Potrebbero piacerti anche
- Algorithmic Specified Complexity in The Game of LifeDocumento11 pagineAlgorithmic Specified Complexity in The Game of LifeLelieth Martin CastroNessuna valutazione finora
- Lecture One: Harmonic Functions and The Harnack InequalityDocumento5 pagineLecture One: Harmonic Functions and The Harnack InequalityMuntazir MehdiNessuna valutazione finora
- Plantilla Tarea ControlDocumento9 paginePlantilla Tarea ControlVi RSNessuna valutazione finora
- dg1 hw5 SolutionsDocumento11 paginedg1 hw5 Solutionschristophercabezas93Nessuna valutazione finora
- Supplementary MaterialDocumento4 pagineSupplementary MaterialEliezer SilvaNessuna valutazione finora
- COGS 118 Homework 3 Supervised Machine Learning AlgorithmsDocumento7 pagineCOGS 118 Homework 3 Supervised Machine Learning AlgorithmsVeronica LinNessuna valutazione finora
- Tutorial 8 QuestionsDocumento3 pagineTutorial 8 QuestionsEvan DuhNessuna valutazione finora
- Cee235b Handout JacobianDocumento4 pagineCee235b Handout JacobianNguyen DuyNessuna valutazione finora
- Lu 2017Documento5 pagineLu 2017Padma KNessuna valutazione finora
- Triple Int16 8Documento7 pagineTriple Int16 8Nikoli MajorNessuna valutazione finora
- 11 Sliding Mode ControlDocumento9 pagine11 Sliding Mode ControlKgotsofalang Kayson NqhwakiNessuna valutazione finora
- Assignment 2Documento2 pagineAssignment 2Eric HeNessuna valutazione finora
- 2011 002 Final SolDocumento6 pagine2011 002 Final Solakash gargNessuna valutazione finora
- Finite Difference Methods For PDEsDocumento73 pagineFinite Difference Methods For PDEsxz12110324Nessuna valutazione finora
- Power Sys State EstimatnDocumento6 paginePower Sys State EstimatnAnonymous dJETDebGNessuna valutazione finora
- Discretization and Simulation For A Class of Spdes With Applications To Zakai and Mckean-Vlasov EquationsDocumento43 pagineDiscretization and Simulation For A Class of Spdes With Applications To Zakai and Mckean-Vlasov EquationspoojaNessuna valutazione finora
- CSE Example Capacitor Numerical PDEDocumento13 pagineCSE Example Capacitor Numerical PDESarthak SinghNessuna valutazione finora
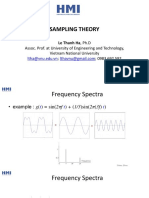
- Digital Image Processing - Sampling TheoryDocumento56 pagineDigital Image Processing - Sampling TheoryLong Đặng HoàngNessuna valutazione finora
- Viscous Fluid FlowDocumento48 pagineViscous Fluid FlowTrym Erik Nielsen100% (1)
- Notes On Finite Elements: 1 Basic DefinitionsDocumento7 pagineNotes On Finite Elements: 1 Basic Definitionsdalves31503Nessuna valutazione finora
- Lie Algebra 8Documento5 pagineLie Algebra 8симплектик геометрияNessuna valutazione finora
- Velocity PotentialDocumento14 pagineVelocity PotentialGeorge DukeNessuna valutazione finora
- MA8352-Linear Algebra and Partial Differential EquationsDocumento2 pagineMA8352-Linear Algebra and Partial Differential Equationssyed1188Nessuna valutazione finora
- Further Wiener-Hopf DevelopmentsDocumento10 pagineFurther Wiener-Hopf DevelopmentsalfonsoNessuna valutazione finora
- 18.657: Mathematics of Machine Learning: S R LR LK KDocumento9 pagine18.657: Mathematics of Machine Learning: S R LR LK KBanupriya BalasubramanianNessuna valutazione finora
- Assignment 5 - Due November 1: 2 B A B A 2 2 0 0Documento1 paginaAssignment 5 - Due November 1: 2 B A B A 2 2 0 0Harsh Vardhan DubeyNessuna valutazione finora
- DualDocumento6 pagineDualGiovanny Fuentes SalvoNessuna valutazione finora
- 10.1515 - Math 2022 0520Documento9 pagine10.1515 - Math 2022 0520Efrén Urbano Martínez PérezNessuna valutazione finora
- Lecture 09 - Differential Structures: The Pivotal Concept of Tangent Vector Spaces (Schuller's Geometric Anatomy of Theoretical Physics)Documento10 pagineLecture 09 - Differential Structures: The Pivotal Concept of Tangent Vector Spaces (Schuller's Geometric Anatomy of Theoretical Physics)Simon Rea100% (1)
- Luby's Alg. For Maximal Independent Sets Using Pairwise IndependenceDocumento6 pagineLuby's Alg. For Maximal Independent Sets Using Pairwise IndependenceHenrique LimaNessuna valutazione finora
- AE 301 - Aerodynamics I - Spring 2015 Answers To Problem Set 4Documento7 pagineAE 301 - Aerodynamics I - Spring 2015 Answers To Problem Set 4TheTannedFishNessuna valutazione finora
