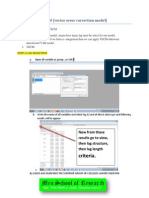
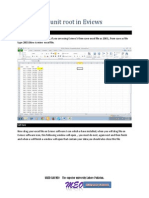
Potrebbero piacerti anche
- Grant Proposal Template: Project SummaryDocumento3 pagineGrant Proposal Template: Project SummaryKoraljka Rozic50% (2)
- Stat443 Final2018 PDFDocumento4 pagineStat443 Final2018 PDFTongtong ZhaiNessuna valutazione finora
- Chapter Twenty - Time SeriesDocumento21 pagineChapter Twenty - Time SeriesSDB_EconometricsNessuna valutazione finora
- EC310K: Effect of US Food Aid on ConflictDocumento2 pagineEC310K: Effect of US Food Aid on ConflictRO BWNNessuna valutazione finora
- 3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013Documento37 pagine3 Multiple Linear Regression: Estimation and Properties: Ezequiel Uriel Universidad de Valencia Version: 09-2013penyia100% (1)
- Time Sereis Analysis Using StataDocumento26 pagineTime Sereis Analysis Using Statasaeed meo100% (6)
- An Introduction To Stata For Economists: Data AnalysisDocumento48 pagineAn Introduction To Stata For Economists: Data AnalysisXiaoying XuNessuna valutazione finora
- Structural Equation Modeling in StataDocumento10 pagineStructural Equation Modeling in StatajamazalaleNessuna valutazione finora
- VAR Lecture2Documento39 pagineVAR Lecture2Udita GopalkrishnaNessuna valutazione finora
- Forecasting Paddy Production in Trincomalee District Using ARIMAX ModelsDocumento5 pagineForecasting Paddy Production in Trincomalee District Using ARIMAX ModelsAgus Setiansyah Idris ShalehNessuna valutazione finora
- 578assignment2 F14 SolDocumento15 pagine578assignment2 F14 Solaman_nsuNessuna valutazione finora
- VAR Models ExplainedDocumento8 pagineVAR Models Explainedv4nhuy3nNessuna valutazione finora
- Generalized Method of Moments (GMM) Estimation: OutlineDocumento16 pagineGeneralized Method of Moments (GMM) Estimation: OutlineDione BhaskaraNessuna valutazione finora
- Introduction To Vars and Structural Vars:: Estimation & Tests Using StataDocumento69 pagineIntroduction To Vars and Structural Vars:: Estimation & Tests Using StataMohammed Al-SubaieNessuna valutazione finora
- Slides 2-04 - The ARMA Model and Model Selection PDFDocumento14 pagineSlides 2-04 - The ARMA Model and Model Selection PDFEduardo SeminarioNessuna valutazione finora
- Measuring The Sustainabili Ty of Cities An Analysis of The Use of Local IndicatorsDocumento12 pagineMeasuring The Sustainabili Ty of Cities An Analysis of The Use of Local IndicatorsVicky CeunfinNessuna valutazione finora
- ARIMAXDocumento10 pagineARIMAXRyubi FarNessuna valutazione finora
- Okun Law Pakisatn 1Documento7 pagineOkun Law Pakisatn 1Ali ArsalanNessuna valutazione finora
- Metrics Final Slides From Darmouth PDFDocumento126 pagineMetrics Final Slides From Darmouth PDFNarutoLLNNessuna valutazione finora
- STATA Data PanelDocumento11 pagineSTATA Data PanelalbertolossNessuna valutazione finora
- PowerBI Handwritten NoteDocumento2 paginePowerBI Handwritten NoteririxayNessuna valutazione finora
- Linear Statistical Models The Less Than Full Rank Model: Yao-Ban ChanDocumento140 pagineLinear Statistical Models The Less Than Full Rank Model: Yao-Ban ChanJack WangNessuna valutazione finora
- Empirical Analysis of The Relationship Between Economic Growth and Energy Consumption in Nigeria: A Multivariate Cointegration ApproachDocumento12 pagineEmpirical Analysis of The Relationship Between Economic Growth and Energy Consumption in Nigeria: A Multivariate Cointegration ApproachTI Journals PublishingNessuna valutazione finora
- Char LieDocumento64 pagineChar LieppecNessuna valutazione finora
- Application of VAR Model AnalysisDocumento22 pagineApplication of VAR Model AnalysisEason SaintNessuna valutazione finora
- Panel Data Models: Dynamic Panels and Unit RootsDocumento20 paginePanel Data Models: Dynamic Panels and Unit RootsJeremiahOmwoyoNessuna valutazione finora
