Potrebbero piacerti anche
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Audio On ARM Cortex-M ProcessorsDocumento5 pagineAudio On ARM Cortex-M ProcessorsravigobiNessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- A Comparative Runtime Analysis of Heuristic AlgorithmsDocumento18 pagineA Comparative Runtime Analysis of Heuristic AlgorithmsravigobiNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Analyzing HardFaults On Cortex-M CPUDocumento12 pagineAnalyzing HardFaults On Cortex-M CPUravigobiNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Streaming Linear Regression On Spark MLlib and MOADocumento4 pagineStreaming Linear Regression On Spark MLlib and MOAravigobiNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Spark On Hadoop Vs MPI OpenMP On BeowulfDocumento10 pagineSpark On Hadoop Vs MPI OpenMP On BeowulfravigobiNessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Big O NotationsDocumento19 pagineBig O NotationsravigobiNessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Complexity Measures For Meta-LearningDocumento12 pagineComplexity Measures For Meta-LearningravigobiNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Automotive Big DataDocumento10 pagineAutomotive Big DataravigobiNessuna valutazione finora
- Cordillera Administrative Regional Office: Application Form Certificate of Need For New General HospitalsDocumento2 pagineCordillera Administrative Regional Office: Application Form Certificate of Need For New General HospitalsRocky Montañer0% (1)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- RasunaDocumento13 pagineRasunaAlen RendakNessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- AAPCDocumento10 pagineAAPCprincyphilip67% (3)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Oebps 21Documento91 pagineOebps 21Max Laban Seminario0% (1)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Registration of Patient Transport VehicleDocumento2 pagineRegistration of Patient Transport VehicleMenGuitar100% (1)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
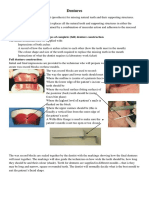
- DenturesDocumento3 pagineDenturesMohammadNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- History of Nursing 2nd WeekDocumento71 pagineHistory of Nursing 2nd WeekjeffrejrNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Colon Surgery SponsorshipDocumento2 pagineColon Surgery SponsorshipAlexisRoyENessuna valutazione finora
- MIS Project ReportDocumento15 pagineMIS Project ReportAbhishek GoyalNessuna valutazione finora
- Functional in Medical English: Tonang Dwi ArdyantoDocumento28 pagineFunctional in Medical English: Tonang Dwi ArdyantoAsri HandayaniNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Middle East Architect 2013 07 PDFDocumento60 pagineMiddle East Architect 2013 07 PDFmif7Nessuna valutazione finora
- Surgical Management of Acute CholecystitisDocumento17 pagineSurgical Management of Acute Cholecystitisgrayburn_1Nessuna valutazione finora
- Quiz PeriDocumento3 pagineQuiz PeriAlina Juliana MagopetNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Final Test 51 TNDocumento3 pagineFinal Test 51 TNosamyy100% (1)
- NABH Accreditation Standards For Ayurveda ClinicsDocumento59 pagineNABH Accreditation Standards For Ayurveda Clinicsabhimanyu nehraNessuna valutazione finora
- Medicaid Provider Enrollment Guide 2011Documento18 pagineMedicaid Provider Enrollment Guide 2011Patrick PerezNessuna valutazione finora
- Results For Internist: Selected Sort/FiltersDocumento9 pagineResults For Internist: Selected Sort/FiltersmanoojvsNessuna valutazione finora
- 4 F Guevara Muñoz B3 U2Documento15 pagine4 F Guevara Muñoz B3 U2CHRISTIAN GUEVARANessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Caring For The Heart Failure Patient: Contemporary Nursing InterventionsDocumento8 pagineCaring For The Heart Failure Patient: Contemporary Nursing Interventionsnurulanisa0703Nessuna valutazione finora
- Temperature MeasurementDocumento5 pagineTemperature Measurementl10n_ass100% (1)
- Nursing PhilosophyDocumento6 pagineNursing Philosophyapi-541532244Nessuna valutazione finora
- Inspector General ReportDocumento48 pagineInspector General ReportDenise PridgenNessuna valutazione finora
- Certificate of BirthDocumento1 paginaCertificate of BirthMilan ComputerNessuna valutazione finora
- Organ Donation ProcessDocumento1 paginaOrgan Donation ProcessinforumdocsNessuna valutazione finora
- Script and PPT IPSGDocumento19 pagineScript and PPT IPSGAudreey Gwen50% (2)
- Psych Process RecordingDocumento7 paginePsych Process RecordingHaon AnasuNessuna valutazione finora
- EnteralDocumento5 pagineEnteralSahil DhamijaNessuna valutazione finora
- Payment PDFDocumento35 paginePayment PDFLauraMariaAndresanNessuna valutazione finora
- Lim R (2018) Benefits of Quiet Time Interventions in The Intensive Care Unit - A Literature Review. Nursing Standard. 32, 30, 41-48.Documento8 pagineLim R (2018) Benefits of Quiet Time Interventions in The Intensive Care Unit - A Literature Review. Nursing Standard. 32, 30, 41-48.Neesha MNessuna valutazione finora
- ImplantDocumento4 pagineImplantMohamed KudaihNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)