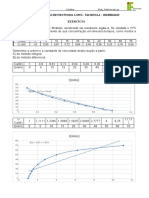
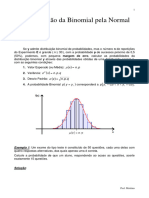
Potrebbero piacerti anche
- Simplexsimplesio 2010Documento15 pagineSimplexsimplesio 2010Nuno Calane100% (2)
- Matemática EscolarDocumento5 pagineMatemática EscolarGonçalves Dos Santos MolaNessuna valutazione finora
- Determinação Do Teor de Sacarose Por PolarimetriaDocumento5 pagineDeterminação Do Teor de Sacarose Por PolarimetriaRita FernandesNessuna valutazione finora
- Nuivesidade Save: Teste 3 - Trabalho Do CampoDocumento9 pagineNuivesidade Save: Teste 3 - Trabalho Do CampoArchel Gomes da SilvaNessuna valutazione finora
- Skoog Capítulo 5Documento15 pagineSkoog Capítulo 5Aline R. FernandesNessuna valutazione finora
- Uma Casca Esférica Oca, Feita de Ferro, Flutua Quase Completamente Submersa Na Água Veja ADocumento2 pagineUma Casca Esférica Oca, Feita de Ferro, Flutua Quase Completamente Submersa Na Água Veja ALeonardoMadeira11Nessuna valutazione finora
- EDO's de Primeira OrdemDocumento14 pagineEDO's de Primeira OrdemLeonardo PinheiroNessuna valutazione finora
- TQI 2019 1 CapIIDocumento103 pagineTQI 2019 1 CapIIAleffSantosNessuna valutazione finora
- Psicoterapia Humanista ExistencialDocumento15 paginePsicoterapia Humanista ExistencialGOOSI666Nessuna valutazione finora
- Monografia - Programação LinearDocumento59 pagineMonografia - Programação LinearRafael MendesNessuna valutazione finora
- Variancia e Desvio PadraoDocumento7 pagineVariancia e Desvio PadraoJoão de MouraNessuna valutazione finora
- Funções Explícitas e ImplícitasDocumento4 pagineFunções Explícitas e ImplícitasmadsonengNessuna valutazione finora
- EXPERIMENTO 01 - FractaisDocumento6 pagineEXPERIMENTO 01 - FractaisLipie AlcantaraNessuna valutazione finora
- Testes de HipótesesDocumento34 pagineTestes de HipótesesJorge Luiz Velasquez VelasquezNessuna valutazione finora
- Teste Z para Comparação de Duas Proporções PDFDocumento6 pagineTeste Z para Comparação de Duas Proporções PDFFabricio AlmeidaNessuna valutazione finora
- Medidas de Tendência GeraisDocumento12 pagineMedidas de Tendência GeraisTeo SilvaNessuna valutazione finora
- Funcões EulerianaDocumento28 pagineFuncões EulerianaAlex MonitoNessuna valutazione finora
- Exercício Cinética QuímicaDocumento6 pagineExercício Cinética QuímicaLucas BentesNessuna valutazione finora
- Exemplos 6Documento5 pagineExemplos 6Diogo LucenaNessuna valutazione finora
- Derivadas ParciaisDocumento24 pagineDerivadas ParciaisClasmeson VieiraNessuna valutazione finora
- Cap. 2 - ALGUMAS DISTRIBUIÇÕES DE PROBABILIDADESDocumento23 pagineCap. 2 - ALGUMAS DISTRIBUIÇÕES DE PROBABILIDADESThiago SouzaNessuna valutazione finora
- Teoria Cinética Dos GasesDocumento6 pagineTeoria Cinética Dos GasesCAPAINA BENCILARIO ANDRE F100% (1)
- Diferenciação e Integração NuméricaDocumento58 pagineDiferenciação e Integração NuméricaCalebe CostaNessuna valutazione finora
- Continuidade em Funções de Duas VariáveisDocumento6 pagineContinuidade em Funções de Duas VariáveisDavid RodriguesNessuna valutazione finora
- Curso Probabilidade e Estatistica PDFDocumento77 pagineCurso Probabilidade e Estatistica PDFvinicius50Nessuna valutazione finora
- Projecto de Monografia-FADUCODocumento14 pagineProjecto de Monografia-FADUCOIlidio SamboNessuna valutazione finora
- 4 - Medidas de Tendência CentralDocumento6 pagine4 - Medidas de Tendência CentralEllen Claudine Paes BarretoNessuna valutazione finora
- 2 - 32 - Planejamento - Educacional - e - de - EnsinoDocumento32 pagine2 - 32 - Planejamento - Educacional - e - de - EnsinoMarcia Livio AdvogadaNessuna valutazione finora
- LogicajoaonunesDocumento367 pagineLogicajoaonunesGabriel de AlmeidaNessuna valutazione finora
- Teste 2 - Probabilidade e Estatística - CORECÇÃODocumento3 pagineTeste 2 - Probabilidade e Estatística - CORECÇÃOArcénio Nhalungo VINessuna valutazione finora
- Relatório - Interferência de Micro-OndasDocumento9 pagineRelatório - Interferência de Micro-OndasQuézia BarbosaNessuna valutazione finora
- Cálculo de PredicadosDocumento10 pagineCálculo de PredicadosLuciana Conceição Dias CamposNessuna valutazione finora
- RelatíDocumento9 pagineRelatíZ3tyyTVNessuna valutazione finora
- Equações RacionaisDocumento8 pagineEquações RacionaisFadi Fernando Emilio AntónioNessuna valutazione finora
- Mecânica 11 1T 1Documento10 pagineMecânica 11 1T 1CastroNessuna valutazione finora
