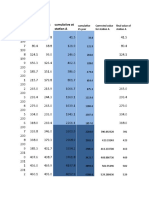
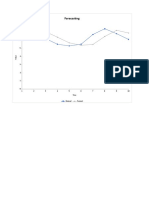
Potrebbero piacerti anche
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesDa EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesValutazione: 5 su 5 stelle5/5 (3)
- 1.0 - Ap - Intro To Ap CalculusDocumento4 pagine1.0 - Ap - Intro To Ap CalculusmohamedNessuna valutazione finora
- Section I: Pipes Flowing Under Pressure Tables For Discharge and Loss of Head and PowerDocumento42 pagineSection I: Pipes Flowing Under Pressure Tables For Discharge and Loss of Head and PowerVishakha PatelNessuna valutazione finora
- Business Statistics AssignmentDocumento9 pagineBusiness Statistics AssignmentkshitijNessuna valutazione finora
- P324 08A MP 02 DPD Calc KeyDocumento2 pagineP324 08A MP 02 DPD Calc KeySrimonta RoyNessuna valutazione finora
- Polyethylene Pe SDR Pressure Rated TubeDocumento1 paginaPolyethylene Pe SDR Pressure Rated TubeJaime RamirezNessuna valutazione finora
- Peps2 Muhammad AndhikaDocumento5 paginePeps2 Muhammad AndhikaMuhammad AndhikaNessuna valutazione finora
- Print Tabel - BrgndaDocumento3 paginePrint Tabel - BrgndaNovilma Maryeci DukaNessuna valutazione finora
- Water 2 Assignment 01Documento8 pagineWater 2 Assignment 01Talha BhuttoNessuna valutazione finora
- Stainlesssteel Sheets As Per Astm&Weight-Kg.: Thickness Sizes MM 1219mm X 2438mm 1524mm X 3048mmDocumento3 pagineStainlesssteel Sheets As Per Astm&Weight-Kg.: Thickness Sizes MM 1219mm X 2438mm 1524mm X 3048mmuaarNessuna valutazione finora
- Shear Box Test ReportDocumento6 pagineShear Box Test Reportnishan_ravin50% (2)
- GlifosatoDocumento8 pagineGlifosatoCarlos Mesa OrozcoNessuna valutazione finora
- Biproses GrafikDocumento5 pagineBiproses GrafikAhmad AfifNessuna valutazione finora
- Fisica FiinalDocumento3 pagineFisica FiinalRonald HurtadoNessuna valutazione finora
- Electricity Data SetDocumento1 paginaElectricity Data Setr.warne-23Nessuna valutazione finora
- Universiyt of Benghazi (Autorecovered)Documento6 pagineUniversiyt of Benghazi (Autorecovered)Abrahim SahatiNessuna valutazione finora
- Tecno 3Documento21 pagineTecno 3williamlz2016Nessuna valutazione finora
- Lloyds TableDocumento4 pagineLloyds Tablerf.rifki3Nessuna valutazione finora
- عبدالله سيد محمد علىDocumento17 pagineعبدالله سيد محمد علىAhmed HoursNessuna valutazione finora
- Lecture7appendixa 12thsep2009Documento31 pagineLecture7appendixa 12thsep2009Richa ShekharNessuna valutazione finora
- Taller Conservacion ResueltoDocumento21 pagineTaller Conservacion ResueltoElian Josue MontalvoNessuna valutazione finora
- ThermoooDocumento15 pagineThermoooNor Hamizah HassanNessuna valutazione finora
- Van Der Hoven SpectrumDocumento4 pagineVan Der Hoven SpectrumFirdous Ul NazirNessuna valutazione finora
- 5000 Series Std. Angle Rain Curtain™ Nozzle Performance 5000 Series Std. Angle Rain Curtain™ Nozzle Performance METRICDocumento4 pagine5000 Series Std. Angle Rain Curtain™ Nozzle Performance 5000 Series Std. Angle Rain Curtain™ Nozzle Performance METRICLeo MedinaNessuna valutazione finora
- Schedule 40 MS PipesDocumento2 pagineSchedule 40 MS PipesASIM MURTAZANessuna valutazione finora
