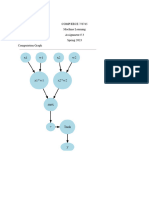
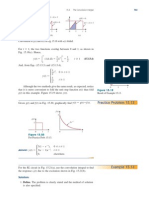
Potrebbero piacerti anche
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Documento5 pagineAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNessuna valutazione finora
- Regularization For Neural NetworkDocumento37 pagineRegularization For Neural NetworkKamakshi SubramaniamNessuna valutazione finora
- Software for Roundoff Analysis of Matrix AlgorithmsDa EverandSoftware for Roundoff Analysis of Matrix AlgorithmsValutazione: 3 su 5 stelle3/5 (1)
- Model - Ipynb - ColaboratoryDocumento3 pagineModel - Ipynb - ColaboratorySHREYANSHU KODILKARNessuna valutazione finora
- Machine Learnin1Documento41 pagineMachine Learnin1Surabhi Kulkarni100% (1)
- # ELG 5255 Applied Machine Learning Fall 2020 # Quiz 1 (Bayesian Decision Theory)Documento6 pagine# ELG 5255 Applied Machine Learning Fall 2020 # Quiz 1 (Bayesian Decision Theory)raosahebNessuna valutazione finora
- Naive Bayes Model With Python 1684166563Documento9 pagineNaive Bayes Model With Python 1684166563mohit c-35Nessuna valutazione finora
- Hand-Printed Character Recognizer Using Neural Networks: By: Shahzad Malik (219762)Documento9 pagineHand-Printed Character Recognizer Using Neural Networks: By: Shahzad Malik (219762)Waleed KingNessuna valutazione finora
- DWMDocumento9 pagineDWMmanasi sawantNessuna valutazione finora
- Random Forest: Implementaciones de Scikit-Learn Sobre QSARDocumento11 pagineRandom Forest: Implementaciones de Scikit-Learn Sobre QSARRichard Jimenez100% (1)
- Fashion MNIST-6Documento10 pagineFashion MNIST-6akif barbaros dikmenNessuna valutazione finora
- DL RecordDocumento37 pagineDL RecordNAWAS HussainNessuna valutazione finora
- Case Study - ClassifierDocumento5 pagineCase Study - ClassifierStuti SinghNessuna valutazione finora
- SclabDocumento36 pagineSclabsarigasemmalaiNessuna valutazione finora
- Chapter FourandfiveDocumento18 pagineChapter FourandfiveSimeon Paul taiwoNessuna valutazione finora
- NEURAL NETWORKS Basics Using MatlabDocumento51 pagineNEURAL NETWORKS Basics Using Matlabsreemd100% (2)
- Rev Insurance Business ReportDocumento4 pagineRev Insurance Business ReportPratigya pathakNessuna valutazione finora
- Implementing KNN Algorithm: Importing LibrariesDocumento6 pagineImplementing KNN Algorithm: Importing LibrariesHarish Kumar PamnaniNessuna valutazione finora
- ML Lab6.Ipynb - ColaboratoryDocumento5 pagineML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Generative AI Binary ClassificationDocumento7 pagineGenerative AI Binary ClassificationCyborg UltraNessuna valutazione finora
- NguyenTrungThinh BT3.3Documento5 pagineNguyenTrungThinh BT3.3Nguyen Trung ThinhNessuna valutazione finora
- Practical - 5 - 52Documento4 paginePractical - 5 - 52Royal EmpireNessuna valutazione finora
- Note 5Documento24 pagineNote 5nuthan manideepNessuna valutazione finora
- NSGA and Optimization DocumentDocumento6 pagineNSGA and Optimization DocumentAnutthara RatnayakeNessuna valutazione finora
- OM Lab CH 17Documento29 pagineOM Lab CH 17FLAVIAN BIMAHNessuna valutazione finora
- Untitled DocumentDocumento5 pagineUntitled Documentdexteradrian28022004Nessuna valutazione finora
- Design Space Process Models With Monte Carlo SimulationDocumento38 pagineDesign Space Process Models With Monte Carlo Simulationsellerm4c1n2Nessuna valutazione finora
- SC Lab File Fayiz PDFDocumento29 pagineSC Lab File Fayiz PDFfayizpNessuna valutazione finora
- Maxbox Starter96 CNN EvaluationDocumento7 pagineMaxbox Starter96 CNN EvaluationMax KleinerNessuna valutazione finora
- Applicable Artificial Intelligence Back Propagation: Academic Session 2022/2023Documento20 pagineApplicable Artificial Intelligence Back Propagation: Academic Session 2022/2023muhammed suhailNessuna valutazione finora
