Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Ultimate Baccarat StrategyDocumento151 pagineUltimate Baccarat Strategydocreview984% (25)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Pick 4 Strategy - Win The Pick 4 Lottery With Series NumbersDocumento2 paginePick 4 Strategy - Win The Pick 4 Lottery With Series NumbersRobert Walsh64% (14)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Description of Bluffing GameDocumento4 pagineDescription of Bluffing GameDivyesh DixitNessuna valutazione finora
- The Poker BlueprintDocumento171 pagineThe Poker BlueprintBlake Mason100% (10)
- POKER - Increasing Aggression PDFDocumento26 paginePOKER - Increasing Aggression PDFScalabrin Matheus GirardiNessuna valutazione finora
- TargetBaccarat BookDocumento152 pagineTargetBaccarat Bookprashshine100% (1)
- Power Holdem Strategy - Compressed (0001 0250)Documento250 paginePower Holdem Strategy - Compressed (0001 0250)Anonymous 8JMg5fmNessuna valutazione finora
- Lottery ResultDocumento2 pagineLottery ResultARJUNNessuna valutazione finora
- California Antique Slots Bally E1000Documento3 pagineCalifornia Antique Slots Bally E1000Tim WillformNessuna valutazione finora
- IndexDocumento72 pagineIndexSemen sebrioNessuna valutazione finora
- New York Two-Dimensional Lotto App For Lottery Winner PDFDocumento9 pagineNew York Two-Dimensional Lotto App For Lottery Winner PDFDragos George SpataruNessuna valutazione finora
- The Fletcher Formula-Book PDFDocumento168 pagineThe Fletcher Formula-Book PDFSunn AaryaNessuna valutazione finora
- Black JackDocumento9 pagineBlack Jackdario magnetoNessuna valutazione finora
- Numicon Bingo Game - SFLBDocumento21 pagineNumicon Bingo Game - SFLBchiquimary28Nessuna valutazione finora
- Ed Miller's Building A No-Limit Hold'Em Starting Hand ChartDocumento20 pagineEd Miller's Building A No-Limit Hold'Em Starting Hand ChartaliceabusmusNessuna valutazione finora
- North Carolina Education Lottery Policies and Procedures Manual - Game Rules 2.04A - Powerball Game RulesDocumento11 pagineNorth Carolina Education Lottery Policies and Procedures Manual - Game Rules 2.04A - Powerball Game RulesEvian VelazquezNessuna valutazione finora
- 600+ Tambola /bingo Tickets Free For PrintDocumento189 pagine600+ Tambola /bingo Tickets Free For PrintAshish100% (3)
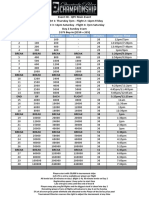
- QPC QLD Main Event StructureDocumento1 paginaQPC QLD Main Event StructurerajscribdNessuna valutazione finora
- Mastering Omaha8 Poker by Krieger LouTenner Mark ZDocumento319 pagineMastering Omaha8 Poker by Krieger LouTenner Mark ZIvan PetrovNessuna valutazione finora
- Power Ball Book FreeDocumento41 paginePower Ball Book FreeChristophe Beck100% (4)
- Test 11Documento3 pagineTest 11Ww tNessuna valutazione finora
- Abc - Bingo Letra TDocumento18 pagineAbc - Bingo Letra TJasmin ParadaNessuna valutazione finora
- Glosario Del PokerDocumento91 pagineGlosario Del PokerantonioNessuna valutazione finora
- How To Play BaccaratDocumento21 pagineHow To Play BaccaratJoderick TejadaNessuna valutazione finora
- Combinatorics and Probability DalesandroDocumento6 pagineCombinatorics and Probability DalesandroDaniel GarcíaNessuna valutazione finora
- Caribbean Stud PokerDocumento6 pagineCaribbean Stud PokerTú ÂnNessuna valutazione finora
- FL Lotto Winning NumbersDocumento17 pagineFL Lotto Winning NumbersrafaelmelroNessuna valutazione finora
- PS 114678 2019 2 11 Wolc-078Documento64 paginePS 114678 2019 2 11 Wolc-078Scalabrin Matheus GirardiNessuna valutazione finora
- Casino Regulatory Manual For Entertainment City Licensees Version 4Documento366 pagineCasino Regulatory Manual For Entertainment City Licensees Version 4Paige Lim100% (2)
- Roulette Table - Google SearchDocumento1 paginaRoulette Table - Google SearchNarmin HosseiniNessuna valutazione finora