Potrebbero piacerti anche
- UF1472 - Lenguajes de definición y modificación de datos SQLDa EverandUF1472 - Lenguajes de definición y modificación de datos SQLNessuna valutazione finora
- Seguridad de DatosDocumento8 pagineSeguridad de DatosjaimetronerNessuna valutazione finora
- Procedimientos Almacenados MySQLDocumento2 pagineProcedimientos Almacenados MySQLVanessa LNessuna valutazione finora
- Actividad 2Documento14 pagineActividad 2Alexander MoralesNessuna valutazione finora
- DP 900Documento6 pagineDP 900Arturo GonzalezNessuna valutazione finora
- Unidad 5Documento2 pagineUnidad 5Lester Noel RamirezNessuna valutazione finora
- Unidad 2 Arquitectura Del GestorDocumento33 pagineUnidad 2 Arquitectura Del Gestorロメロアンドラーデドイツ語Nessuna valutazione finora
- Instalación y configuración SGBDDocumento7 pagineInstalación y configuración SGBDMontero Montero AriasNessuna valutazione finora
- Mogr590204mmnrlm00 NacDocumento2 pagineMogr590204mmnrlm00 NacMiguel Angel Maldonado DelgadoNessuna valutazione finora
- 6th Central Pay Commission Salary CalculatorDocumento15 pagine6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Paralelismo en Bases de Datos: Optimizaci On Detiempos de Respuesta de Una Consulta Mediante Laimplementación de Queries Paralelos Con Scripts Enc Con OpenMPDocumento12 pagineParalelismo en Bases de Datos: Optimizaci On Detiempos de Respuesta de Una Consulta Mediante Laimplementación de Queries Paralelos Con Scripts Enc Con OpenMPAlonso Tenorio100% (1)
- Adm BDDocumento20 pagineAdm BDJorgeNessuna valutazione finora
- Tipos de paralelismo en sistemas informáticosDocumento9 pagineTipos de paralelismo en sistemas informáticosedgarxavier_17Nessuna valutazione finora
- Modelos de bases de datos y SGBDDocumento18 pagineModelos de bases de datos y SGBDDarwin SulbaranNessuna valutazione finora
- Preguntas Unidad 2_DavidNgbeliDocumento3 paginePreguntas Unidad 2_DavidNgbeliDavid NgbeliNessuna valutazione finora
- Tema 1 Conceptos Basicos de OracleDocumento15 pagineTema 1 Conceptos Basicos de OracleJhuneor Otuya NinaNessuna valutazione finora
- Guia de Estudio Primer Examen de Bases de Datos DistribuidasDocumento15 pagineGuia de Estudio Primer Examen de Bases de Datos DistribuidasGalo SalinasNessuna valutazione finora
- Tarea BD IoTDocumento5 pagineTarea BD IoTElvio Gutierrez SosaNessuna valutazione finora
- Arquitectura Interna OracleDocumento13 pagineArquitectura Interna Oraclecipri1234Nessuna valutazione finora
- DBEspacialesDocumento4 pagineDBEspacialesKariin D LunaNessuna valutazione finora
- EventApp: gestión de eventos con MySQL y HibernateDocumento12 pagineEventApp: gestión de eventos con MySQL y HibernateFrancisco JavierNessuna valutazione finora
- Procesamiento Paralelo Con JPPFDocumento19 pagineProcesamiento Paralelo Con JPPFAndrés Felipe GalindoNessuna valutazione finora
- Paper Análisis y Evaluación de Rendimiento de Gestores de Bases de DatosDocumento3 paginePaper Análisis y Evaluación de Rendimiento de Gestores de Bases de DatosJuan CuencaNessuna valutazione finora
- MiniProyecto MongoDBDocumento9 pagineMiniProyecto MongoDBlantisNessuna valutazione finora
- Bases de Datos C# PDFDocumento15 pagineBases de Datos C# PDFtheweebmanNessuna valutazione finora
- Arquitectura ANSI/SPARC y niveles de un SGBDDocumento5 pagineArquitectura ANSI/SPARC y niveles de un SGBDHenry BlackburnNessuna valutazione finora
- CouchDB para aplicaciones webDocumento16 pagineCouchDB para aplicaciones webAlba Iris Torres SandovalNessuna valutazione finora
- Definición SGBDDocumento5 pagineDefinición SGBDJosé Luis García SorianoNessuna valutazione finora