- Impact of Student Engagement On Academic Performance and Quality of Relationships of Traditional and Nontraditional StudentsDocumento22 pagineImpact of Student Engagement On Academic Performance and Quality of Relationships of Traditional and Nontraditional StudentsGeorge GomezNessuna valutazione finora
- Between Within Stata AnalysisDocumento3 pagineBetween Within Stata AnalysisMaria PappaNessuna valutazione finora
- Statistics 578 Assignemnt 3Documento12 pagineStatistics 578 Assignemnt 3Mia Dee100% (1)
- TSExamples PDFDocumento9 pagineTSExamples PDFKhalilNessuna valutazione finora
- Var Models and Granger CausalityDocumento38 pagineVar Models and Granger CausalityzoeNessuna valutazione finora
- Quantitative Methods & Logical Reasoning Question Bank Unit-IDocumento27 pagineQuantitative Methods & Logical Reasoning Question Bank Unit-IaymanNessuna valutazione finora
- Time Series - Practical ExercisesDocumento9 pagineTime Series - Practical ExercisesJobayer Islam TunanNessuna valutazione finora
- The Practice of Econometrics Analysis Using EViews Software: Unit Root, Cointegration and Causality Tests (39Documento25 pagineThe Practice of Econometrics Analysis Using EViews Software: Unit Root, Cointegration and Causality Tests (39Min Fong LawNessuna valutazione finora
- BA 578 Live Fin Set2Documento17 pagineBA 578 Live Fin Set2Sumana Salauddin100% (1)
- Sections 2.1 - 2.3: Mind On StatisticsDocumento22 pagineSections 2.1 - 2.3: Mind On StatisticsMahmoud Ayoub GodaNessuna valutazione finora
- Univariate Time Series Modelling and Forecasting: An ExampleDocumento72 pagineUnivariate Time Series Modelling and Forecasting: An Examplejamesburden100% (1)
- Time Series QuestionsDocumento9 pagineTime Series Questionsakriti_08100% (1)
- CPT Section D Quantitative Aptitude Chapter12 Regression AnalysisDocumento66 pagineCPT Section D Quantitative Aptitude Chapter12 Regression AnalysisRanga SriNessuna valutazione finora
- Introduction to Regression Models for Panel Data Analysis WorkshopDocumento42 pagineIntroduction to Regression Models for Panel Data Analysis WorkshopAnonymous 0sxQqwAIMBNessuna valutazione finora
- Microeconometrics Lecture NotesDocumento407 pagineMicroeconometrics Lecture NotesburgguNessuna valutazione finora
- Time Series Models and Forecasting and ForecastingDocumento49 pagineTime Series Models and Forecasting and ForecastingDominic AndohNessuna valutazione finora
- TS PartIIDocumento50 pagineTS PartIIأبوسوار هندسةNessuna valutazione finora
- Basic time series concepts ARMA and ARIMADocumento86 pagineBasic time series concepts ARMA and ARIMAane9sdNessuna valutazione finora
- GMM Resume PDFDocumento60 pagineGMM Resume PDFdamian camargoNessuna valutazione finora
- DSE Super 20 Solutions: DSE entrance 2016 exam problemsDocumento20 pagineDSE Super 20 Solutions: DSE entrance 2016 exam problemsshakthiNessuna valutazione finora
- MCQ 12765 KDocumento21 pagineMCQ 12765 Kcool_spNessuna valutazione finora
- Cointegration PDFDocumento76 pagineCointegration PDFVaishali SharmaNessuna valutazione finora
- ArimaDocumento4 pagineArimaSofia LivelyNessuna valutazione finora
- 2015 Midterm SolutionsDocumento7 pagine2015 Midterm SolutionsEdith Kua100% (1)
- Examples FTSA Questions2Documento18 pagineExamples FTSA Questions2Anonymous 7CxwuBUJz3Nessuna valutazione finora
- New Multivariate Time-Series Estimators in Stata 11Documento34 pagineNew Multivariate Time-Series Estimators in Stata 11Aviral Kumar TiwariNessuna valutazione finora
- Panel Data AnalysisDocumento8 paginePanel Data AnalysisAditya Kumar SinghNessuna valutazione finora
- Lecture 7 VARDocumento34 pagineLecture 7 VAREason SaintNessuna valutazione finora
- Study Guide For ECO 3411Documento109 pagineStudy Guide For ECO 3411asd1084Nessuna valutazione finora
- Arimax ArimaDocumento57 pagineArimax ArimaTeresaMadurai100% (1)
- Econometrics of Panel Data ModelsDocumento34 pagineEconometrics of Panel Data Modelsarmailgm100% (1)
- Panel Data 1Documento6 paginePanel Data 1Abdul AzizNessuna valutazione finora
