Potrebbero piacerti anche
- Learn-Keyboard .Co - Uk: Learn How To Play Electronic Keyboard or PianoDocumento13 pagineLearn-Keyboard .Co - Uk: Learn How To Play Electronic Keyboard or PianoabishekvsNessuna valutazione finora
- Statutory Requirements For Prevention of Sexual Harassment in The Workplace - IndiaDocumento5 pagineStatutory Requirements For Prevention of Sexual Harassment in The Workplace - IndiaabishekvsNessuna valutazione finora
- Full Version Is HEREDocumento4 pagineFull Version Is HEREabishekvsNessuna valutazione finora
- Letter of RecommendationDocumento1 paginaLetter of RecommendationabishekvsNessuna valutazione finora
- Request For Contract Change / Project RequestDocumento10 pagineRequest For Contract Change / Project RequestabishekvsNessuna valutazione finora
- DevOps NotesDocumento2 pagineDevOps NotesabishekvsNessuna valutazione finora
- Presentation 1Documento3 paginePresentation 1abishekvsNessuna valutazione finora
- 2016 Security Awareness (EN) Abishek Vidyashanker: Date / Time Student Score Passing Score ResultDocumento1 pagina2016 Security Awareness (EN) Abishek Vidyashanker: Date / Time Student Score Passing Score ResultabishekvsNessuna valutazione finora
- Gridsetup With PatchDocumento5 pagineGridsetup With PatchabishekvsNessuna valutazione finora
- Suse 12 To 15 UpgradeDocumento6 pagineSuse 12 To 15 UpgradeabishekvsNessuna valutazione finora
- Oracle GoldenGate NotesDocumento9 pagineOracle GoldenGate NotesabishekvsNessuna valutazione finora
- CR Q GB 0000582333Documento42 pagineCR Q GB 0000582333abishekvsNessuna valutazione finora
- D67238GC20 sg1Documento282 pagineD67238GC20 sg1abishekvsNessuna valutazione finora
- Demonstrating Value With BMC Server Automation (Bladelogic)Documento56 pagineDemonstrating Value With BMC Server Automation (Bladelogic)abishekvsNessuna valutazione finora
- Effective Awk Programming Third EditionDocumento448 pagineEffective Awk Programming Third EditionabishekvsNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Ver Notewin 10Documento5 pagineVer Notewin 10Aditya SinghNessuna valutazione finora
- Capsule Research ProposalDocumento4 pagineCapsule Research ProposalAilyn Ursal80% (5)
- Tindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfDocumento278 pagineTindara Addabbo, Edoardo Ales, Ylenia Curzi, Tommaso Fabbri, Olga Rymkevich, Iacopo Senatori - Performance Appraisal in Modern Employment Relations_ An Interdisciplinary Approach-Springer Internationa.pdfMario ChristopherNessuna valutazione finora
- Projects: Term ProjectDocumento2 pagineProjects: Term ProjectCoursePinNessuna valutazione finora
- VISCOROL Series - Magnetic Level Indicators: DescriptionDocumento4 pagineVISCOROL Series - Magnetic Level Indicators: DescriptionRaduNessuna valutazione finora
- SQL Datetime Conversion - String Date Convert Formats - SQLUSA PDFDocumento13 pagineSQL Datetime Conversion - String Date Convert Formats - SQLUSA PDFRaul E CardozoNessuna valutazione finora
- Mounting BearingDocumento4 pagineMounting Bearingoka100% (1)
- KrauseDocumento3 pagineKrauseVasile CuprianNessuna valutazione finora
- Presentation - Prof. Yuan-Shing PerngDocumento92 paginePresentation - Prof. Yuan-Shing PerngPhuongLoanNessuna valutazione finora
- Caso Kola RealDocumento17 pagineCaso Kola RealEvelyn Dayhanna Escobar PalomequeNessuna valutazione finora
- Majalah Remaja Islam Drise #09 by Majalah Drise - Issuu PDFDocumento1 paginaMajalah Remaja Islam Drise #09 by Majalah Drise - Issuu PDFBalqis Ar-Rubayyi' Binti HasanNessuna valutazione finora
- C Sharp Logical TestDocumento6 pagineC Sharp Logical TestBogor0251Nessuna valutazione finora
- The Concept of ElasticityDocumento19 pagineThe Concept of ElasticityVienRiveraNessuna valutazione finora
- Danh Sach Khach Hang VIP Diamond PlazaDocumento9 pagineDanh Sach Khach Hang VIP Diamond PlazaHiệu chuẩn Hiệu chuẩnNessuna valutazione finora
- Scope of Internet As A ICTDocumento10 pagineScope of Internet As A ICTJohnNessuna valutazione finora
- EE1000 DC Networks Problem SetDocumento7 pagineEE1000 DC Networks Problem SetAmit DipankarNessuna valutazione finora
- Heat TreatmentsDocumento14 pagineHeat Treatmentsravishankar100% (1)
- QuizDocumento11 pagineQuizDanica RamosNessuna valutazione finora
- Preventive Maintenance - HematologyDocumento5 paginePreventive Maintenance - HematologyBem GarciaNessuna valutazione finora
- In Partial Fulfillment of The Requirements For The Award of The Degree ofDocumento66 pagineIn Partial Fulfillment of The Requirements For The Award of The Degree ofcicil josyNessuna valutazione finora
- Sacmi Vol 2 Inglese - II EdizioneDocumento416 pagineSacmi Vol 2 Inglese - II Edizionecuibaprau100% (21)
- Digital Documentation Class 10 NotesDocumento8 pagineDigital Documentation Class 10 NotesRuby Khatoon86% (7)
- Payment of GratuityDocumento5 paginePayment of Gratuitypawan2225Nessuna valutazione finora
- Starkville Dispatch Eedition 12-9-18Documento28 pagineStarkville Dispatch Eedition 12-9-18The DispatchNessuna valutazione finora
- BMT6138 Advanced Selling and Negotiation Skills: Digital Assignment-1Documento9 pagineBMT6138 Advanced Selling and Negotiation Skills: Digital Assignment-1Siva MohanNessuna valutazione finora
- T3A-T3L Servo DriverDocumento49 pagineT3A-T3L Servo DriverRodrigo Salazar71% (7)
- Lenskart SheetDocumento1 paginaLenskart SheetThink School libraryNessuna valutazione finora
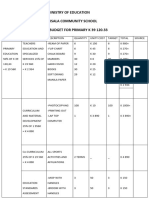
- Ministry of Education Musala SCHDocumento5 pagineMinistry of Education Musala SCHlaonimosesNessuna valutazione finora
- Surface CareDocumento18 pagineSurface CareChristi ThomasNessuna valutazione finora
- Danube Coin LaundryDocumento29 pagineDanube Coin LaundrymjgosslerNessuna valutazione finora