Potrebbero piacerti anche
- Quick Configuration of Openldap and Kerberos In Linux and Authenicating Linux to Active DirectoryDa EverandQuick Configuration of Openldap and Kerberos In Linux and Authenicating Linux to Active DirectoryNessuna valutazione finora
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocumento11 pagineTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNessuna valutazione finora
- Big Data FileDocumento16 pagineBig Data FileArnav ShrivastavaNessuna valutazione finora
- Bda LabDocumento47 pagineBda LabpawanNessuna valutazione finora
- Big Data ManualDocumento19 pagineBig Data ManualMadhubala JNessuna valutazione finora
- Bda ManualDocumento80 pagineBda Manualbhuvans80_mNessuna valutazione finora
- 2 - InstallationDocumento15 pagine2 - Installationboxbe9876Nessuna valutazione finora
- Hadoop Installation Manual 2.odtDocumento20 pagineHadoop Installation Manual 2.odtGurasees SinghNessuna valutazione finora
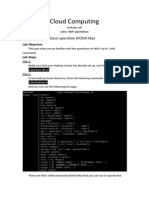
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDocumento61 paginePractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNessuna valutazione finora
- Big Data Lab Manual and SyllabusDocumento71 pagineBig Data Lab Manual and Syllabusstartechbyjus123Nessuna valutazione finora
- Intellipaat Hands On Exercises PDFDocumento49 pagineIntellipaat Hands On Exercises PDFSAURABH RANJANNessuna valutazione finora
- Unit No. 7Documento45 pagineUnit No. 7vishal phuleNessuna valutazione finora
- Hadoop Installation Step by StepDocumento8 pagineHadoop Installation Step by StepRamkumar GopalNessuna valutazione finora
- Big Data & Analytics Lab ManualDocumento51 pagineBig Data & Analytics Lab ManualSathishNessuna valutazione finora
- BIGDATA LAB MANUALDocumento27 pagineBIGDATA LAB MANUALjohn wickNessuna valutazione finora
- Hands OnDocumento26 pagineHands OnAshok Kumar K RNessuna valutazione finora
- BDA LAB ProgramsDocumento56 pagineBDA LAB Programsraghu rama teja vegesnaNessuna valutazione finora
- Instalisasi Hadoop Dengan UbuntuDocumento17 pagineInstalisasi Hadoop Dengan UbuntuMIFTAHUL JANNAH SISTEM INFORMASI 2020Nessuna valutazione finora
- Lab WRK On HadoopDocumento17 pagineLab WRK On HadoopPallavi SharmaNessuna valutazione finora
- BDA Lab Manual-1Documento60 pagineBDA Lab Manual-1pavan chittalaNessuna valutazione finora
- BDT Lab ManualDocumento48 pagineBDT Lab ManualVishnu Vardhan HNessuna valutazione finora
- Hadoop InstallationDocumento7 pagineHadoop InstallationGirik KhullarNessuna valutazione finora
- Hadoop Single Node Cluster Setup StepsDocumento7 pagineHadoop Single Node Cluster Setup StepsShushrutha Reddy KNessuna valutazione finora
- Experiment No - 1Documento13 pagineExperiment No - 1Tameem AhmedNessuna valutazione finora
- Big Data Manual AiDocumento33 pagineBig Data Manual Aismitcse2021Nessuna valutazione finora
- BDA LabManualDocumento20 pagineBDA LabManualposprojectzNessuna valutazione finora
- Hadoop TutorialDocumento30 pagineHadoop TutorialHasanNessuna valutazione finora
- Hadoop File ComplteDocumento18 pagineHadoop File ComplterashantNessuna valutazione finora
- PDC All LabsDocumento129 paginePDC All LabsSai Kiran100% (1)
- How To Install Hadoop On Ubuntu 18Documento15 pagineHow To Install Hadoop On Ubuntu 18Koné Mikpan HervéNessuna valutazione finora
- Lab ManualDocumento86 pagineLab Manualpthuynh709Nessuna valutazione finora
- Hadoop Installation StepsDocumento16 pagineHadoop Installation StepsSrinivasa Rao TNessuna valutazione finora
- Experiment No 1Documento15 pagineExperiment No 1ZEESHAN KHANNessuna valutazione finora
- Online:: Setting Up The EnvironmentDocumento9 pagineOnline:: Setting Up The EnvironmentJanuari SagaNessuna valutazione finora