- HVI Results Compiled TableDocumento1 paginaHVI Results Compiled TableSaurav GhoshNessuna valutazione finora
- Tabel Semilatimi Nava N3Documento31 pagineTabel Semilatimi Nava N3abcdefghijNessuna valutazione finora
- La Première ExpérienceDocumento5 pagineLa Première ExpérienceMohamed El-amine BendjoudaNessuna valutazione finora
- 2 Tabel (Taraf 5%, DB 3)Documento11 pagine2 Tabel (Taraf 5%, DB 3)Hilarius SetiawanNessuna valutazione finora
- Ejemplo 2 PlantillaDocumento29 pagineEjemplo 2 PlantillaJairo GarciaNessuna valutazione finora
- S01TOPO SUBTERRANEA UPN Grupo2Documento8 pagineS01TOPO SUBTERRANEA UPN Grupo2kvnNessuna valutazione finora
- PrykRea INdicadores Avon 1.Documento41 paginePrykRea INdicadores Avon 1.Diana PalaciosNessuna valutazione finora
- 1SBC009500R1002Documento118 pagine1SBC009500R1002Mohamad Kanzul fikri xii-mipa-8 20Nessuna valutazione finora
- 20210114070145Documento5 pagine20210114070145Kvin QuezadaNessuna valutazione finora
- Using Excel'S Rand FunctionDocumento239 pagineUsing Excel'S Rand FunctionSyed Ameer Ali ShahNessuna valutazione finora
- Asg 4 DataDocumento1 paginaAsg 4 DataCherry NgNessuna valutazione finora
- Proximate-Ultimate June 2022Documento25 pagineProximate-Ultimate June 2022Ridhwan IvandraNessuna valutazione finora
- Calcule BozDocumento21 pagineCalcule BozAnca MariaNessuna valutazione finora
- Examen 2, QuizDocumento9 pagineExamen 2, QuizJUNIOR STEVEN CORRALES MADRIZNessuna valutazione finora
- Settlement Analysis of Shallow Foundations Schmertmann MethodDocumento2 pagineSettlement Analysis of Shallow Foundations Schmertmann MethodmdalgamouniNessuna valutazione finora
- Reported Data Corrected Data For 760 MMHG and Vol. Loss Fraction # P, MM HG Cutt (F) V% Sum V% SP - GR@ 60/60 (F) Corrected T (F) Corrected V%Documento3 pagineReported Data Corrected Data For 760 MMHG and Vol. Loss Fraction # P, MM HG Cutt (F) V% Sum V% SP - GR@ 60/60 (F) Corrected T (F) Corrected V%Siraj AL sharifNessuna valutazione finora
- PropertiesDocumento5 paginePropertiesskumarsrNessuna valutazione finora
- PVC WT Per Meter 2Documento2 paginePVC WT Per Meter 2webhareggebru06Nessuna valutazione finora
- Al Kasyaf Nur (202010073) - PERBAIKANDocumento36 pagineAl Kasyaf Nur (202010073) - PERBAIKANTiara FelisNessuna valutazione finora
- CALIBTKDocumento1 paginaCALIBTKPaul CarlyNessuna valutazione finora
- Ejercicios en BiofarmaciaDocumento8 pagineEjercicios en BiofarmaciaAlan Luis CVNessuna valutazione finora
- RLL.1 CC'21 No.2Documento7 pagineRLL.1 CC'21 No.2Sinthya MatteNessuna valutazione finora
- Api 5L SCH 40Documento2 pagineApi 5L SCH 40Viet DangNessuna valutazione finora
- SCH Asdamert Mann CorrectedDocumento9 pagineSCH Asdamert Mann CorrectedJan Roald Buemia TriumfanteNessuna valutazione finora
- R600a Iso Butane PT ChartDocumento2 pagineR600a Iso Butane PT ChartmohammadNessuna valutazione finora
- R600a Iso Butane PT Chart PDFDocumento2 pagineR600a Iso Butane PT Chart PDFKesavReddyNessuna valutazione finora
- R600a Iso Butane PT ChartDocumento2 pagineR600a Iso Butane PT ChartlabNessuna valutazione finora
- R600a Iso Butane PT Chart PDFDocumento2 pagineR600a Iso Butane PT Chart PDFscotchkarmaNessuna valutazione finora
