Potrebbero piacerti anche
- Comparing Databases For An Industrial IoT Use-Case: MongoDB, TimescaleDB, InfluxDB and CrateDBDocumento6 pagineComparing Databases For An Industrial IoT Use-Case: MongoDB, TimescaleDB, InfluxDB and CrateDBSananeNessuna valutazione finora
- Scale Out Scale UpDocumento13 pagineScale Out Scale Uparun_kejariwalNessuna valutazione finora
- Redis Why MongoDB Needs RedisDocumento6 pagineRedis Why MongoDB Needs RedisEstebanNessuna valutazione finora
- Dita - Kebede - BIG Data Assignment ReportDocumento25 pagineDita - Kebede - BIG Data Assignment Reportnuredin abdellahNessuna valutazione finora
- Results: Griddb Performance Using Google Cloud PlatformDocumento2 pagineResults: Griddb Performance Using Google Cloud PlatformShalu OjhaNessuna valutazione finora
- Hadoop - Quick Guide Hadoop - Big Data OverviewDocumento41 pagineHadoop - Quick Guide Hadoop - Big Data OverviewSelva KumarNessuna valutazione finora
- Hadoop Quick GuideDocumento32 pagineHadoop Quick GuideRamanan SubramanianNessuna valutazione finora
- Hadoop - Quick Guide Hadoop - Big Data OverviewDocumento32 pagineHadoop - Quick Guide Hadoop - Big Data OverviewAkhilesh MathurNessuna valutazione finora
- The Growing Enormous of Big Data StorageDocumento6 pagineThe Growing Enormous of Big Data StorageEddy ManurungNessuna valutazione finora
- Research Paper On Big Data HadoopDocumento5 pagineResearch Paper On Big Data Hadoopt1tos1z0t1d2100% (1)
- Hadoop & BigData (UNIT - 2)Documento22 pagineHadoop & BigData (UNIT - 2)Ayush KhandalNessuna valutazione finora
- Unit No. 4Documento67 pagineUnit No. 4vishal phuleNessuna valutazione finora
- Hadoop LabDocumento32 pagineHadoop LabISS GVP100% (1)
- Chapter - 2 HadoopDocumento32 pagineChapter - 2 HadoopRahul PawarNessuna valutazione finora
- MongoDB Performance Tuning: Optimizing MongoDB Databases and their ApplicationsDa EverandMongoDB Performance Tuning: Optimizing MongoDB Databases and their ApplicationsNessuna valutazione finora
- Data Processing For Large Database Using Mapreduce Approach Using ApsoDocumento59 pagineData Processing For Large Database Using Mapreduce Approach Using ApsosumankumarNessuna valutazione finora
- World-Record Performance For Big Data and AnalyticsDocumento8 pagineWorld-Record Performance For Big Data and AnalyticsNguyễn Trung PhongNessuna valutazione finora
- MongoDB Case Study 1Documento6 pagineMongoDB Case Study 1asdfasdfNessuna valutazione finora
- Big Data Hadoop Research PaperDocumento6 pagineBig Data Hadoop Research PaperaflbuagdwNessuna valutazione finora
- Big Data - Mini WorkshopDocumento29 pagineBig Data - Mini WorkshopOpen Data Institute100% (2)
- It DocumentationDocumento61 pagineIt DocumentationVinay MotghareNessuna valutazione finora
- Hadoop PPTDocumento25 pagineHadoop PPTsiv535Nessuna valutazione finora
- Big Data and Hadoop: Senior Product SpecialistDocumento40 pagineBig Data and Hadoop: Senior Product SpecialistRobinNessuna valutazione finora
- Why Mongodb Is So Popular?Documento3 pagineWhy Mongodb Is So Popular?prasannaNessuna valutazione finora
- Some Studies in Firebird Performance: Paul Reeves IbphoenixDocumento43 pagineSome Studies in Firebird Performance: Paul Reeves Ibphoenixbest_wailNessuna valutazione finora