- Hadoop InstallationDocumento11 pagineHadoop InstallationAlekhya AbbarajuNessuna valutazione finora
- Bda Lab ManualDocumento45 pagineBda Lab Manualreenadh shaikNessuna valutazione finora
- Bda LabDocumento37 pagineBda LabDhanush KumarNessuna valutazione finora
- Hadoop 1Documento39 pagineHadoop 1akshaydsarafNessuna valutazione finora
- Sqoop Tutorial: Sqoop: "SQL To Hadoop and Hadoop To SQL"Documento11 pagineSqoop Tutorial: Sqoop: "SQL To Hadoop and Hadoop To SQL"satish.sathya.a2012Nessuna valutazione finora
- BDAODocumento23 pagineBDAOSujamoni 824Nessuna valutazione finora
- @bigdatalabfile 09Documento35 pagine@bigdatalabfile 09goatrip2024Nessuna valutazione finora
- Hadoop Installation StepsDocumento12 pagineHadoop Installation StepssangamNessuna valutazione finora
- Anushka Shetty 35Documento34 pagineAnushka Shetty 35anohanabrotherhoodcaveNessuna valutazione finora
- Data Storage Data Processing: Hadoop Distributed File System (HDFS) MapreduceDocumento35 pagineData Storage Data Processing: Hadoop Distributed File System (HDFS) MapreduceSUDHEER REDDYNessuna valutazione finora
- Hadoop Cluster CreationDocumento8 pagineHadoop Cluster Creationmanish singhNessuna valutazione finora
- Big Data Fundamentals and Platforms Assginment 3Documento6 pagineBig Data Fundamentals and Platforms Assginment 3sagar srivastavaNessuna valutazione finora
- Install SqoopDocumento7 pagineInstall SqoopKajalNessuna valutazione finora
- How To Set Up A Hadoop Cluster in DockerDocumento13 pagineHow To Set Up A Hadoop Cluster in DockerNP NeupaneNessuna valutazione finora
- CC Hadoop LabDocumento6 pagineCC Hadoop LabClaudia ArdeleanNessuna valutazione finora
- $ Sudo Apt-Get Install Oracle-Java8-InstallerDocumento4 pagine$ Sudo Apt-Get Install Oracle-Java8-InstallerkoushikNessuna valutazione finora
- Dsa Practical FileDocumento16 pagineDsa Practical FileGiri KanchanNessuna valutazione finora
- HADOOP 1.X Installation Steps On UbuntuDocumento3 pagineHADOOP 1.X Installation Steps On UbuntuVisheshUtsavNessuna valutazione finora
- Hadoop Installatio1Documento22 pagineHadoop Installatio1paramreddy2000Nessuna valutazione finora
- BDA Lab 8 ManualDocumento7 pagineBDA Lab 8 ManualMydah NasirNessuna valutazione finora
- There Are Two Ways To Install Hadoop in UbantuDocumento10 pagineThere Are Two Ways To Install Hadoop in UbantuSrinivasa Rao TNessuna valutazione finora
- Hadoop InstallDocumento19 pagineHadoop InstallLâm LươngNessuna valutazione finora
- BDA PracticalDocumento38 pagineBDA PracticalJatin MathurNessuna valutazione finora
- GCC Lab ManualDocumento61 pagineGCC Lab ManualMadhu BalaNessuna valutazione finora
- Install Hadoop-2.6.0 On Windows10Documento8 pagineInstall Hadoop-2.6.0 On Windows10Sana LatifNessuna valutazione finora
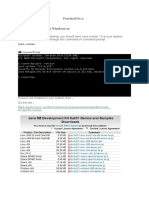
- Practical N0.2 AIM: Install Hadoop Hadoop Installation On Windows 10Documento12 paginePractical N0.2 AIM: Install Hadoop Hadoop Installation On Windows 10Rutikesh ShetyeNessuna valutazione finora
- CPSD.13 SAP HANA Made Simple With Solutions From Dell EMC-Final UpdatesDocumento34 pagineCPSD.13 SAP HANA Made Simple With Solutions From Dell EMC-Final UpdatesdebkrcNessuna valutazione finora
- HDP Certified Administrator (HDPCA) : Certification Overview Take The Exam Anytime, AnywhereDocumento3 pagineHDP Certified Administrator (HDPCA) : Certification Overview Take The Exam Anytime, AnywheredebkrcNessuna valutazione finora
- Dot Net Sap CodeDocumento18 pagineDot Net Sap CodedebkrcNessuna valutazione finora
- 03) Procedure For Design & DevelopmentDocumento6 pagine03) Procedure For Design & Developmentdebkrc100% (2)
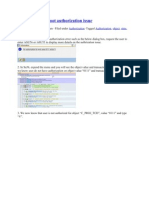
