Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (890)
- VW Canbus BasicDocumento32 pagineVW Canbus BasicDzulkiflee Hj Hamdan100% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Python BasicsDocumento59 paginePython Basicsmanikantamnk1150% (2)
- Python 3 Hands OnDocumento139 paginePython 3 Hands OnusersupreethNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (73)
- How To Think Like A Computer Scientist Using Python 3Documento421 pagineHow To Think Like A Computer Scientist Using Python 3Subhash Mantha75% (4)
- The Python Challenge SolutionsDocumento53 pagineThe Python Challenge Solutionsmanikantamnk110% (1)
- WordPress Theme Development GuideDocumento15 pagineWordPress Theme Development GuideRaj KUMARNessuna valutazione finora
- Web CrawlerDocumento28 pagineWeb Crawlermanikantamnk11Nessuna valutazione finora
- Gate Syllabus EC ImpDocumento7 pagineGate Syllabus EC Impmanikantamnk11Nessuna valutazione finora
- Exception Handling A PR 96Documento7 pagineException Handling A PR 96manikantamnk11Nessuna valutazione finora
- To DoDocumento1 paginaTo Domanikantamnk11Nessuna valutazione finora
- Pyhton CodeDocumento1 paginaPyhton Codemanikantamnk11Nessuna valutazione finora
- Links To BookmarksDocumento1 paginaLinks To Bookmarksmanikantamnk11Nessuna valutazione finora
- STL Tutorial and Referece GuideDocumento545 pagineSTL Tutorial and Referece Guidewqd165Nessuna valutazione finora
- Coding As A CraftDocumento280 pagineCoding As A Craftmanikantamnk11Nessuna valutazione finora
- Python3 Notes PDFDocumento459 paginePython3 Notes PDFRaedadobeAdobeNessuna valutazione finora
- Front End HandbookDocumento130 pagineFront End Handbookmanikantamnk11Nessuna valutazione finora
- CodeSchool TryPython PDFDocumento75 pagineCodeSchool TryPython PDFmanikantamnk11Nessuna valutazione finora
- Byte of PythonDocumento177 pagineByte of PythonShubham GotraNessuna valutazione finora
- Phython BasicsDocumento428 paginePhython BasicsRajesh DurisalaNessuna valutazione finora
- Front End Handbook PDFDocumento132 pagineFront End Handbook PDFSally Wong100% (1)
- Slides PDFDocumento35 pagineSlides PDFvarunjaincseNessuna valutazione finora
- Python Imm6613 PDFDocumento28 paginePython Imm6613 PDFmanikantamnk11Nessuna valutazione finora
- PythonDocumento68 paginePythonalok541100% (2)
- Learning To Program With PythonDocumento283 pagineLearning To Program With Pythonalkaline123100% (4)
- Good PracticesDocumento43 pagineGood PracticesAndrei DiaconuNessuna valutazione finora
- Understanding The StackDocumento119 pagineUnderstanding The Stackmanikantamnk11Nessuna valutazione finora
- Python 3 Module ExamplesDocumento147 paginePython 3 Module Examplesmanikantamnk11Nessuna valutazione finora
- Python Testing TutorialDocumento52 paginePython Testing Tutorialmanikantamnk11Nessuna valutazione finora
- Understanding The Stack PDFDocumento11 pagineUnderstanding The Stack PDFmanikantamnk11Nessuna valutazione finora
- Python 3 ReferenceDocumento15 paginePython 3 Referencemanikantamnk11Nessuna valutazione finora
- Introduction To Applet ProgrammingDocumento27 pagineIntroduction To Applet ProgrammingkarthickamsecNessuna valutazione finora
- Web Technology NotesDocumento13 pagineWeb Technology NotesTemp MailNessuna valutazione finora
- PGDCA SyllabusDocumento16 paginePGDCA SyllabusMr freakyNessuna valutazione finora
