Potrebbero piacerti anche
- Scientific Method PDFDocumento1 paginaScientific Method PDFBillones Rebalde MarnelleNessuna valutazione finora
- Lab Manual Ebt 251Documento29 pagineLab Manual Ebt 251Ahmad Helmi AdnanNessuna valutazione finora
- Silabo de Biotecnología Ambiental EspochDocumento15 pagineSilabo de Biotecnología Ambiental EspochIsrael José MendozaNessuna valutazione finora
- Deskriptor AlpukatDocumento58 pagineDeskriptor AlpukattinNessuna valutazione finora
- Transgenicplants PPT 170509172214 PDFDocumento31 pagineTransgenicplants PPT 170509172214 PDFKishore KaranNessuna valutazione finora
- Plasmids ReplicationDocumento6 paginePlasmids ReplicationRaquel VieiraNessuna valutazione finora
- Course Syllabus: Georgetownx Medx202 - 01: Genomic Medicine Gets PersonalDocumento21 pagineCourse Syllabus: Georgetownx Medx202 - 01: Genomic Medicine Gets PersonalAlfonso Estrada100% (1)
- CLADOGRAM Practice ProblemsDocumento2 pagineCLADOGRAM Practice ProblemsBraden CooperNessuna valutazione finora
- Trevine Et Al. 2022 - New Combination TachymeniniDocumento21 pagineTrevine Et Al. 2022 - New Combination TachymeniniTito BarrosNessuna valutazione finora
- Analisis Economico de Explotacion Apicola en ChileDocumento10 pagineAnalisis Economico de Explotacion Apicola en ChileMauricio NúñezNessuna valutazione finora
- Olympic Inquiry HomeworkDocumento5 pagineOlympic Inquiry HomeworkMrStuDevNessuna valutazione finora
- Compilation of Soil and Sediment Standards Criteria and Guidelines. February 1995Documento77 pagineCompilation of Soil and Sediment Standards Criteria and Guidelines. February 1995Gonzalo RosadoNessuna valutazione finora
- FERMENTAS Thermo-Scientific-Molecular-Biology-Workflow-Solutions-Brochure PDFDocumento12 pagineFERMENTAS Thermo-Scientific-Molecular-Biology-Workflow-Solutions-Brochure PDFCarlos Arturo OsorioNessuna valutazione finora
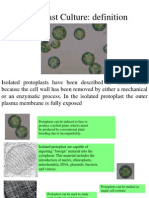
- Protoplast Culture: Isolated Plant Cells Without Cell WallsDocumento20 pagineProtoplast Culture: Isolated Plant Cells Without Cell WallsSivamani SelvarajuNessuna valutazione finora
- Domestic Cooking Methods Affect The Nutritional Quality of Red CabbageDocumento6 pagineDomestic Cooking Methods Affect The Nutritional Quality of Red CabbageAndrea Osorio AlturoNessuna valutazione finora
- Metabolic Engineering To Improve Bioactive Secondary MetabolitesDocumento14 pagineMetabolic Engineering To Improve Bioactive Secondary MetabolitesBOTANY DEPARTMENTNessuna valutazione finora
- Mcintyre - Habitat Variegation, An Alternative To Fragmentation PDFDocumento3 pagineMcintyre - Habitat Variegation, An Alternative To Fragmentation PDFivanNessuna valutazione finora
- Bio Tools BookletDocumento5 pagineBio Tools BookletTanvi GargNessuna valutazione finora
- Exercises For Phylogeny: Exercise 1. Parsimony and Rooted Versus Unrooted TreesDocumento11 pagineExercises For Phylogeny: Exercise 1. Parsimony and Rooted Versus Unrooted TreesNeeru RedhuNessuna valutazione finora
- The Ensembl Xref System: Table Name PurposeDocumento9 pagineThe Ensembl Xref System: Table Name PurposeBharatbioinormaticshauNessuna valutazione finora
- Linux Bootcamp ExercisesDocumento9 pagineLinux Bootcamp ExercisesAnonymous O35Go0G4mhNessuna valutazione finora
- UNIX BASICS - Beginners Guide For Unix Commands - by MeenakshiDocumento7 pagineUNIX BASICS - Beginners Guide For Unix Commands - by Meenakshipravin216Nessuna valutazione finora
- 16S Metagenomic Analysis TutorialDocumento9 pagine16S Metagenomic Analysis TutorialJack SimNessuna valutazione finora
- BeaglingDocumento39 pagineBeaglingEstebanNessuna valutazione finora
- Introduction To Unix-And-Linux-Redirecting-Output-And-Finding-FilesDocumento12 pagineIntroduction To Unix-And-Linux-Redirecting-Output-And-Finding-FilesChristopher InclanNessuna valutazione finora
- A Brief Tutorial On Maxent: by Steven J. Phillips, AT&T ResearchDocumento40 pagineA Brief Tutorial On Maxent: by Steven J. Phillips, AT&T ResearchsatucitaNessuna valutazione finora
- Basic of UnixDocumento5 pagineBasic of UnixAbhishek kapoorNessuna valutazione finora
- Red Triangle: in The Upper-Right Corner Have Pop-Up Instructions That Can Be Displayed If You Hover Over The FieldDocumento10 pagineRed Triangle: in The Upper-Right Corner Have Pop-Up Instructions That Can Be Displayed If You Hover Over The FieldZhang ChengNessuna valutazione finora
