Potrebbero piacerti anche
- CorreoDocumento3 pagineCorreoJulianDavidAngaritaRodriguezNessuna valutazione finora
- Manual de Funciones Dto 156 de 2017Documento93 pagineManual de Funciones Dto 156 de 2017JulianDavidAngaritaRodriguezNessuna valutazione finora
- El DineroDocumento4 pagineEl DineroJulianDavidAngaritaRodriguezNessuna valutazione finora
- Flujograma Restaurante El TiestoDocumento1 paginaFlujograma Restaurante El TiestoJulianDavidAngaritaRodriguezNessuna valutazione finora
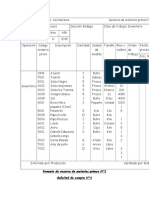
- Formato de Reserva de Materias PrimasDocumento11 pagineFormato de Reserva de Materias PrimasJulianDavidAngaritaRodriguez50% (2)
- Riesgo SDocumento15 pagineRiesgo SJulianDavidAngaritaRodriguezNessuna valutazione finora
- Da VinsonDocumento1 paginaDa VinsonJulianDavidAngaritaRodriguezNessuna valutazione finora
- Administracion de Empresas Plan de Estudios Flujograma 201402Documento1 paginaAdministracion de Empresas Plan de Estudios Flujograma 201402JulianDavidAngaritaRodriguezNessuna valutazione finora
- Mapa de ProcedimientosDocumento3 pagineMapa de ProcedimientosJulianDavidAngaritaRodriguezNessuna valutazione finora
- Lucha DescolonizadoraDocumento5 pagineLucha DescolonizadoraJulianDavidAngaritaRodriguezNessuna valutazione finora
- CAIDA LIBREDocumento8 pagineCAIDA LIBREJavier Izquierdo Morejon100% (3)
- Mano de ObraDocumento3 pagineMano de ObraJulianDavidAngaritaRodriguezNessuna valutazione finora
- Mano de Obra JDocumento10 pagineMano de Obra JJulianDavidAngaritaRodriguezNessuna valutazione finora
- Flujograma Restaurante El TiestoDocumento1 paginaFlujograma Restaurante El TiestoJulianDavidAngaritaRodriguezNessuna valutazione finora
- AnatomiaDocumento5 pagineAnatomiaJulianDavidAngaritaRodriguezNessuna valutazione finora
- Economia IiDocumento171 pagineEconomia IixhwizerNessuna valutazione finora
- El Mero MachoteDocumento8 pagineEl Mero MachoteJulianDavidAngaritaRodriguezNessuna valutazione finora
- Formato de Reserva de Materias PrimasDocumento11 pagineFormato de Reserva de Materias PrimasJulianDavidAngaritaRodriguez50% (2)
- Mano de ObraDocumento3 pagineMano de ObraJulianDavidAngaritaRodriguezNessuna valutazione finora
- Mano de ObraDocumento3 pagineMano de ObraJulianDavidAngaritaRodriguezNessuna valutazione finora
- Formato de Reserva de Materias PrimasDocumento11 pagineFormato de Reserva de Materias PrimasJulianDavidAngaritaRodriguez50% (2)
- Econometria Final FinalDocumento11 pagineEconometria Final FinalJulianDavidAngaritaRodriguezNessuna valutazione finora
- Qué Es Merchandising y Cómo Se Aplica en El Punto de VentaDocumento7 pagineQué Es Merchandising y Cómo Se Aplica en El Punto de VentaJulianDavidAngaritaRodriguez100% (1)
- Investigación de MercadosDocumento2 pagineInvestigación de MercadosJulianDavidAngaritaRodriguezNessuna valutazione finora
- Ampliación de La Reserva de TalentoDocumento40 pagineAmpliación de La Reserva de TalentoJulieArleneDeFlorentino67% (3)
- Can You Say What Your Strategy Is - En.esDocumento10 pagineCan You Say What Your Strategy Is - En.esArmando M. TobonNessuna valutazione finora
- Carta de pago hipoteca EscuintlaDocumento4 pagineCarta de pago hipoteca Escuintlalilian amandaNessuna valutazione finora
- Estados Financieros DUOCDocumento7 pagineEstados Financieros DUOCManuelAlejandroGallegosVivarNessuna valutazione finora
