Potrebbero piacerti anche
- 3D CNNs for Human Action Recognition in VideosDocumento11 pagine3D CNNs for Human Action Recognition in VideosLUCAS HAASNessuna valutazione finora
- 3D Convolutional Neural Networks For Human Action RecognitionDocumento11 pagine3D Convolutional Neural Networks For Human Action RecognitionaditriadiNessuna valutazione finora
- LinkNet - Exploiting Encoder Representations For Efficient Semantic SegmentationDocumento5 pagineLinkNet - Exploiting Encoder Representations For Efficient Semantic SegmentationMario Galindo QueraltNessuna valutazione finora
- Video Transformer NetworkDocumento11 pagineVideo Transformer NetworkAqib MumtazNessuna valutazione finora
- Wang - Human Action Recognition Algorithm Based On Multi-Feature Map Fusion - 2020Documento9 pagineWang - Human Action Recognition Algorithm Based On Multi-Feature Map Fusion - 2020masoud kiaNessuna valutazione finora
- EI 2017 Art00004 Grigorios-TsagkatakisDocumento6 pagineEI 2017 Art00004 Grigorios-Tsagkatakismr.parth147Nessuna valutazione finora
- Non-Local Neural NetworksDocumento10 pagineNon-Local Neural NetworksEmran SalehNessuna valutazione finora
- Real-Time Ssdlite Object Detection On FpgaDocumento14 pagineReal-Time Ssdlite Object Detection On FpgaBhaumik ChavdaNessuna valutazione finora
- Handwritten Letter Recognition Using Artificial Intelligence'Documento9 pagineHandwritten Letter Recognition Using Artificial Intelligence'IJRASETPublicationsNessuna valutazione finora
- Unsupervised Deep Video Hashing With Balanced RotationDocumento7 pagineUnsupervised Deep Video Hashing With Balanced RotationriadelectroNessuna valutazione finora
- Combined CNN Transformer Encoder For Enhanced FineDocumento5 pagineCombined CNN Transformer Encoder For Enhanced FinephuongNessuna valutazione finora
- Improving Image Classification With Frequency Domain Layers For Feature ExtractionDocumento7 pagineImproving Image Classification With Frequency Domain Layers For Feature ExtractionWISSALNessuna valutazione finora
- Learning Spatiotemporal Features With 3D Convolutional NetworksDocumento16 pagineLearning Spatiotemporal Features With 3D Convolutional NetworksVenkata PraneethNessuna valutazione finora
- Transformer-Based Image CompressionDocumento10 pagineTransformer-Based Image CompressionBolivar Omar PacaNessuna valutazione finora
- Deep Learning IntroDocumento14 pagineDeep Learning IntropalansamyNessuna valutazione finora
- FAST VIDEO OBJECT SEGMENTATIONDocumento10 pagineFAST VIDEO OBJECT SEGMENTATIONadityaNessuna valutazione finora
- Deep Affine Motion Compensation Network For Inter Prediction in VVCDocumento11 pagineDeep Affine Motion Compensation Network For Inter Prediction in VVCMateus AraújoNessuna valutazione finora
- Deep Residual Learning For Image and Video RecognitionDocumento13 pagineDeep Residual Learning For Image and Video RecognitionAbu RayhanNessuna valutazione finora
- OrigamiDocumento14 pagineOrigamiSarthak GoyalNessuna valutazione finora
- A Real-Time Object Detection Processor With Xnor-BDocumento13 pagineA Real-Time Object Detection Processor With Xnor-BcattiewpieNessuna valutazione finora
- 2004 10934v1 PDFDocumento17 pagine2004 10934v1 PDFKSHITIJ SONI 19PE10041Nessuna valutazione finora
- Tokenlearner: What Can 8 Learned Tokens Do For Images and Videos?Documento21 pagineTokenlearner: What Can 8 Learned Tokens Do For Images and Videos?Papasanimohan SrinivasNessuna valutazione finora
