Potrebbero piacerti anche
- HW 11Documento8 pagineHW 11api-465474049Nessuna valutazione finora
- function: 計財系碩一 108071603 黃偉德 1. LookbackcallmcDocumento7 paginefunction: 計財系碩一 108071603 黃偉德 1. Lookbackcallmcapi-516881339Nessuna valutazione finora
- HW 10Documento4 pagineHW 10api-516646274Nessuna valutazione finora
- Function: % Generate Asset PathsDocumento5 pagineFunction: % Generate Asset Pathsapi-516881339Nessuna valutazione finora
- New Microsoft Word Document 1Documento4 pagineNew Microsoft Word Document 1api-516881339Nessuna valutazione finora
- HW 12Documento3 pagineHW 12api-463579132Nessuna valutazione finora
- HW 9Documento11 pagineHW 9api-465474049Nessuna valutazione finora
- % BLSMC.M: FunctionDocumento4 pagine% BLSMC.M: Functionapi-516881339Nessuna valutazione finora
- Listing Code Voice RecognitionDocumento11 pagineListing Code Voice RecognitionRivanto ParungNessuna valutazione finora
- % BPSKDocumento10 pagine% BPSKMajd ShakhatrehNessuna valutazione finora
- HW 14Documento12 pagineHW 14api-465474049Nessuna valutazione finora
- HW 9Documento11 pagineHW 9api-289065336Nessuna valutazione finora
- Name: Dhruvil K Kotecha ID No.: 17CP024 Sub. Code: CP-402 Sub. Name: ADT Semester: 7 Year: 2020/21Documento30 pagineName: Dhruvil K Kotecha ID No.: 17CP024 Sub. Code: CP-402 Sub. Name: ADT Semester: 7 Year: 2020/21Dhruvil KotechaNessuna valutazione finora
- HW 14Documento4 pagineHW 14api-463579132Nessuna valutazione finora
- %初始化 %¸个体经验保留 %全局经验保留 %×最大迭代次数 %%微粒数 %问题的规模(城市规模) %迭代计数器 %¸各代最佳路线 % 各代最佳路线的长度 %¸各代路线的平均长度 %产生微粒数的初始位置 for i=1:mDocumento3 pagine%初始化 %¸个体经验保留 %全局经验保留 %×最大迭代次数 %%微粒数 %问题的规模(城市规模) %迭代计数器 %¸各代最佳路线 % 各代最佳路线的长度 %¸各代路线的平均长度 %产生微粒数的初始位置 for i=1:mDIONLY oneNessuna valutazione finora
- 6 F 193483165 D 13 F 6255 ADocumento15 pagine6 F 193483165 D 13 F 6255 Aapi-616455436Nessuna valutazione finora
- PycwtDocumento2 paginePycwtBayu PinTnanNessuna valutazione finora
- HW 6Documento13 pagineHW 6api-465474049Nessuna valutazione finora
- AppendixDocumento19 pagineAppendixDr-Eng Imad A. ShaheenNessuna valutazione finora
- Finite ExplicitDocumento2 pagineFinite ExplicithlvijaykumarNessuna valutazione finora
- % Bsformula.mDocumento30 pagine% Bsformula.mapi-616455436Nessuna valutazione finora
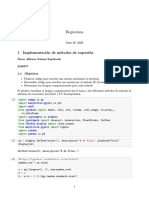
- Regression: 1 Implementación de Métodos de RegresiónDocumento11 pagineRegression: 1 Implementación de Métodos de RegresiónÓscar Alfonso Gómez SepúlvedaNessuna valutazione finora
- % Ex. 1 % % QPSK % Uncorrelated Rayleigh % ML Detection % Spatial Multiplexing % % Comparing The Optimal ML Decoder With The Simple ZF DecoderDocumento2 pagine% Ex. 1 % % QPSK % Uncorrelated Rayleigh % ML Detection % Spatial Multiplexing % % Comparing The Optimal ML Decoder With The Simple ZF DecoderCharu ShreeNessuna valutazione finora
- Digital Modulation and DemodulationDocumento11 pagineDigital Modulation and DemodulationpoornimaNessuna valutazione finora
- All All: Program 2Documento2 pagineAll All: Program 2HARIPRASATH ECENessuna valutazione finora
- CT 303 Digital Communications Lab 9: Heer Gohil 201901135Documento25 pagineCT 303 Digital Communications Lab 9: Heer Gohil 201901135H GNessuna valutazione finora
- Untitled: Markowitz Efficient FrontierDocumento9 pagineUntitled: Markowitz Efficient Frontierakash srivastavaNessuna valutazione finora
- Delta and Adaptive Delta ModulationDocumento6 pagineDelta and Adaptive Delta Modulationabc abcNessuna valutazione finora
- Computational FinanceDocumento19 pagineComputational FinancePrateek BhatnagarNessuna valutazione finora
- Membangkitkan Signal: All TT - SFDocumento8 pagineMembangkitkan Signal: All TT - SFIsa MahfudiNessuna valutazione finora
- Lab#9: Steady State Error Analysis and DesignDocumento9 pagineLab#9: Steady State Error Analysis and DesignHammad SattiNessuna valutazione finora
