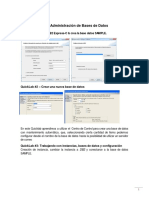
Potrebbero piacerti anche
- Unidad 1. Principios Del Modelado de NegociosDocumento21 pagineUnidad 1. Principios Del Modelado de NegociosBâütïštà Rêyęš ÃrbïlńęwNessuna valutazione finora
- Examen Final ResueltoDocumento4 pagineExamen Final ResueltoSantiago FreireNessuna valutazione finora
- S03.s1 - Bootstrap PDFDocumento35 pagineS03.s1 - Bootstrap PDFClaudio Ibarra RiosNessuna valutazione finora
- Comandos Básicos 01 R v2Documento8 pagineComandos Básicos 01 R v2Marie GarciaNessuna valutazione finora
- Diseño Estructurado de YourdonDocumento17 pagineDiseño Estructurado de YourdonPablo Cesar González GarcíaNessuna valutazione finora
- Ejercicios C++ resueltosDocumento10 pagineEjercicios C++ resueltosjjurado183Nessuna valutazione finora
- Metodología Propuesta Por SAS InstituteDocumento3 pagineMetodología Propuesta Por SAS InstituteOwens HowardNessuna valutazione finora
- Diseño Avanzado de Base de Datos PDFDocumento49 pagineDiseño Avanzado de Base de Datos PDFMiguel Alonso Palacios TarrilloNessuna valutazione finora
- Usando MySQL Workbench para Diseñar Y Crear Una Base deDocumento28 pagineUsando MySQL Workbench para Diseñar Y Crear Una Base denandoy2kNessuna valutazione finora
- Guía introductoria de comandos básicos de LinuxDocumento4 pagineGuía introductoria de comandos básicos de LinuxAnthOny ManosalvaNessuna valutazione finora
- Problemas de PDDDocumento3 pagineProblemas de PDDAlvis UlisesNessuna valutazione finora
- Arquitectura de Computadoras: Tendencias FuturasDocumento2 pagineArquitectura de Computadoras: Tendencias FuturasAntonio Acosta Murillo100% (1)
- Estudio de FactibilidadDocumento15 pagineEstudio de FactibilidadAlder SerranoNessuna valutazione finora
- Llenado de CajonesDocumento11 pagineLlenado de CajonesPepe Mejía CadenaNessuna valutazione finora
- ALG III - G7 2017 Algoritmos Matematicos y Geometricos 2016-IDocumento18 pagineALG III - G7 2017 Algoritmos Matematicos y Geometricos 2016-IYunior SotoNessuna valutazione finora
- Ejemplo Pilas y ColasDocumento13 pagineEjemplo Pilas y Colassilvergirl137Nessuna valutazione finora
- Estrategias para Eldiseno de EsquemasDocumento12 pagineEstrategias para Eldiseno de EsquemasJose Luis Capote0% (1)
- Act. InglesDocumento8 pagineAct. Inglesanon_278407064Nessuna valutazione finora
- Guia Practicas PowerDesignerDocumento0 pagineGuia Practicas PowerDesignerMax SantiagoNessuna valutazione finora
- Modelo Dimensional-Estrella - DosimetroDocumento5 pagineModelo Dimensional-Estrella - DosimetroKiranRoiNessuna valutazione finora
- Pivot DinamicoDocumento5 paginePivot DinamicoNatacha De La RosaNessuna valutazione finora
- Tercer Parcial Hojas ElectronicasDocumento21 pagineTercer Parcial Hojas ElectronicasBrayan G. Bonilla AlmonteNessuna valutazione finora
- LaboratoriosBDII PDFDocumento20 pagineLaboratoriosBDII PDFJosué MaidanaNessuna valutazione finora
- Ficha para AnteproyectoDocumento5 pagineFicha para AnteproyectocarolinaNessuna valutazione finora
- Peter Chen - Crea - Dor Del Modelo Entidad-Relación (Modelo ER)Documento3 paginePeter Chen - Crea - Dor Del Modelo Entidad-Relación (Modelo ER)Albert VulcanoNessuna valutazione finora
- Silabo Del Curso de Metodologia de Sistemas BlandosDocumento5 pagineSilabo Del Curso de Metodologia de Sistemas BlandosPavlov Garcia MelgarejoNessuna valutazione finora
- Problema Investigación InfanciaDocumento7 pagineProblema Investigación InfanciaDaniela Soledad Pacheco CNessuna valutazione finora
- Actividad 4 M1 - Consigna PDFDocumento2 pagineActividad 4 M1 - Consigna PDFdarkNessuna valutazione finora
- Programación en SQL PDFDocumento11 pagineProgramación en SQL PDFledaquirozNessuna valutazione finora
