasJhorsyGonzálesArroyoNessuna valutazione finora