Potrebbero piacerti anche
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- 4x4 Matrix Key-Board Interfacing With ATmega32Documento6 pagine4x4 Matrix Key-Board Interfacing With ATmega32Emin Kültürel100% (1)
- Circuit Schematic LiPo Battery Charger Using LM324 ICDocumento3 pagineCircuit Schematic LiPo Battery Charger Using LM324 ICEmin Kültürel0% (1)
- Small DC Motor Control by PWM Method Using Atmega8Documento4 pagineSmall DC Motor Control by PWM Method Using Atmega8Emin KültürelNessuna valutazione finora
- EE 109 Unit 10 - Pulse Width ModulationDocumento16 pagineEE 109 Unit 10 - Pulse Width ModulationEmin KültürelNessuna valutazione finora
- EE 109 Unit 18 - Noise Margins, Interfacing, and Tri-StatesDocumento22 pagineEE 109 Unit 18 - Noise Margins, Interfacing, and Tri-StatesEmin KültürelNessuna valutazione finora
- Introduction To Computer Science-1Documento46 pagineIntroduction To Computer Science-1Emin KültürelNessuna valutazione finora
- EE 109 Unit 20: IEEE 754 Floating Point Representation Floating Point ArithmeticDocumento31 pagineEE 109 Unit 20: IEEE 754 Floating Point Representation Floating Point ArithmeticEmin KültürelNessuna valutazione finora
- EE109Unit18 NoiseMarginCMOS NotesDocumento7 pagineEE109Unit18 NoiseMarginCMOS NotesEmin KültürelNessuna valutazione finora
- Real Timer Using Microcontroller ATME8535Documento4 pagineReal Timer Using Microcontroller ATME8535Emin KültürelNessuna valutazione finora
- Unit 8 - RecursionDocumento16 pagineUnit 8 - RecursionEmin KültürelNessuna valutazione finora
- Lecture5 Data Stuctures AlgorithmsDocumento53 pagineLecture5 Data Stuctures AlgorithmsEmin KültürelNessuna valutazione finora
- Lecture11 Abstract Machines TheoryDocumento40 pagineLecture11 Abstract Machines TheoryEmin KültürelNessuna valutazione finora
- Newbies Guide To Avr Timers-10Documento18 pagineNewbies Guide To Avr Timers-10Emin KültürelNessuna valutazione finora
- Voltage Supervisory Circuit With TL7705Documento1 paginaVoltage Supervisory Circuit With TL7705Emin KültürelNessuna valutazione finora
- Accessing The EEPROMDocumento12 pagineAccessing The EEPROMEmin KültürelNessuna valutazione finora
- Experiment 5Documento4 pagineExperiment 5idaayudwitasariNessuna valutazione finora
- Woodward 2301A 9905 9907 Series Technical ManualDocumento52 pagineWoodward 2301A 9905 9907 Series Technical Manualtimipl2100% (5)
- Advanced Ev3 Robot ProgrammingDocumento36 pagineAdvanced Ev3 Robot ProgrammingJaime TorresNessuna valutazione finora
- Siemens Gigaset A38hDocumento10 pagineSiemens Gigaset A38hAlexandre Sieiro LungovNessuna valutazione finora
- AC SPINDLE MOTOR Paramete PDFDocumento750 pagineAC SPINDLE MOTOR Paramete PDFJosh NhânNessuna valutazione finora
- Module Code and Title: Programme: Credit: Module Tutor: General ObjectivesDocumento5 pagineModule Code and Title: Programme: Credit: Module Tutor: General ObjectivesAmrith SubidiNessuna valutazione finora
