Potrebbero piacerti anche
- El Amor en Los Tiempos Del CóleraDocumento19 pagineEl Amor en Los Tiempos Del CóleraMichael Medina Flores100% (1)
- Medidas de Asimetría y CurtosisDocumento3 pagineMedidas de Asimetría y CurtosisLuis Fernando Ortiz RodriguezNessuna valutazione finora
- Nom 015 STPS 2001Documento5 pagineNom 015 STPS 2001Luis Enrique Martinez CarvajalNessuna valutazione finora
- MSAL. Formulación de Proyectos de SaludDocumento65 pagineMSAL. Formulación de Proyectos de SaludwalterfdezNessuna valutazione finora
- SOCIOLOGIA PPTDocumento51 pagineSOCIOLOGIA PPTARTZOFTNKZ PZNessuna valutazione finora
- La Entrevista Psicológica PDFDocumento4 pagineLa Entrevista Psicológica PDFLuis CMNessuna valutazione finora
- Examen Parcial - Semana 4 - Inv - Segundo Bloque-Proyecto Social en Educacion - (Grupo1)Documento9 pagineExamen Parcial - Semana 4 - Inv - Segundo Bloque-Proyecto Social en Educacion - (Grupo1)ROSARIO SANTOS100% (1)
- Fica Labo 1Documento7 pagineFica Labo 1Lenin Vladimir BestNessuna valutazione finora
- Plan de Adecuación y Manejo Ambiental - PAMADocumento41 paginePlan de Adecuación y Manejo Ambiental - PAMAThais Yulisa Huamani Hilario100% (1)
- Ejercicios de Estadistica para Economistas 2Documento23 pagineEjercicios de Estadistica para Economistas 2Jaime Gaston Vera LipnickiNessuna valutazione finora
- Semana 1Documento33 pagineSemana 1MARIA MENDOZA REQUEJONessuna valutazione finora
- 2 Aplicaciones de ExponencialesDocumento1 pagina2 Aplicaciones de ExponencialesladyNessuna valutazione finora
- Correlacion y RegresionDocumento19 pagineCorrelacion y Regresionfredmanca512Nessuna valutazione finora
- Valor Del Tiempo-2Documento10 pagineValor Del Tiempo-2Patrick PulacheNessuna valutazione finora
- Caso Tai LoyDocumento6 pagineCaso Tai LoyEduardo coronadoNessuna valutazione finora
- Práctica 05Documento3 paginePráctica 05WILLIAMNessuna valutazione finora
- Guia de Practica 2Documento5 pagineGuia de Practica 2Ricardo Prieto MallquiNessuna valutazione finora
- Econometria II PDFDocumento140 pagineEconometria II PDFLeidi Aracely Carmen CarmenNessuna valutazione finora
- Coeficiente de VariaciónDocumento3 pagineCoeficiente de VariaciónevertNessuna valutazione finora
- 3ra PracticaDocumento6 pagine3ra PracticaJavier CopitanNessuna valutazione finora
- Practica Dirigida 3Documento17 paginePractica Dirigida 3Jessenia R.MoralesNessuna valutazione finora
- Modelo GeneralDocumento8 pagineModelo GeneralDante Dennis Cotrina AnguloNessuna valutazione finora
- Trabajo de Econometria FinalDocumento14 pagineTrabajo de Econometria FinalJulio Cisneros Enciso0% (1)
- Conceptos Basicos de Estadistica y Medidas de Tendencia CentralDocumento3 pagineConceptos Basicos de Estadistica y Medidas de Tendencia CentralJAVIER RODRIGUEZNessuna valutazione finora
- Función Característica y Función Generatriz de MomentosDocumento9 pagineFunción Característica y Función Generatriz de MomentosMarty HuamanNessuna valutazione finora
- Introduccion RequerimientosDocumento32 pagineIntroduccion RequerimientosGabriel MontesinosNessuna valutazione finora
- Solucionario Microeconomia 23 de Mayo 2018Documento34 pagineSolucionario Microeconomia 23 de Mayo 2018Mauricio Gherardelli SimunovicNessuna valutazione finora
- Ma143 201501 Cuaderno de TrabajoDocumento251 pagineMa143 201501 Cuaderno de TrabajoAna Tito NorabuenaNessuna valutazione finora
- PDF Probabilidad y Estadistica Un Enfoque Basado en El Desarrollo de Competencias CompressDocumento68 paginePDF Probabilidad y Estadistica Un Enfoque Basado en El Desarrollo de Competencias CompressEl tuNessuna valutazione finora
- Tasa de InflacionDocumento2 pagineTasa de InflacionJosue Miguel Lozada Montoya100% (1)
