Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Python Programming For Mechanical EngineersDocumento93 paginePython Programming For Mechanical Engineershichem YT100% (1)
- Navier - Stokes Equations: Grzegorz Łukaszewicz Piotr KalitaDocumento30 pagineNavier - Stokes Equations: Grzegorz Łukaszewicz Piotr KalitaAhmed SajitNessuna valutazione finora
- Small Engine SimulationDocumento20 pagineSmall Engine SimulationAhmed SajitNessuna valutazione finora
- 1-d Ic Engine Model With Python PDFDocumento11 pagine1-d Ic Engine Model With Python PDFAhmed SajitNessuna valutazione finora
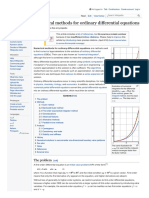
- Ode WikiDocumento10 pagineOde WikiAhmed SajitNessuna valutazione finora
- Characterization of Waste Frying Oils Obtained From Different FacilitiesDocumento7 pagineCharacterization of Waste Frying Oils Obtained From Different FacilitiesAhmed SajitNessuna valutazione finora
- 2007 - Terry Hendricks PDFDocumento181 pagine2007 - Terry Hendricks PDFAhmed SajitNessuna valutazione finora
- Issue Brief BioenergyDocumento6 pagineIssue Brief BioenergyAhmed SajitNessuna valutazione finora
- 2007 - Terry Hendricks PDFDocumento181 pagine2007 - Terry Hendricks PDFAhmed SajitNessuna valutazione finora
- Fuel Air CycleDocumento10 pagineFuel Air CycleJaysukh Ghetiya63% (8)
- ICESym Quick Start Guide for Simulating a Two-Cylinder EngineDocumento4 pagineICESym Quick Start Guide for Simulating a Two-Cylinder EngineAhmed SajitNessuna valutazione finora
- Non-Conventional Seed Oils As Potential Feedstocks For Future Biodiesel Industries: A Brief ReviewDocumento6 pagineNon-Conventional Seed Oils As Potential Feedstocks For Future Biodiesel Industries: A Brief ReviewAhmed SajitNessuna valutazione finora
- (Ebook - PDF) How To Crack CD Protections PDFDocumento4 pagine(Ebook - PDF) How To Crack CD Protections PDFJorge ArévaloNessuna valutazione finora
- 5.self Declaration of Minority Community 2311 PDFDocumento1 pagina5.self Declaration of Minority Community 2311 PDFSanjida100% (1)
- 100 Questions On EnvironmentDocumento20 pagine100 Questions On EnvironmentvgasNessuna valutazione finora
- Biodiesel Analytical MethodsDocumento100 pagineBiodiesel Analytical MethodsNicolás Cárcamo AstorgaNessuna valutazione finora
- V001t02a010 Icef2016 9383Documento8 pagineV001t02a010 Icef2016 9383Ahmed SajitNessuna valutazione finora
- List of Journals - SCI and SSCIDocumento69 pagineList of Journals - SCI and SSCIRahul RajNessuna valutazione finora
- International Literature Review On The Possibilities of Biodiesel ProductionDocumento7 pagineInternational Literature Review On The Possibilities of Biodiesel ProductionAhmed SajitNessuna valutazione finora
- Writing Idiomatic Python 3 PDFDocumento66 pagineWriting Idiomatic Python 3 PDFMonty Singh100% (3)
- Previous Year Questions CultureDocumento6 paginePrevious Year Questions CultureAhmed SajitNessuna valutazione finora
- Mel713 37Documento46 pagineMel713 37Rudresh AnandNessuna valutazione finora
- IASbaba Current Affairs Monthly Magazine - NOVEMBER 2016Documento2 pagineIASbaba Current Affairs Monthly Magazine - NOVEMBER 2016Ahmed SajitNessuna valutazione finora
- Convocation Notification 25.10.2017Documento3 pagineConvocation Notification 25.10.2017Ahmed SajitNessuna valutazione finora
- Previous Year Questions Amp Solutions Medieval HistoryDocumento3 paginePrevious Year Questions Amp Solutions Medieval HistoryAhmed SajitNessuna valutazione finora
- Previous Year Questions Amp Solutions - Modern HistoryDocumento9 paginePrevious Year Questions Amp Solutions - Modern HistoryAhmed SajitNessuna valutazione finora
- IASbaba Current Affairs Monthly Magazine - OCTOBER 2016Documento1 paginaIASbaba Current Affairs Monthly Magazine - OCTOBER 2016Ahmed SajitNessuna valutazione finora
