Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Lambda-Calculus, Combinators and Functional Programming PDFDocumento194 pagineLambda-Calculus, Combinators and Functional Programming PDFMadhusoodan Shanbhag100% (2)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Lec 3Documento76 pagineLec 3kuku288Nessuna valutazione finora
- Semi-Supervised Learning A Brief ReviewDocumento6 pagineSemi-Supervised Learning A Brief ReviewReshma KhemchandaniNessuna valutazione finora
- Journal Pone 0247330Documento14 pagineJournal Pone 0247330viju001Nessuna valutazione finora
- Air Quality2Documento11 pagineAir Quality2viju001Nessuna valutazione finora
- Jurisoo Tarkvaratehnika 2017Documento45 pagineJurisoo Tarkvaratehnika 2017viju001Nessuna valutazione finora
- Silviu Risco ThesisDocumento308 pagineSilviu Risco Thesisviju001Nessuna valutazione finora
- A Detailed Excursion On Machine Learning Approach, Algorithms and ApplicationsDocumento8 pagineA Detailed Excursion On Machine Learning Approach, Algorithms and Applicationsviju001Nessuna valutazione finora
- Energy Efficiency Techniques in Cloud CoDocumento7 pagineEnergy Efficiency Techniques in Cloud Coviju001Nessuna valutazione finora
- Deep Recurrent Level Set For Segmenting Brain TumorsDocumento8 pagineDeep Recurrent Level Set For Segmenting Brain Tumorsviju001Nessuna valutazione finora
- LubnaAlhenaki Project4Documento20 pagineLubnaAlhenaki Project4viju001Nessuna valutazione finora
- State Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest CertificateDocumento1 paginaState Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest Certificateviju001100% (1)
- Using Using Using Using Using Using Using Using Using Namespace Public Partial ClassDocumento14 pagineUsing Using Using Using Using Using Using Using Using Namespace Public Partial Classviju001Nessuna valutazione finora
- Big Data Analytics in Supply Chain Management: A Systematic Literature Review and Research DirectionsDocumento29 pagineBig Data Analytics in Supply Chain Management: A Systematic Literature Review and Research Directionsviju001Nessuna valutazione finora
- Data Mining Analysis of The Parkinsons DiseaseDocumento107 pagineData Mining Analysis of The Parkinsons Diseaseviju001Nessuna valutazione finora
- Handling Missing Data Analysis of A Challenging Data Set Using Multiple ImputationDocumento20 pagineHandling Missing Data Analysis of A Challenging Data Set Using Multiple Imputationviju001Nessuna valutazione finora
- Biometric Fingerprint Student Attendance System: Software Requirement SpecificationsDocumento19 pagineBiometric Fingerprint Student Attendance System: Software Requirement Specificationsviju001Nessuna valutazione finora
- Support Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball ClusteringDocumento9 pagineSupport Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball Clusteringviju001Nessuna valutazione finora
- A New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita NathDocumento5 pagineA New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita Nathviju001Nessuna valutazione finora
- Fingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya MishraDocumento5 pagineFingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya Mishraviju001Nessuna valutazione finora
- 10 - Chapter 1Documento22 pagine10 - Chapter 1viju001Nessuna valutazione finora
- Fingerprint Orientation Field Enhancement: April 2011Documento9 pagineFingerprint Orientation Field Enhancement: April 2011viju001Nessuna valutazione finora
- Fingerprint Enhancement Using Improved Orientation and Circular Gabor FilterDocumento7 pagineFingerprint Enhancement Using Improved Orientation and Circular Gabor Filterviju001Nessuna valutazione finora
- Iot Based Biometric Attendance System Using ArduinoDocumento108 pagineIot Based Biometric Attendance System Using Arduinoviju001Nessuna valutazione finora
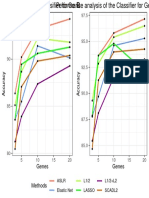
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Documento1 paginaGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001Nessuna valutazione finora
- 04 - Chapter 1Documento19 pagine04 - Chapter 1viju001Nessuna valutazione finora
- 14 - Chapter 6Documento7 pagine14 - Chapter 6viju001Nessuna valutazione finora
- T.A. & D.A. BillDocumento1 paginaT.A. & D.A. Billviju001Nessuna valutazione finora
