Potrebbero piacerti anche
- Damodaran IntangiblesDocumento51 pagineDamodaran IntangiblesLenin TeranNessuna valutazione finora
- 1+1 (Pat. Pending) - Mathematics, Software and Free Speech: Why Software and Patents Need To Get A DivorceDocumento47 pagine1+1 (Pat. Pending) - Mathematics, Software and Free Speech: Why Software and Patents Need To Get A DivorcejgyoergerNessuna valutazione finora
- Micro Project IT & IPDocumento32 pagineMicro Project IT & IPMohima DuttaNessuna valutazione finora
- A Literature Review On The State-Of-The-Art in Patent AnalysisDocumento5 pagineA Literature Review On The State-Of-The-Art in Patent AnalysisafmzxppzpvolufNessuna valutazione finora
- Rough Draft Intellectutal Property Law: Patenting Software Related Inventions Trend in UK and USDocumento3 pagineRough Draft Intellectutal Property Law: Patenting Software Related Inventions Trend in UK and USAnkit AnandNessuna valutazione finora
- Theory of SunDocumento19 pagineTheory of SunNicholas GawanNessuna valutazione finora
- Intellectual Property Rights Research PaperDocumento6 pagineIntellectual Property Rights Research Paperefhkebh8100% (1)
- Strategic Managment Part 2Documento77 pagineStrategic Managment Part 2baniaputri.workNessuna valutazione finora
- R&D Spillovers, Patents and The Incentives To Innovate in Japan and The United StatesDocumento48 pagineR&D Spillovers, Patents and The Incentives To Innovate in Japan and The United StatesnoorsmNessuna valutazione finora
- Farr-Mensa - What Is A Patent WorthDocumento70 pagineFarr-Mensa - What Is A Patent WorthGarfield PosternNessuna valutazione finora
- Ieee Why Small Tech High Impact PDFDocumento16 pagineIeee Why Small Tech High Impact PDFErika ChongNessuna valutazione finora
- Essential Patents, FRAND Royalties and Technological StandardsDocumento30 pagineEssential Patents, FRAND Royalties and Technological StandardsSniffer 1Nessuna valutazione finora
- Research Policy: Alan C. Marco, Joshua D. Sarnoff, Charles A.W. Degrazia TDocumento17 pagineResearch Policy: Alan C. Marco, Joshua D. Sarnoff, Charles A.W. Degrazia TJorge RamírezNessuna valutazione finora
- 23UWSLEL025_20200401016_Prerna BhansaliDocumento17 pagine23UWSLEL025_20200401016_Prerna BhansaliPrerna BhansaliNessuna valutazione finora
- Luminaries LetterDocumento6 pagineLuminaries LetterabdNessuna valutazione finora
- What Is A Software PatentDocumento3 pagineWhat Is A Software PatentSachin TendulkarNessuna valutazione finora
- Antitrust, Intellectual Property AND Standard Setting OrganizationsDocumento13 pagineAntitrust, Intellectual Property AND Standard Setting OrganizationsChris PiNessuna valutazione finora
- Measuring The Costs and Benefits of Patent Pools - 78 Ohio St. L.J. 281Documento45 pagineMeasuring The Costs and Benefits of Patent Pools - 78 Ohio St. L.J. 281Anonymous qyExl9dUQuNessuna valutazione finora
- White House Patent Troll ReportDocumento17 pagineWhite House Patent Troll ReportGina SmithNessuna valutazione finora
- PHD Thesis Intellectual Property RightsDocumento11 paginePHD Thesis Intellectual Property Rightsafcmxfnqq100% (1)
- The Development of Synthetic Biology-A Patent AnalysisDocumento12 pagineThe Development of Synthetic Biology-A Patent AnalysisArtemisa QRNessuna valutazione finora
- Patent Analysis-7 PDFDocumento8 paginePatent Analysis-7 PDFsriniefsNessuna valutazione finora
- Avoid Expensive Conflicts With Your CompetitorsDocumento5 pagineAvoid Expensive Conflicts With Your CompetitorsmanojhunkNessuna valutazione finora
