Potrebbero piacerti anche
- Getting Grounded On AnalyticsDocumento31 pagineGetting Grounded On AnalyticsIvan Jon Ferriol100% (2)
- Solution Manual To Engineering Mechanics StaticsDocumento6 pagineSolution Manual To Engineering Mechanics StaticsTony17% (18)
- Problem Set 5Documento5 pagineProblem Set 5Sila KapsataNessuna valutazione finora
- Statistical Basic Question and Solutions With Problem and Solutions.Documento9 pagineStatistical Basic Question and Solutions With Problem and Solutions.Atiqur RahmanNessuna valutazione finora
- Final Unit III Mathematic IV (Stat. Tech. I)Documento39 pagineFinal Unit III Mathematic IV (Stat. Tech. I)Piyush lavaniaNessuna valutazione finora
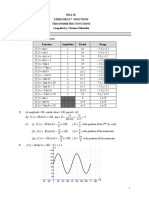
- 1 3 TransformationsDocumento7 pagine1 3 TransformationsSyeda Saman Zahra Zaidi/TCHR/GBFNessuna valutazione finora
- Functions Transformations Shifts Reflections CompositionDocumento7 pagineFunctions Transformations Shifts Reflections CompositionSyeda Saman Zahra Zaidi/TCHR/GBFNessuna valutazione finora
- 9 Prolog5 Cut List UpdatedDocumento51 pagine9 Prolog5 Cut List UpdateddongmianjunNessuna valutazione finora
- Assignment 4 MATH1090 Logic: Intermediate Value Theorem 0Documento18 pagineAssignment 4 MATH1090 Logic: Intermediate Value Theorem 0Shezi FeziNessuna valutazione finora
- Pattern Recognition Techniques and ApplicationsDocumento30 paginePattern Recognition Techniques and ApplicationsAshish MittalNessuna valutazione finora
- S1) Basic Probability ReviewDocumento71 pagineS1) Basic Probability ReviewMAYANK HARSANINessuna valutazione finora
- Inference in BNDocumento18 pagineInference in BNVaijayanthi SNessuna valutazione finora
- Daily Test Series 2010: Day 1 15.03.10 ChemistryDocumento4 pagineDaily Test Series 2010: Day 1 15.03.10 ChemistryMOHAMMED ASIFNessuna valutazione finora
- Topic 3.1Documento11 pagineTopic 3.1Damith ErangaNessuna valutazione finora
- Ece - 650 - Lect - 3 - SP - 15 - v7Documento40 pagineEce - 650 - Lect - 3 - SP - 15 - v7Mehul ShahNessuna valutazione finora
- Important Random Variables: BinomialDocumento15 pagineImportant Random Variables: Binomialsudhesh4u2003Nessuna valutazione finora
- Test DocumentDocumento7 pagineTest DocumentWaqas KhalidNessuna valutazione finora
- (MAI 3.8) TRIGONOMETRIC FUNCTIONS - SolutionsDocumento7 pagine(MAI 3.8) TRIGONOMETRIC FUNCTIONS - Solutionsdhaval.desai98Nessuna valutazione finora
- Root of Equations - Bracketing MethodsDocumento17 pagineRoot of Equations - Bracketing MethodssupergioNessuna valutazione finora
- 5 Prob - OverviewDocumento10 pagine5 Prob - OverviewRinnapat LertsakkongkulNessuna valutazione finora
- Math 600 Day 10: Lee Brackets of Vector FieldsDocumento16 pagineMath 600 Day 10: Lee Brackets of Vector FieldstestNessuna valutazione finora
- Term 1: Business Statistics: Session 4: Continuous Probability DistributionsDocumento26 pagineTerm 1: Business Statistics: Session 4: Continuous Probability DistributionsTanuj LalchandaniNessuna valutazione finora
- Chapter 9 - MeanDocumento74 pagineChapter 9 - MeanAarushNessuna valutazione finora
- Basic Probability ReviewDocumento77 pagineBasic Probability Reviewcoolapple123Nessuna valutazione finora
- VL2023240103477 DaDocumento3 pagineVL2023240103477 Dadeanambrose5004Nessuna valutazione finora
- CH 3 Probability TheoryDocumento14 pagineCH 3 Probability TheoryPoint BlankNessuna valutazione finora
- BCI PHD SeminarDocumento20 pagineBCI PHD Seminarastronom.saradnikNessuna valutazione finora
- MAT2001-STATISTICS FOR ENGINEERS-Probability DistributionsDocumento24 pagineMAT2001-STATISTICS FOR ENGINEERS-Probability DistributionsCathrine CruzNessuna valutazione finora
- 06 Joint DistributionsDocumento119 pagine06 Joint DistributionsEDM19B015 THODETI CHINA BABUNessuna valutazione finora
- Solutions HW 5Documento5 pagineSolutions HW 5Abcd EfghNessuna valutazione finora