- Indian Amateur MMS Videos: Closeup Anal and Vaginal SexDocumento6 pagineIndian Amateur MMS Videos: Closeup Anal and Vaginal SexAhmed SajitNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Dynamic Programming: Fundamrntals of Computer AlgorithmsDocumento33 pagineDynamic Programming: Fundamrntals of Computer Algorithmsshanthi prabhaNessuna valutazione finora
- SOL - DU - MBAFT-6202 Decision Modeling and Optimization With Distributed NetworkDocumento45 pagineSOL - DU - MBAFT-6202 Decision Modeling and Optimization With Distributed NetworkAmish SinghNessuna valutazione finora
- January 2022Documento8 pagineJanuary 2022Jasser ChtourouNessuna valutazione finora
- Linear Algebra MCQsDocumento75 pagineLinear Algebra MCQsMuhammad Arslan Rasool100% (1)
- Angles and the Unit Circle Trigonometry GuideDocumento3 pagineAngles and the Unit Circle Trigonometry GuideEsmeralda LopezNessuna valutazione finora
- Test 9 - Find the value of √8 − 2√8 − 2√8 − 2√8 − 2√8Documento1 paginaTest 9 - Find the value of √8 − 2√8 − 2√8 − 2√8 − 2√8Musab AlbarbariNessuna valutazione finora
- Homework 4 SolutionsDocumento7 pagineHomework 4 Solutionsstett100% (2)
- LAPLACE TRANSFORM TITLEDocumento4 pagineLAPLACE TRANSFORM TITLEtingliang0831Nessuna valutazione finora
- Absolute Maxima and MinimaDocumento3 pagineAbsolute Maxima and MinimaTANEESH VARMMA SNessuna valutazione finora
- Mathematics-V Lab ManualDocumento28 pagineMathematics-V Lab ManualAyshath AsnaNessuna valutazione finora
- END 395 Lecture 5 HandoutDocumento5 pagineEND 395 Lecture 5 HandoutFerda ÇetikNessuna valutazione finora
- Inverse Power Method, Shifted Power Method and DeflationDocumento4 pagineInverse Power Method, Shifted Power Method and DeflationM.Y M.ANessuna valutazione finora
- Lesson 1 AntiDerivativesDocumento9 pagineLesson 1 AntiDerivativesomay12Nessuna valutazione finora
- Rational Functions Represent Real-Life SituationsDocumento19 pagineRational Functions Represent Real-Life SituationsCarbon CopyNessuna valutazione finora
- Name. Kishankumar Goud Roll No. 37 Class. Fybsc - It Div. A: Numerical and Statistical MethodDocumento28 pagineName. Kishankumar Goud Roll No. 37 Class. Fybsc - It Div. A: Numerical and Statistical MethodKajal GoudNessuna valutazione finora
- Functions and Calculus ConceptsDocumento18 pagineFunctions and Calculus ConceptsMichael AliagaNessuna valutazione finora
- FLab-04 EXP4Documento20 pagineFLab-04 EXP4Carl Kevin CartijanoNessuna valutazione finora
- General Mathematics Exam Reviewer (Grade 11, First Quarter)Documento13 pagineGeneral Mathematics Exam Reviewer (Grade 11, First Quarter)jv sy75% (4)
- Solving Systems of Linear Equations Using Matrices PDFDocumento11 pagineSolving Systems of Linear Equations Using Matrices PDFRen Joseph LogronioNessuna valutazione finora
- Inverse Trigonometric Functions: Principal Value Range and Domain of ITFDocumento47 pagineInverse Trigonometric Functions: Principal Value Range and Domain of ITFDgjnNessuna valutazione finora
- AlgebraDocumento9 pagineAlgebraJunaid K JumaniNessuna valutazione finora
- Restrained Lict Domination in GraphsDocumento7 pagineRestrained Lict Domination in GraphsInternational Journal of Research in Engineering and TechnologyNessuna valutazione finora
- AIHManualDocumento57 pagineAIHManuallaxman gupttaNessuna valutazione finora
- Analysis and Design of AlgorithmsDocumento4 pagineAnalysis and Design of AlgorithmsSAMAY N. JAINNessuna valutazione finora
- Lecture Design PatternsDocumento27 pagineLecture Design Patterns220103172Nessuna valutazione finora
- StewartCalc8 07 05Documento21 pagineStewartCalc8 07 05Hera leyNessuna valutazione finora
- General Mathematics NatDocumento7 pagineGeneral Mathematics NatPearl Arianne Moncada MontealegreNessuna valutazione finora
- Ma6351 Tpde PDFDocumento295 pagineMa6351 Tpde PDFNe En JoviNessuna valutazione finora
- Interpolation: Finite DifferencesDocumento18 pagineInterpolation: Finite DifferencesImrul HasanNessuna valutazione finora
- Final Test Mae101 Fall 2019 HiepttDocumento18 pagineFinal Test Mae101 Fall 2019 HiepttNguyễn Duy ĐạtNessuna valutazione finora