- Class 10 Multilevel ModelsDocumento42 pagineClass 10 Multilevel Modelshubik38Nessuna valutazione finora
- VECMDocumento9 pagineVECMsaeed meo100% (3)
- Oracle LearningsDocumento8 pagineOracle LearningsG RajakannuNessuna valutazione finora
- Summer 2020 Updated Class Schedule MCDocumento10 pagineSummer 2020 Updated Class Schedule MCSayed Farrukh AhmedNessuna valutazione finora
- Completion of The Accounting CycleDocumento54 pagineCompletion of The Accounting CycleSayed Farrukh AhmedNessuna valutazione finora
- Analysis of Credit Management System of Jamuna Bank Limited (JBL)Documento38 pagineAnalysis of Credit Management System of Jamuna Bank Limited (JBL)Sayed Farrukh AhmedNessuna valutazione finora
- Data Co2Documento15 pagineData Co2Sayed Farrukh AhmedNessuna valutazione finora
- Bye ByeDocumento1 paginaBye ByeSayed Farrukh AhmedNessuna valutazione finora
- Intercorporate Acquisitions and Investments in Other EntitiesDocumento31 pagineIntercorporate Acquisitions and Investments in Other EntitiesSayed Farrukh AhmedNessuna valutazione finora
- FDI's Impact on SAARC Nations' Economic GrowthDocumento17 pagineFDI's Impact on SAARC Nations' Economic GrowthSayed Farrukh AhmedNessuna valutazione finora
- Data Co2Documento15 pagineData Co2Sayed Farrukh AhmedNessuna valutazione finora
- FDI and Exports Impact Economic Growth in South AfricaDocumento24 pagineFDI and Exports Impact Economic Growth in South AfricaSayed Farrukh AhmedNessuna valutazione finora
- Chapter 21: Accounting For LeasesDocumento28 pagineChapter 21: Accounting For LeasesSayed Farrukh Ahmed100% (1)
- Cross-Sectional Dependence-Good PDFDocumento16 pagineCross-Sectional Dependence-Good PDFSayed Farrukh AhmedNessuna valutazione finora
- Good WDocumento1 paginaGood WSayed Farrukh AhmedNessuna valutazione finora
- Macroeconomic Forces and Stock Prices in BangladeshDocumento55 pagineMacroeconomic Forces and Stock Prices in BangladeshSayed Farrukh AhmedNessuna valutazione finora
- Cross-Sectional Dependence-Good PDFDocumento16 pagineCross-Sectional Dependence-Good PDFSayed Farrukh AhmedNessuna valutazione finora
- CH 03Documento91 pagineCH 03Sayed Farrukh AhmedNessuna valutazione finora
- Accounting Principles: The Recording ProcessDocumento55 pagineAccounting Principles: The Recording ProcessSayed Farrukh AhmedNessuna valutazione finora
- New Microsoft Office Excel WorksheetDocumento1 paginaNew Microsoft Office Excel WorksheetSayed Farrukh AhmedNessuna valutazione finora
- My WonrkDocumento1 paginaMy WonrkSayed Farrukh AhmedNessuna valutazione finora
- New Microsoft Office Word DocumentDocumento2 pagineNew Microsoft Office Word DocumentSayed Farrukh AhmedNessuna valutazione finora
- Lcpi Lgdps Lgi Lint Lcpi (-3) Lgdps (-3) Lgi (-3) Lint (-3)Documento2 pagineLcpi Lgdps Lgi Lint Lcpi (-3) Lgdps (-3) Lgi (-3) Lint (-3)Sayed Farrukh AhmedNessuna valutazione finora
- Chapter 21: Accounting For LeasesDocumento28 pagineChapter 21: Accounting For LeasesSayed Farrukh Ahmed100% (1)
- Panel Data RepresentationDocumento2 paginePanel Data RepresentationSayed Farrukh AhmedNessuna valutazione finora
- Today 2017Documento1 paginaToday 2017Sayed Farrukh AhmedNessuna valutazione finora
- LankaBangla Securities trade confirmationDocumento1 paginaLankaBangla Securities trade confirmationSayed Farrukh AhmedNessuna valutazione finora
- LankaBangla Securities trade confirmationDocumento1 paginaLankaBangla Securities trade confirmationSayed Farrukh AhmedNessuna valutazione finora
- Time Series Analysis and ARDL Modeling in StataDocumento26 pagineTime Series Analysis and ARDL Modeling in StataSayed Farrukh AhmedNessuna valutazione finora
- Granger CusalityDocumento4 pagineGranger CusalitySayed Farrukh AhmedNessuna valutazione finora
- VECMDocumento9 pagineVECMsaeed meo100% (3)
- Unit Root Using EviewDocumento9 pagineUnit Root Using Eviewsaeed meo75% (4)
- Large Scale Guided Wave TestingDocumento4 pagineLarge Scale Guided Wave Testingkhanz88_rulz1039Nessuna valutazione finora