- Feature Selection Using Deep Neural Networks: July 2015Documento7 pagineFeature Selection Using Deep Neural Networks: July 2015RahulsinghooooNessuna valutazione finora
- Learning Robust Feature Representations For Scene Text DetectionDocumento10 pagineLearning Robust Feature Representations For Scene Text DetectionMinh Đinh NhậtNessuna valutazione finora
- Learning Video Object Segmentation From Static ImagesDocumento16 pagineLearning Video Object Segmentation From Static ImagesAlejandro PosadaNessuna valutazione finora
- Deepdecision: A Mobile Deep Learning Framework For Edge Video AnalyticsDocumento9 pagineDeepdecision: A Mobile Deep Learning Framework For Edge Video AnalyticsmorganNessuna valutazione finora
- Semantic-Guided Feature Selection for Image CaptioningDocumento10 pagineSemantic-Guided Feature Selection for Image CaptioningTomislav IvandicNessuna valutazione finora
- IEEE SIGNAL PROCESSING MAGAZINE SURVEY OF MODEL COMPRESSION AND ACCELERATION FOR DEEP NEURAL NETWORKSDocumento10 pagineIEEE SIGNAL PROCESSING MAGAZINE SURVEY OF MODEL COMPRESSION AND ACCELERATION FOR DEEP NEURAL NETWORKSirfanwahla786Nessuna valutazione finora
- 2 Convolutional Neural Network For Image ClassificationDocumento6 pagine2 Convolutional Neural Network For Image ClassificationKompruch BenjaputharakNessuna valutazione finora
- Global-Local Path Networks For Monocular Depth Estimation With Vertical CutdepthDocumento11 pagineGlobal-Local Path Networks For Monocular Depth Estimation With Vertical Cutdepthus GPTNessuna valutazione finora
- Deep Tensor Convolution On MulticoresDocumento10 pagineDeep Tensor Convolution On MulticoresTrần Văn DuyNessuna valutazione finora
- Temporal Segment Networks: Towards Good Practices For Deep Action RecognitionDocumento16 pagineTemporal Segment Networks: Towards Good Practices For Deep Action RecognitionAkashGargNessuna valutazione finora
- 1 Abstract: Dev Barbhaya, Ankit Yadav, Lochan Gupta, Utkarsh Agrawal, and Vinamra ShrivastavaDocumento1 pagina1 Abstract: Dev Barbhaya, Ankit Yadav, Lochan Gupta, Utkarsh Agrawal, and Vinamra ShrivastavaAryann kumarNessuna valutazione finora
- A Compressed Deep Convolutional Neural Networks For Face RecognitionDocumento6 pagineA Compressed Deep Convolutional Neural Networks For Face RecognitionSiddharth KoliparaNessuna valutazione finora
- Sensors: Quantization and Deployment of Deep Neural Networks On MicrocontrollersDocumento32 pagineSensors: Quantization and Deployment of Deep Neural Networks On MicrocontrollerstptuyenNessuna valutazione finora
- Video Chatting Platform With Video Enhancing Feature Using Super ResolutionDocumento7 pagineVideo Chatting Platform With Video Enhancing Feature Using Super ResolutionIJRASETPublicationsNessuna valutazione finora
- Quo Vadis, Action Recognition? A New Model and The Kinetics DatasetDocumento10 pagineQuo Vadis, Action Recognition? A New Model and The Kinetics DatasetAkashGargNessuna valutazione finora
- Large-Scale Image-To-Video Face Retrieval With Convolutional Neural Network FeaturesDocumento6 pagineLarge-Scale Image-To-Video Face Retrieval With Convolutional Neural Network FeaturesIAES IJAINessuna valutazione finora
- Deep Iris Network Design with Computation and Model ConstraintsDocumento10 pagineDeep Iris Network Design with Computation and Model ConstraintspedroNessuna valutazione finora
- Aligning and Prompting Everything All at Once For Universal Visual PerceptionDocumento5 pagineAligning and Prompting Everything All at Once For Universal Visual Perceptionmallikarjunareddy kotaNessuna valutazione finora
