Potrebbero piacerti anche
- Python Functions OOP Exceptions ClassesDocumento17 paginePython Functions OOP Exceptions ClassesKaushal Deshmukh50% (6)
- Modules 1Documento9 pagineModules 1karthiyayani umashankarNessuna valutazione finora
- A New Convolutional Neural Network Based Data-Driven Fault Diagnosis MethodDocumento9 pagineA New Convolutional Neural Network Based Data-Driven Fault Diagnosis Methodhachan100% (1)
- Introduction To Data Mining: Business Analytics, 1eDocumento18 pagineIntroduction To Data Mining: Business Analytics, 1eJosephine CastilloNessuna valutazione finora
- Aiml LabDocumento14 pagineAiml Lab1DT19IS146TriveniNessuna valutazione finora
- Noron ThiDocumento26 pagineNoron ThiĐức ThánhNessuna valutazione finora
- Report Q4Documento10 pagineReport Q4GAYATHRI NATESHNessuna valutazione finora
- Load CSV, Normalize Features, Logistic RegressionDocumento3 pagineLoad CSV, Normalize Features, Logistic RegressioncndNessuna valutazione finora
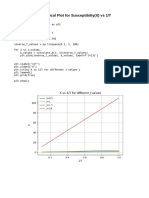
- PlotDocumento5 paginePlotRupam DeyNessuna valutazione finora
- Regression: 1 Implementación de Métodos de RegresiónDocumento11 pagineRegression: 1 Implementación de Métodos de RegresiónÓscar Alfonso Gómez SepúlvedaNessuna valutazione finora
- Python3 FrescoDocumento8 paginePython3 FrescoNaresh ReddyNessuna valutazione finora
- Python PracticalDocumento30 paginePython PracticalSayan MajiNessuna valutazione finora
- Single Layer Perceptron With Custom Dataset LinkDocumento4 pagineSingle Layer Perceptron With Custom Dataset LinkJaydev RavalNessuna valutazione finora
- Stats Practical NotebookDocumento23 pagineStats Practical NotebookBhuvanesh SriniNessuna valutazione finora
- Advance AI and ML LABDocumento16 pagineAdvance AI and ML LABPriyanka PriyaNessuna valutazione finora
- Number Theory Functions in PythonDocumento7 pagineNumber Theory Functions in PythonTom ColvinNessuna valutazione finora
- ML Lab ManualDocumento37 pagineML Lab Manualapekshapandekar01100% (1)
- Python 3 Oops Hands OnDocumento7 paginePython 3 Oops Hands OnrajeshNessuna valutazione finora
- Fall Semester 2020-21 AI with Python Lab Digital Assignment -2Documento5 pagineFall Semester 2020-21 AI with Python Lab Digital Assignment -2sejal mittalNessuna valutazione finora
- PythonDocumento10 paginePythonKalim Ullah MarwatNessuna valutazione finora
- ML Course Description & Lab ExperimentsDocumento48 pagineML Course Description & Lab ExperimentsRavi ShankarNessuna valutazione finora
- Python Matrix MultiplicationDocumento29 paginePython Matrix Multiplicationsagar panchalNessuna valutazione finora
- Find Minimum and Maximum Elements in a List Using Divide and ConquerDocumento29 pagineFind Minimum and Maximum Elements in a List Using Divide and ConquerSaraunsh JadhavNessuna valutazione finora
- AIML Lab ProgDocumento15 pagineAIML Lab ProgGreen MongorNessuna valutazione finora
- Python Oops FunctionDocumento14 paginePython Oops FunctionPratik Kumar JhaNessuna valutazione finora
- ML Lab Manual PDFDocumento9 pagineML Lab Manual PDFAnonymous KvIcYFNessuna valutazione finora
- Tutorial Classification PyDocumento7 pagineTutorial Classification PyLucas ZNessuna valutazione finora
- Assignment 04 NmupDocumento6 pagineAssignment 04 NmupAkhil SharmaNessuna valutazione finora
- New Daa RahulDocumento24 pagineNew Daa RahulAbcd XyzNessuna valutazione finora
- CVDL Exp4 CodeDocumento22 pagineCVDL Exp4 CodepramodNessuna valutazione finora
- CSE 3024: Web Mining Lab Assessment - 3 Decision Tree vs Naive Bayes PerformanceDocumento13 pagineCSE 3024: Web Mining Lab Assessment - 3 Decision Tree vs Naive Bayes PerformanceNikitha ReddyNessuna valutazione finora
- DaaDocumento7 pagineDaakjhsuigajighNessuna valutazione finora
- Python 3 Functions and OOPs FPDocumento10 paginePython 3 Functions and OOPs FPPriya SatheeshNessuna valutazione finora
- ML Lab ManualDocumento28 pagineML Lab ManualSharan PatilNessuna valutazione finora
- Ai Lab CodeDocumento14 pagineAi Lab CodeAladin sabariNessuna valutazione finora
- #Iteration Counter: Gradient - DescentDocumento2 pagine#Iteration Counter: Gradient - DescentDivyani ChavanNessuna valutazione finora