- CS 100 Lab Five - Fall 2019: ./a.out ./a.out 99 55.5 11 - 6.5 600.35 32.7Documento1 paginaCS 100 Lab Five - Fall 2019: ./a.out ./a.out 99 55.5 11 - 6.5 600.35 32.7Muhammad MusaNessuna valutazione finora
- UnixDocumento1 paginaUnixMukesh KumarNessuna valutazione finora
- Aggregates: Studying The Aggregation of Molecules in Trajectories of Molecular DynamicsDocumento11 pagineAggregates: Studying The Aggregation of Molecules in Trajectories of Molecular DynamicschuneshphysicsNessuna valutazione finora
- Repeatanalyzer Quickstart Guide: Direct Download (Recommended)Documento17 pagineRepeatanalyzer Quickstart Guide: Direct Download (Recommended)Cristal VillalbaNessuna valutazione finora
- Table and Field Name Overwrites XML File PDFDocumento6 pagineTable and Field Name Overwrites XML File PDFla_civilNessuna valutazione finora
- System Call Function: System Calls Can Fail in Many Ways. For ExampleDocumento6 pagineSystem Call Function: System Calls Can Fail in Many Ways. For Exampleani_nambiNessuna valutazione finora
- Quantitative Clad Is TicsDocumento49 pagineQuantitative Clad Is Ticspuzzledeciencia100% (1)
- Erlang - Parsetools-1.4Documento16 pagineErlang - Parsetools-1.4rodrigoNessuna valutazione finora
- Phylogenetic Comparative Methods in R Using Phylogeny As A Statistical FixDocumento22 paginePhylogenetic Comparative Methods in R Using Phylogeny As A Statistical FixSara Gamboa JuradoNessuna valutazione finora
- Handout 3Documento7 pagineHandout 3Mon LucyNessuna valutazione finora
- Obfuscator User Guide: Capabilities & LimitationsDocumento2 pagineObfuscator User Guide: Capabilities & LimitationsSulimin NgNessuna valutazione finora
- Project 4 InstructionsDocumento6 pagineProject 4 InstructionsJohnNessuna valutazione finora
- A Brief Tutorial On Maxent: Getting StartedDocumento39 pagineA Brief Tutorial On Maxent: Getting StartedGuilherme DemetrioNessuna valutazione finora
- Phylogenetic Tree Lab (FASTA)Documento8 paginePhylogenetic Tree Lab (FASTA)cupoguNessuna valutazione finora
- Laboratory Exercise 6Documento9 pagineLaboratory Exercise 6Energy AntelopeNessuna valutazione finora
- 5139 Phillips Brief Tutorial On MaxentDocumento29 pagine5139 Phillips Brief Tutorial On MaxentSilvana ArosaNessuna valutazione finora
- 6Documento26 pagine6khitiNessuna valutazione finora
- Essential Unix commands explainedDocumento33 pagineEssential Unix commands explainedAmitava SarderNessuna valutazione finora
- Finite Element Analysis With Error EstimatorsDocumento2 pagineFinite Element Analysis With Error EstimatorsAlexShearNessuna valutazione finora
- Abacus ManualDocumento11 pagineAbacus ManualVaishnav KunalNessuna valutazione finora
- Files in Folders and SubfoldersDocumento6 pagineFiles in Folders and SubfoldersYamini ShindeNessuna valutazione finora
- Concurrent Request ORA-20100 Errors in The Request LogsDocumento3 pagineConcurrent Request ORA-20100 Errors in The Request Logsnagarajuvcc123Nessuna valutazione finora
- Species Distribution Modeling With RDocumento79 pagineSpecies Distribution Modeling With RopulitheNessuna valutazione finora
- Exercise 1.listing Files and Directories: Command Meaning Ls Ls - A Mkdir CD Directory CD CD CD .Documento11 pagineExercise 1.listing Files and Directories: Command Meaning Ls Ls - A Mkdir CD Directory CD CD CD .uvs sahuNessuna valutazione finora
- 1 Motivation: Setting Up To Use PstoneDocumento9 pagine1 Motivation: Setting Up To Use PstoneSwathi PatibandlaNessuna valutazione finora
- Step by Step Use of UnloadAZK and Analyze Tools in DMDXDocumento8 pagineStep by Step Use of UnloadAZK and Analyze Tools in DMDXama267Nessuna valutazione finora
- Linux Interview Questions and AnswersDocumento11 pagineLinux Interview Questions and Answersdillip21100% (1)
- Using Repeatmasker To Identify Repetitive Elements in Genomic SequencesDocumento14 pagineUsing Repeatmasker To Identify Repetitive Elements in Genomic SequencesslimcharliNessuna valutazione finora
- Structure Calculations With XplorDocumento7 pagineStructure Calculations With XplorShantanu S BhattacharyyaNessuna valutazione finora
- Clarke & Gorley - 2015 - Getting Started Primer V7Documento20 pagineClarke & Gorley - 2015 - Getting Started Primer V7Prabowo BudiNessuna valutazione finora