- Research Paper On HadoopDocumento5 pagineResearch Paper On Hadoopwlyxiqrhf100% (1)
- Cloud-Native Transactions and Analytics in SingleStoreDocumento13 pagineCloud-Native Transactions and Analytics in SingleStorepeterpan107Nessuna valutazione finora
- SI PresentationDocumento14 pagineSI PresentationDuvan MejiaNessuna valutazione finora
- Big Data - RDBMS, NoSQL and DynamoDBDocumento6 pagineBig Data - RDBMS, NoSQL and DynamoDBGanapathy PNessuna valutazione finora
- BDEv3.5 Perf. Benchmark and Architect DesignDocumento28 pagineBDEv3.5 Perf. Benchmark and Architect DesignSontas JiamsripongNessuna valutazione finora
- Research Paper On Real Time Data WarehouseDocumento7 pagineResearch Paper On Real Time Data Warehousefvf8zrn0100% (1)
- Unlock The Value of Big Data With The DX2000 From NECDocumento23 pagineUnlock The Value of Big Data With The DX2000 From NECPrincipled TechnologiesNessuna valutazione finora
- Bigdata Implementations-CasestudyDocumento1 paginaBigdata Implementations-CasestudyVivek BiradarNessuna valutazione finora
- Prepared by Richa Btech (Cse) 6 Sem Dav University JalandharDocumento30 paginePrepared by Richa Btech (Cse) 6 Sem Dav University JalandharRichaNessuna valutazione finora
- Fundamentals of Big Data and Business AnalyticsDocumento6 pagineFundamentals of Big Data and Business Analyticsjitendra.jgec8525Nessuna valutazione finora
- Application Cache Performance Testing: Product Evaluation: Azure Cache For RedisDocumento27 pagineApplication Cache Performance Testing: Product Evaluation: Azure Cache For RedisHarish NaikNessuna valutazione finora
- Analysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterDocumento8 pagineAnalysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterInternational Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- Optimization of Computing and Networking Resources of A Hadoop Cluster Based On Software Defined NetworkDocumento15 pagineOptimization of Computing and Networking Resources of A Hadoop Cluster Based On Software Defined NetworkliyuxinNessuna valutazione finora
- HSNetwork For DSystemsDocumento31 pagineHSNetwork For DSystemsEric KialNessuna valutazione finora
- Big Data Question BankDocumento38 pagineBig Data Question Bankindrajeet007Nessuna valutazione finora
- Hadoop - MapReduceDocumento51 pagineHadoop - MapReducedangtranNessuna valutazione finora
- The Design and Implementation of E-Commerce Log Analysis System Based On HadoopDocumento5 pagineThe Design and Implementation of E-Commerce Log Analysis System Based On HadoopInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- Big Data and GenomicsDocumento17 pagineBig Data and GenomicsAndreea VezeteuNessuna valutazione finora
- Science BSC Information Technology Semester 5 2019 November Next Generation Technologies CbcsDocumento21 pagineScience BSC Information Technology Semester 5 2019 November Next Generation Technologies Cbcsnikhilsingh9637115898Nessuna valutazione finora
- O Codificador LimpoDocumento8 pagineO Codificador LimpoFrancis JS0% (1)
- Big Data and Analytics Challenges and Solutions in CloudDocumento6 pagineBig Data and Analytics Challenges and Solutions in CloudAJER JOURNALNessuna valutazione finora
