Potrebbero piacerti anche
- Howto Urllib2Documento11 pagineHowto Urllib2aleks3Nessuna valutazione finora
- Programming FPGAs: Getting Started with VerilogDa EverandProgramming FPGAs: Getting Started with VerilogValutazione: 3.5 su 5 stelle3.5/5 (2)
- Python-RDM Documentation: Release 0.1Documento36 paginePython-RDM Documentation: Release 0.1IENSOUBO DidierNessuna valutazione finora
- Programming Arduino Next Steps: Going Further with Sketches, Second EditionDa EverandProgramming Arduino Next Steps: Going Further with Sketches, Second EditionValutazione: 3 su 5 stelle3/5 (3)
- Pandas Datareader LatestDocumento65 paginePandas Datareader LatestIgor SzalajNessuna valutazione finora
- Tornado Documentation Release NotesDocumento239 pagineTornado Documentation Release NotesRiyaz MohammedNessuna valutazione finora
- Pdfreader Documentation: Release 0.1.9Documento40 paginePdfreader Documentation: Release 0.1.9Alina CrengutzaNessuna valutazione finora
- Pdfreader Documentation: Release 0.1.7Documento40 paginePdfreader Documentation: Release 0.1.7IuliaNessuna valutazione finora
- Pdfreader Documentation: Release 0.1.10Documento40 paginePdfreader Documentation: Release 0.1.10Rebeca AntoniaNessuna valutazione finora
- Conpot Readthedocs Io en LatestDocumento105 pagineConpot Readthedocs Io en LatestFebrian RachmadNessuna valutazione finora
- Pdfreader Readthedocs Io en LatestDocumento40 paginePdfreader Readthedocs Io en LatestTheBoyNessuna valutazione finora
- Pdfreader Readthedocs Io en LatestDocumento40 paginePdfreader Readthedocs Io en Latestflorentina22tinaNessuna valutazione finora
- aiogram Docs QuickstartDocumento257 pagineaiogram Docs QuickstartJeff NguebouNessuna valutazione finora
- aiogram Documentation Quick StartDocumento245 pagineaiogram Documentation Quick Startdsfdsf23411Nessuna valutazione finora
- aiogram Documentation Quick StartDocumento245 pagineaiogram Documentation Quick Startdsfdsf23411Nessuna valutazione finora
- Routingpy Readthedocs Io en LatestDocumento58 pagineRoutingpy Readthedocs Io en LatestpablomartinezdiezNessuna valutazione finora
- PDF Document Viewer and Extractor DocumentationDocumento38 paginePDF Document Viewer and Extractor DocumentationCatalinaCirimbeiNessuna valutazione finora
- howto-loggingDocumento17 paginehowto-loggingAmdeaNessuna valutazione finora
- Flask Restx Readthedocs Io en LatestDocumento95 pagineFlask Restx Readthedocs Io en LatestRyang SohnNessuna valutazione finora
- Flask Restx Readthedocs Io en LatestDocumento95 pagineFlask Restx Readthedocs Io en Latestatabe tahNessuna valutazione finora
- BLC Project PDFDocumento23 pagineBLC Project PDFFakibazz frndsNessuna valutazione finora
- Cpython Devguide PDFDocumento161 pagineCpython Devguide PDFsafe agileNessuna valutazione finora
- Python Developer's Guide Documentation: Brett CannonDocumento169 paginePython Developer's Guide Documentation: Brett CannonkmdasariNessuna valutazione finora
- Howto LoggingDocumento17 pagineHowto LoggingSamuel LaurianoNessuna valutazione finora
- Open FastDocumento425 pagineOpen FastRodolfo Curci PuracaNessuna valutazione finora
- Puresnmp Readthedocs Io en LatestDocumento77 paginePuresnmp Readthedocs Io en LatestDouglas CruzNessuna valutazione finora
- 01.JavaScript Reintroduction 1Documento60 pagine01.JavaScript Reintroduction 1Teodora DimovskaNessuna valutazione finora
- Django AllauthDocumento69 pagineDjango AllauthThapaa LilaNessuna valutazione finora
- Ezdxf Readthedocs Io en Master PDFDocumento524 pagineEzdxf Readthedocs Io en Master PDFHybcon 18Nessuna valutazione finora
- Devguide Python Org en LatestDocumento171 pagineDevguide Python Org en LatestPranit WaydhaneNessuna valutazione finora
