Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- UAP Grading Policy Numeric Grade Letter Grade Grade PointDocumento2 pagineUAP Grading Policy Numeric Grade Letter Grade Grade Pointshahnewaz.eeeNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Entrepreneurship - PPTX Version 1 - Copy (Autosaved) (Autosaved) (Autosaved) (Autosaved)Documento211 pagineEntrepreneurship - PPTX Version 1 - Copy (Autosaved) (Autosaved) (Autosaved) (Autosaved)Leona Alicpala67% (3)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Capgemini - 2012-06-13 - 2012 Analyst Day - 3 - Michelin - A Better Way ForwardDocumento12 pagineCapgemini - 2012-06-13 - 2012 Analyst Day - 3 - Michelin - A Better Way ForwardAvanish VermaNessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Managing Errors and ExceptionDocumento12 pagineManaging Errors and ExceptionShanmuka Sreenivas100% (1)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Written Report SampleDocumento16 pagineWritten Report Sampleallanposo3Nessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Flipkart Labels 06 Jul 2022 09 52Documento37 pagineFlipkart Labels 06 Jul 2022 09 52Dharmesh ManiyaNessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- LU 5.1 ElectrochemistryDocumento32 pagineLU 5.1 ElectrochemistryNurAkila Mohd YasirNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Localization On ECG: Myocardial Ischemia / Injury / InfarctionDocumento56 pagineLocalization On ECG: Myocardial Ischemia / Injury / InfarctionduratulfahliaNessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- E-CRM Analytics The Role of Data Integra PDFDocumento310 pagineE-CRM Analytics The Role of Data Integra PDFJohn JiménezNessuna valutazione finora
- Chapter 5 - Principle of Marketing UpdateDocumento58 pagineChapter 5 - Principle of Marketing UpdateKhaing HtooNessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Fertilisation and PregnancyDocumento24 pagineFertilisation and PregnancyLopak TikeNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Land CrabDocumento8 pagineLand CrabGisela Tuk'uchNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Marriage of Figaro LibrettoDocumento64 pagineThe Marriage of Figaro LibrettoTristan BartonNessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Essays of Warren Buffett - Lessons For Corporate America by Lawrence Cunningham - The Rabbit HoleDocumento3 pagineEssays of Warren Buffett - Lessons For Corporate America by Lawrence Cunningham - The Rabbit Holebrijsing0% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Vq40de Service ManualDocumento257 pagineVq40de Service Manualjaumegus100% (4)
- Libya AIP Part1Documento145 pagineLibya AIP Part1Hitham Ghwiel100% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
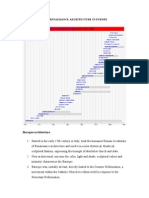
- Post Renaissance Architecture in EuropeDocumento10 paginePost Renaissance Architecture in Europekali_007Nessuna valutazione finora
- CandyDocumento24 pagineCandySjdb FjfbNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Pogon Lifta MRL PDFDocumento128 paginePogon Lifta MRL PDFMašinsko ProjektovanjeNessuna valutazione finora
- Lecture 19 Code Standards and ReviewDocumento27 pagineLecture 19 Code Standards and ReviewAdhil Ashik vNessuna valutazione finora
- Solutions DPP 2Documento3 pagineSolutions DPP 2Tech. VideciousNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- 2015 Student Handbook 16 January 2015Documento66 pagine2015 Student Handbook 16 January 2015John KhanNessuna valutazione finora
- Pediatric Fever of Unknown Origin: Educational GapDocumento14 paginePediatric Fever of Unknown Origin: Educational GapPiegl-Gulácsy VeraNessuna valutazione finora
- Dependent ClauseDocumento28 pagineDependent ClauseAndi Febryan RamadhaniNessuna valutazione finora
- LP Week 8Documento4 pagineLP Week 8WIBER ChapterLampungNessuna valutazione finora
- B-GL-385-009 Short Range Anti-Armour Weapon (Medium)Documento171 pagineB-GL-385-009 Short Range Anti-Armour Weapon (Medium)Jared A. Lang100% (1)
- Communication Skill - Time ManagementDocumento18 pagineCommunication Skill - Time ManagementChấn NguyễnNessuna valutazione finora
- PM 50 Service ManualDocumento60 paginePM 50 Service ManualLeoni AnjosNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- You Can't Blame A FireDocumento8 pagineYou Can't Blame A FireMontana QuarterlyNessuna valutazione finora
- Ships Near A Rocky Coast With Awaiting Landing PartyDocumento2 pagineShips Near A Rocky Coast With Awaiting Landing PartyFouaAj1 FouaAj1Nessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)