- Data Migration From RDBMS To Hadoop: Platform Migration ApproachDocumento25 pagineData Migration From RDBMS To Hadoop: Platform Migration ApproachVibhaw Prakash RajanNessuna valutazione finora
- Evaluate The Performance of MongoDB NoSQL Database Using PythonDocumento5 pagineEvaluate The Performance of MongoDB NoSQL Database Using PythonGRD JournalsNessuna valutazione finora
- Caso de Computo ForenseDocumento2 pagineCaso de Computo Forenseapi-245231397Nessuna valutazione finora
- Distributed Database Management Systems and The Data GridDocumento12 pagineDistributed Database Management Systems and The Data Gridselvaraj.MNessuna valutazione finora
- Benchmarking Criteria For A Cloud Data WarehouseDocumento11 pagineBenchmarking Criteria For A Cloud Data Warehousexxcabdi123Nessuna valutazione finora
- Hadoop: Presented by Y NaveenDocumento7 pagineHadoop: Presented by Y NaveenNaveen YellapuNessuna valutazione finora
- A Survey of Post-Relational Data Management and NOSQL MovementDocumento22 pagineA Survey of Post-Relational Data Management and NOSQL MovementLeonardo Gastiaburu LopezNessuna valutazione finora
- Big Data Analysis Concepts and ReferencesDocumento60 pagineBig Data Analysis Concepts and ReferencesJamie Gibson100% (1)
- Big DataDocumento43 pagineBig DataABHIJEETH kumarNessuna valutazione finora
- Information and Guidelines For The NMR AssignmentDocumento4 pagineInformation and Guidelines For The NMR AssignmentBlake ConnollyNessuna valutazione finora
- Mid-Term Exam RevisionDocumento31 pagineMid-Term Exam RevisionBlake ConnollyNessuna valutazione finora
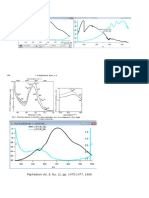
- Pdyhedron Vol. 9, No. 12, Pp. 1475-1477, 1990Documento2 paginePdyhedron Vol. 9, No. 12, Pp. 1475-1477, 1990Blake ConnollyNessuna valutazione finora
- Christ, Be Our Light! Shine in Our Hearts. Shine Through The Darkness. Christ, Be Our Light! Shine in Your Church Gathered TodayDocumento1 paginaChrist, Be Our Light! Shine in Our Hearts. Shine Through The Darkness. Christ, Be Our Light! Shine in Your Church Gathered TodayBlake ConnollyNessuna valutazione finora
- Photochromism and PiezochromismDocumento6 paginePhotochromism and PiezochromismBlake ConnollyNessuna valutazione finora
- Bella Bartok: Click To Hear Bartok's MusicDocumento11 pagineBella Bartok: Click To Hear Bartok's MusicBlake ConnollyNessuna valutazione finora
- JDBC 1Documento20 pagineJDBC 1Pratik SoundarkarNessuna valutazione finora
- 6 Month Review Form-USA - NewDocumento3 pagine6 Month Review Form-USA - NewAnonymous m0GYryKkdKNessuna valutazione finora
- Resume FebaDocumento2 pagineResume Febafeba ferdinandNessuna valutazione finora
- SQL Server 2014 In-Memory OLTP Workload Patterns and Migration Considerations TDM White PaperDocumento35 pagineSQL Server 2014 In-Memory OLTP Workload Patterns and Migration Considerations TDM White PapermanishsgNessuna valutazione finora
- The SQL Injection and Signature EvasionDocumento11 pagineThe SQL Injection and Signature Evasionsynfin80Nessuna valutazione finora
- Splunk 8.1 Fundamentals Part 3Documento304 pagineSplunk 8.1 Fundamentals Part 3S Lavanyaa100% (4)
- Siebel Personalization Administration Guide: Version 7.7 Rev A March 2005Documento116 pagineSiebel Personalization Administration Guide: Version 7.7 Rev A March 2005Jiri BartlNessuna valutazione finora