- QGIS 2.0 UserGuide PT PTDocumento283 pagineQGIS 2.0 UserGuide PT PTPaulo RibeiroNessuna valutazione finora
- Curso PythonDocumento159 pagineCurso PythonmaruxasiNessuna valutazione finora
- AspnetDocumento479 pagineAspnetAyoub SannoutiNessuna valutazione finora
- Howto LoggingDocumento17 pagineHowto Logginglil telNessuna valutazione finora
- Aiogram Documentation: Release 2.9.2Documento220 pagineAiogram Documentation: Release 2.9.2alexxxxxxxNessuna valutazione finora
- Howto LoggingDocumento17 pagineHowto LoggingJason DavisNessuna valutazione finora
- Logging HOWTO: Guido Van Rossum and The Python Development TeamDocumento17 pagineLogging HOWTO: Guido Van Rossum and The Python Development TeamCesar Marinho EirasNessuna valutazione finora
- Python IntelhexDocumento25 paginePython Intelhexcarlosalberto_28Nessuna valutazione finora
- Python Logging GuideDocumento17 paginePython Logging GuideBernie RivasNessuna valutazione finora
- Aiozmq Readthedocs Io en LatestDocumento68 pagineAiozmq Readthedocs Io en LatestGustavo Meneses PérezNessuna valutazione finora
- Python Logging GuideDocumento16 paginePython Logging Guidealeks3Nessuna valutazione finora
- QGIS User Guide: Release 2.18Documento10 pagineQGIS User Guide: Release 2.18Mihai LazarNessuna valutazione finora
- QGIS 2.18 UserGuide enDocumento479 pagineQGIS 2.18 UserGuide enMihai LazarNessuna valutazione finora
- QGIS Testing UserGuide enDocumento885 pagineQGIS Testing UserGuide enaqqad945701100% (1)
- Django REST Framework JSON API DocsDocumento21 pagineDjango REST Framework JSON API DocsHenry OseiNessuna valutazione finora
- Computational Chemistry Using LinuxDocumento17 pagineComputational Chemistry Using LinuxmauricioesguerraNessuna valutazione finora
- Django Rest Framework Json APIDocumento21 pagineDjango Rest Framework Json APIHimawan SandhiNessuna valutazione finora
- Logging HOWTO: Guido Van Rossum and The Python Development TeamDocumento17 pagineLogging HOWTO: Guido Van Rossum and The Python Development Teambibas khakuralNessuna valutazione finora
- QGIS 2.18 UserGuide enDocumento475 pagineQGIS 2.18 UserGuide enRiccardo RicciNessuna valutazione finora
- Python Redmine PDFDocumento97 paginePython Redmine PDFramki1980Nessuna valutazione finora
- Segmentation Models Documentation: Release 0.1.2Documento25 pagineSegmentation Models Documentation: Release 0.1.2Swati ModiNessuna valutazione finora
- Python For AstronomersDocumento62 paginePython For AstronomersUncleMiltyNessuna valutazione finora
- Howto LoggingDocumento18 pagineHowto LoggingWisdom OkuNessuna valutazione finora
- Howto FunctionalDocumento22 pagineHowto FunctionalRuthvikNessuna valutazione finora
- Howto - LoggingDocumento18 pagineHowto - LoggingAsd HdfseasNessuna valutazione finora
- Ezdxf Readthedocs Io en LatestDocumento350 pagineEzdxf Readthedocs Io en LatestsureshNessuna valutazione finora
- Django Rest Framework Json APIDocumento21 pagineDjango Rest Framework Json APIAshok PatidarNessuna valutazione finora
- DynetxDocumento72 pagineDynetxMaz Har UlNessuna valutazione finora
- AiohttpDocumento140 pagineAiohttpRohan JainNessuna valutazione finora
- What Is Permeable Concrete?: Design of The SampleDocumento1 paginaWhat Is Permeable Concrete?: Design of The SampleRanu GamesNessuna valutazione finora
- Software EngineeringDocumento40 pagineSoftware EngineeringRanu GamesNessuna valutazione finora
- E0805034043Documento5 pagineE0805034043Ranu GamesNessuna valutazione finora
- Ortho1 PDFDocumento2 pagineOrtho1 PDFadnanraisahmedNessuna valutazione finora
- Impacts of Extreme Events On Transmission and Distribution SystemsDocumento10 pagineImpacts of Extreme Events On Transmission and Distribution SystemsRanu GamesNessuna valutazione finora