- Metodologia de Las 6dDocumento1 paginaMetodologia de Las 6dLuis Huaymana EnrriquezNessuna valutazione finora
- Analisis de Formulario en PHPDocumento11 pagineAnalisis de Formulario en PHPTamara Carla NoriegaNessuna valutazione finora
- Ejercicios de BasededatosDocumento13 pagineEjercicios de BasededatosByhelmrNessuna valutazione finora
- Dbdesigner 4 Mini ManualDocumento6 pagineDbdesigner 4 Mini ManualElder RodriguezNessuna valutazione finora
- ORACLEDocumento2 pagineORACLEJean Luis RFNessuna valutazione finora
- 03-Taller de BISQL - SSAS - CubosDocumento4 pagine03-Taller de BISQL - SSAS - Cuboselmer ÑaupasNessuna valutazione finora
- Busqueda No InformadaDocumento30 pagineBusqueda No InformadaTerrySantiagoNessuna valutazione finora
- Introducción A La Animación Por ComputadoraDocumento13 pagineIntroducción A La Animación Por Computadoraartemio hernandez gallegos100% (1)
- Tutorial PascalDocumento12 pagineTutorial PascalEnrique Cruz CheccoNessuna valutazione finora
- Consideraciones en El Diseño DWDocumento12 pagineConsideraciones en El Diseño DWmano2116100% (1)
- Manual Oracle Hyperion Usuario DesarrolladorDocumento27 pagineManual Oracle Hyperion Usuario DesarrolladormanuNessuna valutazione finora
- Metodología Rup Parte PracticaDocumento16 pagineMetodología Rup Parte PracticaChloe NoahNessuna valutazione finora
- Modelos de negocios con UMLDocumento9 pagineModelos de negocios con UMLBetty JuarezNessuna valutazione finora
- Simulación Usando NetlogoDocumento20 pagineSimulación Usando NetlogoSebastian TaleroNessuna valutazione finora
- Simulacion C Sharp - ADocumento32 pagineSimulacion C Sharp - ARob BrañezNessuna valutazione finora
- Curso BIDocumento73 pagineCurso BIEjLandetaRNessuna valutazione finora
- Tutorial Pivotal TrackerDocumento15 pagineTutorial Pivotal TrackerpglezNessuna valutazione finora
- Leer Archivo XML C#Documento3 pagineLeer Archivo XML C#jhonext3055Nessuna valutazione finora
- Funciones de DOS y BIOS Manual - Catalina Dominguez Reyes PDFDocumento143 pagineFunciones de DOS y BIOS Manual - Catalina Dominguez Reyes PDFMarcos Saldaña100% (1)
- Formato de textoDocumento4 pagineFormato de textoPedrinho CruzNessuna valutazione finora
- Estructuras de Datos en Lenguaje Java (CCG)Documento37 pagineEstructuras de Datos en Lenguaje Java (CCG)Miguel Angel Lopez Gonzalez0% (1)
- Sistemas Operativos de Tiempo CompartidoDocumento2 pagineSistemas Operativos de Tiempo CompartidoAngel Ralph0% (1)
- 1.3.3 Lab - Python Programming ReviewDocumento16 pagine1.3.3 Lab - Python Programming ReviewWill D. Gómez VegaNessuna valutazione finora
- Alg III 2019-II - g1 - Formalismo, AbstraccionDocumento17 pagineAlg III 2019-II - g1 - Formalismo, AbstraccionNikol LópezNessuna valutazione finora
- Importar y Exportar DatosDocumento4 pagineImportar y Exportar DatosSebasTianLopezNessuna valutazione finora
- Diseño MISDDocumento12 pagineDiseño MISDIsrael CarrilloNessuna valutazione finora
- Introducción a Power Pivot en ExcelDocumento47 pagineIntroducción a Power Pivot en ExcelJorge E Reyes ChNessuna valutazione finora
- 3.4.1 Visualizando Los Datos en Las TablasDocumento16 pagine3.4.1 Visualizando Los Datos en Las TablasamandaNessuna valutazione finora
- Vensim 3Documento29 pagineVensim 3JavierGonzales10Nessuna valutazione finora
- Informe Sobre El Uso y Manejo de Power PivotDocumento18 pagineInforme Sobre El Uso y Manejo de Power PivotEduardo Arevalo MarrufoNessuna valutazione finora
- Proyecto 1.1Documento12 pagineProyecto 1.1SherlockNessuna valutazione finora
- Leonardo - Antología - Enrique VerásteguiDocumento22 pagineLeonardo - Antología - Enrique VerásteguiJaime Jose Arias CongrainsNessuna valutazione finora
- POEMAS ARTICOS Y OTRAS ALQUIMIAS Por VICENTE HUIDOBRODocumento29 paginePOEMAS ARTICOS Y OTRAS ALQUIMIAS Por VICENTE HUIDOBROJaime Jose Arias CongrainsNessuna valutazione finora