- Hizami CHAPTER 1-FeedbacksDocumento5 pagineHizami CHAPTER 1-FeedbacksMohd Hizami Ab HalimNessuna valutazione finora
- Deep Learning-Based Multiple Object Visual Tracking On Embedded System For IoT and MobileDocumento8 pagineDeep Learning-Based Multiple Object Visual Tracking On Embedded System For IoT and MobileciaobubuNessuna valutazione finora
- Deep Learning Inference On Mobile Devices: Deepx: A Software Accelerator For Low-PowerDocumento12 pagineDeep Learning Inference On Mobile Devices: Deepx: A Software Accelerator For Low-PowerMewada HirenNessuna valutazione finora
- Improving The Performance of CBIR Using XGBoost Classifier With Deep CNN-Based Feature ExtractionDocumento6 pagineImproving The Performance of CBIR Using XGBoost Classifier With Deep CNN-Based Feature ExtractionYI JIE ONGNessuna valutazione finora
- An Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAsDocumento14 pagineAn Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAspalansamyNessuna valutazione finora
- JTECCNNDocumento6 pagineJTECCNN윤희지Nessuna valutazione finora
- Poly ScientistDocumento14 paginePoly ScientistMasci MerouaniNessuna valutazione finora
- GhostNet: Cheap Operations Generate More FeaturesDocumento10 pagineGhostNet: Cheap Operations Generate More FeaturesSSCPNessuna valutazione finora
- UNETRDocumento11 pagineUNETRAbduljabbar Salem Ba-MahelNessuna valutazione finora
- Vision Transformers for Dense Prediction: DPT ArchitectureDocumento15 pagineVision Transformers for Dense Prediction: DPT Architecture徐啸宇Nessuna valutazione finora
- Transformer-Based Visual Segmentation - A SurveyDocumento23 pagineTransformer-Based Visual Segmentation - A SurveycvalprhpNessuna valutazione finora
- Younis 2020Documento5 pagineYounis 2020nalakathshamil8Nessuna valutazione finora
- Surfcnn: A Descriptor Accelerated Convolutional Neural Network For Image-Based Indoor LocalizationDocumento10 pagineSurfcnn: A Descriptor Accelerated Convolutional Neural Network For Image-Based Indoor LocalizationgodhamwingNessuna valutazione finora
- DFANet Deep Feature Aggregation For Real-Time Semantic SegmentationDocumento10 pagineDFANet Deep Feature Aggregation For Real-Time Semantic Segmentationprajna acharyaNessuna valutazione finora
- Lightweight Deep LearningDocumento27 pagineLightweight Deep LearningHuston LAMNessuna valutazione finora
- Innovative Approach To Detect Mental Disorder Using Multimodal TechniqueDocumento4 pagineInnovative Approach To Detect Mental Disorder Using Multimodal TechniqueEditor IJRITCCNessuna valutazione finora
- Journal of Advanced Research: Andrei-Alexandru Tulbure, Adrian-Alexandru Tulbure, Eva-Henrietta DulfDocumento16 pagineJournal of Advanced Research: Andrei-Alexandru Tulbure, Adrian-Alexandru Tulbure, Eva-Henrietta DulfBudrescu GeorgeNessuna valutazione finora
- An Introduction To Deep Learning For The Physical LayerDocumento13 pagineAn Introduction To Deep Learning For The Physical Layerzhouxinzhao0211Nessuna valutazione finora
- Mobilenetv2: Inverted Residuals and Linear BottlenecksDocumento14 pagineMobilenetv2: Inverted Residuals and Linear Bottlenecksrineeth mNessuna valutazione finora
- Embedded Deep Learning: Algorithms, Architectures and Circuits for Always-on Neural Network ProcessingDa EverandEmbedded Deep Learning: Algorithms, Architectures and Circuits for Always-on Neural Network ProcessingNessuna valutazione finora