- How To Troubleshoot AuthorizationDocumento4 pagineHow To Troubleshoot AuthorizationdebkrcNessuna valutazione finora
- Learning Solution: From The Tatas An IntegratedDocumento4 pagineLearning Solution: From The Tatas An IntegrateddebkrcNessuna valutazione finora
- Big DATA Analytics: C.Ranichandra & N.C.SenthilkumarDocumento46 pagineBig DATA Analytics: C.Ranichandra & N.C.Senthilkumaranubhav guptaNessuna valutazione finora
- Big Data NOTES and QBDocumento92 pagineBig Data NOTES and QBSivaNessuna valutazione finora
- Research Paper On MapreduceDocumento7 pagineResearch Paper On Mapreducegjosukwgf100% (1)
- Dinesh KhanalDocumento6 pagineDinesh KhanalshubhamNessuna valutazione finora
- The Big Data Technology LandscapeDocumento36 pagineThe Big Data Technology LandscapePonnusamy S PichaimuthuNessuna valutazione finora
- Introduction To Nosql: Gabriele PozzaniDocumento49 pagineIntroduction To Nosql: Gabriele PozzaniLeonardo Gastiaburu LopezNessuna valutazione finora
- Shourie Amireddy ResumeDocumento1 paginaShourie Amireddy ResumeShourie ReddyNessuna valutazione finora
- Big Data AnalyticsDocumento64 pagineBig Data AnalyticsSameer MemonNessuna valutazione finora
- 2021 - CC - ASSIGN - 8weeks CourseDocumento34 pagine2021 - CC - ASSIGN - 8weeks CoursesaiNessuna valutazione finora
- M.Tech (CSE) Big Data Analytics CurriculumDocumento69 pagineM.Tech (CSE) Big Data Analytics CurriculumPskaruppiah KarupsNessuna valutazione finora
- Detecting Botnets Using MapReduceDocumento6 pagineDetecting Botnets Using MapReducerumpiyaNessuna valutazione finora
- BigData Module 2Documento41 pagineBigData Module 2R SANJAY CSNessuna valutazione finora
- Hadoop Ecosystem - GeeksforGeeksDocumento7 pagineHadoop Ecosystem - GeeksforGeeksAkhiNessuna valutazione finora
- Using Mongodb As A Tick Database 2013Documento40 pagineUsing Mongodb As A Tick Database 2013Valentin KantorNessuna valutazione finora
- Map ReduceDocumento40 pagineMap ReduceHareen ReddyNessuna valutazione finora
- NOSqlDocumento46 pagineNOSqlSAM7028Nessuna valutazione finora
- Borkar Shashikant@yahoo - Co.inDocumento4 pagineBorkar Shashikant@yahoo - Co.inshaziboNessuna valutazione finora
- Hadoop NotesDocumento11 pagineHadoop NotesVijay Vishwanath ThombareNessuna valutazione finora
- Big DataDocumento22 pagineBig Datavinay_krishna_1100% (3)
- Bda LabDocumento37 pagineBda LabDhanush KumarNessuna valutazione finora
- Iot-Based Big Data Storage Systems in Cloud Computing: Perspectives and ChallengesDocumento13 pagineIot-Based Big Data Storage Systems in Cloud Computing: Perspectives and ChallengesSACHIN KUMARNessuna valutazione finora
- Akash Data EngineerDocumento6 pagineAkash Data EngineerHARSHANessuna valutazione finora
- Big Data Analytics On Large Scale Shared Storage System: University of Computer Studies, Yangon, MyanmarDocumento7 pagineBig Data Analytics On Large Scale Shared Storage System: University of Computer Studies, Yangon, MyanmarKyar Nyo AyeNessuna valutazione finora
- Lab Manual BDADocumento36 pagineLab Manual BDAhemalata jangaleNessuna valutazione finora
- 2019 Book EssentialsOfBusinessAnalytics PDFDocumento971 pagine2019 Book EssentialsOfBusinessAnalytics PDFAndres Camacho Suarez89% (9)
- Real Time Hadoop Interview Questions From Various InterviewsDocumento6 pagineReal Time Hadoop Interview Questions From Various InterviewsSaurabh GuptaNessuna valutazione finora
- Cloudera Search User GuideDocumento86 pagineCloudera Search User GuideNgoc TranNessuna valutazione finora
- Seminar-Deep Learning RoportDocumento40 pagineSeminar-Deep Learning RoportDr Kowsalya SaravananNessuna valutazione finora
- Developer Exercise InstructionsDocumento50 pagineDeveloper Exercise InstructionsseshuchoudaryNessuna valutazione finora