Potrebbero piacerti anche
- List of Companies For Email DatabaseDocumento2 pagineList of Companies For Email DatabaseKishore Kumar50% (2)
- MAC Pro PriceDocumento2 pagineMAC Pro PriceKishore KumarNessuna valutazione finora
- CD 74 SpecsDocumento65 pagineCD 74 SpecsKishore Kumar100% (1)
- HP Color LaserJet E77822-E77825-E77830Documento6 pagineHP Color LaserJet E77822-E77825-E77830Chan ReyNessuna valutazione finora
- DELL PowerEdge R710 Technical GuideBookDocumento63 pagineDELL PowerEdge R710 Technical GuideBooksimon_sparks_1Nessuna valutazione finora
- Dubai Bus Route List September - 2017: Call CenterDocumento1 paginaDubai Bus Route List September - 2017: Call CenterKishore KumarNessuna valutazione finora
- Dubai Bus Route List September - 2017: Call CenterDocumento1 paginaDubai Bus Route List September - 2017: Call CenterKishore KumarNessuna valutazione finora
- EO2-QSG I1pro 2 User Guide enDocumento309 pagineEO2-QSG I1pro 2 User Guide enKishore KumarNessuna valutazione finora
- CD 74 SpecsDocumento65 pagineCD 74 SpecsKishore Kumar100% (1)
- Moment by Moment Expecting Advent Al Qaim PDFDocumento59 pagineMoment by Moment Expecting Advent Al Qaim PDFKishore KumarNessuna valutazione finora
- HP Latex 360 Printer Warranty Status ExpiredDocumento1 paginaHP Latex 360 Printer Warranty Status ExpiredKishore KumarNessuna valutazione finora
- Servertroubleshootingguide en PDFDocumento132 pagineServertroubleshootingguide en PDFVanquish64Nessuna valutazione finora
- IDES - General Information About The Usage ofDocumento3 pagineIDES - General Information About The Usage ofKishore KumarNessuna valutazione finora
- Getting Started With Power Map Preview - September RefreshDocumento57 pagineGetting Started With Power Map Preview - September RefreshWeliton Scarabotto MoorNessuna valutazione finora
- Servertroubleshootingguide en PDFDocumento132 pagineServertroubleshootingguide en PDFVanquish64Nessuna valutazione finora
- Oracle Database 10g Release 2 (10.2) Installation For Linux x86-64Documento28 pagineOracle Database 10g Release 2 (10.2) Installation For Linux x86-64mdbedareNessuna valutazione finora
- Free NasDocumento3 pagineFree NasKishore KumarNessuna valutazione finora
- Learn Hindi Through English PDFDocumento106 pagineLearn Hindi Through English PDFKevin Raman65% (20)
- SPAM Steps ExplainedDocumento2 pagineSPAM Steps ExplainedKishore KumarNessuna valutazione finora
- HP Laptop Service Center in ChennaiDocumento2 pagineHP Laptop Service Center in ChennaiKishore KumarNessuna valutazione finora
- Support Pack Check ListDocumento1 paginaSupport Pack Check ListKishore KumarNessuna valutazione finora
- Learn Hindi Through English PDFDocumento106 pagineLearn Hindi Through English PDFKevin Raman65% (20)
- What Are SAP NotesDocumento1 paginaWhat Are SAP NotesKishore KumarNessuna valutazione finora
- Reset OCS Queue using SE37 TCODEDocumento1 paginaReset OCS Queue using SE37 TCODEKishore KumarNessuna valutazione finora
- SPAM UpgrageDocumento8 pagineSPAM UpgrageKishore KumarNessuna valutazione finora
- CUA Configuration StepsDocumento9 pagineCUA Configuration StepsKishore KumarNessuna valutazione finora
- Reimplementation of SNOTEDocumento1 paginaReimplementation of SNOTEKishore KumarNessuna valutazione finora
- SAP Technical OverviewDocumento31 pagineSAP Technical OverviewKishore Kumar100% (1)
- LINUX CommandDocumento2 pagineLINUX CommandKishore KumarNessuna valutazione finora
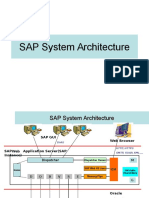
- SAP R/3 Overview & Basis Technology: Enterprise Wide Information SystemsDocumento22 pagineSAP R/3 Overview & Basis Technology: Enterprise Wide Information SystemsKishore Kumar100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Cds Ambala School - Google SearchDocumento1 paginaCds Ambala School - Google Searchmegha jainNessuna valutazione finora