- Simple, Efficient and Effective Encodings of Local Deep Features For Video Action RecognitionDocumento8 pagineSimple, Efficient and Effective Encodings of Local Deep Features For Video Action RecognitionAnonymous ntIcRwM55RNessuna valutazione finora
- Spatio-Temporal Vector of Locally Max Pooled Features For Action Recognition in VideosDocumento11 pagineSpatio-Temporal Vector of Locally Max Pooled Features For Action Recognition in VideosAnonymous ntIcRwM55RNessuna valutazione finora
- SpeeD at MediaEval 2013 A Phone Recognition Approach To Spoken Term Detection PDFDocumento2 pagineSpeeD at MediaEval 2013 A Phone Recognition Approach To Spoken Term Detection PDFAnonymous ntIcRwM55RNessuna valutazione finora
- Spatio-Temporal VLAD Encoding For Human Action Recognition in VideosDocumento12 pagineSpatio-Temporal VLAD Encoding For Human Action Recognition in VideosAnonymous ntIcRwM55RNessuna valutazione finora
- The Cut Detection Issue in The Animation Movie DomainDocumento10 pagineThe Cut Detection Issue in The Animation Movie DomainAnonymous ntIcRwM55RNessuna valutazione finora
- Tackling Action - Based Video Abstraction of Animated Movies For Video BrowsingDocumento40 pagineTackling Action - Based Video Abstraction of Animated Movies For Video BrowsingAnonymous ntIcRwM55RNessuna valutazione finora
- Tackling Action - Based Video Abstraction of Animated Movies For Video BrowsingDocumento40 pagineTackling Action - Based Video Abstraction of Animated Movies For Video BrowsingAnonymous ntIcRwM55RNessuna valutazione finora
- Spatio-Temporal VLAD Encoding For Human Action Recognition in VideosDocumento12 pagineSpatio-Temporal VLAD Encoding For Human Action Recognition in VideosAnonymous ntIcRwM55RNessuna valutazione finora
- Static Hand Gesture Recognition SystemDocumento12 pagineStatic Hand Gesture Recognition SystemAnonymous ntIcRwM55RNessuna valutazione finora
- SpeeD at MediaEval 2013 A Phone Recognition Approach To Spoken Term Detection PDFDocumento2 pagineSpeeD at MediaEval 2013 A Phone Recognition Approach To Spoken Term Detection PDFAnonymous ntIcRwM55RNessuna valutazione finora
- The Influence of The Similarity Measure To Relevance FeedbackDocumento5 pagineThe Influence of The Similarity Measure To Relevance FeedbackAnonymous ntIcRwM55RNessuna valutazione finora
- Time Matters! Capturing Variation in Time in Video Using Fisher Kernels PDFDocumento4 pagineTime Matters! Capturing Variation in Time in Video Using Fisher Kernels PDFAnonymous ntIcRwM55RNessuna valutazione finora
- Static Hand Gesture Recognition SystemDocumento12 pagineStatic Hand Gesture Recognition SystemAnonymous ntIcRwM55RNessuna valutazione finora
- Tackling Action - Based Video Abstraction of Animated Movies For Video BrowsingDocumento40 pagineTackling Action - Based Video Abstraction of Animated Movies For Video BrowsingAnonymous ntIcRwM55RNessuna valutazione finora
- Static Hand Gesture Recognition SystemDocumento12 pagineStatic Hand Gesture Recognition SystemAnonymous ntIcRwM55RNessuna valutazione finora
- Video Genre Categorization and Representation Using Audio-Visual InformationDocumento41 pagineVideo Genre Categorization and Representation Using Audio-Visual InformationAnonymous ntIcRwM55RNessuna valutazione finora
- VSD2014 A Dataset For Violent Scenes Detection in Hollywood Movies and Web VideosDocumento6 pagineVSD2014 A Dataset For Violent Scenes Detection in Hollywood Movies and Web VideosAnonymous ntIcRwM55RNessuna valutazione finora
- UPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksDocumento9 pagineUPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksAnonymous ntIcRwM55RNessuna valutazione finora
- View Synthesis Based On Temporal Prediction Via Warped Motion Vector FieldsDocumento5 pagineView Synthesis Based On Temporal Prediction Via Warped Motion Vector FieldsAnonymous ntIcRwM55RNessuna valutazione finora
- Gestures Recognition Based On The Fusion of Hand Postures and Arm GesturesDocumento2 pagineGestures Recognition Based On The Fusion of Hand Postures and Arm GesturesAnonymous ntIcRwM55RNessuna valutazione finora
- Fisher Kernel Based Relevance Feedback For Multimodal Video RetrievalDocumento8 pagineFisher Kernel Based Relevance Feedback For Multimodal Video RetrievalAnonymous ntIcRwM55RNessuna valutazione finora
- Fisher Kernel Temporal Variation-Based Relevance Feedback For Video RetrievalDocumento41 pagineFisher Kernel Temporal Variation-Based Relevance Feedback For Video RetrievalAnonymous ntIcRwM55RNessuna valutazione finora
- From Improved Auto-Taggers To Improved MusicDocumento10 pagineFrom Improved Auto-Taggers To Improved MusicAnonymous ntIcRwM55RNessuna valutazione finora
- Generating Captions For Medical Images With A Deep Learning Multi-Hypothesis Approach ImageCLEF 2017 Caption TaskDocumento6 pagineGenerating Captions For Medical Images With A Deep Learning Multi-Hypothesis Approach ImageCLEF 2017 Caption TaskAnonymous ntIcRwM55RNessuna valutazione finora
- Ensemble-Based Learning Using Few Training Samples For Video Surveillance ScenariosDocumento6 pagineEnsemble-Based Learning Using Few Training Samples For Video Surveillance ScenariosAnonymous ntIcRwM55RNessuna valutazione finora
- Ensemble-Based Learning Using Few Training Samples For Video Surveillance ScenariosDocumento6 pagineEnsemble-Based Learning Using Few Training Samples For Video Surveillance ScenariosAnonymous ntIcRwM55RNessuna valutazione finora
- Fisher Kernel Temporal Variation-Based Relevance Feedback For Video RetrievalDocumento41 pagineFisher Kernel Temporal Variation-Based Relevance Feedback For Video RetrievalAnonymous ntIcRwM55RNessuna valutazione finora
- Fisher Kernel Based Relevance Feedback For Multimodal Video RetrievalDocumento8 pagineFisher Kernel Based Relevance Feedback For Multimodal Video RetrievalAnonymous ntIcRwM55RNessuna valutazione finora
- Event-Based Media Processing and Analysis A Survey of The LiteratureDocumento28 pagineEvent-Based Media Processing and Analysis A Survey of The LiteratureAnonymous ntIcRwM55RNessuna valutazione finora
- School Account Management SystemDocumento11 pagineSchool Account Management SystemHashirwaleedNessuna valutazione finora
- MF Cobol ManualDocumento586 pagineMF Cobol ManualGopichand MayaraNessuna valutazione finora
- Google's Intellectual Property (IP) Regarding Computers, Computing, and Computational MethodsDocumento39 pagineGoogle's Intellectual Property (IP) Regarding Computers, Computing, and Computational MethodsElan MoritzNessuna valutazione finora
- Considerations, Best Practices and Requirements For A Virtualised Mobile NetworkDocumento25 pagineConsiderations, Best Practices and Requirements For A Virtualised Mobile NetworkArbabNessuna valutazione finora
- Face Tracking With A Pan - Tilt Servo Bracket - SparkFun ElectronicsDocumento24 pagineFace Tracking With A Pan - Tilt Servo Bracket - SparkFun ElectronicsLarasmoyo NugrohoNessuna valutazione finora
