Potrebbero piacerti anche
- 2 Measures of Central TendencyDocumento21 pagine2 Measures of Central TendencyBroccoli ChanNessuna valutazione finora
- Measures of Central TendencyDocumento4 pagineMeasures of Central TendencyJhon dave SurbanoNessuna valutazione finora
- Chapter 4Documento19 pagineChapter 4Larry RicoNessuna valutazione finora
- 4 Statistics Measures of Central TendencyandyDocumento24 pagine4 Statistics Measures of Central TendencyandyJa Caliboso100% (1)
- Prepared by Mr. A.P Nanada, Associate Prof. (OM) : Decision Science Sub. Code: MBA 105 (For MBA Students)Documento247 paginePrepared by Mr. A.P Nanada, Associate Prof. (OM) : Decision Science Sub. Code: MBA 105 (For MBA Students)saubhagya ranjan routNessuna valutazione finora
- Measures of Central Tendency and Other Positional MeasuresDocumento13 pagineMeasures of Central Tendency and Other Positional Measuresbv123bvNessuna valutazione finora
- Stat & ProbabilityDocumento67 pagineStat & Probabilityanna luna berryNessuna valutazione finora
- Measures of Central Tendency Grouped DataDocumento8 pagineMeasures of Central Tendency Grouped DataLabLab ChattoNessuna valutazione finora
- GROUPED DATA - Measures of Central Tendency - Mean Median ModeDocumento21 pagineGROUPED DATA - Measures of Central Tendency - Mean Median ModeJohann AlegreNessuna valutazione finora
- Central TendencyDocumento216 pagineCentral TendencyJai John100% (1)
- Measure of Central Tendency - QuestionsDocumento14 pagineMeasure of Central Tendency - QuestionsMohd HannanNessuna valutazione finora
- Final Module in Assessment 1Documento23 pagineFinal Module in Assessment 1Sheena LiagaoNessuna valutazione finora
- Measure of Position For Ingrouped DataDocumento19 pagineMeasure of Position For Ingrouped DataRavie Acuna DiongsonNessuna valutazione finora
- Module5 Measures of Central Tendency Grouped Data Business 1Documento13 pagineModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomNessuna valutazione finora
- Module5 Measures of Central Tendency Grouped Data Business 1Documento13 pagineModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomNessuna valutazione finora
- Statistics For Social Science 1Documento18 pagineStatistics For Social Science 1TCNessuna valutazione finora
- Measures of DispersionDocumento26 pagineMeasures of DispersionAshish Sen GuptaNessuna valutazione finora
- Statistics and Probability Chp4Documento8 pagineStatistics and Probability Chp4Renor SagunNessuna valutazione finora
- Measures of Central TendencyDocumento20 pagineMeasures of Central TendencyJhovelle AnsayNessuna valutazione finora
- Module 3 and 4 StatDocumento31 pagineModule 3 and 4 StatBrandon BorromeoNessuna valutazione finora
- Lesson 3 Measures of Central Tendency Power PointDocumento29 pagineLesson 3 Measures of Central Tendency Power PointJoyce Laru-anNessuna valutazione finora
- Mean, Median & ModeDocumento6 pagineMean, Median & ModeReina CuizonNessuna valutazione finora
- Reviewer MathDocumento18 pagineReviewer MathYAGI, Miyuki F.Nessuna valutazione finora
- Final Module in Assessment in LearningDocumento23 pagineFinal Module in Assessment in LearningGeneNessuna valutazione finora
- Slides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeDocumento22 pagineSlides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeKim NamjoonneNessuna valutazione finora
- 1743 Chapter 2 Data Description (A)Documento15 pagine1743 Chapter 2 Data Description (A)Sho Pin TanNessuna valutazione finora