- Expected Value:) P (X X X EDocumento28 pagineExpected Value:) P (X X X EQuyên Nguyễn HảiNessuna valutazione finora
- W9PSDocumento9 pagineW9PSpolar necksonNessuna valutazione finora
- Information Theory BasicsDocumento32 pagineInformation Theory BasicsSudesh KumarNessuna valutazione finora
- Lecture11Documento20 pagineLecture11AtpNessuna valutazione finora
- Trigonometric Functions SolutionsDocumento8 pagineTrigonometric Functions Solutionsamos attigahNessuna valutazione finora
- Mean Median ModeDocumento29 pagineMean Median ModeJc LanuzaNessuna valutazione finora
- Artificial Intelligence: Adina Magda FloreaDocumento36 pagineArtificial Intelligence: Adina Magda FloreaPablo Lorenzo Muños SanchesNessuna valutazione finora
- Chap 3Documento18 pagineChap 3MELASHU ARAGIENessuna valutazione finora
- Lectures Prepared By: Elchanan Mossel Yelena ShvetsDocumento21 pagineLectures Prepared By: Elchanan Mossel Yelena ShvetsAdil AliNessuna valutazione finora
- Huong Dan Lam Tat Ca Cac DangDocumento14 pagineHuong Dan Lam Tat Ca Cac DangNguyễn Chí CườngNessuna valutazione finora
- KSEEB Math Model Paper 2018-19Documento5 pagineKSEEB Math Model Paper 2018-19Vishwanath HarnalNessuna valutazione finora
- Lecture-Note of Chapter 4 From LemmiDocumento34 pagineLecture-Note of Chapter 4 From LemmiMustefa UsmaelNessuna valutazione finora
- MATH F113 Mid-Sem Solutions-ModifiedDocumento4 pagineMATH F113 Mid-Sem Solutions-Modifiedf20230746Nessuna valutazione finora
- Statistics For Business and Economics: 7 EditionDocumento57 pagineStatistics For Business and Economics: 7 EditionÜmit Mustafa GüzeyNessuna valutazione finora
- Jointly Distributed Random VariablesDocumento8 pagineJointly Distributed Random VariablesSoham SinhaNessuna valutazione finora
- STA416 - Topic 4 - 3Documento40 pagineSTA416 - Topic 4 - 3sofia the firstNessuna valutazione finora
- Surajit Roy - Numerical MethodsDocumento7 pagineSurajit Roy - Numerical Methodssurojitr420Nessuna valutazione finora
- B I M C M C S: Ayesian Nference and Arkov Hain Onte Arlo ImulationDocumento22 pagineB I M C M C S: Ayesian Nference and Arkov Hain Onte Arlo ImulationKanta PrajapatNessuna valutazione finora
- Discrete Random Variables and Probability DistributionsDocumento49 pagineDiscrete Random Variables and Probability DistributionsDali MetreveliNessuna valutazione finora
- Calculating Mean, Variance of Discrete Prob DistributionsDocumento51 pagineCalculating Mean, Variance of Discrete Prob DistributionsKathleen RafananNessuna valutazione finora
- Lecture 20Documento94 pagineLecture 20zaidNessuna valutazione finora
- Robust SlidesDocumento32 pagineRobust Slidesmyturtle game01Nessuna valutazione finora
- 4 ProbabilityDocumento31 pagine4 ProbabilityabaidNessuna valutazione finora
- Review02-Random VariablesDocumento39 pagineReview02-Random VariableskazunsanjayaNessuna valutazione finora
- 02 Tangent PlanesDocumento75 pagine02 Tangent PlanesyayNessuna valutazione finora
- College Algebra - Sample12Documento25 pagineCollege Algebra - Sample12AbchoNessuna valutazione finora
- Statistics For Business and Economics: 7 EditionDocumento52 pagineStatistics For Business and Economics: 7 EditionmanurivieraNessuna valutazione finora
- AB1202 Statistics and Analysis: (Part 1 of 2) Concepts of ProbabilityDocumento17 pagineAB1202 Statistics and Analysis: (Part 1 of 2) Concepts of ProbabilityxtheleNessuna valutazione finora
- The Apron Library Seminar on Static AnalysisDocumento56 pagineThe Apron Library Seminar on Static AnalysisArasuArunNessuna valutazione finora
- Assignment No.02 MTH100 (Fall2023)Documento3 pagineAssignment No.02 MTH100 (Fall2023)Mubashir aftabNessuna valutazione finora
- SRDS Lecture 2 Probability DistributionsDocumento35 pagineSRDS Lecture 2 Probability Distributionsprraaddeej chatelNessuna valutazione finora