- Points & Deviations - A Pattern Language For Fire Alarm SystemsDocumento12 paginePoints & Deviations - A Pattern Language For Fire Alarm SystemsAhmed AhmedabdelrazekNessuna valutazione finora
- Conexionado de Motores InduccionDocumento152 pagineConexionado de Motores InduccionFabianTorres100% (1)
- Smart HomeDocumento7 pagineSmart HomeWentika Putri100% (1)
- Registers and CountersDocumento28 pagineRegisters and CountersHammadMehmoodNessuna valutazione finora
- Floating-Gate MOSFET: From Wikipedia, The Free EncyclopediaDocumento4 pagineFloating-Gate MOSFET: From Wikipedia, The Free EncyclopediaAtul RainaNessuna valutazione finora
- P7p55d-E LX Memory QVLDocumento6 pagineP7p55d-E LX Memory QVLKhai EmanNessuna valutazione finora
- Computer Engineering Department: Real-Time Embedded Processor Systems (ACOE343)Documento4 pagineComputer Engineering Department: Real-Time Embedded Processor Systems (ACOE343)Imam ArievNessuna valutazione finora
- Presentation DIP5000 enDocumento31 paginePresentation DIP5000 enNeelakandan MasilamaniNessuna valutazione finora
- Computer Organization Course Outline To Be Printed-1Documento2 pagineComputer Organization Course Outline To Be Printed-1habtamu fentewNessuna valutazione finora
- LaptopDocumento14 pagineLaptopDwarakesh VishwanathanNessuna valutazione finora
- Quartus II Introduction PDFDocumento38 pagineQuartus II Introduction PDFwindywake3910Nessuna valutazione finora
- Manual Operação Computador PAT DS85Documento60 pagineManual Operação Computador PAT DS85EdilsonNessuna valutazione finora
- SINAMICS S120 Commissioning Manual 0306 EngDocumento412 pagineSINAMICS S120 Commissioning Manual 0306 Engwww.otomasyonegitimi.com100% (1)
- Root File SystemDocumento2 pagineRoot File Systemtiwari anupamNessuna valutazione finora
- Fire Cat Iss 6 9Documento190 pagineFire Cat Iss 6 9mohsen zeyad1Nessuna valutazione finora
- Lab Course-I SlipsDocumento39 pagineLab Course-I SlipsRK NAIR0% (1)
- Distributed OS Sem VDocumento5 pagineDistributed OS Sem VsoujanaNessuna valutazione finora
- g5 Medical Devices Vibracare Vibraacare Service ManualDocumento4 pagineg5 Medical Devices Vibracare Vibraacare Service ManualFélix HernándezNessuna valutazione finora
- DS9 NewlongDocumento52 pagineDS9 NewlongSegio ReyNessuna valutazione finora
- Job PortalDocumento13 pagineJob PortalAkhilSainiNessuna valutazione finora
- How To Get Every Detail About SSDT, GDT, IDT in A Blink of An Eye - Sina & Shahriar's BlogDocumento7 pagineHow To Get Every Detail About SSDT, GDT, IDT in A Blink of An Eye - Sina & Shahriar's Blog宛俊Nessuna valutazione finora
- A010031 How To Use PowerAIX Historical Cumulative Statistics To Indicate Performance Issues Cairo Earlj July16-2016Documento60 pagineA010031 How To Use PowerAIX Historical Cumulative Statistics To Indicate Performance Issues Cairo Earlj July16-2016Okuntade OluwoleNessuna valutazione finora
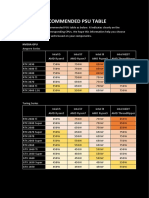
- Recommended Psu TableDocumento2 pagineRecommended Psu TableFaisal Fikri HakimNessuna valutazione finora
- CWRU Cutter 2010 NI Week ApplicationDocumento8 pagineCWRU Cutter 2010 NI Week ApplicationMadhumita RameshbabuNessuna valutazione finora
- Asansol Engineering College: Topic: PPT Assignment On "Comparative Study On Different Types of Topology"Documento10 pagineAsansol Engineering College: Topic: PPT Assignment On "Comparative Study On Different Types of Topology"Haimanti SadhuNessuna valutazione finora