- DrAshrafElsafty ResearchMehods ESLSCA July12Documento297 pagineDrAshrafElsafty ResearchMehods ESLSCA July12mezo_noniNessuna valutazione finora
- Certificate in Mera Lund 195709294Documento2 pagineCertificate in Mera Lund 195709294Rohit SinghNessuna valutazione finora
- Clinical Tools For The Assessment of Pain in Sedated Critically Ill AdultsDocumento10 pagineClinical Tools For The Assessment of Pain in Sedated Critically Ill AdultsEviNessuna valutazione finora
- 2 Simple Regression Model Estimation and PropertiesDocumento48 pagine2 Simple Regression Model Estimation and PropertiesMuhammad Chaudhry100% (1)
- TQM Seven Tool For MangementDocumento33 pagineTQM Seven Tool For MangementMuneeb JavaidNessuna valutazione finora
- Quantitative Analysis and Business Decisions: Decision Making Under RiskDocumento4 pagineQuantitative Analysis and Business Decisions: Decision Making Under RiskSiva Prasad PasupuletiNessuna valutazione finora
- Appendix B Load TestDocumento17 pagineAppendix B Load Testanjas_tsNessuna valutazione finora
- Ogl 357 Module 7 - Milestone ThreeDocumento17 pagineOgl 357 Module 7 - Milestone Threeapi-632529970Nessuna valutazione finora
- Attitudes, Motivation, and Self-Efficacy in LearningDocumento51 pagineAttitudes, Motivation, and Self-Efficacy in Learningpattymosq1992100% (1)
- Patient Satisfaction SurveyDocumento113 paginePatient Satisfaction SurveyCherry Mae L. Villanueva100% (1)
- BP Industry Safety AlertDocumento2 pagineBP Industry Safety AlertWahyu Wicaksono100% (1)
- 5.1 Mining Data StreamsDocumento16 pagine5.1 Mining Data StreamsRaj EndranNessuna valutazione finora
- Table of Contents Hand MoisturizerDocumento3 pagineTable of Contents Hand MoisturizerDavidNessuna valutazione finora
- Status Report On Broadband and Broadcast Access in The State of Madhya PradeshDocumento52 pagineStatus Report On Broadband and Broadcast Access in The State of Madhya PradeshVikas SamvadNessuna valutazione finora
- Action Research Academic Performance of Kindergarten Pupils With Parents Involvements of Tandag Central Elementry School (Tandag City Division)Documento8 pagineAction Research Academic Performance of Kindergarten Pupils With Parents Involvements of Tandag Central Elementry School (Tandag City Division)KLeb VillalozNessuna valutazione finora
- Sigma TechDocumento16 pagineSigma TechㄎㄎㄎㄎNessuna valutazione finora
- Scoring Matrices PSSMDocumento17 pagineScoring Matrices PSSMrayx_1Nessuna valutazione finora
- A Phenomenological Study of The Impact of Electronic Gadgets Among Abm StudentsDocumento55 pagineA Phenomenological Study of The Impact of Electronic Gadgets Among Abm StudentsJelou CuestasNessuna valutazione finora
- MANANANGGALDocumento3 pagineMANANANGGALJeminah PauneNessuna valutazione finora
- Adb9 Bsbpmg517 Manage Project RiskDocumento140 pagineAdb9 Bsbpmg517 Manage Project RiskLili Pabuena VillarrealNessuna valutazione finora
- Avery Sporting GoodsDocumento15 pagineAvery Sporting GoodsKodem JohnsonNessuna valutazione finora
- Chinmulgund FDocumento6 pagineChinmulgund FPushpamNessuna valutazione finora
- IMC Based PID Controllers Retuning and It's Performance AssessmentDocumento8 pagineIMC Based PID Controllers Retuning and It's Performance AssessmentdivyaNessuna valutazione finora
- Literature Review Example MathematicsDocumento5 pagineLiterature Review Example Mathematicsaehupavkg100% (1)
- 2015 08 26 Adverse Event Report and Investigation FormDocumento8 pagine2015 08 26 Adverse Event Report and Investigation FormSt Mary Redcliffe ChurchNessuna valutazione finora
- Qsa Questionnaire ConclusionsDocumento1 paginaQsa Questionnaire Conclusionsapi-297068612Nessuna valutazione finora
- Practical Research 1 Human RightsDocumento15 paginePractical Research 1 Human Rightsphoebe lhou gadgad catao-anNessuna valutazione finora
- Lesson 3 - SCM PDFDocumento24 pagineLesson 3 - SCM PDFPam G.Nessuna valutazione finora