- Radically Elementary Probability Theory. (AM-117), Volume 117Da EverandRadically Elementary Probability Theory. (AM-117), Volume 117Valutazione: 4 su 5 stelle4/5 (2)
- A Course of Mathematics for Engineerings and Scientists: Volume 5Da EverandA Course of Mathematics for Engineerings and Scientists: Volume 5Nessuna valutazione finora
- CV NotesDocumento314 pagineCV NotesAndrew FuNessuna valutazione finora
- GT Robotics Guide: Algorithms for Localization and PlanningDocumento33 pagineGT Robotics Guide: Algorithms for Localization and PlanningAndrew FuNessuna valutazione finora
- The Category Partition MethodDocumento11 pagineThe Category Partition MethodAndrew FuNessuna valutazione finora
- The Category Partition MethodDocumento11 pagineThe Category Partition MethodAndrew FuNessuna valutazione finora
- 2011-IEEE TSMC PartC - GalarFdezBarrenecheaBustinceHerreraDocumento22 pagine2011-IEEE TSMC PartC - GalarFdezBarrenecheaBustinceHerrerasuman deyNessuna valutazione finora
- White box test techniques: Statement, Branch and Path coverageDocumento4 pagineWhite box test techniques: Statement, Branch and Path coverageAndrew FuNessuna valutazione finora
- Mastering Markdown GitHub GuidesDocumento7 pagineMastering Markdown GitHub GuidesAndrew FuNessuna valutazione finora
- A Survey of Predictive Modelling Under Imbalanced Distributions PDFDocumento48 pagineA Survey of Predictive Modelling Under Imbalanced Distributions PDFAndrew FuNessuna valutazione finora
- UML BookDocumento710 pagineUML Bookapi-3706009100% (1)
- Black Box Test Techiniques - SW Testing ConceptsDocumento2 pagineBlack Box Test Techiniques - SW Testing ConceptsAndrew FuNessuna valutazione finora
- Conda Cheat Sheet: Bit - Ly/trycondaDocumento2 pagineConda Cheat Sheet: Bit - Ly/trycondamaxellligue5487Nessuna valutazione finora
- White box test techniques: Statement, Branch and Path coverageDocumento4 pagineWhite box test techniques: Statement, Branch and Path coverageAndrew FuNessuna valutazione finora
- SSRN Id2557236Documento100 pagineSSRN Id2557236Andrew FuNessuna valutazione finora
- Factor Investing Boosts Corporate Bond ReturnsDocumento49 pagineFactor Investing Boosts Corporate Bond ReturnsAndrew FuNessuna valutazione finora
- SSRN Id3015609Documento19 pagineSSRN Id3015609Andrew FuNessuna valutazione finora
- SSRN Id191668Documento33 pagineSSRN Id191668Andrew FuNessuna valutazione finora
- Ten Financial Applications of Machine Learning: Marcos López de PradoDocumento20 pagineTen Financial Applications of Machine Learning: Marcos López de PradoAndrew FuNessuna valutazione finora
- Leetcode - Find KTH Number in M Sorted ArraysDocumento5 pagineLeetcode - Find KTH Number in M Sorted ArraysAndrew FuNessuna valutazione finora
- A Practical Guide To Quantitative Portafolio TradingDocumento842 pagineA Practical Guide To Quantitative Portafolio Tradingalexa_sherpyNessuna valutazione finora
- Predictions 2011Documento8 paginePredictions 2011Andrew FuNessuna valutazione finora
- ModelsDocumento16 pagineModelsAndrew FuNessuna valutazione finora
- A Macro Framework For Equity ValuationDocumento3 pagineA Macro Framework For Equity Valuationmarketfolly.com100% (3)
- Market Club Diversification 30Documento10 pagineMarket Club Diversification 30Meshach ManoharNessuna valutazione finora
- Energy Markets and Risk-The Big PictureDocumento18 pagineEnergy Markets and Risk-The Big PictureAndrew FuNessuna valutazione finora
- Sampling Plans Guide Acceptance MethodsDocumento16 pagineSampling Plans Guide Acceptance MethodssamadmsinNessuna valutazione finora
- Introductory Statistics 10th Edition Weiss Test BankDocumento36 pagineIntroductory Statistics 10th Edition Weiss Test Bankethelbertsangffz100% (28)
- Kernel Density Estimation of Traffic Accidents in A Network SpaceDocumento39 pagineKernel Density Estimation of Traffic Accidents in A Network SpaceboskomatovicNessuna valutazione finora
