Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Not A Toy Sample PDFDocumento37 pagineNot A Toy Sample PDFMartha Paola CorralesNessuna valutazione finora
- SyncopeDocumento105 pagineSyncopeJohn DasNessuna valutazione finora
- Image Enhancement - Frequency DomainDocumento33 pagineImage Enhancement - Frequency DomainKani MozhiNessuna valutazione finora
- Identification of Normal and Abnormal Ecg Using Neural NetworkDocumento6 pagineIdentification of Normal and Abnormal Ecg Using Neural NetworkKani MozhiNessuna valutazione finora
- Go L Riz Khatami ZahraDocumento103 pagineGo L Riz Khatami ZahraKani MozhiNessuna valutazione finora
- Deep Learning Algorithm For Arrhythmia Detection: Hilmy Assodiky, Iwan Syarif, Tessy BadriyahDocumento7 pagineDeep Learning Algorithm For Arrhythmia Detection: Hilmy Assodiky, Iwan Syarif, Tessy BadriyahKani MozhiNessuna valutazione finora
- Classification of ECC SignalsDocumento28 pagineClassification of ECC SignalsKani MozhiNessuna valutazione finora
- Electronic Mail SecurityDocumento29 pagineElectronic Mail SecurityKani MozhiNessuna valutazione finora
- Classification of ECG Signals Using Machine Learning Techniques: A SurveyDocumento8 pagineClassification of ECG Signals Using Machine Learning Techniques: A SurveyKani MozhiNessuna valutazione finora
- Part 5: Transport Protocols For Wireless Mobile Networks: Sequence NumbersDocumento6 paginePart 5: Transport Protocols For Wireless Mobile Networks: Sequence NumbersKani MozhiNessuna valutazione finora
- A Novel Atrial Fibrillation Prediction Algorithm Applicable To Recordings From Portable DevicesDocumento4 pagineA Novel Atrial Fibrillation Prediction Algorithm Applicable To Recordings From Portable DevicesKani MozhiNessuna valutazione finora
- Brian 2017Documento6 pagineBrian 2017Kani MozhiNessuna valutazione finora
- Automatic Classification of ECG Signal For Heart Disease Diagnosis Using Morphological FeaturesDocumento7 pagineAutomatic Classification of ECG Signal For Heart Disease Diagnosis Using Morphological FeaturesKani MozhiNessuna valutazione finora
- ECG Signal ClassificationDocumento34 pagineECG Signal ClassificationKani MozhiNessuna valutazione finora
- Btnodes: Design and Deployment of Wireless Networked Embedded SystemsDocumento42 pagineBtnodes: Design and Deployment of Wireless Networked Embedded SystemsKani MozhiNessuna valutazione finora
- Embedded SystemsDocumento1 paginaEmbedded SystemsKani MozhiNessuna valutazione finora
- BEI605 Embedded SystemDocumento79 pagineBEI605 Embedded SystemKani Mozhi100% (2)
- Today: Wired Embedded Networks: Characteristics and Requirements Some Embedded LansDocumento25 pagineToday: Wired Embedded Networks: Characteristics and Requirements Some Embedded LansKani MozhiNessuna valutazione finora
- On The Design and Control of Wireless Networked Embedded SystemsDocumento6 pagineOn The Design and Control of Wireless Networked Embedded SystemsKani MozhiNessuna valutazione finora
- (TCP Ip) IntroDocumento43 pagine(TCP Ip) IntroKani MozhiNessuna valutazione finora
- cc11Documento793 paginecc11s_padu3003@yahoo.comNessuna valutazione finora
- HRMDocumento118 pagineHRMKarthic KasiliaNessuna valutazione finora
- Design and Analysis of Modified Front Double Wishbone Suspension For A Three Wheel Hybrid VehicleDocumento4 pagineDesign and Analysis of Modified Front Double Wishbone Suspension For A Three Wheel Hybrid VehicleRima AroraNessuna valutazione finora