- Elogio A La Mujer Brava (Hector Abad)Documento3 pagineElogio A La Mujer Brava (Hector Abad)Jaime Jose Arias CongrainsNessuna valutazione finora
- La Formacion de La Identidad PeruanaDocumento9 pagineLa Formacion de La Identidad PeruanaJaime Jose Arias CongrainsNessuna valutazione finora
- Técnicas de investigación en neurofisiología de la audición y efectos de psicofármacos en el electroretinograma de la rataDocumento2 pagineTécnicas de investigación en neurofisiología de la audición y efectos de psicofármacos en el electroretinograma de la rataJaime Jose Arias CongrainsNessuna valutazione finora
- LA MANO DESASIDA (Canto A Machu Picchu) Por MARTÍN ADÁNDocumento105 pagineLA MANO DESASIDA (Canto A Machu Picchu) Por MARTÍN ADÁNJaime Jose Arias Congrains100% (1)
- ANIMAL FANTÁSTICO INDOMESTICABLE Por LUIS LEÓN HERRERADocumento3 pagineANIMAL FANTÁSTICO INDOMESTICABLE Por LUIS LEÓN HERRERAJaime Jose Arias CongrainsNessuna valutazione finora
- Reflexiones esenciales sobre la identidad peruanaDocumento12 pagineReflexiones esenciales sobre la identidad peruanaJaime Jose Arias CongrainsNessuna valutazione finora
- Clases Latentes by Marcelino Sánchez RiveroDocumento22 pagineClases Latentes by Marcelino Sánchez RiveroJaime Jose Arias CongrainsNessuna valutazione finora
- Chiappo, Leopoldo - Planteamientos Fundamentales de La Renovación UniversitariaDocumento144 pagineChiappo, Leopoldo - Planteamientos Fundamentales de La Renovación UniversitariaJaime Jose Arias CongrainsNessuna valutazione finora
- VISIONES DE ENERO de José María EgurenDocumento4 pagineVISIONES DE ENERO de José María EgurenJaime Jose Arias CongrainsNessuna valutazione finora
- Correlaciones Con Variables Categóricas PDFDocumento19 pagineCorrelaciones Con Variables Categóricas PDFJaime Jose Arias CongrainsNessuna valutazione finora
- Redes Neuronales, Textos DepuradosDocumento10 pagineRedes Neuronales, Textos DepuradosJaime Jose Arias CongrainsNessuna valutazione finora
- LA HISTERIA EN PERU REPUBLICANO Por JUAN B. LASTRESDocumento27 pagineLA HISTERIA EN PERU REPUBLICANO Por JUAN B. LASTRESJaime Jose Arias CongrainsNessuna valutazione finora
- Leccion de Anatomia - OSCAR BARRAZADocumento128 pagineLeccion de Anatomia - OSCAR BARRAZAJaime Jose Arias CongrainsNessuna valutazione finora
- De 2008 Practica Análisis CorrespondenciasDocumento385 pagineDe 2008 Practica Análisis CorrespondenciasosvaldoblancoNessuna valutazione finora
- Mente, Cerebro y Física CuánticaDocumento29 pagineMente, Cerebro y Física CuánticaJaime Jose Arias CongrainsNessuna valutazione finora
- Manual EstadisticaDocumento30 pagineManual EstadisticaJaime Jose Arias CongrainsNessuna valutazione finora
- Correlaciones Con Variables Categóricas PDFDocumento19 pagineCorrelaciones Con Variables Categóricas PDFJaime Jose Arias CongrainsNessuna valutazione finora
- Correlaciones Con Variables Categóricas PDFDocumento19 pagineCorrelaciones Con Variables Categóricas PDFJaime Jose Arias CongrainsNessuna valutazione finora
- Mitologia Inca - EspanholDocumento2 pagineMitologia Inca - Espanholapi-3773691Nessuna valutazione finora
- Modulo Sobre La Distribucion NormalDocumento45 pagineModulo Sobre La Distribucion NormalAlejandro AyalaNessuna valutazione finora
- SPSS 0701bDocumento6 pagineSPSS 0701bJoaquin HerediaNessuna valutazione finora
- De 2008 Practica Análisis CorrespondenciasDocumento385 pagineDe 2008 Practica Análisis CorrespondenciasosvaldoblancoNessuna valutazione finora
- Modulo Sobre La Distribucion NormalDocumento45 pagineModulo Sobre La Distribucion NormalAlejandro AyalaNessuna valutazione finora
- SPSS 0701bDocumento6 pagineSPSS 0701bJoaquin HerediaNessuna valutazione finora