- Probleme Laborator: Compilare: Mpicc Prog.c - o Prog Executie: Mpirun - N 4 ./progDocumento14 pagineProbleme Laborator: Compilare: Mpicc Prog.c - o Prog Executie: Mpirun - N 4 ./progMaria LuizaNessuna valutazione finora
- Python Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersDocumento12 paginePython Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersAYUSHI DEOTARENessuna valutazione finora
- DAA RecordDocumento15 pagineDAA Recorddharun0704Nessuna valutazione finora
- Cau1 Rom Import From Import Import Import As Import As From ImportDocumento4 pagineCau1 Rom Import From Import Import Import As Import As From ImportKenny LongNessuna valutazione finora
- Python Programming Jagesh SoniDocumento15 paginePython Programming Jagesh SoniJagesh SoniNessuna valutazione finora
- Python Programming Examples CollectionDocumento22 paginePython Programming Examples Collectionparv saxenaNessuna valutazione finora
- Cardio Screen RFDocumento27 pagineCardio Screen RFThe Mind100% (1)
- Big Data Assignment - 4Documento6 pagineBig Data Assignment - 4Rajeev MukheshNessuna valutazione finora
- Comparing test errors of AdaBoost and Bagging classifiersDocumento12 pagineComparing test errors of AdaBoost and Bagging classifierssurbhiNessuna valutazione finora
- ML LabDocumento7 pagineML LabSharan PatilNessuna valutazione finora
- DWM 10Documento5 pagineDWM 10Aqid KhatkhatayNessuna valutazione finora
- Technical Interview Questions Technical Interview QuestionsDocumento13 pagineTechnical Interview Questions Technical Interview Questionsschultz jrNessuna valutazione finora
- Python Programming Practical ListDocumento36 paginePython Programming Practical ListRehan PathanNessuna valutazione finora
- EE-769 Linear Regression AssignmentDocumento11 pagineEE-769 Linear Regression AssignmentSachin BisenNessuna valutazione finora
- MA311M Assignment 2 - Code Listing: Animesh Renanse - 180108048 September 2020Documento4 pagineMA311M Assignment 2 - Code Listing: Animesh Renanse - 180108048 September 2020Animesh SinghNessuna valutazione finora
- ML Lab....... 3-Converted NewDocumento27 pagineML Lab....... 3-Converted NewHanisha BavanaNessuna valutazione finora
- TayyabDocumento35 pagineTayyabMassabaliKhanNessuna valutazione finora
- EE 559 HW2Code PDFDocumento7 pagineEE 559 HW2Code PDFAliNessuna valutazione finora
- Index of Programming ExperimentsDocumento14 pagineIndex of Programming ExperimentsAman SinghNessuna valutazione finora
- CodeDocumento11 pagineCodemushahedNessuna valutazione finora
- Aiml LabDocumento13 pagineAiml LabAishwarya BiradarNessuna valutazione finora
- 8 Animation Parabole - PyDocumento3 pagine8 Animation Parabole - PyDoan HunterNessuna valutazione finora
- Cryptography Lab ManualDocumento18 pagineCryptography Lab ManualDhruv SanganiNessuna valutazione finora
- Supervidsed AlgorithmDocumento19 pagineSupervidsed AlgorithmMittu RajareddyNessuna valutazione finora
- Comparing Hidden Markov Models and Long Short Term Memory Neural Networks For Learning Action RepresentationsDocumento12 pagineComparing Hidden Markov Models and Long Short Term Memory Neural Networks For Learning Action Representationssun_917443954Nessuna valutazione finora
- Bayesian InferenceDocumento28 pagineBayesian Inferencesun_917443954Nessuna valutazione finora
- What Is Data Science? Probability Overview Descriptive StatisticsDocumento10 pagineWhat Is Data Science? Probability Overview Descriptive StatisticsMauricioRojasNessuna valutazione finora
- LEadDocumento2 pagineLEadsun_917443954Nessuna valutazione finora
- ReadDocumento1 paginaReadsun_917443954Nessuna valutazione finora
- Free SF Kingston LicenseDocumento1 paginaFree SF Kingston Licensesun_917443954Nessuna valutazione finora
- Free SF Kingston LicenseDocumento1 paginaFree SF Kingston Licensesun_917443954Nessuna valutazione finora
- CSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient DescentDocumento5 pagineCSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient Descentsun_917443954Nessuna valutazione finora
- HW1Documento4 pagineHW1sun_917443954Nessuna valutazione finora
- CSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient DescentDocumento5 pagineCSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient Descentsun_917443954Nessuna valutazione finora
- Journal Pre-Proof: Developments in The Built EnvironmentDocumento25 pagineJournal Pre-Proof: Developments in The Built EnvironmentPutri DartamanNessuna valutazione finora
- State-Of-The-Art Review On Asset Management Methodologies For Oil-Immersed Power TransformersDocumento18 pagineState-Of-The-Art Review On Asset Management Methodologies For Oil-Immersed Power TransformersAdrian SieNessuna valutazione finora
- Disease Prediction Using Data MiningDocumento5 pagineDisease Prediction Using Data MiningabhishekNessuna valutazione finora
- Breast Cancer Prediction Using Deep Learning Technique RNN and GRUDocumento5 pagineBreast Cancer Prediction Using Deep Learning Technique RNN and GRUqaz532145Nessuna valutazione finora
- Snowflake MLPFDocumento7 pagineSnowflake MLPFjahnavi208Nessuna valutazione finora
- Lecture 07 KNN 14112022 034756pmDocumento24 pagineLecture 07 KNN 14112022 034756pmMisbah100% (1)
- Data ScientistGiang VoDocumento1 paginaData ScientistGiang VoVõTrườngGiangNessuna valutazione finora
- Lec4 Oct12 2022 PracticalNotes LinearRegressionDocumento34 pagineLec4 Oct12 2022 PracticalNotes LinearRegressionasasdNessuna valutazione finora
- Review On NLP Paraphrase Detection ApproachesDocumento4 pagineReview On NLP Paraphrase Detection ApproachesInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- AI Algorithms, Data Structures, and Idioms in Prolog, Lisp (PDFDrive) - 264-363Documento100 pagineAI Algorithms, Data Structures, and Idioms in Prolog, Lisp (PDFDrive) - 264-363vothanhvNessuna valutazione finora
- CSE121Documento8 pagineCSE121Vedanth PradhanNessuna valutazione finora
- Introduction to AI: What is it and how does it workDocumento24 pagineIntroduction to AI: What is it and how does it workSMRITI SETHINessuna valutazione finora
- NIPS2019 TGAN Supplementary PDFDocumento7 pagineNIPS2019 TGAN Supplementary PDFAmber SaxenaNessuna valutazione finora
- Age and Gender Detection Project Using Deep LearningDocumento25 pagineAge and Gender Detection Project Using Deep LearningPrinceNessuna valutazione finora
- Concise Introduction to Machine LearningDocumento168 pagineConcise Introduction to Machine LearningDr. M. LavanyaNessuna valutazione finora
- Topic 5 - Part1 Multilayer PerceptronDocumento28 pagineTopic 5 - Part1 Multilayer Perceptronﻣﺤﻤﺪ الخميسNessuna valutazione finora
- 4504icbtme - Ics Assignment CDocumento6 pagine4504icbtme - Ics Assignment CKamal SurenNessuna valutazione finora
- 10 Benefits of Incorporating Generative AI in The Manufacturing ProcessDocumento12 pagine10 Benefits of Incorporating Generative AI in The Manufacturing Processcelinedion89121Nessuna valutazione finora
- Introduction To Deep Learning: by Gargee SanyalDocumento20 pagineIntroduction To Deep Learning: by Gargee Sanyalgiani2008Nessuna valutazione finora
- An Improved K Medoids Clustering Approach - 2022 - Journal of Computational MatDocumento12 pagineAn Improved K Medoids Clustering Approach - 2022 - Journal of Computational MatRich PhanNessuna valutazione finora
- Chapter 1 IntroductionDocumento5 pagineChapter 1 IntroductionStudy MailNessuna valutazione finora
- Senior Artificial Intelligence Engineer CVDocumento5 pagineSenior Artificial Intelligence Engineer CVdatascience0304Nessuna valutazione finora
- White PaperDocumento8 pagineWhite PaperAnthony YanickNessuna valutazione finora
- Advanced Data Mining Techniqes in BioinformaticsDocumento343 pagineAdvanced Data Mining Techniqes in BioinformaticsNaeem Ahmed100% (1)
- SSRN Id3693395Documento62 pagineSSRN Id3693395tema.kouznetsovNessuna valutazione finora
- Face Recognition Web App Tutorial: by Fatih Cagatay AkyonDocumento14 pagineFace Recognition Web App Tutorial: by Fatih Cagatay AkyonMancho JaramilloNessuna valutazione finora
- Applications of Big Data Analytics in Asset and Wealth ManagementDocumento6 pagineApplications of Big Data Analytics in Asset and Wealth ManagementInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora