Potrebbero piacerti anche
- HP Scanjet N9120 (Service Manual) PDFDocumento394 pagineHP Scanjet N9120 (Service Manual) PDFcamilohto80% (5)
- Zgouras Catherine Team Together 1 Teachers BookDocumento257 pagineZgouras Catherine Team Together 1 Teachers Booknata86% (7)
- En 1993 09Documento160 pagineEn 1993 09Vio ChiNessuna valutazione finora
- 2.2 Exercises With Matlab: 2.2.1 Standard Normal DistributionDocumento9 pagine2.2 Exercises With Matlab: 2.2.1 Standard Normal Distributionabymani004Nessuna valutazione finora
- Unit 4 - Continuous Random VariablesDocumento35 pagineUnit 4 - Continuous Random VariablesShouq AbdullahNessuna valutazione finora
- Stat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.eduDocumento35 pagineStat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.edujamesyuNessuna valutazione finora
- Example 3.2: Given Probability DistributionDocumento38 pagineExample 3.2: Given Probability Distributionloc1409Nessuna valutazione finora
- 04 BasisDocumento8 pagine04 BasishariNessuna valutazione finora
- Chap 004Documento33 pagineChap 004Evan AdrielNessuna valutazione finora
- Much As Much As Dis Tri Buci OnesDocumento75 pagineMuch As Much As Dis Tri Buci Onesjccr185Nessuna valutazione finora
- Chap004 - Sao ChépDocumento49 pagineChap004 - Sao ChépLan PhanNessuna valutazione finora
- Numerical Optimization in MatlabDocumento25 pagineNumerical Optimization in MatlabMahfuzulhoq ChowdhuryNessuna valutazione finora
- Numerical MethodsDocumento23 pagineNumerical Methodsarjay plataNessuna valutazione finora
- Module 5 - Stat. - Prob.Documento4 pagineModule 5 - Stat. - Prob.Nicole MendozaNessuna valutazione finora
- Quantitative Methods in Linguistics - Lecture 3: Adrian Brasoveanu March 30, 2014Documento51 pagineQuantitative Methods in Linguistics - Lecture 3: Adrian Brasoveanu March 30, 2014Samuel Alfonzo Gil BarcoNessuna valutazione finora
- Lecture-13 - ESO208 - Aug 31 - 2022Documento28 pagineLecture-13 - ESO208 - Aug 31 - 2022Imad ShaikhNessuna valutazione finora
- Statistics For ManagememtDocumento152 pagineStatistics For Managememttowfik sefaNessuna valutazione finora
- Numericla MethodDocumento45 pagineNumericla Methodsubrozn GamerNessuna valutazione finora
- Bayesian Classifier Implementation Using MATLABDocumento21 pagineBayesian Classifier Implementation Using MATLABShabeeb Ali OruvangaraNessuna valutazione finora
- Sergios Theodoridis Konstantinos KoutroumbasDocumento80 pagineSergios Theodoridis Konstantinos KoutroumbasKumarNessuna valutazione finora
- Fitting Statistical Models With PROC MCMC: Conference PaperDocumento27 pagineFitting Statistical Models With PROC MCMC: Conference PaperDimitriosNessuna valutazione finora
- 1 Probability DistributionDocumento24 pagine1 Probability DistributionDominic AguirreNessuna valutazione finora
- 01 - Descriptive Statistics - PrintDocumento36 pagine01 - Descriptive Statistics - PrintPhoeurn ChanarunNessuna valutazione finora
- Machine Learning in Practice: SdmimdDocumento113 pagineMachine Learning in Practice: SdmimdTangirala AshwiniNessuna valutazione finora
- Probability PDFDocumento30 pagineProbability PDFeetahaNessuna valutazione finora
- Gaussian Probability Density Functions: Properties and Error CharacterizationDocumento30 pagineGaussian Probability Density Functions: Properties and Error CharacterizationNizar SaadiNessuna valutazione finora
- Final 2006Documento15 pagineFinal 2006Muhammad MurtazaNessuna valutazione finora
- Numerical Analysis II PDFDocumento115 pagineNumerical Analysis II PDFAlaa GhaziNessuna valutazione finora
- Sergios Theodoridis Konstantinos KoutroumbasDocumento76 pagineSergios Theodoridis Konstantinos KoutroumbasIshwar MhtNessuna valutazione finora
- Assignment 2Documento2 pagineAssignment 2NitinSrivastavaNessuna valutazione finora
- 8.a. DistributionsDocumento28 pagine8.a. Distributionsromi moriNessuna valutazione finora
- CS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text DataDocumento35 pagineCS109/Stat121/AC209/E-109 Data Science: Bayesian Methods Continued, Text Dataankit devNessuna valutazione finora
- Normal DistributionDocumento36 pagineNormal DistributionRajesh JayachandranNessuna valutazione finora
- Physics Through Computational Thinking: Micro Lecture: Fixed Points in One Dimension Dymanical SystemsDocumento7 paginePhysics Through Computational Thinking: Micro Lecture: Fixed Points in One Dimension Dymanical SystemsWilson Bros.Nessuna valutazione finora
- Chapter # 4 Measures of Dispersion: Shahid MehmoodDocumento21 pagineChapter # 4 Measures of Dispersion: Shahid MehmoodMohsin AliNessuna valutazione finora
- Smart Antennas: Gudlavalleru Engineering CollegeDocumento31 pagineSmart Antennas: Gudlavalleru Engineering CollegeSAI PRATHYUSHA NIMMAGADDDANessuna valutazione finora
- BUSN 2429 CH 5 ExampleDocumento10 pagineBUSN 2429 CH 5 ExampleThắng ĐoànNessuna valutazione finora
- Calculus of A Single Variable Hybrid Early Transcendental Functions 6Th Edition Larso Solutions Manual Full Chapter PDFDocumento36 pagineCalculus of A Single Variable Hybrid Early Transcendental Functions 6Th Edition Larso Solutions Manual Full Chapter PDFcarol.alvarez992100% (14)
- Calculus of A Single Variable Hybrid Early Transcendental Functions 6th Edition Larso Solutions Manual 1Documento36 pagineCalculus of A Single Variable Hybrid Early Transcendental Functions 6th Edition Larso Solutions Manual 1lisarodriguezjabyorwmtk100% (24)
- Lecture (8) DerivativesDocumento27 pagineLecture (8) Derivativesmhamadhawlery16Nessuna valutazione finora
- ProblemsDocumento46 pagineProblemsgaur1234Nessuna valutazione finora
- MATE2A2 Introduction Fourier SeriesDocumento16 pagineMATE2A2 Introduction Fourier Seriesportia733hhNessuna valutazione finora
- Concepts in Calculus I - Beta Version - 2011 - Miklos Bona - Sergei ShabanovDocumento188 pagineConcepts in Calculus I - Beta Version - 2011 - Miklos Bona - Sergei ShabanovThomaz SennaNessuna valutazione finora
- (Ch4) - Interpolation-MaterialDocumento59 pagine(Ch4) - Interpolation-MaterialSky FireNessuna valutazione finora
- Sharp Statistical Tools Statistics For Extremes: Georg LindgrenDocumento48 pagineSharp Statistical Tools Statistics For Extremes: Georg LindgrenThalles Giangiarulo de AguiarNessuna valutazione finora
- Loss Distributions (Burnecki)Documento19 pagineLoss Distributions (Burnecki)LapaPereiraNessuna valutazione finora
- CENTRAL TENDENCY MEASURES Lectures 3+4+5Documento35 pagineCENTRAL TENDENCY MEASURES Lectures 3+4+5Stefan DobreNessuna valutazione finora
- Discussion 3 SupervisedDocumento14 pagineDiscussion 3 SupervisedPavan KumarNessuna valutazione finora
- Lec 12Documento10 pagineLec 12stathiss11Nessuna valutazione finora
- Lec 3 ClassDocumento16 pagineLec 3 ClassKarl HelbiroNessuna valutazione finora
- MAT2001-Statistics For Engineers Statistics For EngineersDocumento24 pagineMAT2001-Statistics For Engineers Statistics For EngineersCathrine CruzNessuna valutazione finora
- Kuliah - FEATURE SELECTION - Maret2015Documento31 pagineKuliah - FEATURE SELECTION - Maret2015iv jumat klompokNessuna valutazione finora