- Cap3. Distribuiçoes de Variaveis AleatoriasDocumento14 pagineCap3. Distribuiçoes de Variaveis Aleatoriasmessias sorteNessuna valutazione finora
- 850-Matemática IDocumento2 pagine850-Matemática IDavid MontesNessuna valutazione finora
- Apostila de Cálculo IVDocumento52 pagineApostila de Cálculo IVPedro SampaioNessuna valutazione finora
- Probabilidade e EstatísticaDocumento7 pagineProbabilidade e EstatísticaGETULIO VICENTE VIEIRA MENEZESNessuna valutazione finora
- Sistemas de Equações Do Primeiro Grau Com Duas Incógnitas (IMPRIMIR)Documento4 pagineSistemas de Equações Do Primeiro Grau Com Duas Incógnitas (IMPRIMIR)Maria Eduarda Santos0% (1)
- Slides 07 - Máximos e MínimosDocumento37 pagineSlides 07 - Máximos e MínimosJamilsonMedeirosNessuna valutazione finora
- Aproximação Binomial NormalDocumento10 pagineAproximação Binomial NormalRodrigo AntonioNessuna valutazione finora
- Praticas de Algebra VectorialDocumento5 paginePraticas de Algebra VectorialObedé Obedé0% (1)
- Lista de Exercícios de FísicaDocumento6 pagineLista de Exercícios de FísicaJorge Henrique Marques MarianoNessuna valutazione finora
- Avaliacao Duma MedicaoDocumento36 pagineAvaliacao Duma MedicaoAmos Samuel Sitoe100% (1)
- Relatório Física Experimental I (Corrigido) - Lucas RodriguesDocumento10 pagineRelatório Física Experimental I (Corrigido) - Lucas RodriguesLucas RodriguesNessuna valutazione finora
- Relatório - Fosfato Refrigerante (Coca-Cola)Documento6 pagineRelatório - Fosfato Refrigerante (Coca-Cola)Bruna FariasNessuna valutazione finora
- Prova de Calculo Poli UspDocumento5 pagineProva de Calculo Poli UspMatemáticaFísicaExcelNessuna valutazione finora
- 2014 Uninovafapi Lista de Exercicio Matrizes e Determinantes 1Documento20 pagine2014 Uninovafapi Lista de Exercicio Matrizes e Determinantes 1Diego santiago de limaNessuna valutazione finora
- O Metodo Simplex e Analise de SensibilidadeDocumento67 pagineO Metodo Simplex e Analise de SensibilidadeAnderson Diniz100% (1)
- Lista Exercícios - 02 Gases ReaisDocumento2 pagineLista Exercícios - 02 Gases ReaisChris_Oliveira85Nessuna valutazione finora
- Relatorio Fisica 2 Boyle-MariotteDocumento9 pagineRelatorio Fisica 2 Boyle-MariotteVictor HayneNessuna valutazione finora
- Arvores SemanticasDocumento36 pagineArvores SemanticasjjjuuuuuNessuna valutazione finora
- Inequações TrigonométricasDocumento7 pagineInequações TrigonométricasJemisse TingaNessuna valutazione finora
- Trabalho de Propriedades Físicas - Lasers PDFDocumento21 pagineTrabalho de Propriedades Físicas - Lasers PDFPedro Paulo MaiaNessuna valutazione finora
- Análise de Estabilidade Termodinâmica Através Do Método Conjunto GeradorDocumento7 pagineAnálise de Estabilidade Termodinâmica Através Do Método Conjunto GeradorJosemar Pereira da SilvaNessuna valutazione finora
- Otimização P2B Maurício SantosDocumento16 pagineOtimização P2B Maurício Santosmauricio511Nessuna valutazione finora
- Artigo Simone PDFDocumento30 pagineArtigo Simone PDFHiroshi MurofushiNessuna valutazione finora
- Sebenta Capitulo 1Documento19 pagineSebenta Capitulo 1satpirataNessuna valutazione finora
- Trabalho de Métodos Numericos-1Documento38 pagineTrabalho de Métodos Numericos-1Viviane CavalerNessuna valutazione finora
- Monografia Fernando EQDocumento50 pagineMonografia Fernando EQPaulo FernandoNessuna valutazione finora
- GeometriaenemDocumento44 pagineGeometriaenemCarla PuppimNessuna valutazione finora
- Portfolio CV 5Documento7 paginePortfolio CV 5luizbrturboNessuna valutazione finora
- Direcoes para Metodos de Busca LinearDocumento31 pagineDirecoes para Metodos de Busca LinearPaulo FernandoNessuna valutazione finora
- Fatorização LU PDFDocumento7 pagineFatorização LU PDFLeandro SimõesNessuna valutazione finora
- Dicas Diebold IM453HUDocumento40 pagineDicas Diebold IM453HURobert Alexandre GamaNessuna valutazione finora
- Aula 04Documento61 pagineAula 04Ed SilvaNessuna valutazione finora
- Aula Metodos IterativosDocumento19 pagineAula Metodos Iterativosalan crystian santosNessuna valutazione finora
- Cálculo Numérico - Paulo Xavier PamplonaDocumento145 pagineCálculo Numérico - Paulo Xavier PamplonaLucas Franco CarvalhêdoNessuna valutazione finora
- Aula 0901Documento16 pagineAula 0901mdanieeeelNessuna valutazione finora
- Metodos NumericosDocumento27 pagineMetodos NumericosJulio Moura100% (1)
- RecursividadeDocumento22 pagineRecursividadeLetícia de Jesus33% (3)
- CN QuartaLista 2020 1eDocumento2 pagineCN QuartaLista 2020 1eJoseilton SouzaNessuna valutazione finora