Potrebbero piacerti anche
- Cheat SheetDocumento2 pagineCheat SheetHarry HarryNessuna valutazione finora
- Normalization Questions With AnswersDocumento6 pagineNormalization Questions With Answerspoker83% (29)
- Relations and FunctionsDocumento6 pagineRelations and FunctionsTalveda Shreya100% (1)
- (F G) (X) F (X) G (X) : Remember!!!Documento1 pagina(F G) (X) F (X) G (X) : Remember!!!Alfred IntongNessuna valutazione finora
- Functional Dependencies and Normalization4Documento86 pagineFunctional Dependencies and Normalization4AbuBakar SohailNessuna valutazione finora
- Chapter-02: Relations and Functions: Basic ConceptsDocumento12 pagineChapter-02: Relations and Functions: Basic ConceptsAbduk100% (1)
- English Action Plan 2023-2024Documento5 pagineEnglish Action Plan 2023-2024Gina DaligdigNessuna valutazione finora
- Relational Database DesignDocumento76 pagineRelational Database Designpranay639Nessuna valutazione finora
- A Research Paper On DormitoriesDocumento5 pagineA Research Paper On DormitoriesNicholas Ivy EscaloNessuna valutazione finora
- 01 Gyramatic-Operator Manual V2-4-1Documento30 pagine01 Gyramatic-Operator Manual V2-4-1gytoman100% (2)
- Data Bases CheatsheetDocumento2 pagineData Bases CheatsheetLucas GonzalezNessuna valutazione finora
- (Fanuc Lad 0I-Mc) Ladder Diagram 1Documento160 pagine(Fanuc Lad 0I-Mc) Ladder Diagram 1Ujang NachrawiNessuna valutazione finora
- Jastram Rudder Feedback UnitDocumento21 pagineJastram Rudder Feedback UnitGary Gouveia100% (3)
- GS Ep Tec 260 enDocumento61 pagineGS Ep Tec 260 enCesarNessuna valutazione finora
- CS2102 - Cheat SheetDocumento3 pagineCS2102 - Cheat SheetNagi TejaNessuna valutazione finora
- FD Slide2 09Documento19 pagineFD Slide2 09Sathis Kumar KathiresanNessuna valutazione finora
- Chapter 3Documento80 pagineChapter 3Đức NguyênNessuna valutazione finora
- Uni IiiDocumento17 pagineUni IiiGOVINDAN MNessuna valutazione finora
- 5.1 - Chapter 3 - Functional DependenciesDocumento34 pagine5.1 - Chapter 3 - Functional DependenciesPhạm Nhựt HàoNessuna valutazione finora
- Relational Database Design Functional DependenciesDocumento27 pagineRelational Database Design Functional DependenciesAshutosh TiwariNessuna valutazione finora
- CLass 12 - Relations and Functions - Shivani SharmaDocumento101 pagineCLass 12 - Relations and Functions - Shivani SharmaAmina sabu06Nessuna valutazione finora
- Saikeerthi - GT - Lecture 2Documento4 pagineSaikeerthi - GT - Lecture 220saikeerthiNessuna valutazione finora
- 1.2. Relational ModelDocumento22 pagine1.2. Relational ModelragulNessuna valutazione finora
- 2 Relational Model Part 1of3Documento24 pagine2 Relational Model Part 1of3co22352Nessuna valutazione finora
- 5 - Chapter 3 - Functional DependenciesDocumento26 pagine5 - Chapter 3 - Functional DependenciesQuang SọtNessuna valutazione finora
- EE5121: Convex Optimization: Assignment 1Documento2 pagineEE5121: Convex Optimization: Assignment 1elleshNessuna valutazione finora
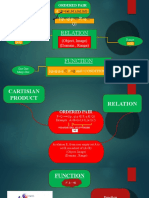
- Relations and Functions: Cartesian ProductDocumento5 pagineRelations and Functions: Cartesian ProductDave Jedidiah TibaldoNessuna valutazione finora
- Travers A LsDocumento16 pagineTravers A LsΓιάννης ΣτεργίουNessuna valutazione finora
- Design Theory For Relational DatabasesDocumento73 pagineDesign Theory For Relational DatabasesLương Hồng PhúcNessuna valutazione finora
- 4 Database Management SystemsDocumento4 pagine4 Database Management Systemsjp techNessuna valutazione finora
- ER Diagrams (Concluded), Schema Refinement, and NormalizationDocumento39 pagineER Diagrams (Concluded), Schema Refinement, and NormalizationagrawalamitkumarNessuna valutazione finora
- Relational Database Design Functional DependenciesDocumento21 pagineRelational Database Design Functional DependenciesayushsrivastavaNessuna valutazione finora
- Lossless Decomposition Anannya SenguptaDocumento27 pagineLossless Decomposition Anannya SenguptaSwati GuptaNessuna valutazione finora