- Friction of Pipe 2Documento5 pagineFriction of Pipe 2Ranu GamesNessuna valutazione finora
- Portable Electrical Ladder: XXX-X-XXXX-XXXX-X/XX/$XX.00 ©20XX IEEEDocumento5 paginePortable Electrical Ladder: XXX-X-XXXX-XXXX-X/XX/$XX.00 ©20XX IEEERanu GamesNessuna valutazione finora
- Friction of Pipe 2Documento5 pagineFriction of Pipe 2Ranu GamesNessuna valutazione finora
- 1Documento7 pagine1Ranu GamesNessuna valutazione finora
- 1Documento7 pagine1Ranu GamesNessuna valutazione finora
- Double Entry System, The Ledger and The Trial BalanceDocumento37 pagineDouble Entry System, The Ledger and The Trial BalanceRanu GamesNessuna valutazione finora
- 11 Chapter 3Documento16 pagine11 Chapter 3Ranu GamesNessuna valutazione finora
- DISCRIPTIONDocumento8 pagineDISCRIPTIONRanu GamesNessuna valutazione finora
- Cover Page PDFDocumento1 paginaCover Page PDFRanu GamesNessuna valutazione finora
- Format of The BalancesheetDocumento2 pagineFormat of The BalancesheetRanu Games100% (1)
- Power Cycles 2019Documento29 paginePower Cycles 2019Ranu Games100% (1)
- Discussion: Spur Gear & Helical Gears: Cutaway ModelDocumento6 pagineDiscussion: Spur Gear & Helical Gears: Cutaway ModelRanu GamesNessuna valutazione finora
- Fluid Statics: Figure 3.1 (P. 31)Documento10 pagineFluid Statics: Figure 3.1 (P. 31)Omil RastogiNessuna valutazione finora
- Flywheel or Inertia Wheel Used in A MachineDocumento3 pagineFlywheel or Inertia Wheel Used in A MachineRanu GamesNessuna valutazione finora
- Ortho1 PDFDocumento2 pagineOrtho1 PDFadnanraisahmedNessuna valutazione finora
- DLTC Announcement 2017-NewDocumento4 pagineDLTC Announcement 2017-NewRanu GamesNessuna valutazione finora
- Theoretical Determination of Metacentric Height of A Floating BodyDocumento2 pagineTheoretical Determination of Metacentric Height of A Floating BodyRanu GamesNessuna valutazione finora
- Viscosity vs. Temperature For Common FluidsDocumento1 paginaViscosity vs. Temperature For Common FluidsRanu GamesNessuna valutazione finora
- Ship MovementsDocumento1 paginaShip MovementsRanu GamesNessuna valutazione finora
- Introduction To Fluid Mechanics - 2005Documento27 pagineIntroduction To Fluid Mechanics - 2005Ranu GamesNessuna valutazione finora
- CE 1022 Buoyancy and Relative Equilibrium - Lecture NoteDocumento36 pagineCE 1022 Buoyancy and Relative Equilibrium - Lecture NoteRanu GamesNessuna valutazione finora
- Ch3 Fluid Statics (Part B)Documento68 pagineCh3 Fluid Statics (Part B)lofeagaiNessuna valutazione finora
- B12e Fluid Mechanics Fluid Mechanics Fluid MechanicsDocumento2 pagineB12e Fluid Mechanics Fluid Mechanics Fluid MechanicsKushanNessuna valutazione finora
- Ds PalmSecure SDK Software Development Kit (FINAL)Documento3 pagineDs PalmSecure SDK Software Development Kit (FINAL)Irwan AsminanNessuna valutazione finora
- Tips & Tricks: HTML Tags and Drag & DropDocumento1 paginaTips & Tricks: HTML Tags and Drag & DropTOPdeskNessuna valutazione finora
- Security&OpmarkDocumento19 pagineSecurity&Opmarksina20795Nessuna valutazione finora
- Mos 365 Excel Od 2022Documento2 pagineMos 365 Excel Od 2022Mai Hương HoàngNessuna valutazione finora
- VBS QCDocumento9 pagineVBS QCjanardanupadhyayNessuna valutazione finora
- Crack Online Passwords With HYDRADocumento9 pagineCrack Online Passwords With HYDRASaimonK100% (1)
- UK - Angular - Day 2 PDFDocumento12 pagineUK - Angular - Day 2 PDFAmitNessuna valutazione finora
- How To Import Data Into ROVERDocumento23 pagineHow To Import Data Into ROVERMa Khristina Cassandra PacomaNessuna valutazione finora
- Us 14 Rosenberg Reflections On Trusting TrustZoneDocumento33 pagineUs 14 Rosenberg Reflections On Trusting TrustZoneth3.pil0tNessuna valutazione finora