- Rumah123 Com Seocheck 2022 08 09Documento31 pagineRumah123 Com Seocheck 2022 08 09IT Helpdesk PT.HK RealtindoNessuna valutazione finora
- Dompdf Github Guia php5Documento4 pagineDompdf Github Guia php5Dylan CipagautaNessuna valutazione finora
- WWW Softwaretestinghelp Com How To Perform Backend TestingDocumento12 pagineWWW Softwaretestinghelp Com How To Perform Backend TestingJagadeesh AdapalaNessuna valutazione finora
- GCUF School Management System DocumentationDocumento15 pagineGCUF School Management System DocumentationTayyab ayyubNessuna valutazione finora
- Tab Menu: A Region Plug-In For Oracle Application ExpressDocumento6 pagineTab Menu: A Region Plug-In For Oracle Application ExpressAnonymous pWOoGdHZNessuna valutazione finora
- CIDOS LMS - Lecturer User ManualDocumento29 pagineCIDOS LMS - Lecturer User ManualRoshaizul Nizam Mohd SaniNessuna valutazione finora
- Mehak WD - 2Documento34 pagineMehak WD - 2bmehak154Nessuna valutazione finora
- HTML5 Input TypesDocumento7 pagineHTML5 Input TypessureshNessuna valutazione finora
- Topic 7: Understanding The Functionality of HTML What Is HTML?Documento9 pagineTopic 7: Understanding The Functionality of HTML What Is HTML?Erandi GodamannaNessuna valutazione finora
- How To Make A Blogger TemplateDocumento35 pagineHow To Make A Blogger Templateamargupta100% (1)
- YVK Antiquities Project ReportDocumento8 pagineYVK Antiquities Project ReportKillShot RahilNessuna valutazione finora
- Resume 2022updateDocumento1 paginaResume 2022updateJB - 10SS 731765 Harold M Brathwaite SSNessuna valutazione finora
- Web Developer with 8+ Years of ExperienceDocumento7 pagineWeb Developer with 8+ Years of ExperiencerecruiterkkNessuna valutazione finora
- Release Note E39143Documento40 pagineRelease Note E39143Anonymous Ulfg13EGNessuna valutazione finora
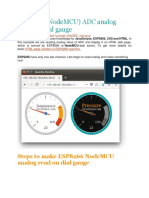
- Read analog value and display on ESP8266 NodeMCU dial gaugeDocumento9 pagineRead analog value and display on ESP8266 NodeMCU dial gaugeNoor SyaifulNessuna valutazione finora
- Training For Fresher Trainee Junior ASP - Dot Net Developer MVC Nopcommerce - Ver 1.0Documento4 pagineTraining For Fresher Trainee Junior ASP - Dot Net Developer MVC Nopcommerce - Ver 1.02112056.Vruti DesaiNessuna valutazione finora
- M Tech SDM-Curriculum SyllabiDocumento69 pagineM Tech SDM-Curriculum SyllabiDinesh AnbumaniNessuna valutazione finora
- Topic 3Documento25 pagineTopic 3Lotan KumarNessuna valutazione finora
- Polymer and Web ComponentsDocumento26 paginePolymer and Web ComponentsAdjetey Adjei-laryeaNessuna valutazione finora
- RJ Hospital Management SystemDocumento3 pagineRJ Hospital Management SystemRamNessuna valutazione finora
- MCQDocumento8 pagineMCQDebarpitaa RoyNessuna valutazione finora
- Web Application For Duhok Dormitory SystemDocumento24 pagineWeb Application For Duhok Dormitory SystemDler AhmadNessuna valutazione finora
- Front End Foundations Level1Documento43 pagineFront End Foundations Level1Lucian CernăuţeanuNessuna valutazione finora
- 4.patient Record ManagementDocumento110 pagine4.patient Record ManagementDarshan NagarajNessuna valutazione finora
- Question Bank - WTL-oral Question Bank - WTL-oralDocumento9 pagineQuestion Bank - WTL-oral Question Bank - WTL-oralAniket BhoknalNessuna valutazione finora
- 06 Trends & IssuesDocumento59 pagine06 Trends & IssuesBulacandia ResearchvoirNessuna valutazione finora