Potrebbero piacerti anche
- Final 2Documento1 paginaFinal 2MJ CARVAJALNessuna valutazione finora
- Bajaj Auto - BIDADocumento26 pagineBajaj Auto - BIDASandeep SagarNessuna valutazione finora
- E-Brosure Water TerraceDocumento20 pagineE-Brosure Water TerraceM Rifqi PT. Ryuu IndustryNessuna valutazione finora
- Input Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufDocumento2 pagineInput Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufMark Anthony Salazar ArcayanNessuna valutazione finora
- FP (Plan) - 1Documento1 paginaFP (Plan) - 1Boknoy DrilonNessuna valutazione finora
- CE168P-2 S-Curve SampleDocumento4 pagineCE168P-2 S-Curve SampleCat BugNessuna valutazione finora
- Green Synthesis of Fe Nanoparticles Using Citrus Maxima Peels Aqueous ExtractsDocumento2 pagineGreen Synthesis of Fe Nanoparticles Using Citrus Maxima Peels Aqueous ExtractsDavid SeguinNessuna valutazione finora
- Tarea Economia GeneralDocumento2 pagineTarea Economia GeneralAndres OlmosNessuna valutazione finora
- Recurring Expenses No People PeopleDocumento4 pagineRecurring Expenses No People PeoplePradeep PanigrahiNessuna valutazione finora
- Inflow Performance RelationshipDocumento3 pagineInflow Performance Relationshippandu ariefNessuna valutazione finora
- Resource Utilization Sheet - 1Documento17 pagineResource Utilization Sheet - 1Ujjal RegmiNessuna valutazione finora
- BdryDocumento8 pagineBdrycat buenafeNessuna valutazione finora
- Brochure Cluster - The Mahogany Residence (Final) PDFDocumento21 pagineBrochure Cluster - The Mahogany Residence (Final) PDFTkko riastoNessuna valutazione finora
- Construction Industry AnalysisDocumento132 pagineConstruction Industry AnalysisEleanorXuNessuna valutazione finora
- Thruster Disc Brakes SB 8 Series: Pintsch BubenzerDocumento7 pagineThruster Disc Brakes SB 8 Series: Pintsch BubenzerJose Luis Vivanco MontenegroNessuna valutazione finora
- Drafting Individual Project REPORT CE0105815Documento4 pagineDrafting Individual Project REPORT CE0105815Keith TayNessuna valutazione finora
- Graph ValvesDocumento2 pagineGraph ValvesPriyankNessuna valutazione finora
- Thruster Disc Brakes SB 8 Series: Pintsch BubenzerDocumento7 pagineThruster Disc Brakes SB 8 Series: Pintsch Bubenzersholhan azizNessuna valutazione finora
- C:/Users/USER/Desktop/LAPORAN KP/download - PNGDocumento1 paginaC:/Users/USER/Desktop/LAPORAN KP/download - PNGJesica SuyantoNessuna valutazione finora
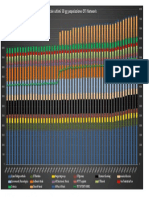
- Totale50 OTI Network StatsDocumento1 paginaTotale50 OTI Network StatsFranco ScaccoNessuna valutazione finora
- Differential Plot: Mean Size FractionDocumento2 pagineDifferential Plot: Mean Size FractionZain Ali ZingNessuna valutazione finora
- Strategy MapsDocumento2 pagineStrategy Mapsprincemech2004Nessuna valutazione finora
- Mecanismos de Freios IndustriaisDocumento60 pagineMecanismos de Freios IndustriaisfabioNessuna valutazione finora
- Denah Pondasi Revisi 2Documento1 paginaDenah Pondasi Revisi 2Dion IndrazNessuna valutazione finora
- Part 1 Cost BaselineDocumento2 paginePart 1 Cost BaselineMohammad NaumanNessuna valutazione finora
- Oshiyie Site Organizational Layout PDFDocumento1 paginaOshiyie Site Organizational Layout PDFNana BarimaNessuna valutazione finora
- Oshiyie Site Organizational LayoutDocumento1 paginaOshiyie Site Organizational LayoutNana BarimaNessuna valutazione finora
- Oshiyie Site Organizational Layout PDFDocumento1 paginaOshiyie Site Organizational Layout PDFNana BarimaNessuna valutazione finora
- Trial - EUL-DCH Load BalancingDocumento10 pagineTrial - EUL-DCH Load BalancingkafleNessuna valutazione finora
- F3A1 Carbon.2.fid F3A1 CarbonDocumento1 paginaF3A1 Carbon.2.fid F3A1 Carbonzinebzinebberr berryNessuna valutazione finora
