Potrebbero piacerti anche
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- BPC Innoteam M - Tes PDFDocumento27 pagineBPC Innoteam M - Tes PDFmusturNessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- 04285956Documento12 pagine04285956raviNessuna valutazione finora
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Transformations and Actions: A Visual Guide of The APIDocumento122 pagineTransformations and Actions: A Visual Guide of The APIJorge Emilio Roa BarretoNessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- Transformations and Actions: A Visual Guide of The APIDocumento122 pagineTransformations and Actions: A Visual Guide of The APIJorge Emilio Roa BarretoNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- BPC Innoteam M - Tes PDFDocumento27 pagineBPC Innoteam M - Tes PDFmusturNessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- BPC Innoteam M - Tes PDFDocumento27 pagineBPC Innoteam M - Tes PDFmusturNessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- AnnexureD PDFDocumento1 paginaAnnexureD PDFMukesh ShahNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Excel 51 TipsDocumento59 pagineExcel 51 Tipsklodiklodi100% (1)
- A Universal UHF RFID Reader AntennaDocumento8 pagineA Universal UHF RFID Reader AntennaraviNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Numerical MethodsDocumento25 pagineNumerical MethodsraviNessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- When Are Transmission-Line Effects Important For On-Chip InterconnectionsDocumento11 pagineWhen Are Transmission-Line Effects Important For On-Chip InterconnectionsraviNessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Design of A Compact Antenna With Flared Groundplane For A Wearable Breast Hyperthermia SystemDocumento12 pagineDesign of A Compact Antenna With Flared Groundplane For A Wearable Breast Hyperthermia SystemraviNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Ferrite-Loaded Waveguide AntennaDocumento4 pagineFerrite-Loaded Waveguide AntennaraviNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Hadoop and Java Ques - AnsDocumento222 pagineHadoop and Java Ques - AnsraviNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (344)
- Hive ObjectiveDocumento2 pagineHive ObjectiveraviNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- The Tapered Slot AntennaDocumento10 pagineThe Tapered Slot AntennaraviNessuna valutazione finora
- Hadoop ObjectiveDocumento2 pagineHadoop ObjectiveraviNessuna valutazione finora
- A Shared Aperture Dual-Frequency Circularly Polarized Microstrip Array AntennaDocumento4 pagineA Shared Aperture Dual-Frequency Circularly Polarized Microstrip Array AntennaraviNessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Hadoop Interview Questions Author: Pappupass Learning ResourceDocumento16 pagineHadoop Interview Questions Author: Pappupass Learning ResourceDheeraj ReddyNessuna valutazione finora
- Microwave Very Short Wave: 300 MHZ - 300 GHZDocumento50 pagineMicrowave Very Short Wave: 300 MHZ - 300 GHZraviNessuna valutazione finora
- Dual-Loop Antenna Design For Hepta-BandDocumento11 pagineDual-Loop Antenna Design For Hepta-BandraviNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Design A MultibandDocumento3 pagineDesign A MultibandraviNessuna valutazione finora
- PIG High-Level LangDocumento42 paginePIG High-Level LangraviNessuna valutazione finora
- Cubesat APS Letter 2015 RefDocumento4 pagineCubesat APS Letter 2015 RefraviNessuna valutazione finora
- Ch4-Wireless Telecommunication SystemsDocumento52 pagineCh4-Wireless Telecommunication SystemsHerlene Jayne la RoaNessuna valutazione finora
- RF Power AmplifiersDocumento20 pagineRF Power AmplifiersraviNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- Understanding The HDFSFile SystemDocumento15 pagineUnderstanding The HDFSFile SystemraviNessuna valutazione finora
- SparameterIndetail CrosschkDocumento6 pagineSparameterIndetail CrosschkraviNessuna valutazione finora
- PigpptDocumento31 paginePigpptraviNessuna valutazione finora
- F SecureDocumento84 pagineF SecureManishNessuna valutazione finora
- 1 CONTENT UPDATE Ed 3 Building and Enhancing New Literacies Across The Curriculum PDFDocumento10 pagine1 CONTENT UPDATE Ed 3 Building and Enhancing New Literacies Across The Curriculum PDFMeriel JagmisNessuna valutazione finora