- Pratik Zanke Source CodesDocumento20 paginePratik Zanke Source Codespratik zankeNessuna valutazione finora
- Quality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Documento15 pagineQuality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Giuseppe D'AngeloNessuna valutazione finora
- Exercise (Python)Documento2 pagineExercise (Python)asNessuna valutazione finora
- Data Science Chapitre 2Documento98 pagineData Science Chapitre 2Leonel SkaNessuna valutazione finora
- # ELG 5255 Applied Machine Learning Fall 2020 # Assignment 3 (Multivariate Method)Documento8 pagine# ELG 5255 Applied Machine Learning Fall 2020 # Assignment 3 (Multivariate Method)raosahebNessuna valutazione finora
- Data Mining - Weka 3.6.0Documento5 pagineData Mining - Weka 3.6.0Navee JayakodyNessuna valutazione finora
- Exp4 - Supervised LearningDocumento10 pagineExp4 - Supervised LearningmnbatrawiNessuna valutazione finora
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocumento38 pagineC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Week16 N9Documento3 pagineWeek16 N920131A05N9 SRUTHIK THOKALANessuna valutazione finora
- Hands-On Assignment II Solution: Pulse Code Modulation: ReadingDocumento6 pagineHands-On Assignment II Solution: Pulse Code Modulation: ReadingnongonNessuna valutazione finora
- Artificial Neural NetworkDocumento113 pagineArtificial Neural Networkharith danishNessuna valutazione finora
- Gem 101Documento113 pagineGem 101Abraham OmomhenleNessuna valutazione finora
- MINI PROJECT - MergedDocumento8 pagineMINI PROJECT - Mergedbhanucse16Nessuna valutazione finora
- Lecture 04Documento20 pagineLecture 04Tev WallaceNessuna valutazione finora
- Experiment: Forces in Plane Redundant TrussDocumento8 pagineExperiment: Forces in Plane Redundant TrussEdmund TiewNessuna valutazione finora
- Architecture HandbookDocumento19 pagineArchitecture HandbookAnonymous fqvjeG008BNessuna valutazione finora
- Saurabh Verma 9919102005Documento11 pagineSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Lecture Note 11 (2014 S)Documento42 pagineLecture Note 11 (2014 S)Lily EisenringNessuna valutazione finora
- Scikit Learn What Were CoveringDocumento15 pagineScikit Learn What Were CoveringRaiyan ZannatNessuna valutazione finora
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Documento9 pagineML0101EN Clas K Nearest Neighbors CustCat Py v1Rajat SolankiNessuna valutazione finora
- Advanced Statistics-ProjectDocumento16 pagineAdvanced Statistics-Projectvivek rNessuna valutazione finora
- Machine LearningDocumento19 pagineMachine Learningjohnny brooksNessuna valutazione finora
- Multilayer PerceptronDocumento11 pagineMultilayer PerceptronDesya EspriliaNessuna valutazione finora
- 3 Salazar Francisco Improving - Accuracy - Using - ConvolutionsDocumento14 pagine3 Salazar Francisco Improving - Accuracy - Using - ConvolutionsFrank SDNessuna valutazione finora
- Homework 4Documento9 pagineHomework 4alexNessuna valutazione finora
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocumento18 pagine26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNessuna valutazione finora
- C2M4 - Assignment: 1 Cox Proportional Hazards and Random Survival ForestsDocumento18 pagineC2M4 - Assignment: 1 Cox Proportional Hazards and Random Survival ForestsSarah MendesNessuna valutazione finora
- + Richard C. Jaeger, Travis N. Blalock "Microelectronic Circuit Design", Third Edition MC - Graw Hill, 2010Documento1 pagina+ Richard C. Jaeger, Travis N. Blalock "Microelectronic Circuit Design", Third Edition MC - Graw Hill, 2010Zy AnNessuna valutazione finora
- Solu TestDocumento6 pagineSolu TestZy AnNessuna valutazione finora
- EE341 Midterm PDFDocumento4 pagineEE341 Midterm PDFZy AnNessuna valutazione finora
- Howto Use A Spice Model File in Orcad 10.5 DemoDocumento9 pagineHowto Use A Spice Model File in Orcad 10.5 DemoZy AnNessuna valutazione finora