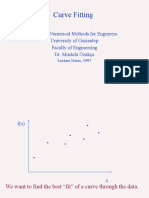
- Curve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaDocumento171 pagineCurve Fitting: ME 537 Numerical Methods For Engineers University of Gaziantep Faculty of Engineering Dr. Mustafa ÖzakçaAbdullah Emirhan AydınNessuna valutazione finora
- Calculus of A Single Variable Early Transcendental Functions 6Th Edition Larson Solutions Manual Full Chapter PDFDocumento36 pagineCalculus of A Single Variable Early Transcendental Functions 6Th Edition Larson Solutions Manual Full Chapter PDFcarol.alvarez992100% (13)
- Calculus of A Single Variable Early Transcendental Functions 6th Edition Larson Solutions Manual 1Documento262 pagineCalculus of A Single Variable Early Transcendental Functions 6th Edition Larson Solutions Manual 1mark100% (33)
- Questions Data EntryDocumento6 pagineQuestions Data EntryOtaigbe PaulNessuna valutazione finora
- Curve Fitting CH 3Documento11 pagineCurve Fitting CH 3Coder DNessuna valutazione finora
- MIT18 385JF14 BabyNormlFmsDocumento15 pagineMIT18 385JF14 BabyNormlFmsMARCO ANTONIO RAMOS ALVANessuna valutazione finora
- Genetic Algorithms TutorialsDocumento29 pagineGenetic Algorithms TutorialsMustafamna Al SalamNessuna valutazione finora
- Information Theoretic Approach To Minimization of Logic Expressions, Trees, Decision Diagrams and CircuitsDocumento71 pagineInformation Theoretic Approach To Minimization of Logic Expressions, Trees, Decision Diagrams and CircuitsAnjan KumarNessuna valutazione finora
- Point Estimation: Statistics (MAST20005) & Elements of Statistics (MAST90058) Semester 2, 2018Documento12 paginePoint Estimation: Statistics (MAST20005) & Elements of Statistics (MAST90058) Semester 2, 2018Anonymous na314kKjOANessuna valutazione finora
- Inverse Problem Theory: Methods for Data Fitting and Model Parameter EstimationDa EverandInverse Problem Theory: Methods for Data Fitting and Model Parameter EstimationNessuna valutazione finora
- Digital Signal Processing (DSP) with Python ProgrammingDa EverandDigital Signal Processing (DSP) with Python ProgrammingNessuna valutazione finora
- AE RF Over FiberDocumento13 pagineAE RF Over FiberĐặng Minh TháiNessuna valutazione finora
- S. R. Abdollahi, H.S. Al-Raweshidy, S. Mehdi Fakhraie, and R. NilavalanDocumento1 paginaS. R. Abdollahi, H.S. Al-Raweshidy, S. Mehdi Fakhraie, and R. NilavalanĐặng Minh TháiNessuna valutazione finora
- G/G/1 Queueing Systems: John C.S. LuiDocumento20 pagineG/G/1 Queueing Systems: John C.S. LuiĐặng Minh TháiNessuna valutazione finora
- BTI Company ProfileDocumento14 pagineBTI Company ProfileĐặng Minh TháiNessuna valutazione finora
- Nex MCOM 13.1 Installation GuideDocumento1 paginaNex MCOM 13.1 Installation GuideĐặng Minh TháiNessuna valutazione finora
- Network Troubleshooting and Optimization With Nemo ToolsDocumento73 pagineNetwork Troubleshooting and Optimization With Nemo ToolsĐặng Minh TháiNessuna valutazione finora
- Mpls22sg Vol.2Documento0 pagineMpls22sg Vol.2Đặng Minh TháiNessuna valutazione finora
- Toftejorg TZ-75 Rotary Jet Head - Portable: Fast, Effective Impact CleaningDocumento3 pagineToftejorg TZ-75 Rotary Jet Head - Portable: Fast, Effective Impact CleaningSamo SpontanostNessuna valutazione finora
- Formulae HandbookDocumento60 pagineFormulae Handbookmgvpalma100% (1)
- Ab 2023Documento5 pagineAb 2023Cristelle Estrada-Romuar JurolanNessuna valutazione finora
- Hydrology Report at CH-9+491Documento3 pagineHydrology Report at CH-9+491juliyet strucNessuna valutazione finora