- 14a16Clase4Cap7FondoAmorti PDFDocumento3 pagine14a16Clase4Cap7FondoAmorti PDFElsa CerezoNessuna valutazione finora
- La Moderna S.A.CDocumento24 pagineLa Moderna S.A.CJosue Jhonatan Porras BecerraNessuna valutazione finora
- Crear Tu EmpresaDocumento2 pagineCrear Tu EmpresaAnonymous i1UjdXNessuna valutazione finora
- Manual de Normas Y Procedimientos de Ventas N4Documento27 pagineManual de Normas Y Procedimientos de Ventas N4GuadalupeNessuna valutazione finora
- Proyecto de Vivero AguacateDocumento19 pagineProyecto de Vivero AguacateRene Palacios100% (2)
- Proyecto de taller de herrería para generar empleos en MexicaliDocumento14 pagineProyecto de taller de herrería para generar empleos en MexicaliJorge Alberto100% (1)
- Análisis microeconómico II: Mercado de factoresDocumento4 pagineAnálisis microeconómico II: Mercado de factoresMarco Yampier Alva Martinez100% (1)
- Las 22 Leyes Inmutables Del MarketingDocumento13 pagineLas 22 Leyes Inmutables Del MarketingesmiicxiitoNessuna valutazione finora
- Diapositivas Ingreso Costos y EJERCICIODocumento14 pagineDiapositivas Ingreso Costos y EJERCICIOapi-377105892% (13)
- Ad General o Ad Financier A BasicaDocumento49 pagineAd General o Ad Financier A Basicawarner77Nessuna valutazione finora
- CONTENIDO DEL TRABAJO GRUPAL Consolidando Una Nueva Idea de NegocioDocumento2 pagineCONTENIDO DEL TRABAJO GRUPAL Consolidando Una Nueva Idea de NegocioJuan David CrewbangerNessuna valutazione finora
- Plan de ahorro familiar para comprar losetaDocumento15 paginePlan de ahorro familiar para comprar losetagàbbý pédràszà50% (2)
- Análisis de costos diferenciales para tomar la decisión de aceptar una orden especial de esquíesDocumento6 pagineAnálisis de costos diferenciales para tomar la decisión de aceptar una orden especial de esquíesErika Pamela Ccasa CasimiroNessuna valutazione finora
- Material Programacion de ProyectosDocumento2 pagineMaterial Programacion de ProyectosJose HernandezNessuna valutazione finora
- Caso AlliiedDocumento5 pagineCaso AlliiedAlejandro MuñanteNessuna valutazione finora
- Concret Paraguay SADocumento15 pagineConcret Paraguay SAubenesqNessuna valutazione finora
- Guía efectivo equivalentesDocumento1 paginaGuía efectivo equivalentesKarla VillafañaNessuna valutazione finora
- ChocotejasDocumento20 pagineChocotejasjose0% (1)
- Subsistema de ComprasDocumento5 pagineSubsistema de ComprasSusana Vilca Córdova100% (2)
- Excel Empresarial 2Documento2 pagineExcel Empresarial 2Katherine CruzNessuna valutazione finora
- El Hombre Más Rico de Babilona - Foro 1-1Documento8 pagineEl Hombre Más Rico de Babilona - Foro 1-1EmerNessuna valutazione finora
- Cuenta 19Documento5 pagineCuenta 19JuanLeninChaucaChumpitaz50% (2)
- Carnes y Mariscos Santa Cruz, proveedor de alimentos en BarranquillaDocumento32 pagineCarnes y Mariscos Santa Cruz, proveedor de alimentos en BarranquillaChristianRuizNessuna valutazione finora
- Libro Pobreza y Prejuicio Resumen Por CapítulosDocumento9 pagineLibro Pobreza y Prejuicio Resumen Por CapítulosConsuelo Aragon67% (3)
- Oferta de Ventas - 14215Documento1 paginaOferta de Ventas - 14215Claudia CéspedesNessuna valutazione finora
- MicroeconomíaDocumento3 pagineMicroeconomíaAmerico SaedNessuna valutazione finora