- Measures of Central TendencyDocumento34 pagineMeasures of Central Tendencyhatem akeedyNessuna valutazione finora
- Mean Mode MedianDocumento17 pagineMean Mode MedianzenneyNessuna valutazione finora
- Measures of Central TendencyDocumento5 pagineMeasures of Central TendencyAngelica FloraNessuna valutazione finora
- Properties of Median in StatisticsDocumento6 pagineProperties of Median in StatisticsElijah IbsaNessuna valutazione finora
- Measures of Central TendencyDocumento11 pagineMeasures of Central Tendencymilkanjeri577Nessuna valutazione finora
- 3-Measure of Central TendencyDocumento11 pagine3-Measure of Central TendencySharlize Veyen RuizNessuna valutazione finora
- Measures of Central TendencyDocumento13 pagineMeasures of Central Tendencydiana nyamisaNessuna valutazione finora
- Arithmetic Mean: Averages or Measures of Central TendencyDocumento9 pagineArithmetic Mean: Averages or Measures of Central TendencySherona ReidNessuna valutazione finora
- Mean, Median & ModeDocumento6 pagineMean, Median & ModeReina CuizonNessuna valutazione finora
- Measures of Central TendencyDocumento27 pagineMeasures of Central TendencyRosemarie AlcantaraNessuna valutazione finora
- Median, ModeDocumento44 pagineMedian, ModeSanjay SNessuna valutazione finora
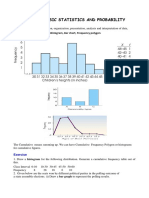
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocumento6 pagineUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNessuna valutazione finora
- Lesson 4 Measures of Central TendencyDocumento7 pagineLesson 4 Measures of Central TendencyKeneth Dave AglibutNessuna valutazione finora
- Unit-II (Topic-1)Documento14 pagineUnit-II (Topic-1)DOODIPALA SREEPREETHAM REDDY 222010326059Nessuna valutazione finora
- Bio StatisticsDocumento110 pagineBio StatisticsPrtap Kumar PatraNessuna valutazione finora
- Educ 98 - MEASURES OF CENTRAL TENDENCYDocumento24 pagineEduc 98 - MEASURES OF CENTRAL TENDENCYMARYKNOL J. ALVAREZNessuna valutazione finora
- Measurement of Central Tendency - Ungrouped Data: Tendency and The Measures of Spread or Variability. 2.12 DefinitionDocumento9 pagineMeasurement of Central Tendency - Ungrouped Data: Tendency and The Measures of Spread or Variability. 2.12 DefinitionDaille Wroble GrayNessuna valutazione finora
- Measures of Variability.2023Documento26 pagineMeasures of Variability.2023leekoodelimNessuna valutazione finora
- F) D X A D FD 000' FD: Mean, Since Assumed Mean (Baseline Average) 27,000 Therefore MeanDocumento5 pagineF) D X A D FD 000' FD: Mean, Since Assumed Mean (Baseline Average) 27,000 Therefore MeanAlinaitwe GodfNessuna valutazione finora
- BBA (N) - 103 Central TendencyDocumento20 pagineBBA (N) - 103 Central TendencyPratyum PradhanNessuna valutazione finora
- Lesson 5 Measures of Dispersion Power PointDocumento18 pagineLesson 5 Measures of Dispersion Power PointJoyce Laru-anNessuna valutazione finora
- 5-Measure of DispersionDocumento9 pagine5-Measure of DispersionSharlize Veyen RuizNessuna valutazione finora
- The Measures of Central TendencyDocumento40 pagineThe Measures of Central TendencyMark Lester Brosas TorreonNessuna valutazione finora
- The StatisticsDocumento4 pagineThe StatisticsHridoy BhuiyanNessuna valutazione finora
- Definition of Terms 1. StatisticsDocumento25 pagineDefinition of Terms 1. StatisticsJane BermoyNessuna valutazione finora
- Module in Inferential Statistics With Additional Exercises Edited Nov 14 by Tats2020Documento90 pagineModule in Inferential Statistics With Additional Exercises Edited Nov 14 by Tats2020Pamela GalveNessuna valutazione finora