- Brake Systems For Mining EnglishDocumento96 pagineBrake Systems For Mining Englisht1o2n3i4Nessuna valutazione finora
- OSHYIYEDocumento1 paginaOSHYIYENana BarimaNessuna valutazione finora
- Denah Villa 150Documento1 paginaDenah Villa 150Tian AryoNessuna valutazione finora
- Selling Price Per Unit, S (RM) Estimated Yearly Demand, D (Units) 75 4500 125 3500 200 2000 250 1000Documento2 pagineSelling Price Per Unit, S (RM) Estimated Yearly Demand, D (Units) 75 4500 125 3500 200 2000 250 1000Filzahtuln FarihahNessuna valutazione finora
- Cumulative CostDocumento1 paginaCumulative CostadlenaNessuna valutazione finora
- Graph 3 PipesDocumento4 pagineGraph 3 PipesPriyankNessuna valutazione finora
- Graph 3 PipesDocumento4 pagineGraph 3 PipesPriyankNessuna valutazione finora
- JMKW Construction Supplies Trading: Petty Cash Fund ReplenishmentDocumento2 pagineJMKW Construction Supplies Trading: Petty Cash Fund ReplenishmentPepeng DmatNessuna valutazione finora
- Movilor DC MotorDocumento4 pagineMovilor DC MotorNurhayadi AmankNessuna valutazione finora
- So-Ing-p01-Kbr Informe Esp Part 5Documento109 pagineSo-Ing-p01-Kbr Informe Esp Part 5VeroNessuna valutazione finora
- Laydown Area For Bullet Option-1Documento1 paginaLaydown Area For Bullet Option-1vikneshNessuna valutazione finora
- MBG Vs Service Radius Profit Vs Service RadiusDocumento6 pagineMBG Vs Service Radius Profit Vs Service RadiuschetanaNessuna valutazione finora
- MBG Vs Service Radius Profit Vs Service RadiusDocumento8 pagineMBG Vs Service Radius Profit Vs Service RadiuschetanaNessuna valutazione finora
- 21pgdm066 - Harshita Mishra - Eco 03Documento5 pagine21pgdm066 - Harshita Mishra - Eco 03Harshita MishraNessuna valutazione finora
- SLIIT Lecture 8 Work Example Sheets To PrintDocumento6 pagineSLIIT Lecture 8 Work Example Sheets To PrintV. OlukaNessuna valutazione finora
- Live Load RDDocumento1 paginaLive Load RDMark JangadNessuna valutazione finora
- The Pioneer - August - September 07Documento20 pagineThe Pioneer - August - September 07nilnilen2009Nessuna valutazione finora
- RMS 0-40000 (KXGS-G TPS) L528 - 61 Rev0012Documento1 paginaRMS 0-40000 (KXGS-G TPS) L528 - 61 Rev0012ufficio.tecnicoNessuna valutazione finora
- 主機維修保養手冊Documento1 pagina主機維修保養手冊a1021332124Nessuna valutazione finora
- Management Accounting Tasks and SolutionDocumento2 pagineManagement Accounting Tasks and SolutionandrewsmithtaderNessuna valutazione finora
- B-H Curve For 1018 SteelDocumento1 paginaB-H Curve For 1018 SteelMaycon MaranNessuna valutazione finora
- Civil Engineering Construction Project (Ecm 317) : Group MembersDocumento28 pagineCivil Engineering Construction Project (Ecm 317) : Group MembersSafi HusseinNessuna valutazione finora
- Homework 2 PDFDocumento1 paginaHomework 2 PDFDa RaNessuna valutazione finora
- Benzene-Toluene Enthalpy Conc Diagram at P 1 Atm: Mole Fraction Benzene in Liquid, XDocumento1 paginaBenzene-Toluene Enthalpy Conc Diagram at P 1 Atm: Mole Fraction Benzene in Liquid, XcarmelclaireNessuna valutazione finora
- Workshop 5 - Multicollinearity and Functional FormDocumento77 pagineWorkshop 5 - Multicollinearity and Functional FormDoan Anh TuanNessuna valutazione finora
- Tangent ModulusDocumento7 pagineTangent ModulusNobel AsresuNessuna valutazione finora
- Group 2 - Automobile Industry - Strategic Management ProjectDocumento9 pagineGroup 2 - Automobile Industry - Strategic Management ProjectVatsala MishraNessuna valutazione finora
- Hammarby Sjöstad: Malin Olsson, Head of Section, Stockholm City Planning AdmDocumento27 pagineHammarby Sjöstad: Malin Olsson, Head of Section, Stockholm City Planning AdmShiva MohanNessuna valutazione finora