- Tusher Center Working Paper 7Documento46 pagineTusher Center Working Paper 7Julius MuhimboNessuna valutazione finora
- Eaddy: Database Copyright Analysis For DummiesDocumento39 pagineEaddy: Database Copyright Analysis For DummiesNew England Law ReviewNessuna valutazione finora
- N L U, J: Ational AW Niversity OdhpurDocumento18 pagineN L U, J: Ational AW Niversity OdhpurAtulya Singh ChauhanNessuna valutazione finora
- DL170 Module 1v1.2Documento13 pagineDL170 Module 1v1.2Dipa SaliNessuna valutazione finora
- AbstractDocumento1 paginaAbstractNavjit SinghNessuna valutazione finora
- Technological Forecasting & Social Change: Yu-Shan Chen, Ke-Chiun ChangDocumento14 pagineTechnological Forecasting & Social Change: Yu-Shan Chen, Ke-Chiun ChangmarcbonnemainsNessuna valutazione finora
- N L U, J: Ational AW Niversity OdhpurDocumento18 pagineN L U, J: Ational AW Niversity OdhpurUtkarsh KhandelwalNessuna valutazione finora
- Solution Manual For Analytics Data Science Artificial Intelligence Systems For Decision Support 11th by ShardaDocumento16 pagineSolution Manual For Analytics Data Science Artificial Intelligence Systems For Decision Support 11th by ShardaCherylElliotttfkg100% (39)
- Lee Davis CMR VersionDocumento28 pagineLee Davis CMR VersionTingting JiangNessuna valutazione finora
- Do Patents Matter For Commercialization - SSRN-id3952317Documento34 pagineDo Patents Matter For Commercialization - SSRN-id3952317Alex ENessuna valutazione finora
- The Private Value of Software PatentsDocumento16 pagineThe Private Value of Software PatentsJingjiang WeiNessuna valutazione finora
- Royalty Stacking and Patent HoldupsDocumento17 pagineRoyalty Stacking and Patent HoldupsUdbhav NandaNessuna valutazione finora
- Dynamics of Open SourceDocumento15 pagineDynamics of Open Sourcejon27183659Nessuna valutazione finora
- Patent Strategy and ManagementDocumento32 paginePatent Strategy and Managementpunjabii_rocksNessuna valutazione finora
- Quickly review patent prosecution historyDocumento64 pagineQuickly review patent prosecution historymailstonaikNessuna valutazione finora
- GeorgeDocumento30 pagineGeorgeAna CarneiroNessuna valutazione finora
- Intellectual Property and The Information Age: October 10, 2010Documento9 pagineIntellectual Property and The Information Age: October 10, 2010khairitkrNessuna valutazione finora
- Business Software PatentsDocumento7 pagineBusiness Software PatentsAbcdefNessuna valutazione finora
- MBS600 Capstone Three IPs Assignment GuideDocumento2 pagineMBS600 Capstone Three IPs Assignment GuideuddhavNessuna valutazione finora
- Patent Search and Analysis: A Practical GuideDocumento181 paginePatent Search and Analysis: A Practical GuideAnkur SaxenaNessuna valutazione finora
- Quantifying Technology Leadership in LTE Standard DevelopmentDocumento35 pagineQuantifying Technology Leadership in LTE Standard Developmenttech_geekNessuna valutazione finora
- Foreign Ownership and Firm Innovation - Evidence From KoreaDocumento29 pagineForeign Ownership and Firm Innovation - Evidence From KoreaZ pristinNessuna valutazione finora
- Final Draft V3 Ipr 2017ballb52Documento19 pagineFinal Draft V3 Ipr 2017ballb52Atulya Singh ChauhanNessuna valutazione finora
- Science Code Manifesto DiscussionDocumento3 pagineScience Code Manifesto DiscussionAmy Simmons McClellanNessuna valutazione finora
- Unit 202Documento6 pagineUnit 202Adam FairhallNessuna valutazione finora
- Cooperation Without Harmonization: The U.S. and The European Patent SystemDocumento29 pagineCooperation Without Harmonization: The U.S. and The European Patent SystemprasanNessuna valutazione finora