- Calc III Quick SheetsDocumento5 pagineCalc III Quick Sheetsguardian12Nessuna valutazione finora
- Final ProjectDocumento4 pagineFinal ProjectChacho BacoaNessuna valutazione finora
- Digital Image ProcessingDocumento2 pagineDigital Image ProcessingGeremu TilahunNessuna valutazione finora
- Algebra of Vector FieldsDocumento4 pagineAlgebra of Vector FieldsVladimir LubyshevNessuna valutazione finora
- What You Need From Analysis: Appendix ADocumento31 pagineWhat You Need From Analysis: Appendix ACarlos BifiNessuna valutazione finora
- Lecture 11: Expanders: Definition 0.1. A Bipartite Graph G (I O E) Is Called An (N, D, C) - Expander If - I - O - NDocumento11 pagineLecture 11: Expanders: Definition 0.1. A Bipartite Graph G (I O E) Is Called An (N, D, C) - Expander If - I - O - Nkientrungle2001Nessuna valutazione finora
- A Preview of Calculus: Lecture Note 1Documento103 pagineA Preview of Calculus: Lecture Note 1ckxkdnnsjsjNessuna valutazione finora
- Aero2258A Thin Aerofoil TheoryLecture NotesDocumento42 pagineAero2258A Thin Aerofoil TheoryLecture NotesSakthi RameshNessuna valutazione finora
- c2 PDFDocumento10 paginec2 PDFChristos DedesNessuna valutazione finora
- FEM MATLAB Code For Linear and Nonlinear Bending Analysis of PlatesDocumento20 pagineFEM MATLAB Code For Linear and Nonlinear Bending Analysis of Platesshambel kipNessuna valutazione finora
- CH605 23 24 Tutorial2Documento3 pagineCH605 23 24 Tutorial2NeerajNessuna valutazione finora
- Risk Theory Supportive Notes (Spring 2015) : 1.1 Models For Individual ClaimsDocumento19 pagineRisk Theory Supportive Notes (Spring 2015) : 1.1 Models For Individual Claimsdavid AbotsitseNessuna valutazione finora
- Numerical Methods of Thermo-Fluid Dynamics I: Deliverable Task Ii: Numerical Solution of Boundary Layer EquationDocumento2 pagineNumerical Methods of Thermo-Fluid Dynamics I: Deliverable Task Ii: Numerical Solution of Boundary Layer EquationJishnu JayarajNessuna valutazione finora
- Function SpacesDocumento20 pagineFunction SpacesGiovanni PalomboNessuna valutazione finora
- Lecture 4 PDFDocumento22 pagineLecture 4 PDFSparrowGospleGilbertNessuna valutazione finora
- 09 Fall 501 LyapDocumento10 pagine09 Fall 501 LyapAnonymous XKlkx7cr2INessuna valutazione finora
- Ps 1Documento5 paginePs 1Emre UysalNessuna valutazione finora
- Green'S Functions of Partial Differential Equations With InvolutionsDocumento12 pagineGreen'S Functions of Partial Differential Equations With InvolutionsDilara ÇınarelNessuna valutazione finora
- MATS 2202 Homework 12Documento4 pagineMATS 2202 Homework 12Segun MacphersonNessuna valutazione finora
- CS 103X: Discrete Structures Homework Assignment 5 - SolutionsDocumento3 pagineCS 103X: Discrete Structures Homework Assignment 5 - SolutionsMichel MagnaNessuna valutazione finora
- 10 - Partial Derivatives SolutionsDocumento3 pagine10 - Partial Derivatives SolutionsFausto SosaNessuna valutazione finora
- Sample Solutions To Practice Problems For Exam I: Math 11 Fall 2007 October 17, 2008Documento27 pagineSample Solutions To Practice Problems For Exam I: Math 11 Fall 2007 October 17, 2008haroldoNessuna valutazione finora
- CS 563 Advanced Topics in Computer Graphics Monte Carlo Integration: Basic ConceptsDocumento38 pagineCS 563 Advanced Topics in Computer Graphics Monte Carlo Integration: Basic ConceptsNeha SameerNessuna valutazione finora
- Midterm 2014Documento23 pagineMidterm 2014Zeeshan Ali SayyedNessuna valutazione finora
- Objectives of Chapter 5:, X, andDocumento6 pagineObjectives of Chapter 5:, X, andMayank SoniNessuna valutazione finora
- Finite Volume Method For One DimensionalDocumento26 pagineFinite Volume Method For One Dimensionalscience1990Nessuna valutazione finora
- Mathematical PhysicsDocumento14 pagineMathematical Physicsosama hasanNessuna valutazione finora
- MA111 Lec7 D3D4Documento20 pagineMA111 Lec7 D3D4pahnhnykNessuna valutazione finora
- Weighted Reference Shifted Phase Encoded Fringe Adjusted Joint Transform Correlator For Class Associative Multiple Target DetectionDocumento4 pagineWeighted Reference Shifted Phase Encoded Fringe Adjusted Joint Transform Correlator For Class Associative Multiple Target Detectionmunadil98Nessuna valutazione finora