- Graph ContractionDocumento2 pagineGraph ContractionPriyankNessuna valutazione finora
- Azure Networking Cookbook2Documento1 paginaAzure Networking Cookbook2p001Nessuna valutazione finora
- Azure Networking Cookbook5 PDFDocumento1 paginaAzure Networking Cookbook5 PDFp001Nessuna valutazione finora
- Azure Networking Cookbook1Documento1 paginaAzure Networking Cookbook1p001Nessuna valutazione finora
- Preface Xi Chapter 1: Azure Virtual Network 1Documento1 paginaPreface Xi Chapter 1: Azure Virtual Network 1p001Nessuna valutazione finora
- Azure Networking Cookbook2 PDFDocumento1 paginaAzure Networking Cookbook2 PDFp001Nessuna valutazione finora
- Exit Strategy For COVID-19 Lockdown - FINAL - CDMT Publication 31Documento1 paginaExit Strategy For COVID-19 Lockdown - FINAL - CDMT Publication 31p001Nessuna valutazione finora
- 2019 National Merit Scholars CaliforniaDocumento1 pagina2019 National Merit Scholars Californiap001Nessuna valutazione finora
- How Do I Prepare For A Software Engineering Job Interview?: 100+ AnswersDocumento1 paginaHow Do I Prepare For A Software Engineering Job Interview?: 100+ Answersp001Nessuna valutazione finora
- How To Prepare For A Software Engineering Job Interview - Quora2Documento1 paginaHow To Prepare For A Software Engineering Job Interview - Quora2p001Nessuna valutazione finora
- A Guide To Writing The Perfect College Essay: PreminenteDocumento1 paginaA Guide To Writing The Perfect College Essay: Preminentep001Nessuna valutazione finora
- Example 2.10 (Vietnam 1998) : Eliminating Radicals and FractionsDocumento1 paginaExample 2.10 (Vietnam 1998) : Eliminating Radicals and Fractionsp001Nessuna valutazione finora
- 2019 National Merit Scholars CaliforniaDocumento1 pagina2019 National Merit Scholars Californiap001Nessuna valutazione finora
- How To Prepare For A Software Engineering Job Interview - Quora3Documento1 paginaHow To Prepare For A Software Engineering Job Interview - Quora3p001Nessuna valutazione finora
- 2computer Science Principles Digital Portfolio Student GuideDocumento1 pagina2computer Science Principles Digital Portfolio Student Guidep001Nessuna valutazione finora
- Singapore Mathematical SocietyDocumento1 paginaSingapore Mathematical Societyp001Nessuna valutazione finora
- S 7Documento1 paginaS 7p001Nessuna valutazione finora
- Supplemental Guidelines To California Adjustments: General InformationDocumento1 paginaSupplemental Guidelines To California Adjustments: General Informationp001Nessuna valutazione finora
- S 8Documento1 paginaS 8p001Nessuna valutazione finora
- Evan Chen (April 30, 2014) A Brief Introduction To Olympiad InequalitiesDocumento1 paginaEvan Chen (April 30, 2014) A Brief Introduction To Olympiad Inequalitiesp001Nessuna valutazione finora
- Practice ProblemsDocumento1 paginaPractice Problemsp001Nessuna valutazione finora
- 'JJYJ - J 20!.0MIV/nDocumento1 pagina'JJYJ - J 20!.0MIV/np001Nessuna valutazione finora
- A Brief Introduction To Olympiad Inequalities: April 30, 2014Documento1 paginaA Brief Introduction To Olympiad Inequalities: April 30, 2014p001Nessuna valutazione finora
- En 5Documento1 paginaEn 5p001Nessuna valutazione finora
- Example 2.7 (Japan) : Evan Chen (April 30, 2014) A Brief Introduction To Olympiad InequalitiesDocumento1 paginaExample 2.7 (Japan) : Evan Chen (April 30, 2014) A Brief Introduction To Olympiad Inequalitiesp001Nessuna valutazione finora
- Inequalities in Arbitrary Functions: Jensen / KaramataDocumento1 paginaInequalities in Arbitrary Functions: Jensen / Karamatap001Nessuna valutazione finora