- Searching and Analysing Patent Document To Solve R&D ProblemsDocumento9 pagineSearching and Analysing Patent Document To Solve R&D ProblemsAsdfNessuna valutazione finora
- Patenting Mathematical Algorithms: What's The Harm?: A Thought Experiment in AlgebraDocumento19 paginePatenting Mathematical Algorithms: What's The Harm?: A Thought Experiment in AlgebraJefferson WidodoNessuna valutazione finora
- Improving The Visibility of Scholarly Software WorkDocumento60 pagineImproving The Visibility of Scholarly Software Workmohammad.aman.ullah.khan.piNessuna valutazione finora
- RM Ip AnsDocumento6 pagineRM Ip AnsApeksha S kenchareddyNessuna valutazione finora
- Understanding and Managing Systemic Innovation in Project-Based IndustriesDocumento18 pagineUnderstanding and Managing Systemic Innovation in Project-Based IndustriesAlejandroNessuna valutazione finora
- The Intellectual Property Office Report - Copyright Works - Streamlining Copyright Licensing For The Digital AgeDocumento76 pagineThe Intellectual Property Office Report - Copyright Works - Streamlining Copyright Licensing For The Digital Agerab24Nessuna valutazione finora
- Software Patents: by Akhil Desai (CWID: 802377119) (MS in Computer Science)Documento13 pagineSoftware Patents: by Akhil Desai (CWID: 802377119) (MS in Computer Science)richardNessuna valutazione finora
- Guidelines For Conducting and Reporting Case Study Research in Software EngineeringDocumento35 pagineGuidelines For Conducting and Reporting Case Study Research in Software EngineeringGizaw MeleseNessuna valutazione finora
- How Do Patents Affect Follow On InnovationDocumento38 pagineHow Do Patents Affect Follow On InnovationHANLIN ZHAONessuna valutazione finora
- Exercises For Scapulothoracic and Postural Muscle StrengthDocumento2 pagineExercises For Scapulothoracic and Postural Muscle StrengthSantosh PatiNessuna valutazione finora
- Assessing Patent ValueDocumento3 pagineAssessing Patent ValueSantosh PatiNessuna valutazione finora
- Site License OverviewDocumento4 pagineSite License OverviewSantosh PatiNessuna valutazione finora
- Wipo Smes TLV 11 Ref t15Documento44 pagineWipo Smes TLV 11 Ref t15Santosh PatiNessuna valutazione finora
- Wipo Ip Econ Ge 2 11 DeterminantsDocumento34 pagineWipo Ip Econ Ge 2 11 DeterminantsSantosh PatiNessuna valutazione finora
- ESRI Educational LicenceDocumento11 pagineESRI Educational LicenceSantosh PatiNessuna valutazione finora
- CIPHER Briefing Patent Strength July20141Documento7 pagineCIPHER Briefing Patent Strength July20141Santosh PatiNessuna valutazione finora
- Sample ReportDocumento9 pagineSample ReportSantosh PatiNessuna valutazione finora
- TV and Broadcasting2013 PDFDocumento478 pagineTV and Broadcasting2013 PDFSantosh PatiNessuna valutazione finora
- Antitrust Article On Exclusive Territorial LicensingDocumento8 pagineAntitrust Article On Exclusive Territorial LicensingSantosh PatiNessuna valutazione finora
- Methods For Patent Valuation PDFDocumento11 pagineMethods For Patent Valuation PDFSantosh PatiNessuna valutazione finora
- Bollywood Is Coming! Copyright and Film Industry Issues RegardingDocumento71 pagineBollywood Is Coming! Copyright and Film Industry Issues RegardingSantosh PatiNessuna valutazione finora
- A Test in Phonetics 500 Questions and Answers On English Pronunciation - Dr. B. Siertsema PDFDocumento91 pagineA Test in Phonetics 500 Questions and Answers On English Pronunciation - Dr. B. Siertsema PDFSantosh PatiNessuna valutazione finora
- 8 Privacy Laws Basics and Best PracticesDocumento22 pagine8 Privacy Laws Basics and Best PracticesSantosh PatiNessuna valutazione finora
- Satellite Retransmission CarriersDocumento30 pagineSatellite Retransmission CarriersSantosh PatiNessuna valutazione finora
- Politics of Intellectual Property Environmentalism For The NetDocumento31 paginePolitics of Intellectual Property Environmentalism For The NetSantosh PatiNessuna valutazione finora
- Scope of Broadcasting Organizations PDFDocumento21 pagineScope of Broadcasting Organizations PDFSantosh PatiNessuna valutazione finora
- Indian Broadcasting Foundation RC 10102016Documento13 pagineIndian Broadcasting Foundation RC 10102016Santosh PatiNessuna valutazione finora
- It's Hard To Find A Good Pair of Genes So Why Make Them Free For TheDocumento18 pagineIt's Hard To Find A Good Pair of Genes So Why Make Them Free For TheSantosh PatiNessuna valutazione finora
- Trademark Use GuidelinesDocumento1 paginaTrademark Use GuidelinesSantosh PatiNessuna valutazione finora
- Pruning The Evergreen Tree Section 3 (D) of The Indian Patents Act 1970Documento29 paginePruning The Evergreen Tree Section 3 (D) of The Indian Patents Act 1970Santosh PatiNessuna valutazione finora
- The Historic and Modern Doctrines of Equivalents and Claiming The Future Part II (1870-1952)Documento43 pagineThe Historic and Modern Doctrines of Equivalents and Claiming The Future Part II (1870-1952)Santosh PatiNessuna valutazione finora
- Copyright Exhaustion in India and USADocumento6 pagineCopyright Exhaustion in India and USASantosh PatiNessuna valutazione finora
- Growth of Software Related Patents in Different CountriesDocumento15 pagineGrowth of Software Related Patents in Different CountriesSantosh PatiNessuna valutazione finora
- The Copyright Protection of Software in UkDocumento7 pagineThe Copyright Protection of Software in UkSantosh PatiNessuna valutazione finora
- Does Decrease in Copying Cost SupportDocumento24 pagineDoes Decrease in Copying Cost SupportSantosh PatiNessuna valutazione finora
- International Patent Manual of AustraliaDocumento264 pagineInternational Patent Manual of AustraliaSantosh PatiNessuna valutazione finora
- The Historic and Modern Doctrines of Equivalents and Claiming The Future IDocumento31 pagineThe Historic and Modern Doctrines of Equivalents and Claiming The Future ISantosh PatiNessuna valutazione finora
- What Japan Should Learn From U.S. Experiences-Tests of Equivalence, Means-Plus-Function Claims and Product-By-Process ClaimsDocumento9 pagineWhat Japan Should Learn From U.S. Experiences-Tests of Equivalence, Means-Plus-Function Claims and Product-By-Process ClaimsSantosh PatiNessuna valutazione finora
- Taming The Doctrine of Equivalents in Light of Patent FailureDocumento29 pagineTaming The Doctrine of Equivalents in Light of Patent FailureSantosh PatiNessuna valutazione finora
- Skripsi #2 Tanpa HyperlinkDocumento19 pagineSkripsi #2 Tanpa HyperlinkindahNessuna valutazione finora
- Sal de CrosetatDocumento3 pagineSal de CrosetatMădălina Pisău100% (1)
- Airy stress function enables determination of stress components in pure beam bendingDocumento19 pagineAiry stress function enables determination of stress components in pure beam bendingmaran.suguNessuna valutazione finora
- Reservoir Saturation ToolDocumento19 pagineReservoir Saturation ToolAli Jay JNessuna valutazione finora
- Academic Performance of Face-to-Face and Online Students in An Introductory Economics Course and Determinants of Final Course GradesDocumento13 pagineAcademic Performance of Face-to-Face and Online Students in An Introductory Economics Course and Determinants of Final Course GradesLou BaldomarNessuna valutazione finora
