Potrebbero piacerti anche
- Graficos EstadisticosDocumento17 pagineGraficos EstadisticosBertaNessuna valutazione finora
- Qué Es Un Gráfico EstadísticoDocumento12 pagineQué Es Un Gráfico EstadísticoLUIS ALFREDO APAZA POMANessuna valutazione finora
- Cómo Creamos Un Gráfico de Velocímetro en ExcelDocumento4 pagineCómo Creamos Un Gráfico de Velocímetro en Excelkopalblanca97Nessuna valutazione finora
- EXCELTOTAL Agrupar FilasDocumento16 pagineEXCELTOTAL Agrupar FilasracpalaciosNessuna valutazione finora
- Hermandez Prieto Teresita Dejesus S1Documento7 pagineHermandez Prieto Teresita Dejesus S1Teresita HernandezNessuna valutazione finora
- Tablas Dinamicas y GraficosDocumento11 pagineTablas Dinamicas y GraficosJohana Ospina GutierrezNessuna valutazione finora
- Métodos de Suavizamiento y Pronóstico para Series de Tiempo - EXCELLDocumento12 pagineMétodos de Suavizamiento y Pronóstico para Series de Tiempo - EXCELLAnonymous eBjkCz0gs100% (1)
- Actividades de Probabilidad y EstadísticaDocumento7 pagineActividades de Probabilidad y EstadísticaFabián CamasNessuna valutazione finora
- Componentes PrincipalesDocumento9 pagineComponentes PrincipalesAnonymous KeU4gphVL5Nessuna valutazione finora
- Guia de Laboratorio 2 GraficosDocumento23 pagineGuia de Laboratorio 2 GraficosProfe JamesNessuna valutazione finora
- Tablas DinamicasDocumento5 pagineTablas DinamicasCatherine CifuentesNessuna valutazione finora
- 5.1 Introducción A PCADocumento16 pagine5.1 Introducción A PCAmyrgeteNessuna valutazione finora
- Trabajo - Gráficos EstadísticosDocumento11 pagineTrabajo - Gráficos EstadísticosJesus BetancourtNessuna valutazione finora
- Estadística DescriptivaDocumento12 pagineEstadística DescriptivaBiann ValdiviaNessuna valutazione finora
- Sintesis 2 Introduccion Al Control de CalidadDocumento17 pagineSintesis 2 Introduccion Al Control de CalidadMARIANAISABEL CONTRERAS ALMONTESNessuna valutazione finora
- 2.8 Analisis de La InformacionDocumento7 pagine2.8 Analisis de La InformacionLUIS ANGEL TORRES REANessuna valutazione finora
- Técnicas de Mejora Continua de CalidadDocumento32 pagineTécnicas de Mejora Continua de CalidadyayoguzmanNessuna valutazione finora
- LodebrunoxdDocumento21 pagineLodebrunoxdluis tellezNessuna valutazione finora
- Análisis Exploratorio de Datos (AED)Documento45 pagineAnálisis Exploratorio de Datos (AED)caligro291Nessuna valutazione finora
- Control Estadístico de Procesos y Sus AplicacionesDocumento12 pagineControl Estadístico de Procesos y Sus AplicacionesRadaylin AdamesNessuna valutazione finora
- Manejo de CubosDocumento17 pagineManejo de CubosIvan Ayala VergelNessuna valutazione finora
- Reporte de Máquina de Aprendizaje No SupervisadoDocumento27 pagineReporte de Máquina de Aprendizaje No Supervisadoluis tellezNessuna valutazione finora
- Diagrama de Caja ReporteDocumento16 pagineDiagrama de Caja ReporteSaid Francisco DuranNessuna valutazione finora
- Lluvia de IdeasDocumento6 pagineLluvia de IdeasAboytes MacoyNessuna valutazione finora
- Una Tabla Dinámica Consiste en El Resumen de Un Conjunto de DatosDocumento9 pagineUna Tabla Dinámica Consiste en El Resumen de Un Conjunto de DatoswguzmanxdNessuna valutazione finora
- Crear Una Tabla Dinámica1Documento4 pagineCrear Una Tabla Dinámica1sarahiNessuna valutazione finora
- Trabajo Colaborativo Matematicas IIDocumento16 pagineTrabajo Colaborativo Matematicas IIJuan David Sanchez VNessuna valutazione finora
- Representación de Datos GráficamenteDocumento10 pagineRepresentación de Datos Gráficamenteliliana ruizNessuna valutazione finora