- Table and Field Name Overwrites XML FileDocumento7 pagineTable and Field Name Overwrites XML FileHaytham ZaghloulNessuna valutazione finora
- Table and Field Name Overwrites XML FileDocumento7 pagineTable and Field Name Overwrites XML FileNguyen Co ThachNessuna valutazione finora
- Management Information SystemDocumento27 pagineManagement Information SystemOscarNessuna valutazione finora
- PV2HVMDocumento1 paginaPV2HVMfaabbasNessuna valutazione finora
- General ConceptsDocumento67 pagineGeneral ConceptsSergio LageNessuna valutazione finora
- Software Engineering:: 3. MethodologyDocumento39 pagineSoftware Engineering:: 3. MethodologyShafrizaNessuna valutazione finora
- E-Commerce Systems Analysis and DesignDocumento5 pagineE-Commerce Systems Analysis and DesignRuchi Anish PatelNessuna valutazione finora
- Types of CryptographyDocumento11 pagineTypes of CryptographyBridget Smith92% (12)
- Remote Monitoring On Capacity of Portable Power Bank in Testing LaboratoriesDocumento6 pagineRemote Monitoring On Capacity of Portable Power Bank in Testing LaboratoriesTatiana RizNessuna valutazione finora
- IBM I2 Analyst'S Notebook: Financial AnalysisDocumento4 pagineIBM I2 Analyst'S Notebook: Financial AnalysisIvana HorvatNessuna valutazione finora
- Addressing Roi in Internet of Things Solutions White PaperDocumento14 pagineAddressing Roi in Internet of Things Solutions White PaperDIpakNessuna valutazione finora
- 3dconnexion - SpaceMouse EnterpriseDocumento15 pagine3dconnexion - SpaceMouse EnterpriseWandersonNessuna valutazione finora
- Thread GroupDocumento11 pagineThread GroupMayank MishraNessuna valutazione finora
- Using System Class Name (Public Static Void Main (Console - Writeline ("My Name Is Sujit") ) )Documento26 pagineUsing System Class Name (Public Static Void Main (Console - Writeline ("My Name Is Sujit") ) )Sunil KumarNessuna valutazione finora
- Why you should use ACTIVE mode in DC++ for better downloadsDocumento3 pagineWhy you should use ACTIVE mode in DC++ for better downloadsAyushmaanNessuna valutazione finora
- Microsoft Workloads in AWSDocumento250 pagineMicrosoft Workloads in AWSmajd natour100% (1)
- Java programs to check number propertiesDocumento4 pagineJava programs to check number propertiesSonali SidanaNessuna valutazione finora
- CTF - DC1 - Lab FileDocumento11 pagineCTF - DC1 - Lab Filecyber mediaNessuna valutazione finora
- Data Retention Rules For Oracle BackupsDocumento5 pagineData Retention Rules For Oracle BackupsVignesh BabuNessuna valutazione finora
- Microfluidics For Healthcare ApplicationsDocumento60 pagineMicrofluidics For Healthcare ApplicationsThoriq salafi100% (1)
- 222 H 754 W ApplicationDocumento2 pagine222 H 754 W ApplicationkhushalyadavNessuna valutazione finora
- SPM ReportDocumento12 pagineSPM ReportSamit ShresthaNessuna valutazione finora
- ZXLTOU13Documento8 pagineZXLTOU13Magesh WaranNessuna valutazione finora
- SGE Cheat Sheet PDFDocumento5 pagineSGE Cheat Sheet PDFKeerati ManeesaiNessuna valutazione finora
- Sqoop Export and Import CommandsDocumento5 pagineSqoop Export and Import CommandsSunny RajpalNessuna valutazione finora
- Digital Twin-Based Monitoring System of Induction Motors Using IoT Sensors and Thermo-Magnetic Finite Element AnalysisDocumento12 pagineDigital Twin-Based Monitoring System of Induction Motors Using IoT Sensors and Thermo-Magnetic Finite Element AnalysisMr. INVINCIBLENessuna valutazione finora
- BGA Rework Station User Manual: Downloaded From Manuals Search EngineDocumento20 pagineBGA Rework Station User Manual: Downloaded From Manuals Search EngineSlaven VlacicNessuna valutazione finora
- Python ResponderDocumento37 paginePython Responderadhi_narenNessuna valutazione finora
- Install Active Directory ObjectsDocumento12 pagineInstall Active Directory ObjectsRosalina Arapan OrenzoNessuna valutazione finora
- Warez News Magazine 01 03Documento115 pagineWarez News Magazine 01 03Colcrock ANessuna valutazione finora
- Signaling Server: Installation and ConfigurationDocumento118 pagineSignaling Server: Installation and Configurationwanriz1971Nessuna valutazione finora
- PySpark Data Frame Questions PDFDocumento57 paginePySpark Data Frame Questions PDFVarun Pathak100% (1)