Potrebbero piacerti anche
- The Judicial Affidavit RuleDocumento20 pagineThe Judicial Affidavit RuleMhay ReyesNessuna valutazione finora
- Mobile NetworkingDocumento26 pagineMobile NetworkingAlexander PhiriNessuna valutazione finora
- Introduction To Computer SecurityDocumento22 pagineIntroduction To Computer SecurityJunaedi PratamaNessuna valutazione finora
- Laude vs. Ginez-Jabalde (MCLE)Documento29 pagineLaude vs. Ginez-Jabalde (MCLE)Justin CebrianNessuna valutazione finora
- IoT Network Project ProposalDocumento5 pagineIoT Network Project ProposalTapas KashyapNessuna valutazione finora
- List of Evolutionary AlgorithmsDocumento7 pagineList of Evolutionary AlgorithmsCmpt CmptNessuna valutazione finora
- Detect plant diseases using deep learningDocumento17 pagineDetect plant diseases using deep learningSuresh BalpandeNessuna valutazione finora
- Manage Hospital Records with HMSDocumento16 pagineManage Hospital Records with HMSDev SoniNessuna valutazione finora
- A Survey and Analysis of Intrusion Detection Models Based On Information Security and Object Technology-Cloud Intrusion DatasetDocumento8 pagineA Survey and Analysis of Intrusion Detection Models Based On Information Security and Object Technology-Cloud Intrusion DatasetIAES IJAINessuna valutazione finora
- Cast Resin Busduct PDFDocumento48 pagineCast Resin Busduct PDFanand2k1100% (1)
- Asn 1Documento25 pagineAsn 1Yukti SharmaNessuna valutazione finora
- Lung Cancer Detection Using Machine Learning IJERTCONV7IS01011Documento6 pagineLung Cancer Detection Using Machine Learning IJERTCONV7IS01011MasToro ShadiqNessuna valutazione finora
- Face Mask Detector: A Project Report Submitted in Partial Fulfillment of The Requirement For The Award of The Degree ofDocumento28 pagineFace Mask Detector: A Project Report Submitted in Partial Fulfillment of The Requirement For The Award of The Degree ofZakaria ElasriNessuna valutazione finora
- Intrusion Detection Techniques in Mobile NetworksDocumento8 pagineIntrusion Detection Techniques in Mobile NetworksInternational Organization of Scientific Research (IOSR)Nessuna valutazione finora
- Convolutional Neural Networks FOR IMAGE CLASSIFICATIONDocumento22 pagineConvolutional Neural Networks FOR IMAGE CLASSIFICATIONPrashanth Reddy SamaNessuna valutazione finora
- Malicious URL Detection Using Machine Learning 2Documento24 pagineMalicious URL Detection Using Machine Learning 2Nguyễn Hà PhươngNessuna valutazione finora
- Face Mask Detection using YOLO v3Documento84 pagineFace Mask Detection using YOLO v3Trung Huynh KienNessuna valutazione finora
- Final Mother DairyDocumento59 pagineFinal Mother DairyAnup Dcruz100% (4)
- ML Algorithm EvolutionDocumento21 pagineML Algorithm Evolutionrahul dravidNessuna valutazione finora
- Research Methods in Machine Learning: A Content Analysis: Jackson Kamiri Geoffrey MarigaDocumento14 pagineResearch Methods in Machine Learning: A Content Analysis: Jackson Kamiri Geoffrey MarigaAmir hilmiNessuna valutazione finora
- Application of Machine Learning in CybersecurityDocumento19 pagineApplication of Machine Learning in Cybersecuritypratap100% (1)
- Deep LearningDocumento10 pagineDeep LearningKanishka Singh RaghuvanshiNessuna valutazione finora
- DATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABDa EverandDATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABNessuna valutazione finora