- Multi TP StrategyDocumento3 pagineMulti TP StrategyyusakulworkNessuna valutazione finora
- Dem SupDocumento5 pagineDem SupBurak AydınNessuna valutazione finora
- Verilog Modules For Common Digital FunctionsDocumento30 pagineVerilog Modules For Common Digital Functionssudarshan poojaryNessuna valutazione finora
- ReporteDocumento9 pagineReporteRenato Sebastian Rodriguez LlanosNessuna valutazione finora
- ECE ProgramDocumento7 pagineECE Programrakshithaa k.s.Nessuna valutazione finora
- Monte Carlo SimulationDocumento70 pagineMonte Carlo SimulationJano Lima100% (2)
- Tugas 1 Zani AkbariDocumento7 pagineTugas 1 Zani AkbariIsa MahfudiNessuna valutazione finora
- HW 6Documento5 pagineHW 6api-289381985Nessuna valutazione finora
- Código em MATLAB 5Documento6 pagineCódigo em MATLAB 5SOST HUMAPNessuna valutazione finora
- Sem 5Documento25 pagineSem 5koulickchakraborty5555Nessuna valutazione finora
- EC1306 Digital Signal Processing Laboratory (REC)Documento50 pagineEC1306 Digital Signal Processing Laboratory (REC)jeyaganesh100% (1)
- Assignment-1 & 2 (MST) : Submitted by - Name - Shailendra Yadav - (21DR0165)Documento5 pagineAssignment-1 & 2 (MST) : Submitted by - Name - Shailendra Yadav - (21DR0165)Shailendra YadavNessuna valutazione finora
- CodeDocumento5 pagineCodeAbhay SharmaNessuna valutazione finora
- R Tools For Portfolio OptimizationDocumento38 pagineR Tools For Portfolio OptimizationlycancapitalNessuna valutazione finora
- Tutorial Questions On Fuzzy Logic 1. A Triangular Member Function Shown in Figure Is To Be Made in MATLAB. Write A Function. Answer: CodeDocumento13 pagineTutorial Questions On Fuzzy Logic 1. A Triangular Member Function Shown in Figure Is To Be Made in MATLAB. Write A Function. Answer: Codekiran preethiNessuna valutazione finora
- Kal013 000000000034b64bDocumento5 pagineKal013 000000000034b64bDivyansh VermaNessuna valutazione finora
- Simulation of Signal Constellations ofDocumento19 pagineSimulation of Signal Constellations ofThahsin ThahirNessuna valutazione finora
- 7 To 10Documento11 pagine7 To 10Ayush ShuklaNessuna valutazione finora
- Verilog ProgramsDocumento40 pagineVerilog ProgramssundaraiahNessuna valutazione finora
- HW 7Documento3 pagineHW 7api-289381985Nessuna valutazione finora
- Multisort Omp Cut - Off.cDocumento5 pagineMultisort Omp Cut - Off.cchristianchavezapNessuna valutazione finora
- CLT (.TXT File)Documento8 pagineCLT (.TXT File)Shaun KradolferNessuna valutazione finora
- fivelumpRB VRmodelParameterDocumento5 paginefivelumpRB VRmodelParameterSopan Ram TambekarNessuna valutazione finora
- 02-Matlab Subroutines Used in The SimulationDocumento17 pagine02-Matlab Subroutines Used in The Simulationtrivedi_urvi9087Nessuna valutazione finora
- All All: Main - Ident.mDocumento10 pagineAll All: Main - Ident.mAndrés Santiago AriasNessuna valutazione finora
- Program Utama Cat Swarm OptimizationDocumento5 pagineProgram Utama Cat Swarm OptimizationRandhani AgusNessuna valutazione finora
- Ritik Raj Kumar - 16500119022 - DAA LABDocumento49 pagineRitik Raj Kumar - 16500119022 - DAA LABRitik guptaNessuna valutazione finora
- HW 14Documento12 pagineHW 14api-465474049Nessuna valutazione finora
- HW 6Documento13 pagineHW 6api-465474049Nessuna valutazione finora
- HW 9Documento11 pagineHW 9api-465474049Nessuna valutazione finora
- HW 4Documento5 pagineHW 4api-465474049Nessuna valutazione finora
- HW 5Documento12 pagineHW 5api-465474049Nessuna valutazione finora
- HW 3Documento8 pagineHW 3api-465474049Nessuna valutazione finora
- HW 2Documento5 pagineHW 2api-465474049Nessuna valutazione finora
- HW 1Documento3 pagineHW 1api-465474049Nessuna valutazione finora
- House of Wisdom - Bayt Al Hikma (For Recording) - ArDocumento83 pagineHouse of Wisdom - Bayt Al Hikma (For Recording) - ArMaeda KNessuna valutazione finora