- TwinCAT TimersDocumento6 pagineTwinCAT TimersveithungengNessuna valutazione finora
- Cae PDFDocumento56 pagineCae PDFChetan HcNessuna valutazione finora
- Competitions: Yauhen BabakhinDocumento29 pagineCompetitions: Yauhen BabakhinAbanoub EdwardNessuna valutazione finora
- GPL Unix Questions For AMDOCSDocumento8 pagineGPL Unix Questions For AMDOCSTabish AlmasNessuna valutazione finora
- Casio FX 82ZA PLUS CheatsheetDocumento11 pagineCasio FX 82ZA PLUS CheatsheetQuinton DuvenageNessuna valutazione finora
- A. Very Short Answer Type QuestionsDocumento2 pagineA. Very Short Answer Type QuestionsArchi SamantaraNessuna valutazione finora
- Oracle Linux 8: Managing Core System ConfigurationDocumento48 pagineOracle Linux 8: Managing Core System Configurationcoky doankNessuna valutazione finora
- CAT P32 - Modbus ProtocolDocumento8 pagineCAT P32 - Modbus ProtocolThomas BORNEYNessuna valutazione finora
- DatabasesDocumento94 pagineDatabasesUshna KhalidNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Adaptive Air Quality Sensing Using Machine LearningDocumento10 pagineAdaptive Air Quality Sensing Using Machine LearningIJRASETPublicationsNessuna valutazione finora
- Prep at Ease: Internship/Project (3180701)Documento19 paginePrep at Ease: Internship/Project (3180701)Shail HiraniNessuna valutazione finora
- Quartiles For Grouped DataDocumento19 pagineQuartiles For Grouped DataBeverly Joy Chicano AlonzoNessuna valutazione finora
- FriendlyPanel Cessna 208 GNS430 ManualDocumento27 pagineFriendlyPanel Cessna 208 GNS430 ManualKonstantin SusdaltzewNessuna valutazione finora
- KST PLC ProConOS 40 enDocumento35 pagineKST PLC ProConOS 40 encheloooxxxNessuna valutazione finora
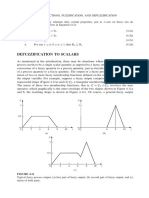
- Defuzzification To ScalarsDocumento13 pagineDefuzzification To ScalarsJoel Edgar Fuertes MelendezNessuna valutazione finora
- Old Paper - 202201 - A6-R5 - COMPUTER ORGANIZATION AND OPERATING SYSTEMDocumento8 pagineOld Paper - 202201 - A6-R5 - COMPUTER ORGANIZATION AND OPERATING SYSTEMJacks LibrearyNessuna valutazione finora
- Web Redesign 2.0 Workflow That WorksDocumento445 pagineWeb Redesign 2.0 Workflow That WorksFelipe Cavalcante100% (1)
- Signlab V91 Vinyl Pro Edition Cracked FULLDocumento2 pagineSignlab V91 Vinyl Pro Edition Cracked FULLLenikime 44Nessuna valutazione finora
- Vised ManualDocumento113 pagineVised ManualTatis MontañezNessuna valutazione finora
- South NTS362R10Documento2 pagineSouth NTS362R10RodrigoNessuna valutazione finora
- Vulnerability Assessment and Penetration Testing IJERTV10IS050111Documento6 pagineVulnerability Assessment and Penetration Testing IJERTV10IS050111Vamsi KrishnaNessuna valutazione finora
- Exercise 2 OSPFv2 - MUHAMMAD IZWAN BIN NAZRI - CS2555ADocumento7 pagineExercise 2 OSPFv2 - MUHAMMAD IZWAN BIN NAZRI - CS2555Aezone8553Nessuna valutazione finora
- COM 121 Topic 1Documento10 pagineCOM 121 Topic 1Bakari HamisiNessuna valutazione finora
- Python QuizDocumento99 paginePython QuizPravin PoudelNessuna valutazione finora
- Vmware Basic Support DatasheetDocumento1 paginaVmware Basic Support DatasheetBenzakour MouadNessuna valutazione finora
- D002186AA3 EVBox Troniq Modular Installation ManualDocumento74 pagineD002186AA3 EVBox Troniq Modular Installation ManualCarlos AndradeNessuna valutazione finora
- W3Schools SQL Quiz TestDocumento4 pagineW3Schools SQL Quiz TestMehulNessuna valutazione finora
- A2-1 InstructionsDocumento2 pagineA2-1 Instructions1999jogeshNessuna valutazione finora
- Starting Database Administration: Oracle DBADa EverandStarting Database Administration: Oracle DBAValutazione: 3 su 5 stelle3/5 (2)
- Dark Data: Why What You Don’t Know MattersDa EverandDark Data: Why What You Don’t Know MattersValutazione: 4.5 su 5 stelle4.5/5 (3)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsDa EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsValutazione: 4.5 su 5 stelle4.5/5 (24)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleDa EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleValutazione: 4 su 5 stelle4/5 (16)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesDa EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesNessuna valutazione finora