- Vanet PresentationDocumento8 pagineVanet Presentationchaitanya gavitNessuna valutazione finora
- VANET SimulationDocumento16 pagineVANET SimulationSujesh P Lal100% (3)
- Challenges in Mobile SecurityDocumento8 pagineChallenges in Mobile SecurityGyhgy EwfdewNessuna valutazione finora
- Unit 1 - Computing ParadigmsDocumento31 pagineUnit 1 - Computing ParadigmsDr.Ramesh Babu PittalaNessuna valutazione finora
- Cloud Computing-CSA Architecture.Documento13 pagineCloud Computing-CSA Architecture.Santhiya RNessuna valutazione finora
- A New Direction For Computer Architecture ResearchDocumento10 pagineA New Direction For Computer Architecture ResearchdbpublicationsNessuna valutazione finora
- Cloud & Virtualisation SeminarDocumento21 pagineCloud & Virtualisation Seminaranupamjha AnuNessuna valutazione finora
- VANETDocumento123 pagineVANETNabeel ShahoodNessuna valutazione finora
- Proceedings ICINC19 PDFDocumento549 pagineProceedings ICINC19 PDFAakash Patil100% (1)
- Finite Automata and ApplicationsDocumento31 pagineFinite Automata and ApplicationsNihad HasanovićNessuna valutazione finora
- Web MiningDocumento22 pagineWeb MiningPriya AgrawalNessuna valutazione finora
- GCC Unit 1Documento83 pagineGCC Unit 1Bhargava TipirisettyNessuna valutazione finora
- Big Data and Cloud ComputingDocumento27 pagineBig Data and Cloud ComputingShreeRoopaUNessuna valutazione finora
- Mentum Planet 5 CoreDocumento50 pagineMentum Planet 5 CoreAnkit NarangNessuna valutazione finora
- Thesis ReportDocumento31 pagineThesis ReportRachit BhargavaNessuna valutazione finora
- Data security methods and approaches in cloud computingDocumento3 pagineData security methods and approaches in cloud computingMahimaKadyanNessuna valutazione finora
- Analysis of Women Safety in Indian Cities Using Machine Learning On TweetsDocumento44 pagineAnalysis of Women Safety in Indian Cities Using Machine Learning On TweetsSandesh RameshNessuna valutazione finora
- Chapter Two (Network Thesis Book)Documento16 pagineChapter Two (Network Thesis Book)Latest Tricks100% (1)
- Module 1-Part 1Documento16 pagineModule 1-Part 1vkamble1990Nessuna valutazione finora
- Blockchain-Based Intelligent Vehicle Data Sharing FrameworkDocumento4 pagineBlockchain-Based Intelligent Vehicle Data Sharing FrameworkAli AliNessuna valutazione finora
- Network Security and Cryptography Dr.P.rizwan AhmedDocumento6 pagineNetwork Security and Cryptography Dr.P.rizwan AhmedRizwan AhmedNessuna valutazione finora
- Android Mobile Application For Online Bus Booking SystemDocumento24 pagineAndroid Mobile Application For Online Bus Booking Systemaishwarya kulkarniNessuna valutazione finora
- Privacy and Data Security in Internet of Things: Arun Nagaraja and N. RajasekharDocumento13 paginePrivacy and Data Security in Internet of Things: Arun Nagaraja and N. RajasekharrajeshNessuna valutazione finora
- A Survey of IoT Security Based On A Layered Architecture of Sensing and Data Analysis-Sensors-20-03625-V4Documento19 pagineA Survey of IoT Security Based On A Layered Architecture of Sensing and Data Analysis-Sensors-20-03625-V4xyzabcd12Nessuna valutazione finora
- Detection of Phishing URLs Using Machine LearningDocumento6 pagineDetection of Phishing URLs Using Machine LearningRokibul hasanNessuna valutazione finora
- Skin Cancer Malignancy Classification With Transfer LearningDocumento80 pagineSkin Cancer Malignancy Classification With Transfer LearningIlyasse Chemlal100% (1)