- Diltoids Numberletter Puzzles Activities Promoting Classroom Dynamics Group Form - 38486Documento5 pagineDiltoids Numberletter Puzzles Activities Promoting Classroom Dynamics Group Form - 38486sinirsistemiNessuna valutazione finora
- Manual HobartDocumento39 pagineManual HobartВолодимир БроNessuna valutazione finora
- Use The Analysis ToolPak To Perform Complex Data Analysis - Excel - OfficeDocumento5 pagineUse The Analysis ToolPak To Perform Complex Data Analysis - Excel - OfficedakingNessuna valutazione finora
- Surge Protection Devices CatalogueDocumento134 pagineSurge Protection Devices CatalogueNguyen Doan QuyetNessuna valutazione finora
- Drsent PT Practice Sba OspfDocumento10 pagineDrsent PT Practice Sba OspfEnergyfellowNessuna valutazione finora
- Permanent Magnet Motor Surface Drive System: Maximize Safety and Energy Efficiency of Progressing Cavity Pumps (PCPS)Documento2 paginePermanent Magnet Motor Surface Drive System: Maximize Safety and Energy Efficiency of Progressing Cavity Pumps (PCPS)Carla Ayelen Chorolque BorgesNessuna valutazione finora
- Mining Discriminative Patterns To Predict Health Status For Cardiopulmonary PatientsDocumento56 pagineMining Discriminative Patterns To Predict Health Status For Cardiopulmonary Patientsaniltatti25Nessuna valutazione finora
- Kowalkowskietal 2023 Digital Service Innovationin B2 BDocumento48 pagineKowalkowskietal 2023 Digital Service Innovationin B2 BAdolf DasslerNessuna valutazione finora
- Sensor de Temperatura e Umidade CarelDocumento1 paginaSensor de Temperatura e Umidade CarelMayconLimaNessuna valutazione finora
- National Pension System (NPS) - Subscriber Registration FormDocumento3 pagineNational Pension System (NPS) - Subscriber Registration FormPratikJagtapNessuna valutazione finora
- Plastic Hinge Length and Depth For Piles in Marine Oil Terminals Including Nonlinear Soil PropertiesDocumento10 paginePlastic Hinge Length and Depth For Piles in Marine Oil Terminals Including Nonlinear Soil PropertiesGopu RNessuna valutazione finora
- Er6f Abs 2013Documento134 pagineEr6f Abs 2013Calibmatic JobNessuna valutazione finora
- Energy BodiesDocumento1 paginaEnergy BodiesannoyingsporeNessuna valutazione finora
- Perilaku Prososial Sebagai Prediktor Status Teman Sebaya Pada RemajaDocumento9 paginePerilaku Prososial Sebagai Prediktor Status Teman Sebaya Pada RemajaMemet GoNessuna valutazione finora
- Mba633 Road To Hell Case AnalysisDocumento3 pagineMba633 Road To Hell Case AnalysisAditi VarshneyNessuna valutazione finora
- ANNEXESDocumento6 pagineANNEXESKyzer Calix LaguitNessuna valutazione finora
- Cross Border Data Transfer Consent Form - DecemberDocumento3 pagineCross Border Data Transfer Consent Form - DecemberFIDELIS MUSEMBINessuna valutazione finora
- Fiedler1950 - A Comparison of Therapeutic Relationships in PsychoanalyticDocumento10 pagineFiedler1950 - A Comparison of Therapeutic Relationships in PsychoanalyticAnca-Maria CovaciNessuna valutazione finora
- n4 HandoutDocumento2 paginen4 HandoutFizzerNessuna valutazione finora
- Pamphlet 89 Chlorine Scrubbing SystemsDocumento36 paginePamphlet 89 Chlorine Scrubbing Systemshfguavita100% (4)
- 1.2 The Basic Features of Employee's Welfare Measures Are As FollowsDocumento51 pagine1.2 The Basic Features of Employee's Welfare Measures Are As FollowsUddipta Bharali100% (1)
- Angle ModulationDocumento26 pagineAngle ModulationAtish RanjanNessuna valutazione finora
- Antenna Systems - Standard Format For Digitized Antenna PatternsDocumento32 pagineAntenna Systems - Standard Format For Digitized Antenna PatternsyokomaNessuna valutazione finora