Potrebbero piacerti anche
- Infección PuerperalDocumento2 pagineInfección PuerperalStefaniaNessuna valutazione finora
- Dia Nacional Del Voto FemeninoDocumento8 pagineDia Nacional Del Voto FemeninoStefaniaNessuna valutazione finora
- Glosario y ProteinogramaDocumento7 pagineGlosario y ProteinogramaStefaniaNessuna valutazione finora
- BACTERIOLOGIA ExpoDocumento28 pagineBACTERIOLOGIA ExpoStefaniaNessuna valutazione finora
- Ambiente PsicosocialDocumento9 pagineAmbiente PsicosocialStefaniaNessuna valutazione finora
- Cuidados PuerperalesDocumento5 pagineCuidados PuerperalesStefaniaNessuna valutazione finora
- Score Mama Word.Documento4 pagineScore Mama Word.StefaniaNessuna valutazione finora
- Constituciòn de La Republica Del EcuadorDocumento1 paginaConstituciòn de La Republica Del EcuadorStefaniaNessuna valutazione finora
- Articulos PeriodisticosDocumento4 pagineArticulos PeriodisticosStefaniaNessuna valutazione finora
- CASO CLINICO TDPDocumento9 pagineCASO CLINICO TDPStefaniaNessuna valutazione finora
- Evoluciòn HistòricaDocumento6 pagineEvoluciòn HistòricaStefaniaNessuna valutazione finora
- Suicidio e InfanticidioDocumento9 pagineSuicidio e InfanticidioStefaniaNessuna valutazione finora
- Valor LealtadDocumento5 pagineValor LealtadStefaniaNessuna valutazione finora
- Valor de La PerseveranciaDocumento2 pagineValor de La PerseveranciaStefaniaNessuna valutazione finora
- Fenómenos Biofísicos Molecualres Biofisica 1Documento4 pagineFenómenos Biofísicos Molecualres Biofisica 1StefaniaNessuna valutazione finora
- Anatomia 2... Clase 2.. Laringe y TraqueaDocumento42 pagineAnatomia 2... Clase 2.. Laringe y TraqueaStefaniaNessuna valutazione finora
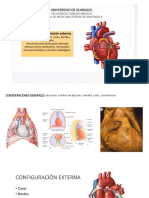
- CORAZONDocumento18 pagineCORAZONStefaniaNessuna valutazione finora
- Evolución Historica de La Medicina LegalDocumento3 pagineEvolución Historica de La Medicina LegalStefaniaNessuna valutazione finora
- Jaime José Nebot SaadiDocumento3 pagineJaime José Nebot SaadiStefaniaNessuna valutazione finora
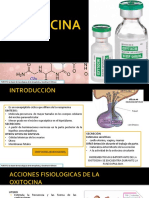
- Oxitocina - Prostaglandinas, CentenoDocumento17 pagineOxitocina - Prostaglandinas, CentenoStefaniaNessuna valutazione finora
- Histamina y Fàrmacos AntihistamìnicosDocumento7 pagineHistamina y Fàrmacos AntihistamìnicosStefaniaNessuna valutazione finora
- Ofrecimiento Del Acto de LA BANDERADocumento2 pagineOfrecimiento Del Acto de LA BANDERAStefaniaNessuna valutazione finora
- Tal Vez Deberías Hablar Con AlguienDocumento383 pagineTal Vez Deberías Hablar Con Alguienjezabel sanchezNessuna valutazione finora
- Simulacion de Viga (Acero Astm A32)Documento4 pagineSimulacion de Viga (Acero Astm A32)Javier Enriquez GutierrezNessuna valutazione finora
- CAUCHING y Trabajo en EquipoDocumento40 pagineCAUCHING y Trabajo en EquipoJose Smith CalisayaNessuna valutazione finora
- Clasificación de Los Aceros Por Su SoldabilidadDocumento10 pagineClasificación de Los Aceros Por Su SoldabilidadCarlos BaldeonNessuna valutazione finora
- 7 Fuentes de MagnetismoDocumento4 pagine7 Fuentes de MagnetismoDisman D'smNessuna valutazione finora