- Enabling Technologies and Federated CloudDocumento38 pagineEnabling Technologies and Federated Cloudasd100% (1)
- Evolution of Cloud ComputingDocumento20 pagineEvolution of Cloud ComputingPonHarshavardhananNessuna valutazione finora
- Cloud Computing Big Data TechnologyDocumento2 pagineCloud Computing Big Data TechnologyAjaysen R VangoorNessuna valutazione finora
- 3g Mobile ComputingDocumento17 pagine3g Mobile ComputingswethaTMRNessuna valutazione finora
- Report VHDL PDFDocumento31 pagineReport VHDL PDFShailesh PrajapatiNessuna valutazione finora
- Energy Efficient Routing Protocols For Wireless Sensor Networks: A SurveyDocumento6 pagineEnergy Efficient Routing Protocols For Wireless Sensor Networks: A SurveyAshish D PatelNessuna valutazione finora
- ML Notes Unit 1-2Documento55 pagineML Notes Unit 1-2Mudit MattaNessuna valutazione finora
- Networking ReportDocumento25 pagineNetworking ReportyogeshNessuna valutazione finora
- Practical Part 2Documento143 paginePractical Part 2HARSH SAVALIYANessuna valutazione finora
- An Recommendation Algorithm Based On Weighted Slope One Algorithm and User-Based Collaborative FilteringDocumento4 pagineAn Recommendation Algorithm Based On Weighted Slope One Algorithm and User-Based Collaborative FilteringDavid Carpio R.Nessuna valutazione finora
- IDS Using Deep LearningDocumento5 pagineIDS Using Deep LearningPranava PranuNessuna valutazione finora
- Implementation of A New Lightweight Encryption Design For Embedded SecurityDocumento10 pagineImplementation of A New Lightweight Encryption Design For Embedded SecurityitzGeekInsideNessuna valutazione finora
- Top 10 List of Network Simulation Tools - Downloadable Link InsideDocumento20 pagineTop 10 List of Network Simulation Tools - Downloadable Link InsiderainydaesNessuna valutazione finora
- 6genesis Flagship Program - Building The Bridges Towards 6G-Enabled Wireless Smart Society and EcosystemDocumento6 pagine6genesis Flagship Program - Building The Bridges Towards 6G-Enabled Wireless Smart Society and EcosystemSamuel BorgesNessuna valutazione finora
- Introduction To VanetsDocumento15 pagineIntroduction To Vanetsgagans137Nessuna valutazione finora
- Machine-to-Machine M2M Communications Third EditionDa EverandMachine-to-Machine M2M Communications Third EditionNessuna valutazione finora
- Google:Management Philosophy A Study in Leadership Through Inspiration and RewardDocumento5 pagineGoogle:Management Philosophy A Study in Leadership Through Inspiration and RewardZachary StandridgeNessuna valutazione finora
- Department of Homeland Security Information Assurance and Cybersecurity Potential FlawsDocumento6 pagineDepartment of Homeland Security Information Assurance and Cybersecurity Potential FlawsZachary StandridgeNessuna valutazione finora
- 2016 Dyn CyberattackDocumento5 pagine2016 Dyn CyberattackZachary StandridgeNessuna valutazione finora
- Identity Theft SecurityDocumento12 pagineIdentity Theft SecurityAnonymous YgND8ONessuna valutazione finora
- 5Documento6 pagine5Zachary StandridgeNessuna valutazione finora
- Performance Management TransformationDocumento5 paginePerformance Management TransformationZachary StandridgeNessuna valutazione finora
- A Case Study in The Origins, Evolution, and Activities of Internet Service Providers Case Study ReportDocumento5 pagineA Case Study in The Origins, Evolution, and Activities of Internet Service Providers Case Study ReportZachary StandridgeNessuna valutazione finora