- Thread BasicsDocumento20 pagineThread Basicskhoaitayran2012_4950Nessuna valutazione finora
- AWS IAM-Cheet-SheetDocumento11 pagineAWS IAM-Cheet-SheetamarmudirajNessuna valutazione finora
- Cross System Lock (Bc-Cst-Eq) : PDF Download From SAP Help Portal: Created On January 29, 2014Documento20 pagineCross System Lock (Bc-Cst-Eq) : PDF Download From SAP Help Portal: Created On January 29, 2014Mike BeisNessuna valutazione finora
- 6CS5 DS Unit-4Documento64 pagine6CS5 DS Unit-4CHIRAG GUPTA PCE19IT010Nessuna valutazione finora
- 2.1 SQTM FCM MetricsDocumento4 pagine2.1 SQTM FCM MetricsEngr Ernest AppiahNessuna valutazione finora
- LDRA Co. Profile Low ResDocumento4 pagineLDRA Co. Profile Low Resashishcse1Nessuna valutazione finora
- Assignment 5.2 System UtilitiesDocumento4 pagineAssignment 5.2 System UtilitiesDhan GaringanNessuna valutazione finora
- IT Risk: Presented By: Kapal Mani Gyawali Suman ShresthaDocumento24 pagineIT Risk: Presented By: Kapal Mani Gyawali Suman ShresthaJames PalmerNessuna valutazione finora
- Sosialisasi Sistem Informasi Berbasis Teknologi Informasi Sebagai Pendukung Penerapan Di Masa Pandemi Covid-19Documento8 pagineSosialisasi Sistem Informasi Berbasis Teknologi Informasi Sebagai Pendukung Penerapan Di Masa Pandemi Covid-19Bu YantiNessuna valutazione finora
- ProcurePort Announces The Release of SpendPilot™, Further Expanding Spend Data AnalysisDocumento2 pagineProcurePort Announces The Release of SpendPilot™, Further Expanding Spend Data AnalysisPR.comNessuna valutazione finora
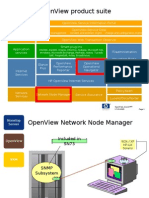
- Open ViewDocumento30 pagineOpen ViewzguzimNessuna valutazione finora
- D06TE6 COM AdbDocumento1 paginaD06TE6 COM Adbspatel_53Nessuna valutazione finora
- Percona MonitoringDocumento3 paginePercona Monitoringhari krishnaNessuna valutazione finora
- Implement A Ion ProcessDocumento2 pagineImplement A Ion ProcessJaweed Aslam ShaikhNessuna valutazione finora
- Diploma in Ethical Hacking - Syllabus - Hacking ClubDocumento33 pagineDiploma in Ethical Hacking - Syllabus - Hacking ClubWaseem AkramNessuna valutazione finora
- Edu en Vsicm8 LabDocumento167 pagineEdu en Vsicm8 Labadsf1150Nessuna valutazione finora
- Tangkawarow 2016 IOP Conf. Ser.: Mater. Sci. Eng. 128 012010 PDFDocumento17 pagineTangkawarow 2016 IOP Conf. Ser.: Mater. Sci. Eng. 128 012010 PDFAnjaly RahmanNessuna valutazione finora
- Project Estimation - Software Engineering Approaches: - Lines of Code (LOC) - Function Points - Cocomo - HeuristicsDocumento16 pagineProject Estimation - Software Engineering Approaches: - Lines of Code (LOC) - Function Points - Cocomo - HeuristicsSatya WiragaNessuna valutazione finora
- TogafDocumento16 pagineTogafHemant ShindeNessuna valutazione finora
- Kognitio ConfigurationandMaintenanceManual v80100Documento117 pagineKognitio ConfigurationandMaintenanceManual v80100amitag007Nessuna valutazione finora
- Requirements Engineering ToolsDocumento6 pagineRequirements Engineering ToolsAlberto LébedevNessuna valutazione finora
- Unit 4 Database Design & Development-2022Documento7 pagineUnit 4 Database Design & Development-2022sisam oliNessuna valutazione finora
- QSAN - Production Training - 2022Documento37 pagineQSAN - Production Training - 2022CromNessuna valutazione finora