- Chapter FiveDocumento28 pagineChapter FiveZy AnNessuna valutazione finora
- Grade 6 ProjAN Posttest-PrintDocumento8 pagineGrade 6 ProjAN Posttest-PrintYa naNessuna valutazione finora
- List of Mobile Phones Supported OTG Function PDFDocumento7 pagineList of Mobile Phones Supported OTG Function PDFCarlos Manuel De Los Santos PerezNessuna valutazione finora
- General Instruction of UopDocumento3 pagineGeneral Instruction of UopwasimNessuna valutazione finora
- Social Dimensions of ComputerisationDocumento6 pagineSocial Dimensions of Computerisationgourav rathore100% (1)
- Ibm Qradar DGDocumento7 pagineIbm Qradar DGMuhammad TalhaNessuna valutazione finora
- A Branch-And-Bound Algorithm For The Time-Dependent Travelling Salesman ProblemDocumento11 pagineA Branch-And-Bound Algorithm For The Time-Dependent Travelling Salesman ProblemDaniel FernándezNessuna valutazione finora
- Desain Layout Mobil Toko Laundry SepatuDocumento7 pagineDesain Layout Mobil Toko Laundry SepatuKlinikrifdaNessuna valutazione finora
- Gas Reservoir Engineering Application ToolkitDocumento20 pagineGas Reservoir Engineering Application Toolkitnishant41288100% (1)
- 01 - Cisco ISE Profiling Reporting - Part 1Documento1 pagina01 - Cisco ISE Profiling Reporting - Part 1Nguyen LeNessuna valutazione finora
- 1st Project Rubric in Math 10Documento1 pagina1st Project Rubric in Math 10JILIANNEYSABELLE MONTONNessuna valutazione finora
- In The Design of A Relational Database Management SystemDocumento5 pagineIn The Design of A Relational Database Management SystemKumbham AbhijitNessuna valutazione finora
- FsDocumento8 pagineFskrishnacfp232Nessuna valutazione finora
- Robotic Process AutomationDocumento6 pagineRobotic Process AutomationTanushree KalitaNessuna valutazione finora
- V2X SurveyDocumento37 pagineV2X SurveyAniket panditNessuna valutazione finora
- Sub-GHz Wi-SUN Introduction v2.0Documento37 pagineSub-GHz Wi-SUN Introduction v2.0Xiong ChwNessuna valutazione finora
- 5713 How Microsoft Moves Their SAP Landscape Into AzureDocumento41 pagine5713 How Microsoft Moves Their SAP Landscape Into AzureHaitham DesokiNessuna valutazione finora
- QuestionDocumento6 pagineQuestionVj Sudhan100% (3)
- Underwater ROV Control SystemDocumento20 pagineUnderwater ROV Control SystemPhanNamNessuna valutazione finora
- Agc 150 Designers Handbook 4189341188 UkDocumento398 pagineAgc 150 Designers Handbook 4189341188 UkMaicon ZagonelNessuna valutazione finora
- Nike CaseDocumento21 pagineNike CaseAnksNessuna valutazione finora
- Research Paper On Support Vector MachineDocumento6 pagineResearch Paper On Support Vector Machinepoypdibkf100% (1)
- Keyboard Shortcuts Windows 7 and 8Documento3 pagineKeyboard Shortcuts Windows 7 and 8Feral ErraticNessuna valutazione finora
- Topic Numarical Lasd ADocumento4 pagineTopic Numarical Lasd AMR.MUSAAB ALMAIDANNessuna valutazione finora
- Math Lecture 1Documento37 pagineMath Lecture 1Mohamed A. TaherNessuna valutazione finora
- Datasheet Axis q1656 Le Box Camera en US 424540Documento3 pagineDatasheet Axis q1656 Le Box Camera en US 424540petereriksson.rosenforsNessuna valutazione finora
- Question Papers of Two Year M. Tech I Semester Regular Examinations April - 2012Documento29 pagineQuestion Papers of Two Year M. Tech I Semester Regular Examinations April - 2012mdphilipNessuna valutazione finora
- TutoriaDocumento351 pagineTutoriasakunthalapcsNessuna valutazione finora
- 50 UNIX - Linux Sysadmin TutorialsDocumento4 pagine50 UNIX - Linux Sysadmin Tutorialshammet217Nessuna valutazione finora
- Lic Unit 1 (1) eDocumento114 pagineLic Unit 1 (1) eganeshNessuna valutazione finora
- Ict Applications - Satellite Systems: Grade 10Documento16 pagineIct Applications - Satellite Systems: Grade 10ruhiyaNessuna valutazione finora