- Principales diferencias entre SGBD Oracle, PostgreSQL, MySQL y SQL ServerDocumento3 paginePrincipales diferencias entre SGBD Oracle, PostgreSQL, MySQL y SQL ServerDiego Fernando SantosNessuna valutazione finora
- Características y diferencias de Oracle, DB2 y SQL ServerDocumento1 paginaCaracterísticas y diferencias de Oracle, DB2 y SQL ServerRobin LorenzoNessuna valutazione finora
- Paralelismo DBMS shared memoryDocumento4 pagineParalelismo DBMS shared memoryJesus MedinaNessuna valutazione finora
- Cierre PDFDocumento35 pagineCierre PDFJuan Antonio ZambranoNessuna valutazione finora
- BitácoraDocumento11 pagineBitácoraGabriel Navarro SalcedoNessuna valutazione finora
- Escenario 6Documento11 pagineEscenario 6Iquito mosi conleNessuna valutazione finora
- AP07-AA8-Ev03 Foro-Plataformas-Drrollo-SWDocumento19 pagineAP07-AA8-Ev03 Foro-Plataformas-Drrollo-SWjuan camilo mesa rodriguezNessuna valutazione finora
- TAREA 2. Gráfico y Explicación de La Arquitectura Interna de OracleDocumento11 pagineTAREA 2. Gráfico y Explicación de La Arquitectura Interna de OracleJosue HRNessuna valutazione finora
- Exposición Examen 1Documento19 pagineExposición Examen 1Valeryn RodriguezNessuna valutazione finora
- Actividad 4Documento5 pagineActividad 4saturvinngNessuna valutazione finora
- Evolución de Las Bases de DatosDocumento16 pagineEvolución de Las Bases de DatosISRAEL ENRIQUE ESPINOZA CHAMPINessuna valutazione finora
- Servidores Bases de DatosDocumento6 pagineServidores Bases de Datosluk17a5Nessuna valutazione finora
- Motor OlapDocumento6 pagineMotor OlapBely Ramirez GutierrezNessuna valutazione finora
- Monitoreo en Las Bases de DatosDocumento7 pagineMonitoreo en Las Bases de DatosJoseph Felix Estrella0% (2)
- Ensayo 2Documento10 pagineEnsayo 2Gabriel Feliz JavierNessuna valutazione finora
- Procesamiento paralelo y clustersDocumento5 pagineProcesamiento paralelo y clustersgeovani malaga fiscalNessuna valutazione finora
- Programacion Paralela Aplicada - 6Documento30 pagineProgramacion Paralela Aplicada - 6Charliber OficinaNessuna valutazione finora
- Guia ORACLE DBA-01 Fundamentos de Los Sistemas Gestores de Bases de DatosDocumento21 pagineGuia ORACLE DBA-01 Fundamentos de Los Sistemas Gestores de Bases de DatosMilton PerezNessuna valutazione finora
- Instalación y configuración de SGBDDocumento14 pagineInstalación y configuración de SGBDDon RamónNessuna valutazione finora
- 50-54 Code34 ArchitectureDocumento5 pagine50-54 Code34 Architecturesixto_pqNessuna valutazione finora
- BasededatosDocumento13 pagineBasededatosAbner David Dotel ChalasNessuna valutazione finora
- Relacion Del DBA Con Otras Areas de Los SistemasDocumento3 pagineRelacion Del DBA Con Otras Areas de Los SistemasMontores Alejandro Félix DennisNessuna valutazione finora
- Bases de Datos ParalelasDocumento7 pagineBases de Datos Paralelasenergy2007Nessuna valutazione finora
- 5C Act3.2 Omar Guzmán Alexandra AlcarazDocumento14 pagine5C Act3.2 Omar Guzmán Alexandra AlcarazHenryredcoat 2005Nessuna valutazione finora
- 2.1 Estructura de Memoria y Procesos de InstanciaDocumento21 pagine2.1 Estructura de Memoria y Procesos de InstanciaSandra Trejo Resendiz100% (1)
- Programacion AvanzadaDocumento10 pagineProgramacion AvanzadaAby MHNessuna valutazione finora
- Estudio comparativo entre PostgreSQL y MySQLDocumento5 pagineEstudio comparativo entre PostgreSQL y MySQLelijobrosNessuna valutazione finora
- TERADATADocumento22 pagineTERADATAAugsutoleconaNessuna valutazione finora
- Arquitectura de Un Sistema Gestor de Base de DatosDocumento7 pagineArquitectura de Un Sistema Gestor de Base de DatosBeycker SilvaNessuna valutazione finora
- DatastageDocumento21 pagineDatastagefendere183Nessuna valutazione finora
