Potrebbero piacerti anche
- CS 12-Pages-1-27Documento27 pagineCS 12-Pages-1-27Marc Jairro GajudoNessuna valutazione finora
- 11 Class Computer Science (Session 2022-23) : Que1: Multiple Choice QuestionsDocumento3 pagine11 Class Computer Science (Session 2022-23) : Que1: Multiple Choice QuestionsinderpreetkaurNessuna valutazione finora
- Computer Science IADocumento6 pagineComputer Science IAjessicaNessuna valutazione finora
- 15CS31TDocumento114 pagine15CS31TSurya RNessuna valutazione finora
- CompilerDocumento6 pagineCompilerAayush RanaNessuna valutazione finora
- Cdee Computer Science Upload 2015SM 3Documento27 pagineCdee Computer Science Upload 2015SM 3Nikodimos EndeshawNessuna valutazione finora
- CC QuestionsDocumento9 pagineCC QuestionsjagdishNessuna valutazione finora
- C Language Is A General Purpose and Structured Pragramming Langauge Developed byDocumento12 pagineC Language Is A General Purpose and Structured Pragramming Langauge Developed byJayagowri CheluriNessuna valutazione finora
- Task 1Documento7 pagineTask 1TJ MilneNessuna valutazione finora
- A Tale of Two Tests STANAG and CEFRDocumento48 pagineA Tale of Two Tests STANAG and CEFRMisael GonçalvesNessuna valutazione finora
- BCA 2nd Sem Assignment 2016-17Documento18 pagineBCA 2nd Sem Assignment 2016-17duffuchimpsNessuna valutazione finora
- 4CP0 02 Pef 20190822Documento8 pagine4CP0 02 Pef 20190822Neily WimalasiriNessuna valutazione finora
- PRP411 Fa1Documento8 paginePRP411 Fa1Yes SurNessuna valutazione finora
- 19CS403 PYTHON LAB EXAM QuestionsDocumento7 pagine19CS403 PYTHON LAB EXAM QuestionsSharan ShettyNessuna valutazione finora
- 4 IT415 Requirement Based Test GenerationDocumento14 pagine4 IT415 Requirement Based Test GenerationKishan Pujara0% (1)
- Chapter FourDocumento13 pagineChapter Fourn64157257Nessuna valutazione finora
- CT 1 - B Answer KeyDocumento6 pagineCT 1 - B Answer Keylalith jettyNessuna valutazione finora
- Language ProcessorsDocumento41 pagineLanguage ProcessorsjaydipNessuna valutazione finora
- Krishna Kanta University BCA Examination, 2014: IiandiquiDocumento5 pagineKrishna Kanta University BCA Examination, 2014: IiandiquiMridupaban DuttaNessuna valutazione finora
- Data Types Used in C-Programming: Data Type Size in Bytes Storage Range RemarksDocumento4 pagineData Types Used in C-Programming: Data Type Size in Bytes Storage Range Remarkssadam hussain90Nessuna valutazione finora
- Problem Solving in C and Python: Programming Exercises and Solutions, Part 1Da EverandProblem Solving in C and Python: Programming Exercises and Solutions, Part 1Valutazione: 4.5 su 5 stelle4.5/5 (2)
- 14 Mca or C ProgrammingDocumento1 pagina14 Mca or C ProgrammingSRINIVASA RAO GANTA100% (1)
- Chapter 3Documento42 pagineChapter 3angawNessuna valutazione finora
- Compiler Construction AsigDocumento1 paginaCompiler Construction AsigAdeel DurraniNessuna valutazione finora
- CH-9 Programming With Python Class 7thDocumento1 paginaCH-9 Programming With Python Class 7thLOVEKARANNessuna valutazione finora
- Complier Construction Principles and Practice: InstructionsDocumento3 pagineComplier Construction Principles and Practice: InstructionsАлександр ДанюкNessuna valutazione finora
- Alevel CDocumento402 pagineAlevel CSyed A H AndrabiNessuna valutazione finora
- Co DataDocumento76 pagineCo DataTarun BeheraNessuna valutazione finora
