Potrebbero piacerti anche
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Circuits Series, Parallel, CombinationDocumento15 pagineCircuits Series, Parallel, CombinationShiba TatsuyaNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Research Youth EmpowermentDocumento18 pagineResearch Youth EmpowermentShiba Tatsuya0% (2)
- SORTINGDocumento46 pagineSORTINGKhushbu BansalNessuna valutazione finora
- Humanistic Theories: Abraham Maslow's TheoryDocumento3 pagineHumanistic Theories: Abraham Maslow's TheoryShiba TatsuyaNessuna valutazione finora
- ExplainDocumento1 paginaExplainShiba TatsuyaNessuna valutazione finora
- Computer Memory and Processor HistoryDocumento7 pagineComputer Memory and Processor HistoryShiba TatsuyaNessuna valutazione finora
- C++ Hands-On LecturesDocumento23 pagineC++ Hands-On LecturesShiba TatsuyaNessuna valutazione finora
- Group 1 - Heap Sort and TimsortDocumento19 pagineGroup 1 - Heap Sort and TimsortMariebeth SenoNessuna valutazione finora
- Dijkstra AlgorithmDocumento4 pagineDijkstra AlgorithmMir Salam KhanNessuna valutazione finora
- LeetCode Cheat Sheet - PIRATE KINGDocumento18 pagineLeetCode Cheat Sheet - PIRATE KINGJoão Vitor R. BaptistaNessuna valutazione finora
- CB19541 AAD SyllabusDocumento2 pagineCB19541 AAD SyllabusbhuvangatesNessuna valutazione finora
- LABMANUALFORMATCNdocx 2022 08 28 20 44 43Documento22 pagineLABMANUALFORMATCNdocx 2022 08 28 20 44 43Nishar AlamNessuna valutazione finora
- HKUST COMP3211 Quiz1Documento3 pagineHKUST COMP3211 Quiz1TKFNessuna valutazione finora
- ResMIL BubbleDocumento17 pagineResMIL BubblemqlmjjjpNessuna valutazione finora
- Bellman FordDocumento10 pagineBellman FordSandeep MehtaNessuna valutazione finora
- The University of Jordan Department of Mathematics: Branch and CutDocumento17 pagineThe University of Jordan Department of Mathematics: Branch and CutAnonymous CZYe2HNessuna valutazione finora
- Algorithms and Data Structures 5Documento11 pagineAlgorithms and Data Structures 5Kyll LNessuna valutazione finora
- Sorting & Searching PDFDocumento4 pagineSorting & Searching PDFJune NgNessuna valutazione finora
- Problem Set 7 SolutionsDocumento7 pagineProblem Set 7 SolutionsBarkhurdar SavdhanNessuna valutazione finora
- Dis09 Sol PDFDocumento4 pagineDis09 Sol PDFpoopyNessuna valutazione finora
- Transport, Assignment and TranshipmentDocumento71 pagineTransport, Assignment and TranshipmentAbdul Ghaffar depar100% (1)
- Lecture Notes On Matroid Intersection: 6.1.1 Bipartite MatchingsDocumento13 pagineLecture Notes On Matroid Intersection: 6.1.1 Bipartite MatchingsJoe SchmoeNessuna valutazione finora
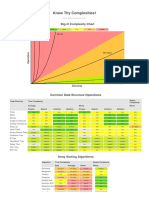
- Know Thy Complexities!: Big-O Complexity ChartDocumento2 pagineKnow Thy Complexities!: Big-O Complexity ChartDhruvaSNessuna valutazione finora
- Ada Lab ManualDocumento35 pagineAda Lab ManualveenarajeevNessuna valutazione finora
- AT2: Graphing The Hospital Floor Problem: Two Floor Plans of A Hospital Floor Are Shown. Draw A Graph That Represents The Floor PlanDocumento4 pagineAT2: Graphing The Hospital Floor Problem: Two Floor Plans of A Hospital Floor Are Shown. Draw A Graph That Represents The Floor PlanKimberly IgbalicNessuna valutazione finora
- Solutions of Tutorial Session 5 Graphs: A B C DDocumento10 pagineSolutions of Tutorial Session 5 Graphs: A B C DNguyễn Thanh LinhNessuna valutazione finora
- Chapter 2 Searching and SortingDocumento19 pagineChapter 2 Searching and Sortingsasane sachinNessuna valutazione finora
- Cse 418Documento3 pagineCse 418Kislay SinghNessuna valutazione finora
- HKUST COMP3211 Quiz1 SolutionDocumento6 pagineHKUST COMP3211 Quiz1 SolutionTKFNessuna valutazione finora
- Design and Analysis of Algorithms Week 11 Lecture 19: Dr. Husnain Mansoor AliDocumento29 pagineDesign and Analysis of Algorithms Week 11 Lecture 19: Dr. Husnain Mansoor AliMuhammad AmmarNessuna valutazione finora
- ADA LAB Assignment PDFDocumento17 pagineADA LAB Assignment PDFChandia PandaNessuna valutazione finora
- CS3401 - AlgorithmDocumento37 pagineCS3401 - Algorithmparanjothi karthikNessuna valutazione finora
- Weiler Atherton Algorithm-Poygon ClippingDocumento12 pagineWeiler Atherton Algorithm-Poygon ClippingVarchasva SinghNessuna valutazione finora
- AlgorithmsDocumento10 pagineAlgorithmsPa Krishna SankarNessuna valutazione finora
- Dsa Lab It LabmanualDocumento4 pagineDsa Lab It LabmanualpoojadhanrajaniNessuna valutazione finora