- Social Media: Twitter 101: LAAMA Christmas Luncheon: DEC. 17, 2009Documento23 pagineSocial Media: Twitter 101: LAAMA Christmas Luncheon: DEC. 17, 2009saharconsultingNessuna valutazione finora
- TELES Training ExercisesDocumento15 pagineTELES Training Exercisesdatop123Nessuna valutazione finora
- 3250 Word Core OutlineDocumento2 pagine3250 Word Core Outlinesefsalman1Nessuna valutazione finora
- Seminar On Search Engine OptimizationDocumento15 pagineSeminar On Search Engine OptimizationAkash JangraNessuna valutazione finora
- Job Scheduler Control M Migration enDocumento12 pagineJob Scheduler Control M Migration enranusofiNessuna valutazione finora
- XBOOT - Multiboot ISO USB Creator for WindowsDocumento3 pagineXBOOT - Multiboot ISO USB Creator for Windowssabar5Nessuna valutazione finora
- Api RestDocumento268 pagineApi RestDan NielNessuna valutazione finora
- MagicInfo Lite Software White PaperDocumento12 pagineMagicInfo Lite Software White PaperLobo NeburNessuna valutazione finora
- E-Tech Q3 Module2Documento16 pagineE-Tech Q3 Module2Ryan Negad50% (2)
- Free $125 Adzooma Microsoft Ads CouponDocumento5 pagineFree $125 Adzooma Microsoft Ads CouponMike Kukwikila SayaNessuna valutazione finora
- HTML Tags: Code What It Does OptionsDocumento5 pagineHTML Tags: Code What It Does OptionsZAINAB ABDULLA 10-FNessuna valutazione finora
- Empowerment Technologies - World Wide WebDocumento54 pagineEmpowerment Technologies - World Wide WebEva Marie BudionganNessuna valutazione finora
- Frequently Asked QuestionsDocumento3 pagineFrequently Asked QuestionsGuru SwamyNessuna valutazione finora
- Xerox Products Affected by Latest Encryption ProtocolsDocumento4 pagineXerox Products Affected by Latest Encryption ProtocolsApsara DilakshiNessuna valutazione finora
- Unit-V: Introduction To AJAXDocumento32 pagineUnit-V: Introduction To AJAXRAVI TEJA MNessuna valutazione finora
- DsfdsDocumento98 pagineDsfdsKarthik KeyanNessuna valutazione finora
- 06 PAPB 06 Jquery Animation Ajax PDFDocumento34 pagine06 PAPB 06 Jquery Animation Ajax PDFUdara YapaNessuna valutazione finora
- DRDA 10g BugDocumento5 pagineDRDA 10g BugagangapurNessuna valutazione finora
- A Mobile Visual Programming System For Android Smartphones and TabletsDocumento2 pagineA Mobile Visual Programming System For Android Smartphones and TabletsFritz FatigaNessuna valutazione finora
- AWP Practical 3Documento7 pagineAWP Practical 3sushil100% (1)
- Workstation Installation ChecklistDocumento13 pagineWorkstation Installation ChecklistSSAS76Nessuna valutazione finora
- Exam PL 200 Microsoft Power Platform Functional Consultant Skills MeasuredDocumento9 pagineExam PL 200 Microsoft Power Platform Functional Consultant Skills MeasuredWaqas AhmedNessuna valutazione finora
- Readme Rsa Securid Software Token Converter 2.6.1: June 2012Documento7 pagineReadme Rsa Securid Software Token Converter 2.6.1: June 2012Nurul BintangNessuna valutazione finora
- Online Notice Board Project DocumentationDocumento6 pagineOnline Notice Board Project DocumentationGm Lakshman100% (4)
- Ms Word Demo1Documento1 paginaMs Word Demo1Swapnali KadamNessuna valutazione finora
- PM Debug InfoDocumento92 paginePM Debug Infodoston5390099Nessuna valutazione finora
- Business Communication Process and Product 7th Edition Guffey Test BankDocumento45 pagineBusiness Communication Process and Product 7th Edition Guffey Test Bankstephaniemosleymfjpgkboei100% (31)
- HFM Financial Management OverviewDocumento46 pagineHFM Financial Management OverviewR SreenuNessuna valutazione finora
- Pulse Secure VPN CCDocumento19 paginePulse Secure VPN CCDavidPerezNessuna valutazione finora