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesDa EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNessuna valutazione finora
- Lay Denial of Knowledge For Justified True BeliefsDocumento10 pagineLay Denial of Knowledge For Justified True BeliefsJuan Camilo Osorio AlcaldeNessuna valutazione finora
- Interdisciplinary Teacher Collaboration For English For Specific Purposes in The PhilippinesDocumento34 pagineInterdisciplinary Teacher Collaboration For English For Specific Purposes in The PhilippinesKathleen MoradaNessuna valutazione finora
- Guias # 2 Segundo Periodo Genitive CaseDocumento7 pagineGuias # 2 Segundo Periodo Genitive Caseferney cordobaNessuna valutazione finora
- Daily Lesson Plan Format (RPH) A. Teaching & Learning DetailsDocumento9 pagineDaily Lesson Plan Format (RPH) A. Teaching & Learning DetailsMistike June100% (1)
- Teaching Reflection-1Documento2 pagineTeaching Reflection-1api-230344725100% (1)
- Week 6 - Interpersonal and Negotiation SkillsDocumento25 pagineWeek 6 - Interpersonal and Negotiation SkillsIodanutzs UkNessuna valutazione finora
- Social AwarenessDocumento11 pagineSocial AwarenessBhumika BiyaniNessuna valutazione finora
- Lang Ans FinalDocumento1 paginaLang Ans FinalJheanelle Andrea GodoyNessuna valutazione finora
- Qualia: IntrospectionDocumento16 pagineQualia: IntrospectionRafael RoaNessuna valutazione finora
- How To Approach To Case Study Type Questions and MCQsDocumento4 pagineHow To Approach To Case Study Type Questions and MCQsKushang ShahNessuna valutazione finora
- Artificial Intelligence Vrs StatisticsDocumento25 pagineArtificial Intelligence Vrs StatisticsJavier Gramajo Lopez100% (1)
- Sınıf 2. SınavDocumento2 pagineSınıf 2. SınavAnıl ÇetinNessuna valutazione finora
- Dimensions of Psychological TheoryDocumento8 pagineDimensions of Psychological TheoryJosé Carlos Sánchez-RamirezNessuna valutazione finora
- Voyage Into Root of LanguageDocumento171 pagineVoyage Into Root of LanguageMadhu KapoorNessuna valutazione finora
- Effect of Word Sense Disambiguation On Neural Machine Translation A Case Study in KoreanDocumento12 pagineEffect of Word Sense Disambiguation On Neural Machine Translation A Case Study in KoreanhemantNessuna valutazione finora
- Glossary of Words Used in ISO 9000-2015 and ISO 9001-2015Documento5 pagineGlossary of Words Used in ISO 9000-2015 and ISO 9001-2015alfredorozalenNessuna valutazione finora
- Oratores Bellatores Laboratores DissertationDocumento6 pagineOratores Bellatores Laboratores DissertationCanSomeoneWriteMyPaperForMeSingapore100% (1)
- Maria Syuhada, 150203221, FTK, PBI, 0895600332660Documento118 pagineMaria Syuhada, 150203221, FTK, PBI, 0895600332660Alexes Paul TancioNessuna valutazione finora
- Communication in Social WorkDocumento2 pagineCommunication in Social WorkOly Marian100% (4)
- NSTP Online Class Module # 1Documento4 pagineNSTP Online Class Module # 1Vench Quiaem50% (2)
- Mid Integrated English 2018-2019Documento11 pagineMid Integrated English 2018-2019hasna azzuhaira100% (2)
- Sdeng3J: Tutorial Letter 102/0/2022Documento17 pagineSdeng3J: Tutorial Letter 102/0/2022Charmainehlongwane4gmail Charmainehlongwane4gmailNessuna valutazione finora
- MACHINE LEARNING ALGORITHM Unit-II Part-II-1Documento65 pagineMACHINE LEARNING ALGORITHM Unit-II Part-II-1akash chandankarNessuna valutazione finora
- HOUSEKEEPING - WEEK 1 UpdatedDocumento5 pagineHOUSEKEEPING - WEEK 1 UpdatedMaria Rizza IlaganNessuna valutazione finora
- The Idea of Progress in Forensic Authorship Analysis Tim GrantDocumento84 pagineThe Idea of Progress in Forensic Authorship Analysis Tim GrantJorge MorteoNessuna valutazione finora
- French CreoleDocumento3 pagineFrench CreolenefNessuna valutazione finora
- Unit 1. An Introduction To Statistical Data Analysis Report: Getting StartedDocumento54 pagineUnit 1. An Introduction To Statistical Data Analysis Report: Getting StartedTrang DươngNessuna valutazione finora
- Symbolism and Environmental DesignDocumento7 pagineSymbolism and Environmental Designshivashz2Nessuna valutazione finora
- HowToLearnAnyLanguage PlusSpeakDocumento43 pagineHowToLearnAnyLanguage PlusSpeakEla100% (1)