- Measures of Central TendencyDocumento18 pagineMeasures of Central TendencyManeth Muñez CaparosNessuna valutazione finora
- Statistical Organization of ScoresDocumento70 pagineStatistical Organization of ScoresKim EsplagoNessuna valutazione finora
- Lesson Plan grouped-PERCENTILEDocumento6 pagineLesson Plan grouped-PERCENTILESherra Mae BagoodNessuna valutazione finora
- STA30111Documento4 pagineSTA30111Gulam MustafaNessuna valutazione finora
- Statistical Analysis - 2Documento5 pagineStatistical Analysis - 2John Paul RamosNessuna valutazione finora
- Mean Median ModeDocumento32 pagineMean Median ModeShiella Mae Baltazar BulauitanNessuna valutazione finora
- MedianDocumento14 pagineMedianzohaibkhan6529Nessuna valutazione finora
- Student Strand Score InterpretationDocumento1 paginaStudent Strand Score InterpretationAnjo Pasiolco CanicosaNessuna valutazione finora
- R.P. A Typical Case of ProsopagnosiaDocumento10 pagineR.P. A Typical Case of ProsopagnosiaAnjo Pasiolco CanicosaNessuna valutazione finora
- Attitude TargetsDocumento4 pagineAttitude TargetsAnjo Pasiolco Canicosa100% (1)
- Thesis Title: "Current Perspectives On Mother Tongue-Based Instruction Among Grade I-IIIDocumento2 pagineThesis Title: "Current Perspectives On Mother Tongue-Based Instruction Among Grade I-IIIAnjo Pasiolco CanicosaNessuna valutazione finora
- Legal Aspect of Nursing ProfessionDocumento85 pagineLegal Aspect of Nursing ProfessionAnjo Pasiolco Canicosa50% (2)
- Introduction To AlgebraDocumento41 pagineIntroduction To AlgebraAnjo Pasiolco Canicosa100% (1)
- ) IncreasesDocumento8 pagine) IncreasesAnjo Pasiolco CanicosaNessuna valutazione finora
- Consumer and Patient Use of Computers For HealthDocumento7 pagineConsumer and Patient Use of Computers For HealthAnjo Pasiolco CanicosaNessuna valutazione finora
- Nursing Informatics in Different CountriesDocumento8 pagineNursing Informatics in Different CountriesAnjo Pasiolco Canicosa100% (1)
- International PerspectivesDocumento52 pagineInternational PerspectivesAnjo Pasiolco Canicosa100% (1)
- Fnri Digest: Figure Below), A Simple and Easy-To-Follow Daily Eating Guide For Filipinos. The Food GuideDocumento3 pagineFnri Digest: Figure Below), A Simple and Easy-To-Follow Daily Eating Guide For Filipinos. The Food GuideAnjo Pasiolco Canicosa100% (1)
- BehavioralDocumento7 pagineBehavioralAnjo Pasiolco CanicosaNessuna valutazione finora
- Geological Forces That Shape The EarthDocumento9 pagineGeological Forces That Shape The EarthAnjo Pasiolco CanicosaNessuna valutazione finora
- List of Different Ethnic Groups in The PhilippinesDocumento2 pagineList of Different Ethnic Groups in The PhilippinesAnjo Pasiolco Canicosa100% (2)
- Leading and Directing HandoutDocumento10 pagineLeading and Directing HandoutAnjo Pasiolco CanicosaNessuna valutazione finora
- Glucose From ProteinDocumento5 pagineGlucose From ProteinAnjo Pasiolco CanicosaNessuna valutazione finora
- Lecture 1Documento6 pagineLecture 1Anjo Pasiolco CanicosaNessuna valutazione finora
- Quantitative Prelim To FinalsDocumento38 pagineQuantitative Prelim To FinalsKim Ryan EsguerraNessuna valutazione finora
- Module5 Measures of Central Tendency Grouped Data Business 1Documento13 pagineModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomNessuna valutazione finora
- Levels of MeasurementDocumento64 pagineLevels of MeasurementIlika Guha MajumdarNessuna valutazione finora
- ISC EconomicsDocumento8 pagineISC EconomicsPrincess Soniya100% (1)