- Tarea 3 Control y CalidadDocumento10 pagineTarea 3 Control y CalidadYelitza Santana100% (1)
- Tipos de GráficosDocumento34 pagineTipos de GráficosLucas MatiasNessuna valutazione finora
- Pronóstico de Demanda Con Regresión LinealDocumento7 paginePronóstico de Demanda Con Regresión LinealCarlosConstantinoNessuna valutazione finora
- Tablas Dinàmicas y Macros en Excel 2016Documento13 pagineTablas Dinàmicas y Macros en Excel 2016B MIRLEY MARINNessuna valutazione finora
- Diagrama de CajaDocumento27 pagineDiagrama de CajaAmerico Farfan VargasNessuna valutazione finora
- ETB - Semana 4 y 5 CompletasDocumento6 pagineETB - Semana 4 y 5 CompletasLuz Angela Torres50% (2)
- Estadística para NegociosDocumento12 pagineEstadística para NegociosLeonardo LinaresNessuna valutazione finora
- TALLER Ejemplo Práctico Sobre Rangos Tridimensionales y Vínculos de CeldasDocumento11 pagineTALLER Ejemplo Práctico Sobre Rangos Tridimensionales y Vínculos de CeldasFelipe JaimesNessuna valutazione finora
- Entrega 2 - Análisis de MuestrasDocumento15 pagineEntrega 2 - Análisis de MuestrasRocío SolísNessuna valutazione finora
- Tablas DinámicasDocumento10 pagineTablas DinámicasBenitoNessuna valutazione finora
- Meta 2.1 - AguayoBandaEstebanDocumento7 pagineMeta 2.1 - AguayoBandaEstebanEsteban Aguayo BandaNessuna valutazione finora
- Diagrama Caja y BigotesDocumento4 pagineDiagrama Caja y Bigotesbelisario bravoNessuna valutazione finora
- Crear Una Tabla Dinamica en ExcellDocumento9 pagineCrear Una Tabla Dinamica en ExcellMartin MaresNessuna valutazione finora
- Aplicaciones Del Algoritmo Id3Documento8 pagineAplicaciones Del Algoritmo Id3Leyvux StarkNessuna valutazione finora
- Tarea 051Documento3 pagineTarea 051Larisa PshenichnajaNessuna valutazione finora
- Demostracion de GraficaDocumento4 pagineDemostracion de GraficaDonato MamaniNessuna valutazione finora
- Laboratorio n1 - Estadistica InferencialDocumento24 pagineLaboratorio n1 - Estadistica InferencialPaula Mariana MurilloNessuna valutazione finora
- Tarea 3 de Gestion de CalidadDocumento15 pagineTarea 3 de Gestion de CalidadEmmanuel Acevedo HernándezNessuna valutazione finora
- Importancia de La Estadistica en La Ingenieria IndustrialDocumento11 pagineImportancia de La Estadistica en La Ingenieria IndustrialMaverick CepedaNessuna valutazione finora
- Tarea No.1Documento9 pagineTarea No.1Andrea BarillasNessuna valutazione finora
- Funciones DaxDocumento24 pagineFunciones DaxalanNessuna valutazione finora
- Investigacion EspecificacionDocumento4 pagineInvestigacion EspecificacionCHRISTIAN JONATHAN MOREDIA PADILLANessuna valutazione finora
- Tabla DinámicaDocumento5 pagineTabla DinámicaSteph RamosNessuna valutazione finora
- Estadistica Descriptiva GraficosDocumento13 pagineEstadistica Descriptiva Graficosaldo bustosNessuna valutazione finora
- HerramientascalidadDocumento37 pagineHerramientascalidadDani ZamudioNessuna valutazione finora
- Promedio MovilDocumento24 paginePromedio MovilPaola LayaNessuna valutazione finora
- Aplicaciones Estadísticas Descriptiva e InferencialDocumento11 pagineAplicaciones Estadísticas Descriptiva e InferencialKarina Goyes MuñozNessuna valutazione finora
- Tabla DinámicasDocumento6 pagineTabla DinámicasZahiry SerranoNessuna valutazione finora
- Grafico de ControlDocumento7 pagineGrafico de ControlEduardo LinganNessuna valutazione finora
- Tema 2Documento14 pagineTema 2Ivan Gutierrez GarciaNessuna valutazione finora
