Potrebbero piacerti anche
- Taller XAMPPDocumento21 pagineTaller XAMPPdianacbermudezNessuna valutazione finora
- Im 1 3 694200997 In1 121 152Documento32 pagineIm 1 3 694200997 In1 121 152Joaquín Enrique MenanteauNessuna valutazione finora
- Citacion Eviccion PDFDocumento3 pagineCitacion Eviccion PDFidiazmNessuna valutazione finora
- Tarea Dia 3Documento2 pagineTarea Dia 3idiazmNessuna valutazione finora
- Codigo PenalDocumento351 pagineCodigo PenalDanny QuezadaNessuna valutazione finora
- Ley Ricarte PDFDocumento20 pagineLey Ricarte PDFidiazmNessuna valutazione finora
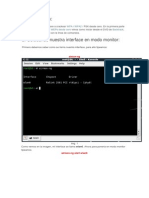
- Crackear Wpa Wpa2 PSKDocumento8 pagineCrackear Wpa Wpa2 PSKp3p17oNessuna valutazione finora
- Gerencia de PersonalDocumento18 pagineGerencia de PersonalVania Vannessa Barrientos SalasNessuna valutazione finora
- Tema 6-1Documento15 pagineTema 6-1idiazmNessuna valutazione finora
- Bases anatómicas del lenguajeDocumento170 pagineBases anatómicas del lenguajeidiazmNessuna valutazione finora
- Calidad en Recursos HumanosDocumento30 pagineCalidad en Recursos HumanosCarmen Rangel RodriguezNessuna valutazione finora
- Análisis Técnico Bolsa ValoresDocumento3 pagineAnálisis Técnico Bolsa ValoresidiazmNessuna valutazione finora
- Diseno y Evaluacion de Un Modelo de Control de OperacionesDocumento139 pagineDiseno y Evaluacion de Un Modelo de Control de OperacionesidiazmNessuna valutazione finora
- Antropología Socio - CulturalDocumento154 pagineAntropología Socio - Culturalidiazm100% (1)
- Analisis Tecnico y FundamentalDocumento44 pagineAnalisis Tecnico y FundamentalMoana Atan100% (1)
- Unidad 1 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)Documento24 pagineUnidad 1 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)idiazmNessuna valutazione finora
- Fundamentos de la Contabilidad PúblicaDocumento85 pagineFundamentos de la Contabilidad PúblicaidiazmNessuna valutazione finora
- Examen Chartismo - Mayo 2017Documento3 pagineExamen Chartismo - Mayo 2017idiazm100% (1)
- Modulo 3 Apuntes Del Curso Implementación de Las NICSP 2017Documento20 pagineModulo 3 Apuntes Del Curso Implementación de Las NICSP 2017idiazmNessuna valutazione finora
- Clasificador PresupuestarioDocumento49 pagineClasificador PresupuestarioidiazmNessuna valutazione finora
- Catalogo de Cuentas Auditoria GubernamentalDocumento175 pagineCatalogo de Cuentas Auditoria GubernamentalSebastian MilanNessuna valutazione finora
- Análisis Técnico Bolsa ValoresDocumento3 pagineAnálisis Técnico Bolsa ValoresidiazmNessuna valutazione finora
- Unidad 1 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)Documento24 pagineUnidad 1 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)idiazmNessuna valutazione finora
- Normativa Nicsp PDFDocumento254 pagineNormativa Nicsp PDFlgba2000Nessuna valutazione finora
- Unidad 2 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)Documento23 pagineUnidad 2 - Chartismo, Análisis Técnico - V1 (UNAB-IEDE)idiazmNessuna valutazione finora
- Auditoria PracticaDocumento495 pagineAuditoria PracticapaperaltNessuna valutazione finora
- Programacion Basica VBDocumento157 pagineProgramacion Basica VBArturo Acoltzi CuatecontziNessuna valutazione finora
- Examen Chartismo - Mayo 2017Documento3 pagineExamen Chartismo - Mayo 2017idiazm100% (1)
- Pastillas anticonceptivas de emergencia guíaDocumento5 paginePastillas anticonceptivas de emergencia guíaJuliana Larrotta TorresNessuna valutazione finora
- Litiasis BiliarDocumento2 pagineLitiasis BiliarEsmeralda AlvarezNessuna valutazione finora
- Problemas Resueltos Nodos1Documento21 pagineProblemas Resueltos Nodos1Jose M Figueroa De la CruzNessuna valutazione finora