- R600a Iso Butane PT Chart PDFDocumento2 pagineR600a Iso Butane PT Chart PDFAnjan Ahsanul Kabir0% (1)
- Enrichment Exam in StatisticsDocumento9 pagineEnrichment Exam in StatisticsMary Rose LinihanNessuna valutazione finora
- Performance Test Results of Modified Bio-Asphalt.: Table 7Documento1 paginaPerformance Test Results of Modified Bio-Asphalt.: Table 7dazulu18Nessuna valutazione finora
- Ejemplo 2 Regresión Lineal Multiple DesarrolladoDocumento14 pagineEjemplo 2 Regresión Lineal Multiple DesarrolladoLuis Enrique Tuñoque GutiérrezNessuna valutazione finora
- T Year Half-Year Sales (1000s) : Rmse Aka Y Y /cma S, IDocumento40 pagineT Year Half-Year Sales (1000s) : Rmse Aka Y Y /cma S, IMrittika Rahman ProttashaNessuna valutazione finora
- Weibull Median Ranks TableDocumento2 pagineWeibull Median Ranks TableOriana Palencia Finol100% (1)
- DN Pipe PDFDocumento6 pagineDN Pipe PDFnassimNessuna valutazione finora
- Paul Kline-An Easy Guide To Factor Analysis-Routledge (1993)Documento24 paginePaul Kline-An Easy Guide To Factor Analysis-Routledge (1993)rknagi0% (1)
- Long Quiz Mathematics 7 NAME: - DATE: - GRADE & SECTION: - SCOREDocumento3 pagineLong Quiz Mathematics 7 NAME: - DATE: - GRADE & SECTION: - SCOREPepito Rosario Baniqued, JrNessuna valutazione finora
- Classification of Metaphase Chromosomes Using Deep Learning Neural NetworkDocumento5 pagineClassification of Metaphase Chromosomes Using Deep Learning Neural NetworkAurangzeb ChaudharyNessuna valutazione finora
- The Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyDocumento17 pagineThe Percentage Oil Content, P, and The Weight, W Milligrams, of Each of 10 RandomlyHalal BoiNessuna valutazione finora
- UT Dallas Syllabus For Stat3332.001.09f Taught by Robert Serfling (Serfling)Documento4 pagineUT Dallas Syllabus For Stat3332.001.09f Taught by Robert Serfling (Serfling)UT Dallas Provost's Technology GroupNessuna valutazione finora
- 5/15/14 COMPLAINT FOR VIOLATIONS OF RACKETEER INFLUENCED AND CORRUPT ORGANIZATIONS ACT; VIOLATIONS OF CONSUMER LEGAL REMEDIES ACT; VIOLATIONS OF UNFAIR COMPETITION LAW; VIOLATIONS OF FALSE ADVERTISING LAW; BREACH OF EXPRESS WARRANTY; BREACH OF IMPLIED WARRANTY OF MERCHANTABILITY; BREACH OF IMPLIED WARRANTY OF FITNESS FOR A PARTICULAR PURPOSE; FRAUD; NEGLIGENT MISREPRESENTATION; RESTITUTION; VIOLATIONS OF NY GBL § 349; and VIOLATIONS OF NY GBL § 350, BRIAN O’TOOLE, ROBERT SOKOLOVE, and MICHAEL BITTON, on behalf of themselves and all others similarly situated, Plaintiffs, v. GENCOR NUTRIENTS, INC.; GE NUTRIENTS, INC.; JITH VEERAVALLI; R.V. VENKATESH; GENERAL NUTRITION CORPORATION; GNC CORPORATION; GENERAL NUTRITION CENTERS, INC.; S&G PROPERTIES, LLC; DIRECT DIGITAL LLC; BRANDON ADCOCK; PAUL REICHELT; JOHN KIM; TRUDERMA, LLC; FORCE FACTOR LLC; and DOES 1-10, Defendants, UNITED STATES DISTRICT COURT CENTRAL DISTRICT OF CALIFORNIA WESTERN DIVISIONDocumento75 pagine5/15/14 COMPLAINT FOR VIOLATIONS OF RACKETEER INFLUENCED AND CORRUPT ORGANIZATIONS ACT; VIOLATIONS OF CONSUMER LEGAL REMEDIES ACT; VIOLATIONS OF UNFAIR COMPETITION LAW; VIOLATIONS OF FALSE ADVERTISING LAW; BREACH OF