- Varios - Manual Fireworks 4 PDFDocumento409 pagineVarios - Manual Fireworks 4 PDFNico InfanteNessuna valutazione finora
- 127 117 2 PB PDFDocumento15 pagine127 117 2 PB PDFDimas E Villarreal PNessuna valutazione finora
- La Iluminación Del Cosmos en La Poesía de Enrique VerásteguiDocumento21 pagineLa Iluminación Del Cosmos en La Poesía de Enrique VerásteguiJaime Jose Arias CongrainsNessuna valutazione finora
- Resumen Cap12Documento1 paginaResumen Cap12赵恺Nessuna valutazione finora
- Unidad 2 Actividad 2Documento4 pagineUnidad 2 Actividad 2Luis Alfredo Espino M.100% (1)
- Quimica EspecialDocumento36 pagineQuimica EspecialBeat CarNessuna valutazione finora
- Como Crear y Atender Una Boveda Espiritual PDF 2Documento2 pagineComo Crear y Atender Una Boveda Espiritual PDF 2Rita Torres SoberanoNessuna valutazione finora
- Guia de LaboratorioDocumento25 pagineGuia de LaboratorioNoemi Yana ChoqueNessuna valutazione finora
- Reflejos Patologicos 453062 Downloable 2449240Documento26 pagineReflejos Patologicos 453062 Downloable 2449240Arlethe OrtegaNessuna valutazione finora
- Tarea 1 Cuestionario Sobre Lactancia MaternaDocumento6 pagineTarea 1 Cuestionario Sobre Lactancia MaternaJeanett Velásquez CorralesNessuna valutazione finora
- Apuntes Cultivos AndinosDocumento189 pagineApuntes Cultivos Andinosjaeyeaj100% (1)
- Ley Hooke resumenDocumento7 pagineLey Hooke resumenSaid Fernando Zacarias SalgadoNessuna valutazione finora
- Acma Proyecto1Documento28 pagineAcma Proyecto1NATALY MORENO ALVARADONessuna valutazione finora
- Manual Usuario Bomba Centrif Manual - HidrostalDocumento10 pagineManual Usuario Bomba Centrif Manual - HidrostalmpicaNessuna valutazione finora
- CV Sheyla Porras Huaman 2023Documento18 pagineCV Sheyla Porras Huaman 2023Alonso Cubas GuzmánNessuna valutazione finora
- Evidencia 2 AlmexaDocumento20 pagineEvidencia 2 AlmexaEuridice LemusNessuna valutazione finora
- Leyva Antonio Xochiquetzal 115-26 PDFDocumento5 pagineLeyva Antonio Xochiquetzal 115-26 PDFAvy AlyNessuna valutazione finora
- Registro de Vacunacion - Covid.19 - FiDocumento6 pagineRegistro de Vacunacion - Covid.19 - FiCésar Augusto Pinedo SaldañaNessuna valutazione finora
- Unidad 1 - Tarea 2Documento10 pagineUnidad 1 - Tarea 2arelis ruizNessuna valutazione finora
- SVD205 LectDocumento7 pagineSVD205 Lectivan oliverosNessuna valutazione finora
- Induccion 2021Documento127 pagineInduccion 2021Sebastián HernandezNessuna valutazione finora
- Guia de Cocinas WebDocumento24 pagineGuia de Cocinas Webelviradlopez100% (1)
- Comunicación Asertiva y El Manejo Adecuado de Conflictos en Los Diferentes Niveles de La OrganizaciónDocumento5 pagineComunicación Asertiva y El Manejo Adecuado de Conflictos en Los Diferentes Niveles de La OrganizaciónSmon LondonoNessuna valutazione finora
- Memoria DescriptivaDocumento37 pagineMemoria DescriptivaElbaOrdonezNessuna valutazione finora
- Docente CreativoDocumento3 pagineDocente CreativoCrisNessuna valutazione finora
- Guia Bloque QuirurgicoDocumento35 pagineGuia Bloque QuirurgicoAgust Polo GuevaraNessuna valutazione finora
- Traduccion Kichua GuayusaDocumento3 pagineTraduccion Kichua GuayusaAngela Oñate Haro0% (1)
- Ejercicios de Matrices y Determinantes-Indicador I-8Documento2 pagineEjercicios de Matrices y Determinantes-Indicador I-8Miguel estela pesantesNessuna valutazione finora
- Agrotodo PDFDocumento1 paginaAgrotodo PDFfredy muñozNessuna valutazione finora
- Manual Tablet SamsungDocumento138 pagineManual Tablet SamsungRaquel RomeroNessuna valutazione finora
- LibroprimeroDocumento194 pagineLibroprimeroWENBO TANNessuna valutazione finora
- 5 Datos Curiosos Del TitanicDocumento1 pagina5 Datos Curiosos Del TitanicGina Paola Pardo MendozaNessuna valutazione finora