- Apuntes de Estadistica Auxiliatura2Documento247 pagineApuntes de Estadistica Auxiliatura2Jhonny mamani huancoNessuna valutazione finora
- 11 Numeros IndiceDocumento47 pagine11 Numeros IndiceFABIOLA YANKEL CASTELLON LOPEZNessuna valutazione finora
- Función Generatriz de MomentosDocumento16 pagineFunción Generatriz de MomentosAlizée jenn0% (1)
- Aportes Teoricos Escuela Neoclasica y Escuela ChicagoDocumento2 pagineAportes Teoricos Escuela Neoclasica y Escuela ChicagoYecid ZamboniNessuna valutazione finora
- TstudentDocumento14 pagineTstudentGloria UgarteNessuna valutazione finora
- 004 PDFDocumento4 pagine004 PDFJohn TimoteoNessuna valutazione finora
- Calizaya Tapia Lucía IsabelDocumento87 pagineCalizaya Tapia Lucía IsabelMELANY KATHERIN ELIAS TREBEJONessuna valutazione finora
- Algebra Matricial - PPTDocumento23 pagineAlgebra Matricial - PPTTatiana FabiNessuna valutazione finora
- Modulo 3 y 4Documento21 pagineModulo 3 y 4Jheniffer CastilloNessuna valutazione finora
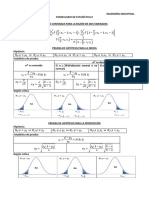
- Formulario para Examen ParcialDocumento4 pagineFormulario para Examen ParcialKatherine Gonzales RodriguesNessuna valutazione finora
- Componentes No Observables de Una Serie de TiempoDocumento17 pagineComponentes No Observables de Una Serie de TiempoVictor Hugo QuilcaNessuna valutazione finora
- Análisis de Estructuras (II Unidad) - CompressedDocumento68 pagineAnálisis de Estructuras (II Unidad) - CompressedAlejandro Casusol GutierrezNessuna valutazione finora
- Coeficiente de Determinación y CorrelaciónDocumento8 pagineCoeficiente de Determinación y CorrelaciónMauricioCortesNessuna valutazione finora
- Examen de Historia Economica General 2021Documento2 pagineExamen de Historia Economica General 2021Alberto ChanelNessuna valutazione finora
- 01estad 2021-2 UniDocumento47 pagine01estad 2021-2 UniANGEL DAVID MAMANI GUARDIANessuna valutazione finora
- Multiplicador MonetarioDocumento3 pagineMultiplicador MonetarioJosé María RamiroNessuna valutazione finora
- Hipergeométrica y Poisson.Documento25 pagineHipergeométrica y Poisson.EMANUEL RUIZ HERNANDEZNessuna valutazione finora
- Manual Métodos Cuantitativos II - 2013 - I - IIDocumento132 pagineManual Métodos Cuantitativos II - 2013 - I - IIDannyGabrielNessuna valutazione finora
- Silabo Matematica Ii Negocios InternacionalesDocumento5 pagineSilabo Matematica Ii Negocios InternacionalesJackeline ValdiviaNessuna valutazione finora
- Macrto Iii TrabajoDocumento28 pagineMacrto Iii TrabajoLuz Mery Condori LuqueNessuna valutazione finora
- Trabajo Final de EstadisticaDocumento30 pagineTrabajo Final de EstadisticahannaNessuna valutazione finora
- Prueb HipDocumento19 paginePrueb HipFernando JordanNessuna valutazione finora
- Practica Medidas de DispersionDocumento12 paginePractica Medidas de DispersionLIZETH L.C.Nessuna valutazione finora
- Monografía 2Documento10 pagineMonografía 2Mateo Pita DelgadoNessuna valutazione finora
- Diapositivas Algebra Lineal PPTX b798bff3 75e0 4793 9cb8 3c0ec0eedb4aDocumento68 pagineDiapositivas Algebra Lineal PPTX b798bff3 75e0 4793 9cb8 3c0ec0eedb4aJulio Cesar ContrerasNessuna valutazione finora
- Pruebas de HipotesisDocumento56 paginePruebas de HipotesisMauricio CajaNessuna valutazione finora
- Modelo Lineal General 2020Documento27 pagineModelo Lineal General 2020Luis Vicente medinaNessuna valutazione finora
- EXAMEN Final - EstadisticaDocumento4 pagineEXAMEN Final - EstadisticaCarmela GalianoNessuna valutazione finora
- Trabajo de Prueba TDocumento25 pagineTrabajo de Prueba TPedro Perez0% (1)
- 5 Ejercicios ResueltosDocumento9 pagine5 Ejercicios ResueltosDamaris Priscila MamaniNessuna valutazione finora
- CuadernoDocumento3 pagineCuadernoMery LAura NavArroNessuna valutazione finora
- Analisis 21 BlackjackDocumento8 pagineAnalisis 21 BlackjackMauricio HernándezNessuna valutazione finora