- C Theory and QuestionsDocumento11 pagineC Theory and QuestionssurajkaulNessuna valutazione finora
- SDT September 2015 Exam MS FinalDocumento15 pagineSDT September 2015 Exam MS FinalKennedy Bernardo PhiriNessuna valutazione finora
- Data Types in Java: Multiple Choice Questions (Tick The Correct Answers)Documento12 pagineData Types in Java: Multiple Choice Questions (Tick The Correct Answers)cr4satyajit100% (1)
- Language Fundamentals C# PDFDocumento46 pagineLanguage Fundamentals C# PDFshanu_agarwal89100% (2)
- 7BCE1C1 - Programming in CDocumento97 pagine7BCE1C1 - Programming in Ckgf0237Nessuna valutazione finora
- C P Notes Submitted By: Dewanand Giri BSC - CSIT First Sem Sec A Roll:8 Submitted To: Prof - Mohan BhandariDocumento27 pagineC P Notes Submitted By: Dewanand Giri BSC - CSIT First Sem Sec A Roll:8 Submitted To: Prof - Mohan BhandariDewanand GiriNessuna valutazione finora
- Chapter 3 - Syntax AnalysisDocumento160 pagineChapter 3 - Syntax Analysissamlegend2217Nessuna valutazione finora
- C Programming QuestionsDocumento15 pagineC Programming Questionsshreyarajput92542Nessuna valutazione finora
- Lesson1 C Introduction1Documento13 pagineLesson1 C Introduction1gcerameshNessuna valutazione finora
- C Programming 3Documento28 pagineC Programming 3Kavya MamillaNessuna valutazione finora
- s2 C Programming KTU 2019 SyllabusDocumento9 pagines2 C Programming KTU 2019 SyllabusShaiju PaulNessuna valutazione finora
- THEORY of CDocumento56 pagineTHEORY of CPravin Prakash AdivarekarNessuna valutazione finora
- 3) F.Y.B.B.A. (C.A.) - Sem - I - LabBook - 2019 - Pattern - 08.07.2021Documento87 pagine3) F.Y.B.B.A. (C.A.) - Sem - I - LabBook - 2019 - Pattern - 08.07.2021AKSHAY GHADGENessuna valutazione finora
- C in WordDocumento107 pagineC in WordPriya ShettyNessuna valutazione finora
- C ProgrammingDocumento14 pagineC ProgrammingSakib MuhaiminNessuna valutazione finora
- Lesson2 - Language Fundamentals1Documento13 pagineLesson2 - Language Fundamentals1Pavan VutukuruNessuna valutazione finora
- Programming Languages SYLLABUSDocumento2 pagineProgramming Languages SYLLABUSHema AroraNessuna valutazione finora
- C Programming Keywords and Identifiers Character SetDocumento26 pagineC Programming Keywords and Identifiers Character Setamandeep651Nessuna valutazione finora
- C Introduction NewDocumento21 pagineC Introduction NewJyoti Kundnani ChandnaniNessuna valutazione finora
- CD Previous QA 2010Documento64 pagineCD Previous QA 2010SagarNessuna valutazione finora
- C - Language by PrashanthDocumento37 pagineC - Language by PrashanthPrashanthNessuna valutazione finora
- The BCS Professional Examination Certificate April 2005 Examiners' ReportDocumento17 pagineThe BCS Professional Examination Certificate April 2005 Examiners' ReportOzioma IhekwoabaNessuna valutazione finora
- C Programming Keywords and IdentifiersDocumento47 pagineC Programming Keywords and IdentifiersJaydeep SinghNessuna valutazione finora
- MCSL-017 C and Assembly Language Programming LabDocumento16 pagineMCSL-017 C and Assembly Language Programming LabSumit RanjanNessuna valutazione finora
- Quantitative Reasoning Practice TestDocumento41 pagineQuantitative Reasoning Practice TestInac ArqNessuna valutazione finora
- prob-F-Talent 2021 Rehearsal - A.LEO Number SystemDocumento4 pagineprob-F-Talent 2021 Rehearsal - A.LEO Number SystemHuy Nguyen BaNessuna valutazione finora
- 5 - NPL - String in C#Documento46 pagine5 - NPL - String in C#binhkatekun2002Nessuna valutazione finora
- Fundamentals of Microcontroller & Its Application: Unit-IiiDocumento30 pagineFundamentals of Microcontroller & Its Application: Unit-IiiRajan PatelNessuna valutazione finora
- ES03 Lab ManualDocumento58 pagineES03 Lab ManualJeric RajalNessuna valutazione finora
- Worksheet 1Documento2 pagineWorksheet 1Biniyam DameneNessuna valutazione finora
- C by PavanDocumento34 pagineC by PavanMaddu PavanNessuna valutazione finora
- Bulletin No. 79Documento117 pagineBulletin No. 79joNessuna valutazione finora
- 7209 MKT Spec Technical DataDocumento5 pagine7209 MKT Spec Technical DatajoNessuna valutazione finora
- Manual FLC3 70Documento1 paginaManual FLC3 70joNessuna valutazione finora
- Advantages of Magnetic GradiometersDocumento5 pagineAdvantages of Magnetic GradiometersjoNessuna valutazione finora
- Commview For Wifi Technical Specifications: Wireless Network Monitor and AnalyzerDocumento1 paginaCommview For Wifi Technical Specifications: Wireless Network Monitor and AnalyzerjoNessuna valutazione finora
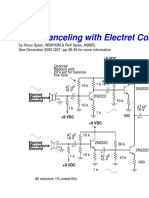
- Noise Canceling With Electret Condenser Microphones: OptionalDocumento1 paginaNoise Canceling With Electret Condenser Microphones: OptionaljoNessuna valutazione finora
- Noise Canceling With Electret Condenser Microphones: OptionalDocumento1 paginaNoise Canceling With Electret Condenser Microphones: OptionaljoNessuna valutazione finora
- RS232 - DTE and DCE Connectors: Click HereDocumento4 pagineRS232 - DTE and DCE Connectors: Click HerejoNessuna valutazione finora
- Simple RF - LF Interface For A Shortwave Receiver: Klik Hier Voor de Nederlandse VersieDocumento31 pagineSimple RF - LF Interface For A Shortwave Receiver: Klik Hier Voor de Nederlandse VersiejoNessuna valutazione finora
- RCL-meter: (Version 1.10)Documento3 pagineRCL-meter: (Version 1.10)joNessuna valutazione finora
- Deep Soil Metal Detector CircuitDocumento17 pagineDeep Soil Metal Detector Circuitjo100% (1)
- Hard Method, Flashing With FastbootDocumento6 pagineHard Method, Flashing With FastbootjoNessuna valutazione finora
- Capability ListDocumento16 pagineCapability ListjoNessuna valutazione finora
- Ant Data SamplesDocumento4 pagineAnt Data SamplesjoNessuna valutazione finora
- Essay WritingDocumento1 paginaEssay WritingPaula Correia AraujoNessuna valutazione finora
- History of Ethiopian Architecture AssignmentDocumento7 pagineHistory of Ethiopian Architecture AssignmentSani MohammedNessuna valutazione finora
- 12 RPP Bahasa Inggris IX KD 3.5Documento4 pagine12 RPP Bahasa Inggris IX KD 3.5Ahsan NizammNessuna valutazione finora
- Toastmaster FullDocumento39 pagineToastmaster Fullmachinel1983Nessuna valutazione finora
- (1978) PRUF - A Meaning Representation Language For Natural Languages (Zadeh)Documento66 pagine(1978) PRUF - A Meaning Representation Language For Natural Languages (Zadeh)Georg OhmNessuna valutazione finora
- Dialog Prestasi August English 2020Documento16 pagineDialog Prestasi August English 2020SAKUNTHALA A/P DHANASEKARAN MoeNessuna valutazione finora
- EF4e Preint Filetest 07aDocumento5 pagineEF4e Preint Filetest 07aLucas AlvesNessuna valutazione finora