- Triptico PapaDocumento2 pagineTriptico PapaNaya Blas AlfaroNessuna valutazione finora
- Catálogo de MaquetasDocumento135 pagineCatálogo de MaquetasJuan José Reque100% (1)
- Kit video portero hogar IP y analógoDocumento5 pagineKit video portero hogar IP y analógoWallace PovisNessuna valutazione finora
- CONOCIMIENTO CULTURA Existen Dos Tipos de Conocimiento Sobre Las Culturas - para Mi Amor KarenDocumento10 pagineCONOCIMIENTO CULTURA Existen Dos Tipos de Conocimiento Sobre Las Culturas - para Mi Amor KarenAntonio ZamoranoNessuna valutazione finora
- Como Elegir ScadaDocumento2 pagineComo Elegir ScadaFranklin Lorenzo castilloNessuna valutazione finora
- Presentación 15Documento17 paginePresentación 15Liz GarcíaNessuna valutazione finora
- Diapositivas de Los FuturosDocumento6 pagineDiapositivas de Los FuturosberthaNessuna valutazione finora
- Cálculo Dif e Int. I - UNAM - 2022Documento6 pagineCálculo Dif e Int. I - UNAM - 2022emilioNessuna valutazione finora
- Tercera Práctica Calificada FS IIDocumento2 pagineTercera Práctica Calificada FS IIJhon EspinozaNessuna valutazione finora
- Mapa Conceptual Hueso FrontalDocumento1 paginaMapa Conceptual Hueso Frontaldarleene.veraNessuna valutazione finora
- ReseñaDocumento6 pagineReseñajoseantonioaar0% (1)
- Grisel Martinez Segunda Evaluacion MapasDocumento2 pagineGrisel Martinez Segunda Evaluacion MapasCarol MartzNessuna valutazione finora
- ¿Por Qué Las Mujeres Pueden Ponerse Ropa de Hombre Pero Los Hombres No Pueden Hacer Lo Mismo Sin Parecer Ridículos - QuoraDocumento1 pagina¿Por Qué Las Mujeres Pueden Ponerse Ropa de Hombre Pero Los Hombres No Pueden Hacer Lo Mismo Sin Parecer Ridículos - QuoraMiguel GarciaNessuna valutazione finora
- Taller Presupuestos de Gastos Operacionales Y No OperacionalesDocumento3 pagineTaller Presupuestos de Gastos Operacionales Y No OperacionalesWilliam de Jesus Quintero DiazNessuna valutazione finora
- Provincias Metalogenéticas Del PeruDocumento10 pagineProvincias Metalogenéticas Del PeruKennedy Medina LopezNessuna valutazione finora
- Solucionario de Laboratorio de Microbiologia - SeguridadDocumento3 pagineSolucionario de Laboratorio de Microbiologia - Seguridadjaime0% (1)
- Mirtha Rugel - Psicología y Comportamiento - S2Documento25 pagineMirtha Rugel - Psicología y Comportamiento - S2FrankNessuna valutazione finora
- Guía de ejercicios de rapidez y velocidadDocumento3 pagineGuía de ejercicios de rapidez y velocidadMoisés InostrozaNessuna valutazione finora
- T2 ErroresDocumento2 pagineT2 ErroresJesus Resta NavarroNessuna valutazione finora
- ATI4-S20-Competencias SocioemocionalesDocumento5 pagineATI4-S20-Competencias SocioemocionalesEdith Marleni Quispe ContrerasNessuna valutazione finora
- Plan de Saneamiento BasicoDocumento13 paginePlan de Saneamiento BasicoKrystyn MarielNessuna valutazione finora
- Signos de Riesgo y Detección Precoz de Psicosis (Psicología) (Spanish Edition) by Jordi E. ObiolsNeus (Coords.) Barrantes-VidalDocumento249 pagineSignos de Riesgo y Detección Precoz de Psicosis (Psicología) (Spanish Edition) by Jordi E. ObiolsNeus (Coords.) Barrantes-VidalGonzalo RojasNessuna valutazione finora
- Tecnologia Mineralurgica ProgramaDocumento3 pagineTecnologia Mineralurgica ProgramaVB JazminNessuna valutazione finora
- Diseño de Un DesarenadorDocumento14 pagineDiseño de Un DesarenadorAdder Juipa PozoNessuna valutazione finora
- Modulo 2-02 Nov - Ley 30364Documento139 pagineModulo 2-02 Nov - Ley 30364Kliver Jefferson Criollo CornejoNessuna valutazione finora
- EA-Unidad 1Documento33 pagineEA-Unidad 1LADY CAROLINA BETANCUR CÁRCAMONessuna valutazione finora
- Pardeamiento No EnzimaticoDocumento16 paginePardeamiento No EnzimaticoJackelin MarzanoNessuna valutazione finora