- 06 - Chapter 3Documento36 pagine06 - Chapter 3viju001Nessuna valutazione finora
- Literature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle PrintDocumento24 pagineLiterature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle Printviju001Nessuna valutazione finora
- Decision Making With Unknown Data: Development of ELECTRE Method Based On Black NumbersDocumento16 pagineDecision Making With Unknown Data: Development of ELECTRE Method Based On Black Numbersviju001Nessuna valutazione finora
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Documento1 paginaGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001Nessuna valutazione finora
- The Superposition PrincipleDocumento10 pagineThe Superposition Principleapi-253529097Nessuna valutazione finora
- N Celebrity AlgorithmDocumento4 pagineN Celebrity AlgorithmKundai MujatiNessuna valutazione finora
- Java MCQDocumento13 pagineJava MCQAlan Joe100% (1)
- DSP Tutorial QuestionsDocumento6 pagineDSP Tutorial Questionschristina90Nessuna valutazione finora
- Floyd-Warshall AlgorithmDocumento6 pagineFloyd-Warshall Algorithmbartee000Nessuna valutazione finora
- On Some Properties of Humbert'S Polynomials: G. V - MilovanovicDocumento5 pagineOn Some Properties of Humbert'S Polynomials: G. V - MilovanovicCharlie PinedoNessuna valutazione finora
- Newton-Raphson Method: Assumptions Interpretation Examples Convergence Analysis Reading AssignmentDocumento46 pagineNewton-Raphson Method: Assumptions Interpretation Examples Convergence Analysis Reading AssignmentPradhabhan RajNessuna valutazione finora
- LPP (Tableau Method)Documento7 pagineLPP (Tableau Method)Ryan Azim ShaikhNessuna valutazione finora
- UsageDocumento263 pagineUsageTairo RobertoNessuna valutazione finora
- Data Structures and Algorithms Algorithms in C++: Jordi Petit Salvador Roura Albert AtseriasDocumento69 pagineData Structures and Algorithms Algorithms in C++: Jordi Petit Salvador Roura Albert AtseriasMohamed YassineNessuna valutazione finora
- Polynomials - 2Documento2 paginePolynomials - 2devanshu sharmaNessuna valutazione finora
- Conversion: Prefix To Postfix and InfixDocumento13 pagineConversion: Prefix To Postfix and InfixSanwar ShardaNessuna valutazione finora
- Laboratory Plan - DSDocumento2 pagineLaboratory Plan - DSKARANAM SANTOSHNessuna valutazione finora
- Load Flow 2Documento23 pagineLoad Flow 2Fawzi RadwanNessuna valutazione finora
- Cyclic Codes: Overview: EE 387, John Gill, Stanford University Notes #5, October 22, Handout #15Documento24 pagineCyclic Codes: Overview: EE 387, John Gill, Stanford University Notes #5, October 22, Handout #15sandipgNessuna valutazione finora
- Hierarchical Clustering: Ke ChenDocumento21 pagineHierarchical Clustering: Ke Chentanees aliNessuna valutazione finora
- MySQL Cheat Sheet String FunctionsDocumento1 paginaMySQL Cheat Sheet String Functionshanuka92Nessuna valutazione finora
- Error Detection and CorrectionDocumento25 pagineError Detection and CorrectionShanta PhaniNessuna valutazione finora
- Lesson 2.1 - Practice A and BDocumento2 pagineLesson 2.1 - Practice A and BnanalagappanNessuna valutazione finora
- Leetcode Tracking SpreadsheetDocumento4 pagineLeetcode Tracking SpreadsheetEverything Of NitinNessuna valutazione finora
- Pumping CFLDocumento4 paginePumping CFLashutoshfriendsNessuna valutazione finora
- Using ADC On Firebird-V Robot: E-Yantra Team Embedded Real-Time Systems Lab Indian Institute of Technology BombayDocumento116 pagineUsing ADC On Firebird-V Robot: E-Yantra Team Embedded Real-Time Systems Lab Indian Institute of Technology BombayRANJITHANessuna valutazione finora
- Unity University Adama Special Campus Department of Business Management Master of Business AdministrationDocumento10 pagineUnity University Adama Special Campus Department of Business Management Master of Business AdministrationGetu WeyessaNessuna valutazione finora
- Numbering SystemsDocumento53 pagineNumbering SystemsStephen TagoNessuna valutazione finora
- Katz - Complexity Theory (Lecture Notes)Documento129 pagineKatz - Complexity Theory (Lecture Notes)Kristina ŠekrstNessuna valutazione finora
- DCS MID - II Set BDocumento2 pagineDCS MID - II Set BN.RAMAKUMARNessuna valutazione finora
- DAA Lecture 2Documento35 pagineDAA Lecture 2AqsaNessuna valutazione finora
- MS1008-Tutorial 5Documento10 pagineMS1008-Tutorial 5Nur FazeelaNessuna valutazione finora