- Statistics ExamplesDocumento2 pagineStatistics ExamplesJake CimafrancaNessuna valutazione finora
- Nonparametric Hypothesis Testing Procedures ExplainedDocumento54 pagineNonparametric Hypothesis Testing Procedures ExplainedYeshambel EwunetuNessuna valutazione finora
- Examining methods to improve Parkinson's disease diagnosisDocumento10 pagineExamining methods to improve Parkinson's disease diagnosisBharat DedhiaNessuna valutazione finora
- BRM MCQs ExplainedDocumento65 pagineBRM MCQs ExplainedTushar WasuNessuna valutazione finora
- Fully Corrected Chapters 4 & 5Documento21 pagineFully Corrected Chapters 4 & 5Iyobosa OmoregieNessuna valutazione finora
- Charter School Achievement What We KnowDocumento50 pagineCharter School Achievement What We KnowIRPSNessuna valutazione finora
- Understanding Randomised Controlled TrialsDocumento5 pagineUnderstanding Randomised Controlled TrialsWafiy AkmalNessuna valutazione finora
- Getting The Information You Need: Data CollectionDocumento52 pagineGetting The Information You Need: Data CollectiontyagidonNessuna valutazione finora
- Assessment of Prevalence Knowledge Attitude and Psychosocial Impact of Acne Vulgaris Among Medical Students in Saudi Arabia 2155 9554 1000404 PDFDocumento7 pagineAssessment of Prevalence Knowledge Attitude and Psychosocial Impact of Acne Vulgaris Among Medical Students in Saudi Arabia 2155 9554 1000404 PDFerinNessuna valutazione finora
- Predictive Machine Learning Applying Cross Industry Standard Process For Data Mining For The Diagnosis of Diabetes Mellitus Type 2Documento14 paginePredictive Machine Learning Applying Cross Industry Standard Process For Data Mining For The Diagnosis of Diabetes Mellitus Type 2IAES IJAINessuna valutazione finora
- Categories of Forecasting Methods: Qualitative vs. Quantitative MethodsDocumento5 pagineCategories of Forecasting Methods: Qualitative vs. Quantitative MethodsAnthonio MaraghNessuna valutazione finora
- Money RoadDocumento9 pagineMoney RoadVicente CáceresNessuna valutazione finora
- Patient Satisfaction and Hospital Facilities AnalysisDocumento7 paginePatient Satisfaction and Hospital Facilities Analysis08999575874Nessuna valutazione finora
- Machine Learning: An Applied Econometric Approach: Sendhil Mullainathan and Jann SpiessDocumento48 pagineMachine Learning: An Applied Econometric Approach: Sendhil Mullainathan and Jann SpiessFabian SalazarNessuna valutazione finora
- CHAPTER3 - Discrete Random VariablesDocumento28 pagineCHAPTER3 - Discrete Random VariablesDustin WhiteNessuna valutazione finora
- Statistics Made Easy PresentationDocumento226 pagineStatistics Made Easy PresentationHariomMaheshwariNessuna valutazione finora
- Data Driven Market Making Via Model Free LearningDocumento8 pagineData Driven Market Making Via Model Free Learningif05041736Nessuna valutazione finora
- Design of Spar-Type Floating Substructures For A 2.5MW-Class Wind Turbine Using Fluid-Structure Coupled AnalysisDocumento13 pagineDesign of Spar-Type Floating Substructures For A 2.5MW-Class Wind Turbine Using Fluid-Structure Coupled AnalysisBehairy AhmedNessuna valutazione finora
- 4282818Documento23 pagine4282818Raquel FernandesNessuna valutazione finora
- Researching Religion Using Quantitative DataDocumento12 pagineResearching Religion Using Quantitative DataJovanaNessuna valutazione finora
- AP Statistics Practice ExamDocumento7 pagineAP Statistics Practice ExamldlewisNessuna valutazione finora
- PMP ITTOsDocumento12 paginePMP ITTOsHari Karan S100% (1)
- Intercomparison of Methods To Estimate Black Carbon EmissionsDocumento8 pagineIntercomparison of Methods To Estimate Black Carbon EmissionsJoy RoyNessuna valutazione finora
- Estimated Realisation Price (ERP) by Neural Networks: Forecasting Commercial Property ValuesDocumento16 pagineEstimated Realisation Price (ERP) by Neural Networks: Forecasting Commercial Property ValuesHarry RandleNessuna valutazione finora