- Resumen de Conceptos Básicos de Apache AirflowDocumento7 pagineResumen de Conceptos Básicos de Apache AirflowElvira R ZeladaNessuna valutazione finora
- EnunciadoDocumento5 pagineEnunciadoLeox89Nessuna valutazione finora
- 9-Administracion de DatosDocumento36 pagine9-Administracion de DatosSantos CorralesNessuna valutazione finora
- Arquitectura OracleDocumento15 pagineArquitectura OracleErick MaxNessuna valutazione finora
- Prueba Técnica DBANube2020Documento4 paginePrueba Técnica DBANube2020Mauro RinconNessuna valutazione finora
- Formularios web y SGBD NoSQL en tercero técnico informáticaDocumento16 pagineFormularios web y SGBD NoSQL en tercero técnico informáticabyronNessuna valutazione finora
- Actividad 2 DDDDocumento8 pagineActividad 2 DDDGustavoLadinoNessuna valutazione finora
- Actividad 3Documento8 pagineActividad 3GustavoLadinoNessuna valutazione finora
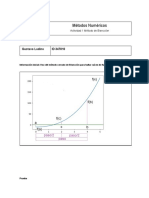
- Actividad 1 Métodos Numericos Biseccion Sabado 27-08Documento6 pagineActividad 1 Métodos Numericos Biseccion Sabado 27-08GustavoLadinoNessuna valutazione finora
- Ensayo Esquemas y Componentes de Una Red IPV6Documento6 pagineEnsayo Esquemas y Componentes de Una Red IPV6GustavoLadinoNessuna valutazione finora
- 09 - Prueba Tecnica Ing Soporte CesviDocumento3 pagine09 - Prueba Tecnica Ing Soporte CesviGustavoLadinoNessuna valutazione finora
- Modelos de Programación 2Documento155 pagineModelos de Programación 2GustavoLadinoNessuna valutazione finora
- Manual de Registro - Curso HuaweiDocumento9 pagineManual de Registro - Curso HuaweiGustavoLadinoNessuna valutazione finora
- Act Interc T3 V2Documento2 pagineAct Interc T3 V2GustavoLadinoNessuna valutazione finora
- CartillaU3S5 PDFDocumento21 pagineCartillaU3S5 PDFFernando SalaNessuna valutazione finora
- Acta Constitucion EmpresaDocumento4 pagineActa Constitucion EmpresaGustavoLadinoNessuna valutazione finora
- Guia - Estilo APA 7 Edicion UNIMINUTO 2020Documento33 pagineGuia - Estilo APA 7 Edicion UNIMINUTO 2020Amalia RojasNessuna valutazione finora
- Acta Constitucion EmpresaDocumento4 pagineActa Constitucion EmpresaGustavoLadinoNessuna valutazione finora
- EJB Java Beans EnterpriseDocumento15 pagineEJB Java Beans EnterpriseRandall CastilloNessuna valutazione finora
- Sistemas P2P suma nodosDocumento1 paginaSistemas P2P suma nodosGustavoLadinoNessuna valutazione finora
- ContratoDocumento6 pagineContratoGustavoLadinoNessuna valutazione finora
- Documento FinalDocumento24 pagineDocumento FinalGustavoLadinoNessuna valutazione finora
- Wholesite PDFDocumento157 pagineWholesite PDFDolores Ayala MuñozNessuna valutazione finora
- Volúmenes y sólidos de revolución: discos y arandelasDocumento6 pagineVolúmenes y sólidos de revolución: discos y arandelasGustavoLadinoNessuna valutazione finora
- Simulator Master Quiz2Documento8 pagineSimulator Master Quiz2GustavoLadinoNessuna valutazione finora
- Proceso de Grados Ceremonia 2-2020-1 - Compressed PDFDocumento1 paginaProceso de Grados Ceremonia 2-2020-1 - Compressed PDFGustavoLadinoNessuna valutazione finora
- Metodologías Ágiles en El Desarrollo de Aplicaciones para Dispositivos Móviles. Estado ActualDocumento14 pagineMetodologías Ágiles en El Desarrollo de Aplicaciones para Dispositivos Móviles. Estado ActualuglybullNessuna valutazione finora
- Vectores en R3Documento19 pagineVectores en R3GustavoLadinoNessuna valutazione finora
- Web Services Con PHP, para Poder Enviar Datos A Otro Sistema.Documento16 pagineWeb Services Con PHP, para Poder Enviar Datos A Otro Sistema.123sunNessuna valutazione finora
- Simulador ScrumDocumento22 pagineSimulador ScrumGustavoLadinoNessuna valutazione finora