EXPRESS WARRANTY; BREACH OF IMPLIED WARRANTY OF MERCHANTABILITY; BREACH OF IMPLIED WARRANTY OF FITNESS FOR A PARTICULAR PURPOSE; FRAUD; NEGLIGENT MISREPRESENTATION; RESTITUTION; VIOLATIONS OF NY GBL § 349; and VIOLATIONS OF NY GBL § 350, BRIAN O’TOOLE, ROBERT SOKOLOVE, and MICHAEL BITTON, on behalf of themselves and all others similarly situated, Plaintiffs, v. GENCOR NUTRIENTS, INC.; GE NUTRIENTS, INC.; JITH VEERAVALLI; R.V. VENKATESH; GENERAL NUTRITION CORPORATION; GNC CORPORATION; GENERAL NUTRITION CENTERS, INC.; S&G PROPERTIES, LLC; DIRECT DIGITAL LLC; BRANDON ADCOCK; PAUL REICHELT; JOHN KIM; TRUDERMA, LLC; FORCE FACTOR LLC; and DOES 1-10, Defendants, UNITED STATES DISTRICT COURT CENTRAL DISTRICT OF CALIFORNIA WESTERN DIVISIONPeter M. HeimlichNessuna valutazione finora
- Secondary School Mathematics and Science Matters: Academic Performance For Secondary Students Transitioning Into University Allied Health and Science CoursesDocumento14 pagineSecondary School Mathematics and Science Matters: Academic Performance For Secondary Students Transitioning Into University Allied Health and Science CoursesCherinetNessuna valutazione finora
- Unit 3 - CORRELATION AND REGRESSIONDocumento85 pagineUnit 3 - CORRELATION AND REGRESSIONsaritalodhi636Nessuna valutazione finora
- Understanding Children S Work in Morocco: Report On Child LabourDocumento78 pagineUnderstanding Children S Work in Morocco: Report On Child Labour842janxNessuna valutazione finora
- Analysts' Stock Views and Revision ActionsDocumento18 pagineAnalysts' Stock Views and Revision ActionsBerchadesNessuna valutazione finora
- Conditional ProbabilityDocumento85 pagineConditional ProbabilityRavi Shankar VermaNessuna valutazione finora
- Lec 1 Data Mining IntroductionDocumento71 pagineLec 1 Data Mining Introductionturjo987Nessuna valutazione finora
- Pengaruh Asfiksia Terhadap Ukuran Lingkar Kepala Anak Usia 6 Bulan - 2 Tahun Di Rumah Sakit Umum Provinsi Nusa Tenggara BaratDocumento9 paginePengaruh Asfiksia Terhadap Ukuran Lingkar Kepala Anak Usia 6 Bulan - 2 Tahun Di Rumah Sakit Umum Provinsi Nusa Tenggara Baratmail junkNessuna valutazione finora
- MGMT 222 Ch. IVDocumento30 pagineMGMT 222 Ch. IVzedingel50% (2)
- Andy Field Using SpssDocumento115 pagineAndy Field Using SpssRomer GesmundoNessuna valutazione finora
- SM3315Documento19 pagineSM3315Riky Tri YunardiNessuna valutazione finora
- Glimpses of Fiscal States in Sub-Saharan AfricaDocumento29 pagineGlimpses of Fiscal States in Sub-Saharan Africamick mooreNessuna valutazione finora
- Dwnload Full Empowerment Series Research Methods For Social Work 9Th Edition PDFDocumento42 pagineDwnload Full Empowerment Series Research Methods For Social Work 9Th Edition PDFharold.bell480100% (23)
- Soal Materi 2Documento6 pagineSoal Materi 2Early SacrificeNessuna valutazione finora
- Service and Customer Satisfaction of Nepal Telecom: A Project Work ReportDocumento49 pagineService and Customer Satisfaction of Nepal Telecom: A Project Work ReportMadan DhakalNessuna valutazione finora
- Toward Evidence-Based Medical Statistics. 1 The P Value FallacyDocumento10 pagineToward Evidence-Based Medical Statistics. 1 The P Value FallacyAlexsandra TostaNessuna valutazione finora