- Teaching Listening and SpeakingDocumento4 pagineTeaching Listening and SpeakingJan Rich100% (1)
- The Using Song To Improve VocabDocumento12 pagineThe Using Song To Improve VocabPutri AyaNessuna valutazione finora
- Q2WEEK OneDocumento11 pagineQ2WEEK Onevivien villaberNessuna valutazione finora
- More Than A Decade of Standards:: Integrating "Communication" in Your Language InstructionDocumento6 pagineMore Than A Decade of Standards:: Integrating "Communication" in Your Language InstructionHenrique AlmeidaNessuna valutazione finora
- Lesson Plan For Tutoring - Grade 3 Unit 1: Welcome - Lesson 2: About UsDocumento3 pagineLesson Plan For Tutoring - Grade 3 Unit 1: Welcome - Lesson 2: About UsNgọc Anh TrầnNessuna valutazione finora
- Morfologie Categorii Verbale Book-1 PDFDocumento201 pagineMorfologie Categorii Verbale Book-1 PDFElena Stefana SalvatoreNessuna valutazione finora
- A Grammar of KarbiDocumento793 pagineA Grammar of Karbialexandreq100% (2)
- Modal Verbs PracticeDocumento6 pagineModal Verbs PracticeMargaret Abreu UcetaNessuna valutazione finora
- Stroke Order in ChineseDocumento7 pagineStroke Order in Chineseprefect447449Nessuna valutazione finora
- Language Paper 2 Mark Scheme PDFDocumento21 pagineLanguage Paper 2 Mark Scheme PDFEbony Butler0% (2)
- Artificial Intelligence & Learning Computers: R.Kartheek B.Tech Iii (I.T) V.R.S & Y.R.N Engineering College, ChiralaDocumento9 pagineArtificial Intelligence & Learning Computers: R.Kartheek B.Tech Iii (I.T) V.R.S & Y.R.N Engineering College, ChiralaRavula KartheekNessuna valutazione finora
- From Arabic Alphabets To Two Dimension Shapes in Kufic Calligraphy Style Using Grid Board CatalogDocumento18 pagineFrom Arabic Alphabets To Two Dimension Shapes in Kufic Calligraphy Style Using Grid Board Catalogimtiaz ahmadNessuna valutazione finora
- Typical Situation - Two Teachers Are Teaching Two Subjects in One Class at The Same Time - ASc TimetablesDocumento2 pagineTypical Situation - Two Teachers Are Teaching Two Subjects in One Class at The Same Time - ASc TimetablesakutekyenNessuna valutazione finora
- New Matrix Int Tests KeyDocumento6 pagineNew Matrix Int Tests KeyMárkó Mészáros100% (4)
- Syntactic Features of English IdiomsDocumento6 pagineSyntactic Features of English IdiomsSandra DiasNessuna valutazione finora
- Kripke On Russell's Notion of ScopeDocumento33 pagineKripke On Russell's Notion of ScopeTristan HazeNessuna valutazione finora
- Advanced English Arabic Translation 19Documento1 paginaAdvanced English Arabic Translation 19A AlharthiNessuna valutazione finora
- Physicians Use of Inclusive Sexual Orientation Language During Teenage Annual VisitsDocumento9 paginePhysicians Use of Inclusive Sexual Orientation Language During Teenage Annual VisitsTherese Berina-MallenNessuna valutazione finora
- Pretest in Oral CommunicationDocumento4 paginePretest in Oral CommunicationmariaNessuna valutazione finora
- Editing Proofreading V 2Documento10 pagineEditing Proofreading V 2AnnaNessuna valutazione finora
- Instruction PlanDocumento8 pagineInstruction PlanUtkarsh SinghNessuna valutazione finora
- Purposive Communication PrelimsDocumento2 paginePurposive Communication PrelimsRaven Micolle Aquino100% (2)
- Scratch Computing BackupDocumento23 pagineScratch Computing BackupAbhishek Gambhir100% (1)