- Normalization: Repetition of Information Inability To Represent Certain Information Loss of InformationDocumento39 pagineNormalization: Repetition of Information Inability To Represent Certain Information Loss of Informationsubhrangshu chandraNessuna valutazione finora
- ApostolDocumento8 pagineApostolShehraiz KhanNessuna valutazione finora
- F U-4 PDFDocumento48 pagineF U-4 PDFRiyaz ShaikNessuna valutazione finora
- DBMS MCQDocumento27 pagineDBMS MCQRathore Yuvraj SinghNessuna valutazione finora
- Real Analysis by R. Vittal Rao: Lecture 1: March 01, 2006Documento3 pagineReal Analysis by R. Vittal Rao: Lecture 1: March 01, 2006RudinNessuna valutazione finora
- Syllabus:: MathematicsDocumento33 pagineSyllabus:: MathematicsMustafa SagbanNessuna valutazione finora
- EE5121: Convex Optimization: Assignment 1Documento2 pagineEE5121: Convex Optimization: Assignment 1Subhankar Chakraborty ee17b031Nessuna valutazione finora
- Relations, Mappings, Functions, Sequences v2.10.0Documento62 pagineRelations, Mappings, Functions, Sequences v2.10.0Marco RicardNessuna valutazione finora
- Relations and Functions XIIDocumento12 pagineRelations and Functions XIIKushalNessuna valutazione finora
- Relations and FunctionsDocumento5 pagineRelations and FunctionsFun PlanetNessuna valutazione finora
- c3 Practicetest4 2223 PDFDocumento4 paginec3 Practicetest4 2223 PDFalex renNessuna valutazione finora
- FunctionsDocumento4 pagineFunctionsMAQNessuna valutazione finora
- Class 11 Maths Notes Chapter 2 Studyguide360 PDFDocumento16 pagineClass 11 Maths Notes Chapter 2 Studyguide360 PDFPranavNessuna valutazione finora
- Rev - Ex 1.relations, FunctionsDocumento1 paginaRev - Ex 1.relations, Functionsepic1941tNessuna valutazione finora
- Relations and FunctionsDocumento2 pagineRelations and FunctionsLets Learn MathsNessuna valutazione finora
- Relation FunctionDocumento2 pagineRelation FunctionAshok PradhanNessuna valutazione finora
- Chapter 3 - Design Theory For Relational DatabasesDocumento73 pagineChapter 3 - Design Theory For Relational DatabasesTruong Huu Nhat (K17 HL)Nessuna valutazione finora
- Gams Bilgi Notu 1625309478-1Documento2 pagineGams Bilgi Notu 1625309478-1Berk AyvazNessuna valutazione finora
- Hermite-Hadamard Type Inequalities For Generalized S-Convex Functions On Real Linear Fractal Set R (0 < α < 1)Documento10 pagineHermite-Hadamard Type Inequalities For Generalized S-Convex Functions On Real Linear Fractal Set R (0 < α < 1)So NiaNessuna valutazione finora
- I 1 To N of F (I) : (Cross)Documento1 paginaI 1 To N of F (I) : (Cross)LangstofNessuna valutazione finora
- Exercises Analysis 2 (2WA40) Lecture 22Documento2 pagineExercises Analysis 2 (2WA40) Lecture 22Andrei PatularuNessuna valutazione finora
- Part2 - Ch5 - Relational Database Design by ER and ERR To Relational MappingDocumento20 paginePart2 - Ch5 - Relational Database Design by ER and ERR To Relational MappingLayan AlajoNessuna valutazione finora
- NormalizationDocumento32 pagineNormalizationsaravanaadNessuna valutazione finora
- Tutorial 1Documento2 pagineTutorial 1rnbapatNessuna valutazione finora
- The Function (And Other Mathematical and Computational Preliminaries)Documento27 pagineThe Function (And Other Mathematical and Computational Preliminaries)anon_70089162Nessuna valutazione finora
- Functional Dependency in DBMSDocumento57 pagineFunctional Dependency in DBMSashkmNessuna valutazione finora
- Unit 2 Functional - Dependency-2Documento22 pagineUnit 2 Functional - Dependency-2Bharti SharmaNessuna valutazione finora
- National Board For Higher Mathematics M. A. and M.Sc. Scholarship Test September 24, 2011 Time Allowed: 150 Minutes Maximum Marks: 30Documento6 pagineNational Board For Higher Mathematics M. A. and M.Sc. Scholarship Test September 24, 2011 Time Allowed: 150 Minutes Maximum Marks: 30Raj RoyNessuna valutazione finora
- Functions-Handout 1Documento3 pagineFunctions-Handout 1goosey ganderNessuna valutazione finora
- On Applications of Rough Sets Theory To Knowledge Discovery: Frida CoaquiraDocumento30 pagineOn Applications of Rough Sets Theory To Knowledge Discovery: Frida CoaquiraFrank JohnNessuna valutazione finora