- 1.PPT ProbabilidadesDocumento40 pagine1.PPT ProbabilidadesJhan Copia JulcaNessuna valutazione finora
- Impuesto 1 2 3 A B Fi Hi %Documento32 pagineImpuesto 1 2 3 A B Fi Hi %JANE CAROLA FLORES ORTIZNessuna valutazione finora
- Investigación de Operaciones 2Documento24 pagineInvestigación de Operaciones 2VICENTE FLORES CARRERANessuna valutazione finora
- Cuadernillo 3 (Medidas de Tendencia Central)Documento20 pagineCuadernillo 3 (Medidas de Tendencia Central)Flavia Romero PardoNessuna valutazione finora
- ListasDocumento7 pagineListasMichael Medina FloresNessuna valutazione finora
- Impacto Ambiental AvanceDocumento8 pagineImpacto Ambiental AvanceMichael Medina FloresNessuna valutazione finora
- Aviso Bolsistas RRHHDocumento1 paginaAviso Bolsistas RRHHMichael Medina FloresNessuna valutazione finora
- CV PostigoDocumento2 pagineCV PostigoMichael Medina FloresNessuna valutazione finora
- 06 Módulo Ix 1Documento840 pagine06 Módulo Ix 1Michael Medina FloresNessuna valutazione finora
- Modelo ReservasDocumento22 pagineModelo ReservasMichael Medina FloresNessuna valutazione finora
- Michael Medina Flores CurriculumDocumento2 pagineMichael Medina Flores CurriculumMichael Medina FloresNessuna valutazione finora
- Políticas de Donald Trump (Sección 1) 2019Documento14 paginePolíticas de Donald Trump (Sección 1) 2019Michael Medina FloresNessuna valutazione finora
- Resolucin N 245 2018 Cu Aprobar Reglamento de Grados y Ttulos de La Unac Parte 1Documento16 pagineResolucin N 245 2018 Cu Aprobar Reglamento de Grados y Ttulos de La Unac Parte 1Michael Medina FloresNessuna valutazione finora
- Formato de Trámite AcadémicoDocumento2 pagineFormato de Trámite AcadémicoKirk Hammet HammerNessuna valutazione finora
- Políticas de Donald Trump (Sección 1) 2019Documento14 paginePolíticas de Donald Trump (Sección 1) 2019Michael Medina FloresNessuna valutazione finora
- Trabajo de Tendencias EconomicasDocumento2 pagineTrabajo de Tendencias EconomicasMichael Medina FloresNessuna valutazione finora
- G5 - Efecto-De-Las-Ondas-Electromagnéticas-Generadas-Por-Líneas-De-Transmisión-De-60-KvDocumento24 pagineG5 - Efecto-De-Las-Ondas-Electromagnéticas-Generadas-Por-Líneas-De-Transmisión-De-60-KvMichael Medina FloresNessuna valutazione finora
- Test Del ApoDocumento2 pagineTest Del ApoMichael Medina FloresNessuna valutazione finora
- C x13 C x13: Y La Segunda Parte EsDocumento1 paginaC x13 C x13: Y La Segunda Parte EsMichael Medina FloresNessuna valutazione finora
- Test Del DoDocumento2 pagineTest Del DoMichael Medina FloresNessuna valutazione finora
- Ministerio de Economía Y FinanzasDocumento2 pagineMinisterio de Economía Y FinanzasMichael Medina FloresNessuna valutazione finora
- Gestion EmpresarialDocumento3 pagineGestion EmpresarialMichael Medina FloresNessuna valutazione finora
- Diseño de Una Turbina PeltonDocumento23 pagineDiseño de Una Turbina PeltonMichael Medina Flores100% (2)
- Anexos 2018Documento12 pagineAnexos 2018Michael Medina FloresNessuna valutazione finora
- LeeameDocumento1 paginaLeeamechejo20Nessuna valutazione finora
- Argument OsDocumento2 pagineArgument OsMichael Medina FloresNessuna valutazione finora
- CD 7520Documento150 pagineCD 7520Michael Medina FloresNessuna valutazione finora
- Medina Flores Michael Antonio-InvestigacionDocumento8 pagineMedina Flores Michael Antonio-InvestigacionMichael Medina FloresNessuna valutazione finora
- ¿El Lider Nace o Se Hace - Grupo 04, Aula 04-1Documento19 pagine¿El Lider Nace o Se Hace - Grupo 04, Aula 04-1Michael Medina FloresNessuna valutazione finora
- El Amor en Los Tiempos Del ColeraDocumento3 pagineEl Amor en Los Tiempos Del ColeraMichael Medina FloresNessuna valutazione finora