- Business Research Methods 11th Edition Cooper Test Bank DownloadDocumento33 pagineBusiness Research Methods 11th Edition Cooper Test Bank Downloadupwindscatterf9ebp100% (32)
- 100% QM SourceDocumento205 pagine100% QM Sourcemoncarla lagonNessuna valutazione finora
- Descriptive Statistics - Solution SheetDocumento32 pagineDescriptive Statistics - Solution Sheetmadelene gatuteoNessuna valutazione finora
- 10 Math Statistics Tp03Documento6 pagine10 Math Statistics Tp03Subha VijayNessuna valutazione finora
- Test Sta3073 - Sta2113 0722 (QP)Documento5 pagineTest Sta3073 - Sta2113 0722 (QP)Siti KhadijahNessuna valutazione finora
- Shinko A-L-E Series ManualDocumento126 pagineShinko A-L-E Series Manualİsmail YILMAZNessuna valutazione finora
- Radio Network Optimization Guideline (HAY) (R)Documento40 pagineRadio Network Optimization Guideline (HAY) (R)Hiep Nguyen Dinh100% (1)
- Chapter 3 - Measure of Location and DispersionDocumento11 pagineChapter 3 - Measure of Location and DispersionNelly MalatjiNessuna valutazione finora
- Basic Statistics For The Utterly ConfusedDocumento45 pagineBasic Statistics For The Utterly ConfusedwaqarnasirkhanNessuna valutazione finora
- Quantitative Methods Case Study: Mattel's Global Expansion: Analysing Growth Trends Name: Taksh Dhami Enrolment No: 20BSP2609 Division: GDocumento7 pagineQuantitative Methods Case Study: Mattel's Global Expansion: Analysing Growth Trends Name: Taksh Dhami Enrolment No: 20BSP2609 Division: GJyot DhamiNessuna valutazione finora
- Week 3, MathDocumento1 paginaWeek 3, MathRieben MistulaNessuna valutazione finora
- Final Module in Assessment 1Documento23 pagineFinal Module in Assessment 1Sheena LiagaoNessuna valutazione finora
- Normal Distribution Research PaperDocumento8 pagineNormal Distribution Research Paperh0251mhq100% (1)
- Ge8077 TQM QBDocumento36 pagineGe8077 TQM QBECE113 - SURESH KUMAR MNessuna valutazione finora
- Normal DistributionDocumento9 pagineNormal Distributiontantan GalamNessuna valutazione finora
- Chapter 1 Introduction To Statistics For EngineersDocumento91 pagineChapter 1 Introduction To Statistics For EngineersEngidNessuna valutazione finora
- SparkNotes - GRE - Data AnalysisDocumento15 pagineSparkNotes - GRE - Data Analysisscribd_sandeepNessuna valutazione finora
- Cufsm IntroductionDocumento14 pagineCufsm Introductionchristos032100% (1)
- DM GTU Study Material Presentations Unit-2 17032021053028AMDocumento60 pagineDM GTU Study Material Presentations Unit-2 17032021053028AMmuhammad Shoaib janjuaNessuna valutazione finora
- QUARTILEDocumento2 pagineQUARTILErhianreign estudilloNessuna valutazione finora
- G100 Operating ManualDocumento48 pagineG100 Operating ManualdianNessuna valutazione finora
- Averages (Chapter 12) QuestionsDocumento17 pagineAverages (Chapter 12) Questionssecret studentNessuna valutazione finora
- Statistical Methods MCQ'SDocumento41 pagineStatistical Methods MCQ'SGuruKPO89% (9)
- BS-chapter1-2022-Intro Statistics-Descrptv N Sumary M & Measures of LocationDocumento54 pagineBS-chapter1-2022-Intro Statistics-Descrptv N Sumary M & Measures of LocationShayanNessuna valutazione finora
- Descriptive Statistics TRIPLE S (STATISTICALLY SIGNIFICANT SQUAD)Documento4 pagineDescriptive Statistics TRIPLE S (STATISTICALLY SIGNIFICANT SQUAD)Dxnesh SonOf SamarasamNessuna valutazione finora
- Research Designs Used in Quantitative Research: Descriptive Research Design Experimental Research DesignDocumento55 pagineResearch Designs Used in Quantitative Research: Descriptive Research Design Experimental Research Designbona veronica viduyaNessuna valutazione finora