- Powerfactory 2020: Technical ReferenceDocumento13 paginePowerfactory 2020: Technical ReferenceDaniel ManjarresNessuna valutazione finora
- Simple Backup/Restore Utility With SQL-: Introduction To SQL-DMODocumento8 pagineSimple Backup/Restore Utility With SQL-: Introduction To SQL-DMOZaeni Marjiyanto, A.mdNessuna valutazione finora
- MCQ Metrology (CCCM & CCCT) PDFDocumento21 pagineMCQ Metrology (CCCM & CCCT) PDFSahil Gauhar67% (3)
- Induction - George Ricarrson 2501987261Documento11 pagineInduction - George Ricarrson 2501987261George RYNessuna valutazione finora
- Design of Bulk CarrierDocumento7 pagineDesign of Bulk CarrierhoangductuanNessuna valutazione finora
- Same Denominator or Numerator Worksheet 1Documento2 pagineSame Denominator or Numerator Worksheet 1Jenny KimNessuna valutazione finora
- Boeing 757-767 Study Guide SummaryDocumento134 pagineBoeing 757-767 Study Guide SummaryEldonP100% (2)
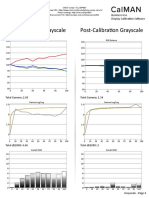
- TCL 55P607 CNET Review Calibration ResultsDocumento3 pagineTCL 55P607 CNET Review Calibration ResultsDavid KatzmaierNessuna valutazione finora
- Basic Engineering Correlation Calculus v3 001Documento3 pagineBasic Engineering Correlation Calculus v3 001Ska doosh100% (1)
- Reliability Prediction Studies On Electrical Insulation Navy Summary Report NAVALDocumento142 pagineReliability Prediction Studies On Electrical Insulation Navy Summary Report NAVALdennisroldanNessuna valutazione finora
- B483B483M 13e1Documento10 pagineB483B483M 13e1Mohamad ZandiNessuna valutazione finora
- Innovative Injection Rate Control With Next Generation Common Rail Fuel Injection SystemDocumento8 pagineInnovative Injection Rate Control With Next Generation Common Rail Fuel Injection SystemRakesh BiswasNessuna valutazione finora
- Rudolf Steiner - Warmth Course GA 321Documento119 pagineRudolf Steiner - Warmth Course GA 321Raul PopescuNessuna valutazione finora
- Huawei Site Design GuidelineDocumento7 pagineHuawei Site Design GuidelineHeru BudiantoNessuna valutazione finora
- Engineering Chemistry Lab Osmania UniversityDocumento83 pagineEngineering Chemistry Lab Osmania UniversityMujtaba khanNessuna valutazione finora
- Brown Stock WashingDocumento22 pagineBrown Stock Washingtreese2Nessuna valutazione finora
- Materi Welding Defect IIDocumento64 pagineMateri Welding Defect IIsmartz inspectionNessuna valutazione finora
- RWM61 Data SheetDocumento3 pagineRWM61 Data SheetBarth XaosNessuna valutazione finora
- ZF AVS Automatic Gearbox Manual PDFDocumento67 pagineZF AVS Automatic Gearbox Manual PDFDardan HusiNessuna valutazione finora
- Financial Modelling Assignment - Ghizal Naqvi (Attock Petroleum Limited)Documento13 pagineFinancial Modelling Assignment - Ghizal Naqvi (Attock Petroleum Limited)Ghizal NaqviNessuna valutazione finora
- HPLC CalculatorDocumento13 pagineHPLC CalculatorRamy AzizNessuna valutazione finora
- Surge Current Protection Using SuperconductorDocumento25 pagineSurge Current Protection Using SuperconductorAbhishek Walter PaulNessuna valutazione finora
- The Importance of Calculators in Math ClassDocumento6 pagineThe Importance of Calculators in Math Classchloe shanice bordiosNessuna valutazione finora
- S7 314 IFM: Hardware and InstallationDocumento87 pagineS7 314 IFM: Hardware and InstallationNitko NetkoNessuna valutazione finora
- 1 11 S Kinetics StudentVersionDocumento14 pagine1 11 S Kinetics StudentVersionMuhammad ilhamNessuna valutazione finora