- FpsecrashlogDocumento19 pagineFpsecrashlogtim lokNessuna valutazione finora
- Angle Grinder Gws 7 100 06013880f0Documento128 pagineAngle Grinder Gws 7 100 06013880f0Kartik ParmeshwaranNessuna valutazione finora
- Comparative Study Between Online and Offilne Learning With Reference of Tutedude E-LearningDocumento61 pagineComparative Study Between Online and Offilne Learning With Reference of Tutedude E-LearningDeeksha Saxena0% (2)
- Arduino Uno CNC ShieldDocumento11 pagineArduino Uno CNC ShieldMărian IoanNessuna valutazione finora
- (Campus of Open Learning) University of Delhi Delhi-110007Documento1 pagina(Campus of Open Learning) University of Delhi Delhi-110007Sahil Singh RanaNessuna valutazione finora
- 1995 Biology Paper I Marking SchemeDocumento13 pagine1995 Biology Paper I Marking Schemetramysss100% (2)
- EKRP311 Vc-Jun2022Documento3 pagineEKRP311 Vc-Jun2022dfmosesi78Nessuna valutazione finora
- ResumeDocumento3 pagineResumeapi-280300136Nessuna valutazione finora
- A Noble Noose of Methods - ExtendedDocumento388 pagineA Noble Noose of Methods - ExtendedtomasiskoNessuna valutazione finora
- Question Answers of Chapter 13 Class 5Documento6 pagineQuestion Answers of Chapter 13 Class 5SuvashreePradhanNessuna valutazione finora
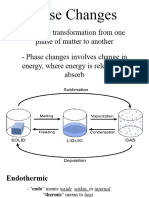
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDocumento19 pagineGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaNessuna valutazione finora
- DION IMPACT 9102 SeriesDocumento5 pagineDION IMPACT 9102 SeriesLENEEVERSONNessuna valutazione finora
- 2016 IT - Sheilding Guide PDFDocumento40 pagine2016 IT - Sheilding Guide PDFlazarosNessuna valutazione finora
- Introduction - Livspace - RenoDocumento12 pagineIntroduction - Livspace - RenoMêghnâ BîswâsNessuna valutazione finora
- Speed, Velocity & Acceleration (Physics Report)Documento66 pagineSpeed, Velocity & Acceleration (Physics Report)Kristian Dave DivaNessuna valutazione finora
- MME 52106 - Optimization in Matlab - NN ToolboxDocumento14 pagineMME 52106 - Optimization in Matlab - NN ToolboxAdarshNessuna valutazione finora
- DMIT - Midbrain - DMIT SoftwareDocumento16 pagineDMIT - Midbrain - DMIT SoftwarevinNessuna valutazione finora
- I I I I: Peroxid.Q!Documento2 pagineI I I I: Peroxid.Q!Diego PradelNessuna valutazione finora
- UM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Documento154 pagineUM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Antony Jacob AshishNessuna valutazione finora
- Formula:: High Low Method (High - Low) Break-Even PointDocumento24 pagineFormula:: High Low Method (High - Low) Break-Even PointRedgie Mark UrsalNessuna valutazione finora
- Syllabus: What Is Artificial Intelligence? ProblemsDocumento66 pagineSyllabus: What Is Artificial Intelligence? ProblemsUdupiSri groupNessuna valutazione finora
- Account Statement 250820 240920 PDFDocumento2 pagineAccount Statement 250820 240920 PDFUnknown100% (1)
- Pantalla MTA 100Documento84 paginePantalla MTA 100dariocontrolNessuna valutazione finora
- Numerical Modelling and Design of Electrical DevicesDocumento69 pagineNumerical Modelling and Design of Electrical Devicesfabrice mellantNessuna valutazione finora
- Brigade Product Catalogue Edition 20 EnglishDocumento88 pagineBrigade Product Catalogue Edition 20 EnglishPelotudoPeloteroNessuna valutazione finora
- Solubility Product ConstantsDocumento6 pagineSolubility Product ConstantsBilal AhmedNessuna valutazione finora