- Benefits of Having A Gnatt Chart in The Project Charter. A Project Manager Best FriendDocumento4 pagineBenefits of Having A Gnatt Chart in The Project Charter. A Project Manager Best FriendZachary StandridgeNessuna valutazione finora
- 1Documento2 pagine1Zachary StandridgeNessuna valutazione finora
- MONETARY POLICY OBJECTIVES AND APPROACHESDocumento2 pagineMONETARY POLICY OBJECTIVES AND APPROACHESMarielle Catiis100% (1)
- Shrey's PHP - PracticalDocumento46 pagineShrey's PHP - PracticalNahi PataNessuna valutazione finora
- The Problem and Its SettingDocumento36 pagineThe Problem and Its SettingRodel CamposoNessuna valutazione finora
- Motorola l6Documento54 pagineMotorola l6Marcelo AriasNessuna valutazione finora
- Business Study Quarterly Paper by Vijay SirDocumento3 pagineBusiness Study Quarterly Paper by Vijay Sirmonish vikramNessuna valutazione finora
- ROUTERDocumento26 pagineROUTERIsraelNessuna valutazione finora
- ION8650 DatasheetDocumento11 pagineION8650 DatasheetAlthaf Axel HiroshiNessuna valutazione finora
- Leader in CSR 2020: A Case Study of Infosys LTDDocumento19 pagineLeader in CSR 2020: A Case Study of Infosys LTDDr.Rashmi GuptaNessuna valutazione finora
- SESSON 1,2 AND 3 use casesDocumento23 pagineSESSON 1,2 AND 3 use casessunilsionNessuna valutazione finora
- An - APX18 206516L CT0Documento2 pagineAn - APX18 206516L CT0Maria MartinsNessuna valutazione finora
- Direct FileActDocumento17 pagineDirect FileActTAPAN TALUKDARNessuna valutazione finora
- Philips Lighting Annual ReportDocumento158 paginePhilips Lighting Annual ReportOctavian Andrei NanciuNessuna valutazione finora
- Wizard's App Pitch Deck by SlidesgoDocumento52 pagineWizard's App Pitch Deck by SlidesgoandreaNessuna valutazione finora
- TMS Software ProductsDocumento214 pagineTMS Software ProductsRomica SauleaNessuna valutazione finora
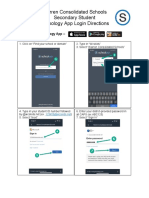
- Schoology App Login DirectionsDocumento5 pagineSchoology App Login Directionsapi-234989244Nessuna valutazione finora
- Klasifikasi Industri Perusahaan TercatatDocumento39 pagineKlasifikasi Industri Perusahaan TercatatFz FuadiNessuna valutazione finora
- 1 s2.0 S0313592622001369 MainDocumento14 pagine1 s2.0 S0313592622001369 MainNGOC VO LE THANHNessuna valutazione finora
- Block P2P Traffic with pfSense using Suricata IPSDocumento6 pagineBlock P2P Traffic with pfSense using Suricata IPSEder Luiz Alves PintoNessuna valutazione finora
- Tugasan HBMT 4303Documento20 pagineTugasan HBMT 4303normahifzanNessuna valutazione finora
- Section 2 in The Forest (Conservation) Act, 1980Documento1 paginaSection 2 in The Forest (Conservation) Act, 1980amit singhNessuna valutazione finora
- Lifetime Physical Fitness and Wellness A Personalized Program 14th Edition Hoeger Test BankDocumento34 pagineLifetime Physical Fitness and Wellness A Personalized Program 14th Edition Hoeger Test Bankbefoolabraida9d6xm100% (27)
- ReportDocumento4 pagineReportapi-463513182Nessuna valutazione finora
- JIG LFO Pack 231 PDFDocumento16 pagineJIG LFO Pack 231 PDFPratiek RaulNessuna valutazione finora
- Ap22 FRQ World History ModernDocumento13 pagineAp22 FRQ World History ModernDylan DanovNessuna valutazione finora
- Apple Led Cinema Display 24inchDocumento84 pagineApple Led Cinema Display 24inchSantos MichelNessuna valutazione finora