- Example 1.2: Evan Chen (April 30, 2014) A Brief Introduction To Olympiad InequalitiesDocumento1 paginaExample 1.2: Evan Chen (April 30, 2014) A Brief Introduction To Olympiad Inequalitiesp001Nessuna valutazione finora
- Lec 15 - 17 (SQL FUNCTIONS)Documento38 pagineLec 15 - 17 (SQL FUNCTIONS)Latest GadgetsNessuna valutazione finora
- Complete File Management System Source Code Using PHP - MySQLi Version 1.1 - Free Source Code, Projects & TutorialsDocumento3 pagineComplete File Management System Source Code Using PHP - MySQLi Version 1.1 - Free Source Code, Projects & TutorialsDani Adugna100% (1)
- Acn PDFDocumento4 pagineAcn PDFmaldiniNessuna valutazione finora
- Scaleout Users GuideDocumento347 pagineScaleout Users Guideerrr33Nessuna valutazione finora
- Operating SystemsDocumento91 pagineOperating SystemssmiNessuna valutazione finora
- Aging ReportDocumento37 pagineAging ReportsupreethNessuna valutazione finora
- Mobile DBMSDocumento34 pagineMobile DBMSTech_MX100% (1)
- A Simple and Easy-To-Use Library To Enjoy Videogames ProgrammingDocumento5 pagineA Simple and Easy-To-Use Library To Enjoy Videogames ProgrammingChandra suriyaNessuna valutazione finora
- Following Are The Multiple Choice QuestionsDocumento6 pagineFollowing Are The Multiple Choice Questionsmax4oneNessuna valutazione finora
- AS400 Interview Questions For AllDocumento272 pagineAS400 Interview Questions For Allsharuk100% (2)
- HCIP-Routing & Switching-IENP V2.5 Exam Outline PDFDocumento3 pagineHCIP-Routing & Switching-IENP V2.5 Exam Outline PDFصلاح الدينNessuna valutazione finora
- SAS Interview QuestionsDocumento33 pagineSAS Interview Questionsapi-384083286% (7)
- Basic 'Select' Exercises: Mysql Task 3Documento4 pagineBasic 'Select' Exercises: Mysql Task 3Sweety PrasadNessuna valutazione finora
- Lecture 1 - Introduction To Data ScienceDocumento39 pagineLecture 1 - Introduction To Data ScienceKhan PkNessuna valutazione finora
- WhatsnewDocumento40 pagineWhatsnewchristianNessuna valutazione finora
- HashSet and HashMapDocumento2 pagineHashSet and HashMapArala FolaNessuna valutazione finora
- FFmpeg StreamingDocumento5 pagineFFmpeg StreaminganyuserNessuna valutazione finora
- Basic Linux Commands PDFDocumento8 pagineBasic Linux Commands PDFDipesh YadavNessuna valutazione finora
- Database Programming With PL/SQL 4-2: Practice Activities: Conditional Control: Case StatementsDocumento5 pagineDatabase Programming With PL/SQL 4-2: Practice Activities: Conditional Control: Case StatementsАбзал КалдыбековNessuna valutazione finora
- SQL Server SsmsDocumento86 pagineSQL Server SsmsAdrian MagpantayNessuna valutazione finora
- Sap BW Data Modeling GuideDocumento18 pagineSap BW Data Modeling GuideSapbi SriNessuna valutazione finora
- 1b (V2.0) Softswitch Control Equipment Technical ManualDocumento96 pagine1b (V2.0) Softswitch Control Equipment Technical ManualDung Tran0% (1)
- 8 Best Python Cheat Sheets For Beginners and Intermediate LearnersDocumento13 pagine8 Best Python Cheat Sheets For Beginners and Intermediate LearnersJoseph Jung100% (1)
- Assignment-2 MODULE-3:: DBMS-18CS53Documento3 pagineAssignment-2 MODULE-3:: DBMS-18CS53neelagundNessuna valutazione finora
- A1 CyberthreatsDocumento2 pagineA1 Cyberthreatsapi-459808522Nessuna valutazione finora
- How To Connect To MySQL Using PHPDocumento3 pagineHow To Connect To MySQL Using PHPSsekabira DavidNessuna valutazione finora
- Presentasi Phase 1 Program FGDP It RepDocumento20 paginePresentasi Phase 1 Program FGDP It RepOky WijayaNessuna valutazione finora
- Sap Bo Fim Fi 10 User enDocumento88 pagineSap Bo Fim Fi 10 User enAakriti ChNessuna valutazione finora
- UntitledDocumento200 pagineUntitledDF PR00% (2)
- RaspbianInstaller - RaspbianDocumento6 pagineRaspbianInstaller - Raspbianclaudiu72Nessuna valutazione finora