- Managing Individual Differences and BehaviorDocumento40 pagineManaging Individual Differences and BehaviorDyg Norjuliani100% (1)
- Spoken KashmiriDocumento120 pagineSpoken KashmiriGourav AroraNessuna valutazione finora
- Chapter-British Parliamentary Debate FormatDocumento8 pagineChapter-British Parliamentary Debate FormatNoelle HarrisonNessuna valutazione finora
- 5 Reported Speech - T16-6 PracticeDocumento3 pagine5 Reported Speech - T16-6 Practice39 - 11A11 Hoàng Ái TúNessuna valutazione finora
- Audi A4 Quattro 3.0 Liter 6-Cyl. 5V Fuel Injection & IgnitionDocumento259 pagineAudi A4 Quattro 3.0 Liter 6-Cyl. 5V Fuel Injection & IgnitionNPNessuna valutazione finora
- Leseprobe Aus: "Multilingualism in The Movies" Von Lukas BleichenbacherDocumento20 pagineLeseprobe Aus: "Multilingualism in The Movies" Von Lukas BleichenbachernarrverlagNessuna valutazione finora
- t10 2010 Jun QDocumento10 paginet10 2010 Jun QAjay TakiarNessuna valutazione finora
- HeavyReding ReportDocumento96 pagineHeavyReding ReportshethNessuna valutazione finora
- 2.2 Push and Pull Sources of InnovationDocumento16 pagine2.2 Push and Pull Sources of Innovationbclarke113Nessuna valutazione finora
- Sigmund Freud 1Documento3 pagineSigmund Freud 1sharoff saakshiniNessuna valutazione finora
- Rizal Course ReviewerDocumento6 pagineRizal Course ReviewerMarianne AtienzaNessuna valutazione finora
- Self-Learning Home Task (SLHT) : Key Drawings and Animation BreakdownsDocumento6 pagineSelf-Learning Home Task (SLHT) : Key Drawings and Animation BreakdownsRUFINO MEDICONessuna valutazione finora
- Psi SiDocumento3 paginePsi Siapi-19973617Nessuna valutazione finora
- Operate A Word Processing Application BasicDocumento46 pagineOperate A Word Processing Application Basicapi-24787158267% (3)
- Engineering Academy: ESE Conventional Revision TEST - IDocumento8 pagineEngineering Academy: ESE Conventional Revision TEST - Ividya chakitwarNessuna valutazione finora
- Introducing Identity - SummaryDocumento4 pagineIntroducing Identity - SummarylkuasNessuna valutazione finora
- K Unit 1 SeptemberDocumento2 pagineK Unit 1 Septemberapi-169447826Nessuna valutazione finora
- Lista Materijala WordDocumento8 pagineLista Materijala WordAdis MacanovicNessuna valutazione finora
- Instructional Supervisory Plan BITDocumento7 pagineInstructional Supervisory Plan BITjeo nalugon100% (2)
- Project Report: Eveplus Web PortalDocumento47 pagineProject Report: Eveplus Web Portaljas121Nessuna valutazione finora
- Happiness Portrayal and Level of Self-Efficacy Among Public Elementary School Heads in A DivisionDocumento13 pagineHappiness Portrayal and Level of Self-Efficacy Among Public Elementary School Heads in A DivisionPsychology and Education: A Multidisciplinary JournalNessuna valutazione finora
- Adventure Shorts Volume 1 (5e)Documento20 pagineAdventure Shorts Volume 1 (5e)admiralpumpkin100% (5)
- Equilibrium of Firm Under Perfect Competition: Presented by Piyush Kumar 2010EEE023Documento18 pagineEquilibrium of Firm Under Perfect Competition: Presented by Piyush Kumar 2010EEE023a0mittal7Nessuna valutazione finora
- Kingdom AnimaliaDocumento13 pagineKingdom AnimaliaAryanNessuna valutazione finora
- A Terence McKenna Audio Archive - Part 1Documento203 pagineA Terence McKenna Audio Archive - Part 1BabaYagaNessuna valutazione finora
- Phonetic Sounds (Vowel Sounds and Consonant Sounds)Documento48 paginePhonetic Sounds (Vowel Sounds and Consonant Sounds)Jayson Donor Zabala100% (1)
- Karaf-Usermanual-2 2 2Documento147 pagineKaraf-Usermanual-2 2 2aaaeeeiiioooNessuna valutazione finora
- Mushoku Tensei Volume 2Documento179 pagineMushoku Tensei Volume 2Bismillah Dika2020Nessuna valutazione finora
- Human Right and Humanitarian. by Solicitor KaturaDocumento12 pagineHuman Right and Humanitarian. by Solicitor KaturaFlavian PangahNessuna valutazione finora