- Cluster Analysis: Concepts and Techniques - Chapter 7Documento60 pagineCluster Analysis: Concepts and Techniques - Chapter 7Suchithra SalilanNessuna valutazione finora
- To Run ANOVADocumento2 pagineTo Run ANOVAalohaNessuna valutazione finora
- M11.12SP Iva 1 - NoelDocumento2 pagineM11.12SP Iva 1 - NoelAquino Udtog100% (1)
- Tata MoDocumento24 pagineTata MoSaurabh RanjanNessuna valutazione finora
- Data CleaningDocumento26 pagineData CleaningPrashant deshmukhNessuna valutazione finora
- Lack of Equipments Inside The FBS Room of San Andres School of MasinlocDocumento9 pagineLack of Equipments Inside The FBS Room of San Andres School of MasinlocRolly Abelon75% (12)
- Var, Svar and Svec ModelsDocumento32 pagineVar, Svar and Svec ModelsSamuel Costa PeresNessuna valutazione finora
- Crystal Ball 7.3 UKDocumento40 pagineCrystal Ball 7.3 UKaminmestariNessuna valutazione finora
- Module9-Correlation and Regression (Business)Documento15 pagineModule9-Correlation and Regression (Business)CIELICA BURCANessuna valutazione finora
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDa EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsValutazione: 4.5 su 5 stelle4.5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryDa EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNessuna valutazione finora
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeDa EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeValutazione: 4 su 5 stelle4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Da EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Valutazione: 5 su 5 stelle5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDa EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingValutazione: 4.5 su 5 stelle4.5/5 (21)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Da EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Nessuna valutazione finora
- Calculus Workbook For Dummies with Online PracticeDa EverandCalculus Workbook For Dummies with Online PracticeValutazione: 3.5 su 5 stelle3.5/5 (8)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathDa EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathValutazione: 5 su 5 stelle5/5 (1)
- Mental Math Secrets - How To Be a Human CalculatorDa EverandMental Math Secrets - How To Be a Human CalculatorValutazione: 5 su 5 stelle5/5 (3)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsDa EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsValutazione: 3.5 su 5 stelle3.5/5 (9)
- Magic Multiplication: Discover the Ultimate Formula for Fast MultiplicationDa EverandMagic Multiplication: Discover the Ultimate Formula for Fast MultiplicationNessuna valutazione finora
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldDa EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldValutazione: 3 su 5 stelle3/5 (80)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Da EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Nessuna valutazione finora
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkDa EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkValutazione: 5 su 5 stelle5/5 (1)