- Change Shortcut Keys - Synfig Animation StudioDocumento1 paginaChange Shortcut Keys - Synfig Animation StudioNdandungNessuna valutazione finora
- RACF5 Ichza6c1Documento444 pagineRACF5 Ichza6c1Siranjeevi MohanarajaNessuna valutazione finora
- Online Admission SystemDocumento3 pagineOnline Admission SystemshitalNessuna valutazione finora
- E15478 PDFDocumento606 pagineE15478 PDFKomal KandiNessuna valutazione finora
- Java Logging APIDocumento5 pagineJava Logging APIemscmrNessuna valutazione finora
- College ManagementDocumento20 pagineCollege ManagementKmrs Sugapriya1213Nessuna valutazione finora
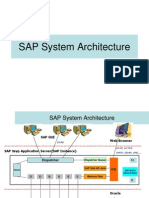
- SAP Technical OverviewDocumento31 pagineSAP Technical OverviewSrikanth Goud100% (1)
- PHP Project Computer AccessoriesDocumento91 paginePHP Project Computer AccessoriesKaranRajNessuna valutazione finora
- Growth For Startups SUS PDFDocumento67 pagineGrowth For Startups SUS PDFPhilip SkogsbergNessuna valutazione finora
- Introduction to Client/Server ArchitectureDocumento21 pagineIntroduction to Client/Server ArchitectureGautam PriyadarshiNessuna valutazione finora
- DXDiagDocumento16 pagineDXDiagtechedt91Nessuna valutazione finora
- Unit-3 HTML: 2160708 Web TechnologyDocumento48 pagineUnit-3 HTML: 2160708 Web Technologydivyesh radadiyaNessuna valutazione finora
- Project Topic: Online Examination in Java: Name: Priya KasbekarDocumento3 pagineProject Topic: Online Examination in Java: Name: Priya KasbekarsagarNessuna valutazione finora
- USB-Driver Installation: Software ManualDocumento24 pagineUSB-Driver Installation: Software ManualLenin RamonNessuna valutazione finora
- Secse 1Documento20 pagineSecse 1Shamim H RiponNessuna valutazione finora
- Tips For Optimimizing WEBI REPORTSDocumento38 pagineTips For Optimimizing WEBI REPORTSManzar AlamNessuna valutazione finora
- UML Taxi Service PDFDocumento10 pagineUML Taxi Service PDFBiniyam MusemaNessuna valutazione finora
- JBL LIVE 650BTNC Manual: User Manuals SimplifiedDocumento15 pagineJBL LIVE 650BTNC Manual: User Manuals Simplifiedbano1501Nessuna valutazione finora
- Debugging Techniques in SAP CRM Web UI.Documento4 pagineDebugging Techniques in SAP CRM Web UI.rajesh98765Nessuna valutazione finora
- Umbraco Basic ConceptsDocumento12 pagineUmbraco Basic Conceptsrenuramesh1904Nessuna valutazione finora
- Understanding Spotify: Try / Learn / ShareDocumento37 pagineUnderstanding Spotify: Try / Learn / ShareJeff Scherrer100% (1)
- Reasonable Doubts: The O.J. Simpson Case and the Criminal Justice SystemDa EverandReasonable Doubts: The O.J. Simpson Case and the Criminal Justice SystemValutazione: 4 su 5 stelle4/5 (25)
- Nine Black Robes: Inside the Supreme Court's Drive to the Right and Its Historic ConsequencesDa EverandNine Black Robes: Inside the Supreme Court's Drive to the Right and Its Historic ConsequencesNessuna valutazione finora
- The Invention of Murder: How the Victorians Revelled in Death and Detection and Created Modern CrimeDa EverandThe Invention of Murder: How the Victorians Revelled in Death and Detection and Created Modern CrimeValutazione: 3.5 su 5 stelle3.5/5 (142)
- O.J. Is Innocent and I Can Prove It: The Shocking Truth about the Murders of Nicole Brown Simpson and Ron GoldmanDa EverandO.J. Is Innocent and I Can Prove It: The Shocking Truth about the Murders of Nicole Brown Simpson and Ron GoldmanValutazione: 4 su 5 stelle4/5 (2)
- Perversion of Justice: The Jeffrey Epstein StoryDa EverandPerversion of Justice: The Jeffrey Epstein StoryValutazione: 4.5 su 5 stelle4.5/5 (10)