- Pasos 1-5Documento5 paginePasos 1-5Michael Medina FloresNessuna valutazione finora
- Lista de TesisDocumento2 pagineLista de TesisMichael Medina FloresNessuna valutazione finora
- TEMA 3 Manual de Procedimientos AdministrativosDocumento17 pagineTEMA 3 Manual de Procedimientos Administrativosapi-373946370% (10)
- Diagnostico Iso 9001Documento17 pagineDiagnostico Iso 9001yeniferNessuna valutazione finora
- Clase 4 Tratamiento V CauntitativasDocumento68 pagineClase 4 Tratamiento V CauntitativasMarco ReyesNessuna valutazione finora
- Resistores Con Configuración en SerieDocumento4 pagineResistores Con Configuración en SerieANA RUIZNessuna valutazione finora
- Resumen Capítulo 1-5Documento10 pagineResumen Capítulo 1-5martyNessuna valutazione finora
- Procedimiento de Evaluación de Riesgos DisergonómicoDocumento10 pagineProcedimiento de Evaluación de Riesgos DisergonómiconancyNessuna valutazione finora
- Espacio Muestral y Estadística DescriptivaDocumento10 pagineEspacio Muestral y Estadística Descriptivacamilo pedrerosNessuna valutazione finora
- Ficha Técnica Instrumento de Evaluación Nivel Fonético (2252)Documento7 pagineFicha Técnica Instrumento de Evaluación Nivel Fonético (2252)celeste bacaNessuna valutazione finora
- Marco MetodológicoDocumento23 pagineMarco MetodológicoGerson SuarezNessuna valutazione finora
- Guía de Examen Final - 2021 - v2Documento3 pagineGuía de Examen Final - 2021 - v2María EmilianaNessuna valutazione finora
- Trabajo Escrito Práctica de Psicología Social.Documento10 pagineTrabajo Escrito Práctica de Psicología Social.Alexander GuerreroNessuna valutazione finora
- PROCESOOOOOOOOOOOOOOOOOODocumento43 paginePROCESOOOOOOOOOOOOOOOOOOAnni Liz FentyNessuna valutazione finora
- Taller - de - Probabilidad - y - Estadistica - Final - PueserDocumento9 pagineTaller - de - Probabilidad - y - Estadistica - Final - PueserKmilo GálvezNessuna valutazione finora
- Act4. Importancia de La ProbabilidadDocumento8 pagineAct4. Importancia de La ProbabilidadRODRÍGUEZ DEL ORBE CINTHYA ESTEFANIA 201618517Nessuna valutazione finora
- Asignación1. Módulo 7 (José T Mejía)Documento9 pagineAsignación1. Módulo 7 (José T Mejía)Juan José Mejía AlvarengaNessuna valutazione finora
- Guil Presiones Internas Del Ámbito Laboral Y:o Familiar Como Antecedentes Del Conflicto Trabajo-FamiliaDocumento11 pagineGuil Presiones Internas Del Ámbito Laboral Y:o Familiar Como Antecedentes Del Conflicto Trabajo-FamiliaAna Gutiérrez MartínezNessuna valutazione finora
- Control de Calidad y GraficasDocumento13 pagineControl de Calidad y GraficasNathasha AguileraNessuna valutazione finora
- Informe Final - Desarrollo de EjerciciosDocumento11 pagineInforme Final - Desarrollo de EjerciciosMarcoantonioAlamoVieraNessuna valutazione finora
- Las Entrevistas de Formato Interrogativo No Son Válidas para Los Propósitos PsicológicoDocumento3 pagineLas Entrevistas de Formato Interrogativo No Son Válidas para Los Propósitos PsicológicoAnthony Malmaceda DiosesNessuna valutazione finora
- 12º A-B Guías TrimestralesDocumento16 pagine12º A-B Guías TrimestralesDustin KlineNessuna valutazione finora
- InentaruoDocumento35 pagineInentaruoCaye CuestaNessuna valutazione finora
- AUDITORÍA AMBIENTAL DiapoDocumento33 pagineAUDITORÍA AMBIENTAL DiapoBryanNessuna valutazione finora
- Aplicación Del Modelo de Aceptación Tecnológica en Sistemas de Información de La Administración Pública Del PerúDocumento8 pagineAplicación Del Modelo de Aceptación Tecnológica en Sistemas de Información de La Administración Pública Del PerúSheyla Mayte Pinaya VallejosNessuna valutazione finora
- Diferencia Entre Evaluación Psicológica Forense y ClínicaDocumento20 pagineDiferencia Entre Evaluación Psicológica Forense y Clínicamaria fernanda delgado rojasNessuna valutazione finora