- TGS 6 - Backpropagation-18.01.53.0065Documento2 pagineTGS 6 - Backpropagation-18.01.53.0065Ki JahsehNessuna valutazione finora
- Recon 2010 Skochinsky PDFDocumento57 pagineRecon 2010 Skochinsky PDFntcaseNessuna valutazione finora
- เครื่องทำกาแฟสด คู่มือ Wega Mini NovaDocumento104 pagineเครื่องทำกาแฟสด คู่มือ Wega Mini Novaแฟรนไชส์กาแฟ ชาอินเดีย กาแฟเปอร์เซียNessuna valutazione finora
- TSA4G1 USB Mini Spectrum Analyzer: Features: ApplicationDocumento2 pagineTSA4G1 USB Mini Spectrum Analyzer: Features: ApplicationEnrique MerinoNessuna valutazione finora
- RTD2122LDocumento52 pagineRTD2122LadriantxeNessuna valutazione finora
- Thermal Paste Banana Peel.Documento15 pagineThermal Paste Banana Peel.Carlos ClimacoNessuna valutazione finora
- Introduction: The Induction Motor Is A Three Phase AC Motor and Is The Most WidelyDocumento13 pagineIntroduction: The Induction Motor Is A Three Phase AC Motor and Is The Most WidelyAsimNessuna valutazione finora
- Lecture 56 - Components of LT SwitchgearDocumento18 pagineLecture 56 - Components of LT SwitchgearSahil Dhapola100% (1)
- Jumbo Remote ControlDocumento8 pagineJumbo Remote ControlmtlpcguysNessuna valutazione finora
- SH 24 As 6Documento38 pagineSH 24 As 6Stefano SinigagliesiNessuna valutazione finora
- Canon Speedlite Transmitter ST-E2Documento19 pagineCanon Speedlite Transmitter ST-E2Dorin CalugaruNessuna valutazione finora
- Motor Protection Selection TablesDocumento1 paginaMotor Protection Selection TablesCharlie MartinezNessuna valutazione finora
- SS16 CPGK DC60Documento4 pagineSS16 CPGK DC60Benjie CallantaNessuna valutazione finora
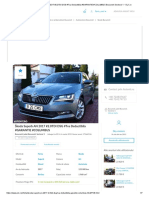
- Škoda Superb An 2017 #2.0TDI DSG #Tva Deductibila #GARANTIE #COLUMBUS Bucuresti Sectorul 1 - OLXDocumento7 pagineŠkoda Superb An 2017 #2.0TDI DSG #Tva Deductibila #GARANTIE #COLUMBUS Bucuresti Sectorul 1 - OLXViorel AvramescuNessuna valutazione finora
- Manual Smart Inverter SamsungDocumento2 pagineManual Smart Inverter SamsungIgor BarrosoNessuna valutazione finora
- DJ ABERTO SIEMENS 3 WT Catalogo-Lv35-3wtDocumento78 pagineDJ ABERTO SIEMENS 3 WT Catalogo-Lv35-3wtMyllerNessuna valutazione finora
- Electrostatic VoltmetersDocumento9 pagineElectrostatic VoltmetersMadhushreeNessuna valutazione finora
- V.35 Cable Interface: TutorialDocumento4 pagineV.35 Cable Interface: Tutorialamin_bravoNessuna valutazione finora
- CET Power - AGIL Tri-Mono Datasheet v1.3Documento2 pagineCET Power - AGIL Tri-Mono Datasheet v1.3jokotsNessuna valutazione finora
- Solar Panel BP3125Documento2 pagineSolar Panel BP3125acuario_86ch@hotmail.comNessuna valutazione finora
- Ee 102 With ObjectivesDocumento8 pagineEe 102 With ObjectivesReyzel Anne FaylognaNessuna valutazione finora
- 38 Champion CM6901 PDFDocumento15 pagine38 Champion CM6901 PDFcarlosgnNessuna valutazione finora
- Manoj Updated CVDocumento5 pagineManoj Updated CVArun TiwariNessuna valutazione finora
- Hyundai Robot Hi5 Controller Operation ManualDocumento463 pagineHyundai Robot Hi5 Controller Operation ManualVoxine Ouscularen0% (1)