- Pasos para Construir Una Tabla de FrecuenciasDocumento23 paginePasos para Construir Una Tabla de FrecuenciasLuis Fernando Castañeda PulidoNessuna valutazione finora
- 4.-Manual de Aplicacion de EncodersDocumento21 pagine4.-Manual de Aplicacion de EncodersCrimson King LinaresNessuna valutazione finora
- Kindergarten de Diseño de ControladoresDocumento19 pagineKindergarten de Diseño de ControladoresAlfonso Peralta DíazNessuna valutazione finora
- 1ra Practica de EP 2019 BDocumento3 pagine1ra Practica de EP 2019 BFernando Taipe'xNessuna valutazione finora
- PDF Solucion1Documento3 paginePDF Solucion1Fernando Taipe'xNessuna valutazione finora
- Catalogo de Contactores de Abb PDFDocumento58 pagineCatalogo de Contactores de Abb PDFFernando Taipe'xNessuna valutazione finora
- Compensador Estatico de VarrasDocumento20 pagineCompensador Estatico de VarrasJulio Vivar GonzalezNessuna valutazione finora
- Ocw - Uc3m TC S3 PDFDocumento8 pagineOcw - Uc3m TC S3 PDFFran MorenoNessuna valutazione finora
- 2 13 PDFDocumento3 pagine2 13 PDFFernando Taipe'xNessuna valutazione finora
- Metodo de NewtonDocumento2 pagineMetodo de NewtonFernando Taipe'xNessuna valutazione finora
- Método de GaussDocumento1 paginaMétodo de GaussFernando Taipe'xNessuna valutazione finora
- Laboratorio de Electronica BasicaDocumento25 pagineLaboratorio de Electronica BasicaJheddy TorrezNessuna valutazione finora
- Método de GaussDocumento1 paginaMétodo de GaussFernando Taipe'xNessuna valutazione finora
- Metodo de NewtonDocumento2 pagineMetodo de NewtonFernando Taipe'xNessuna valutazione finora
- AsipoDocumento3 pagineAsipoFernando Taipe'xNessuna valutazione finora
- Laboratorio 01 - Introducción Al MATLAB y Fuentes de InformaciónDocumento12 pagineLaboratorio 01 - Introducción Al MATLAB y Fuentes de InformaciónFernando Taipe'xNessuna valutazione finora
- Newton RapsonDocumento4 pagineNewton RapsonFernando Taipe'xNessuna valutazione finora
- Contenido TIFDocumento7 pagineContenido TIFFernando Taipe'xNessuna valutazione finora
- Volta Jes y CorrientesDocumento6 pagineVolta Jes y CorrientesFernando Taipe'xNessuna valutazione finora
- Lab 05 - SistDigitalesDocumento14 pagineLab 05 - SistDigitalesFernando Taipe'xNessuna valutazione finora
- Laboratorio 3 Control IDocumento23 pagineLaboratorio 3 Control IFernando Taipe'xNessuna valutazione finora
- Guia 01 NuevoDocumento3 pagineGuia 01 NuevoSamed Maraza JaliriNessuna valutazione finora
- G3 Laboratorios de Circuitos Eléctricos2Documento6 pagineG3 Laboratorios de Circuitos Eléctricos2Fernando Taipe'xNessuna valutazione finora
- Compensadores Estáticos de Potencia Reactiva (SVC)Documento27 pagineCompensadores Estáticos de Potencia Reactiva (SVC)bahamut518Nessuna valutazione finora
- Lab de Digitales (1-4)Documento22 pagineLab de Digitales (1-4)Fernando Taipe'xNessuna valutazione finora
- Proyecto Lab Control 2Documento19 pagineProyecto Lab Control 2Fernando Taipe'xNessuna valutazione finora
- Modulacion DigitalDocumento18 pagineModulacion DigitalAndrés MartinezNessuna valutazione finora
- Circuitos de Corriente AlternaDocumento6 pagineCircuitos de Corriente AlternaManuel FernizaNessuna valutazione finora
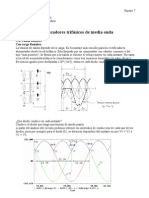
- Rectificadores Trifásicos de Media OndaDocumento6 pagineRectificadores Trifásicos de Media OndaAlx González0% (2)
- Labcitro2 GananciaDocumento5 pagineLabcitro2 GananciaFernando Taipe'xNessuna valutazione finora
- Proyecto Lab Control 2Documento19 pagineProyecto Lab Control 2Fernando Taipe'xNessuna valutazione finora