- Protocolos Igp Egp BGPDocumento13 pagineProtocolos Igp Egp BGPAldair Memije Angel100% (1)
- Guia Práctica 03Documento7 pagineGuia Práctica 03JORGE VICTOR WILFREDO CACHAY WESTERNessuna valutazione finora
- Módulo 3 - RRHHDocumento44 pagineMódulo 3 - RRHHNataly Santa QuispeNessuna valutazione finora
- CURRICULUM VITAE Jhonny Rivas Febrero - 2022Documento10 pagineCURRICULUM VITAE Jhonny Rivas Febrero - 2022Fernando PeredoNessuna valutazione finora
- Instrumentación 1Documento6 pagineInstrumentación 1Humberto ArizaNessuna valutazione finora
- Lab. 1 ECGDocumento3 pagineLab. 1 ECGJulita Nelson GordonNessuna valutazione finora
- 4-C Matutino SD2 No 21Documento6 pagine4-C Matutino SD2 No 21Lorena Jiménez VenturaNessuna valutazione finora
- Cinemática Vectorial (II)Documento2 pagineCinemática Vectorial (II)Carmen Ruiz DuránNessuna valutazione finora
- Marco Teórico AltimetricoDocumento2 pagineMarco Teórico AltimetricoXiomaraNessuna valutazione finora
- Lain - Instrucciones GeneralesDocumento3 pagineLain - Instrucciones GeneralesAngel Alberto Vargas CalleNessuna valutazione finora
- Planes y Programas Primaria 01-05-14Documento91 paginePlanes y Programas Primaria 01-05-14Guiver RenanNessuna valutazione finora
- NUTRICION-piel DIapositivasDocumento48 pagineNUTRICION-piel DIapositivasErickson Rafael Condor Ames100% (1)
- Cuales Son Los Elementos y Características Importantes Que Se Necesitan para La Conformación de DichaDocumento2 pagineCuales Son Los Elementos y Características Importantes Que Se Necesitan para La Conformación de DichaJustin AlvarezNessuna valutazione finora
- Inventario Local Comercial Casa BlancaDocumento3 pagineInventario Local Comercial Casa BlancaCarolae García67% (6)
- VP-030-00 Protocolo Validación Guias VascularesDocumento21 pagineVP-030-00 Protocolo Validación Guias VascularesedurdoNessuna valutazione finora
- Unidad 2 - Asignacion de RecursosDocumento49 pagineUnidad 2 - Asignacion de RecursosfacundoNessuna valutazione finora
- Fiebre de Origen DessconocidoDocumento9 pagineFiebre de Origen DessconocidoBryan RojasNessuna valutazione finora
- Monografia NeuromarketingDocumento25 pagineMonografia NeuromarketingEmely Bustamante RojasNessuna valutazione finora
- Manual Diseno ConcretoDocumento114 pagineManual Diseno Concretodisenounilibre disenounilibreNessuna valutazione finora
- Adolescentes RebeldesDocumento2 pagineAdolescentes RebeldesAndres BurneoNessuna valutazione finora
- Clasificacion de MaderaDocumento6 pagineClasificacion de MaderaMichael RamirezNessuna valutazione finora
- Breve Historia de WindowsDocumento7 pagineBreve Historia de WindowsMiguelCamachoT-TypeNessuna valutazione finora
- Inventos Colombianos-Ingeneria MecatronicaDocumento1 paginaInventos Colombianos-Ingeneria MecatronicaJaiderk David Corredor MateusNessuna valutazione finora
- Cuaderno de TrabajoDocumento1 paginaCuaderno de TrabajoDámaris Emilce MercadoNessuna valutazione finora
- Articulo Revisión VDRL PDFDocumento20 pagineArticulo Revisión VDRL PDFandres Felipe villamil torresNessuna valutazione finora