- Simulator Master Quiz3 PDFDocumento8 pagineSimulator Master Quiz3 PDFGustavoLadinoNessuna valutazione finora
- Consumo de Cigarrillo PDFDocumento14 pagineConsumo de Cigarrillo PDFangie narvaezNessuna valutazione finora
- Simulator Master Quiz3A PDFDocumento9 pagineSimulator Master Quiz3A PDFGustavoLadinoNessuna valutazione finora
- db71 PDFDocumento41 paginedb71 PDFGustavoLadinoNessuna valutazione finora
- La historia del Cartucho: memorias de un barrio olvidadoDocumento132 pagineLa historia del Cartucho: memorias de un barrio olvidadoLuis NietoNessuna valutazione finora
- Material de Reforzamiento U7Documento2 pagineMaterial de Reforzamiento U7Jessi ParkNessuna valutazione finora
- Que Es La InfotecnologíaDocumento2 pagineQue Es La InfotecnologíaTurbo Services100% (2)
- Informe Historia Del InternetDocumento13 pagineInforme Historia Del InternetIsis Navas100% (3)
- Presentación PeopleSoftDocumento18 paginePresentación PeopleSoftSantiago Perez LozanoNessuna valutazione finora
- Acta NacimientoDocumento1 paginaActa NacimientoJuan HernandezNessuna valutazione finora
- CCS Compiler interrupciones y timersDocumento12 pagineCCS Compiler interrupciones y timersJose Luis Rosario SalvadorNessuna valutazione finora
- ¿Qué Es Azure SQL - Azure SQL - Microsoft DocsDocumento15 pagine¿Qué Es Azure SQL - Azure SQL - Microsoft DocsLuna Rebeca Mendoza AlonsoNessuna valutazione finora
- Informe Active DirectoryDocumento24 pagineInforme Active DirectoryKvn SanchezNessuna valutazione finora
- Recursos Unidad I BD - MRDocumento10 pagineRecursos Unidad I BD - MRrelajadoNessuna valutazione finora
- Examen rápido 3 de Inteligencia de NegociosDocumento5 pagineExamen rápido 3 de Inteligencia de NegociossilviNessuna valutazione finora
- Plan de Contingencia InformaticaDocumento9 paginePlan de Contingencia InformaticaJonathan VasquezNessuna valutazione finora
- Investigacion 3Documento6 pagineInvestigacion 3Jenny MartinezNessuna valutazione finora
- Ensayo CCNP SecurityDocumento10 pagineEnsayo CCNP SecurityMariel Madera RodriguezNessuna valutazione finora
- Curriculum Vitae Willy HodgsonDocumento3 pagineCurriculum Vitae Willy HodgsonWilly Hodgson RamosNessuna valutazione finora
- Plataforma Garza Syllabus 2 0 PDFDocumento17 paginePlataforma Garza Syllabus 2 0 PDFIsraelArrietaDoñúNessuna valutazione finora
- Estado Del Arte SAASDocumento3 pagineEstado Del Arte SAASGiancarlo André Márquez NevesNessuna valutazione finora
- Actividad 2Documento3 pagineActividad 2Yesid Gerardo Bernal EcheverriaNessuna valutazione finora
- Formas NormalesDocumento25 pagineFormas Normalesaracelly rivillasNessuna valutazione finora
- Actividad 4Documento23 pagineActividad 4Marcos ArriojasNessuna valutazione finora
- Sistema de Arquitectura Von NeumannDocumento13 pagineSistema de Arquitectura Von NeumannAlejandroEnriqueLucenaBarcoNessuna valutazione finora
- Reporte de Investigación: Clasificación de Hardware y SoftwareDocumento3 pagineReporte de Investigación: Clasificación de Hardware y SoftwareJared MontejoNessuna valutazione finora
- Cotización de Página Web Plan EconómicoDocumento2 pagineCotización de Página Web Plan EconómicoAlliASNessuna valutazione finora
- Reto Semana 10Documento1 paginaReto Semana 10Angel ZQNessuna valutazione finora
- SSTIDocumento12 pagineSSTIgochorneaNessuna valutazione finora
- Base de Datos de Un AlmacénDocumento2 pagineBase de Datos de Un AlmacénMary Elena Llanos RamírezNessuna valutazione finora
- AVALUO 5 Microsoft Word José AcevedoDocumento2 pagineAVALUO 5 Microsoft Word José AcevedoElia Gastón-NievesNessuna valutazione finora
- Actividad Entregable 1 .Informatica BasicaDocumento5 pagineActividad Entregable 1 .Informatica BasicaJhocem DiazNessuna valutazione finora