- CABLEDUCTOSDocumento13 pagineCABLEDUCTOSMilton CarrilloNessuna valutazione finora
- Modelo de Informe Etapa Productiva 2020Documento5 pagineModelo de Informe Etapa Productiva 2020STEVEN ANDRES NAVARRO ESTRADANessuna valutazione finora
- Lab SuelosDocumento15 pagineLab SuelosLeandro VasquezNessuna valutazione finora
- Eduardo Rios y Asociados SacDocumento1 paginaEduardo Rios y Asociados SacJuanGabrielFarfanYoveraNessuna valutazione finora
- ELINCADocumento20 pagineELINCAClaudioNessuna valutazione finora
- Trabajo Simulación 2Documento10 pagineTrabajo Simulación 2Camilo Chica VargasNessuna valutazione finora
- Gaucho 2Documento48 pagineGaucho 2ciccio belloNessuna valutazione finora
- Registros ContablesDocumento3 pagineRegistros ContablesMelany AlfaroNessuna valutazione finora
- Logica Predicados V1Documento46 pagineLogica Predicados V1Ricardo CisnerosNessuna valutazione finora
- Guia Reparacion de Motores de Combustion InternaDocumento58 pagineGuia Reparacion de Motores de Combustion InternaAlfredo Quispe Alvaro0% (1)
- TOBERADocumento11 pagineTOBERAcristhiahnoNessuna valutazione finora
- Aspectos Relevantes Ley 20 886Documento8 pagineAspectos Relevantes Ley 20 886Maria Jose Diaz TapiaNessuna valutazione finora
- Ubs Arrastre Hidraulico MetradoDocumento44 pagineUbs Arrastre Hidraulico MetradoSamira Villanueva DavilaNessuna valutazione finora
- INDG1004 P2-E2 Investigación de OperacionesDocumento6 pagineINDG1004 P2-E2 Investigación de OperacionesMelanie Medina SantamaríaNessuna valutazione finora
- Los Cinco Pilares Del Complejo Industrial Militar de Estados UnidosDocumento5 pagineLos Cinco Pilares Del Complejo Industrial Militar de Estados UnidosEdgar Alexander Esteves MillánNessuna valutazione finora
- Instructivo Instalacion Plantas Energy StoreDocumento3 pagineInstructivo Instalacion Plantas Energy StorePacho SantacruzNessuna valutazione finora
- Metodologia IconixDocumento5 pagineMetodologia IconixPabloYepezNessuna valutazione finora
- Curso Bell 212Documento66 pagineCurso Bell 212EDDIER EDUARDO ROJAS GALVIS75% (4)
- El Convenio de KyotoDocumento4 pagineEl Convenio de KyotoNicolMiaNessuna valutazione finora
- Normativa para La Infraestructura Del TransporteDocumento2 pagineNormativa para La Infraestructura Del TransporteDavid BarzalobreNessuna valutazione finora
- La Relación de MayerDocumento11 pagineLa Relación de MayerAnonymous wH8gUfAFnNessuna valutazione finora
- Resumen Sobre La Norma de Buenas Practicas de LaboratorioDocumento5 pagineResumen Sobre La Norma de Buenas Practicas de LaboratorioDavid SanabriaNessuna valutazione finora
- Campo UnificadoDocumento50 pagineCampo UnificadoCandy ElizabethNessuna valutazione finora
- TP 1 WindowsDocumento20 pagineTP 1 WindowsGeorginaPennella0% (1)
- Plan de Administracion Del Proyecto PDFDocumento5 paginePlan de Administracion Del Proyecto PDFLuisNessuna valutazione finora
- Deli ZiaDocumento6 pagineDeli ZiaWilberth RamosNessuna valutazione finora
- Tarifario Publicitario Clarín Online 2017Documento20 pagineTarifario Publicitario Clarín Online 2017VictoriaNessuna valutazione finora
- Recomendaciones para Estimular El LenguajeDocumento6 pagineRecomendaciones para Estimular El LenguajeBastian Alexander Rodríguez MarifilNessuna valutazione finora
- Tema 3 PDFDocumento72 pagineTema 3 PDFSamuu2420100% (1)
- Semana 13 - Capítulo 10 - Lectura - Norma ISO 9001 - 2015Documento2 pagineSemana 13 - Capítulo 10 - Lectura - Norma ISO 9001 - 2015UnknownConNessuna valutazione finora