- Mathh FestDocumento9 pagineMathh FestanshNessuna valutazione finora
- Lectures on P-Adic L-Functions. (AM-74), Volume 74Da EverandLectures on P-Adic L-Functions. (AM-74), Volume 74Nessuna valutazione finora
- Company Overview of Kidkraft, IncDocumento3 pagineCompany Overview of Kidkraft, IncWeichen Christopher XuNessuna valutazione finora
- Lim Bo SengDocumento1 paginaLim Bo SengWeichen Christopher XuNessuna valutazione finora
- 04 Definitions Basic OpsDocumento5 pagine04 Definitions Basic OpsWeichen Christopher XuNessuna valutazione finora
- 03 Summation NotationDocumento7 pagine03 Summation NotationWeichen Christopher XuNessuna valutazione finora
- 02 Systems of Linear EquationsDocumento6 pagine02 Systems of Linear EquationsWeichen Christopher XuNessuna valutazione finora
- History Essay French RevolutionDocumento3 pagineHistory Essay French RevolutionWeichen Christopher XuNessuna valutazione finora
- Leap Motion PDFDocumento18 pagineLeap Motion PDFAnkiTwilightedNessuna valutazione finora
- SRM OverviewDocumento37 pagineSRM Overviewbravichandra24Nessuna valutazione finora
- Understanding ISO 9001 Calibration RequirementsDocumento6 pagineUnderstanding ISO 9001 Calibration RequirementsAldrin HernandezNessuna valutazione finora
- Missing Person ProjectDocumento9 pagineMissing Person ProjectLaiba WaheedNessuna valutazione finora
- Engineering Properties (Al O) : 94% Aluminum Oxide Mechanical Units of Measure SI/Metric (Imperial)Documento7 pagineEngineering Properties (Al O) : 94% Aluminum Oxide Mechanical Units of Measure SI/Metric (Imperial)Hendy SetiawanNessuna valutazione finora
- G120D Getting Started 0418 en-USDocumento94 pagineG120D Getting Started 0418 en-USHamadi Ben SassiNessuna valutazione finora
- PDF - Gate Valve OS and YDocumento10 paginePDF - Gate Valve OS and YLENINROMEROH4168Nessuna valutazione finora
- En 10143-1993Documento7 pagineEn 10143-1993Eduardo TeixeiraNessuna valutazione finora
- Kelompok CKD - Tugas Terapi Modalitas KeperawatanDocumento14 pagineKelompok CKD - Tugas Terapi Modalitas KeperawatanWinda WidyaNessuna valutazione finora
- (Checked) 12 Anh 1-8Documento9 pagine(Checked) 12 Anh 1-8Nguyễn Khánh LinhNessuna valutazione finora
- Mbeya University of Science and TecnologyDocumento8 pagineMbeya University of Science and TecnologyVuluwa GeorgeNessuna valutazione finora
- Labnet MultiGene Manual PDFDocumento42 pagineLabnet MultiGene Manual PDFcuma mencobaNessuna valutazione finora
- Simulation of Inventory System PDFDocumento18 pagineSimulation of Inventory System PDFhmsohagNessuna valutazione finora
- Waste Heat BoilerDocumento7 pagineWaste Heat Boilerabdul karimNessuna valutazione finora
- Mahmoud Darwish TMADocumento15 pagineMahmoud Darwish TMABassant Ayman Ahmed Abdil Alim100% (1)
- Lab Session 8: To Develop and Understanding About Fatigue and To Draw S-N Curve For The Given Specimen: I. SteelDocumento4 pagineLab Session 8: To Develop and Understanding About Fatigue and To Draw S-N Curve For The Given Specimen: I. SteelMehboob MeharNessuna valutazione finora
- A Microscope For Christmas: Simple and Differential Stains: Definition and ExamplesDocumento4 pagineA Microscope For Christmas: Simple and Differential Stains: Definition and ExamplesGwendolyn CalatravaNessuna valutazione finora
- TrapsDocumento11 pagineTrapsAmandeep AroraNessuna valutazione finora
- L5CoachMentorReflectiveLog TemplateDocumento9 pagineL5CoachMentorReflectiveLog TemplateHadusssNessuna valutazione finora
- ESQLDocumento2 pagineESQLajay110125_kumarNessuna valutazione finora
- Addis Ababa University Lecture NoteDocumento65 pagineAddis Ababa University Lecture NoteTADY TUBE OWNER100% (9)
- Renaissance QuestionsDocumento3 pagineRenaissance QuestionsHezel Escora NavalesNessuna valutazione finora
- Chemistry Project Paper ChromatographyDocumento20 pagineChemistry Project Paper ChromatographyAmrita SNessuna valutazione finora
- p-100 Vol2 1935 Part5Documento132 paginep-100 Vol2 1935 Part5Matias MancillaNessuna valutazione finora