- Reading the Constitution: Why I Chose Pragmatism, not TextualismDa EverandReading the Constitution: Why I Chose Pragmatism, not TextualismNessuna valutazione finora
- University of Berkshire Hathaway: 30 Years of Lessons Learned from Warren Buffett & Charlie Munger at the Annual Shareholders MeetingDa EverandUniversity of Berkshire Hathaway: 30 Years of Lessons Learned from Warren Buffett & Charlie Munger at the Annual Shareholders MeetingValutazione: 4.5 su 5 stelle4.5/5 (97)
- Conviction: The Untold Story of Putting Jodi Arias Behind BarsDa EverandConviction: The Untold Story of Putting Jodi Arias Behind BarsValutazione: 4.5 su 5 stelle4.5/5 (16)
- The Killer Across the Table: Unlocking the Secrets of Serial Killers and Predators with the FBI's Original MindhunterDa EverandThe Killer Across the Table: Unlocking the Secrets of Serial Killers and Predators with the FBI's Original MindhunterValutazione: 4.5 su 5 stelle4.5/5 (456)
- For the Thrill of It: Leopold, Loeb, and the Murder That Shocked Jazz Age ChicagoDa EverandFor the Thrill of It: Leopold, Loeb, and the Murder That Shocked Jazz Age ChicagoValutazione: 4 su 5 stelle4/5 (97)
- Summary: Surrounded by Idiots: The Four Types of Human Behavior and How to Effectively Communicate with Each in Business (and in Life) by Thomas Erikson: Key Takeaways, Summary & AnalysisDa EverandSummary: Surrounded by Idiots: The Four Types of Human Behavior and How to Effectively Communicate with Each in Business (and in Life) by Thomas Erikson: Key Takeaways, Summary & AnalysisValutazione: 4 su 5 stelle4/5 (2)
- Hunting Whitey: The Inside Story of the Capture & Killing of America's Most Wanted Crime BossDa EverandHunting Whitey: The Inside Story of the Capture & Killing of America's Most Wanted Crime BossValutazione: 3.5 su 5 stelle3.5/5 (6)
- A Contractor's Guide to the FIDIC Conditions of ContractDa EverandA Contractor's Guide to the FIDIC Conditions of ContractNessuna valutazione finora
- The Law Says What?: Stuff You Didn't Know About the Law (but Really Should!)Da EverandThe Law Says What?: Stuff You Didn't Know About the Law (but Really Should!)Valutazione: 4.5 su 5 stelle4.5/5 (10)
- I GIVE YOU CREDIT: A DO IT YOURSELF GUIDE TO CREDIT REPAIRDa EverandI GIVE YOU CREDIT: A DO IT YOURSELF GUIDE TO CREDIT REPAIRNessuna valutazione finora
- Introduction to Negotiable Instruments: As per Indian LawsDa EverandIntroduction to Negotiable Instruments: As per Indian LawsValutazione: 5 su 5 stelle5/5 (1)
- Your Deceptive Mind: A Scientific Guide to Critical Thinking (Transcript)Da EverandYour Deceptive Mind: A Scientific Guide to Critical Thinking (Transcript)Valutazione: 4 su 5 stelle4/5 (31)
- The Edge of Doubt: The Trial of Nancy Smith and Joseph AllenDa EverandThe Edge of Doubt: The Trial of Nancy Smith and Joseph AllenValutazione: 4.5 su 5 stelle4.5/5 (10)
- Lady Killers: Deadly Women Throughout HistoryDa EverandLady Killers: Deadly Women Throughout HistoryValutazione: 4 su 5 stelle4/5 (154)
- Never Suck a Dead Man's Hand: Curious Adventures of a CSIDa EverandNever Suck a Dead Man's Hand: Curious Adventures of a CSIValutazione: 4.5 su 5 stelle4.5/5 (13)
- Notarial Practice & Malpractice in the Philippines: Rules, Jurisprudence, & CommentsDa EverandNotarial Practice & Malpractice in the Philippines: Rules, Jurisprudence, & CommentsValutazione: 5 su 5 stelle5/5 (3)
- Getting Through: Cold Calling Techniques To Get Your Foot In The DoorDa EverandGetting Through: Cold Calling Techniques To Get Your Foot In The DoorValutazione: 4.5 su 5 stelle4.5/5 (63)
- We Were Once a Family: A Story of Love, Death, and Child Removal in AmericaDa EverandWe Were Once a Family: A Story of Love, Death, and Child Removal in AmericaValutazione: 4.5 su 5 stelle4.5/5 (53)