Potrebbero piacerti anche
- Discovering Emerging Topics in Social Streams Via Link-Anomaly DetectionDocumento5 pagineDiscovering Emerging Topics in Social Streams Via Link-Anomaly DetectionPraveena Suresh BabuNessuna valutazione finora
- Exploring Emerging Issues in Social Torrent Via Link-Irregularity DetectionDocumento6 pagineExploring Emerging Issues in Social Torrent Via Link-Irregularity DetectionerpublicationNessuna valutazione finora
- Detecting Emerging Areas in Social StreamsDocumento6 pagineDetecting Emerging Areas in Social StreamsEditor IJRITCCNessuna valutazione finora
- mln2018 PDFDocumento11 paginemln2018 PDFKheir eddine DaouadiNessuna valutazione finora
- Analyzing Public Sentiments A ReviewDocumento3 pagineAnalyzing Public Sentiments A ReviewEditor IJRITCCNessuna valutazione finora
- Social Network Analysis Literature ReviewDocumento6 pagineSocial Network Analysis Literature Reviewafmzjbxmbfpoox100% (1)
- Petko Bogdanov Et Alii - The Social Media Genome. Modeling Individual Topic-Specific Behavior in Social Media (ArXiv, July 2013, 2nd)Documento7 paginePetko Bogdanov Et Alii - The Social Media Genome. Modeling Individual Topic-Specific Behavior in Social Media (ArXiv, July 2013, 2nd)Tommaso CiminoNessuna valutazione finora
- Da CH4 SlqaDocumento4 pagineDa CH4 SlqaSushant ThiteNessuna valutazione finora
- Opinion Retrieval in Twitter: Zhunchen Luo Miles Osborne Ting WangDocumento4 pagineOpinion Retrieval in Twitter: Zhunchen Luo Miles Osborne Ting WangNeri David MartinezNessuna valutazione finora
- AM08 Gruzd Hay ICTADocumento5 pagineAM08 Gruzd Hay ICTAkcwbsgNessuna valutazione finora
- Applications of Social Media and Social Network Analysis - Lecture Notes in Social Networks PDFDocumento247 pagineApplications of Social Media and Social Network Analysis - Lecture Notes in Social Networks PDFrwrewrwt100% (1)
- Semantifying Twitter - The Influencetracker OntologyDocumento8 pagineSemantifying Twitter - The Influencetracker OntologyjbshirkNessuna valutazione finora
- FX RTMDocumento15 pagineFX RTMАйзада АманкелдиеваNessuna valutazione finora
- Opinion Mining On Social Media Data: 2013 IEEE 14th International Conference On Mobile Data ManagementDocumento6 pagineOpinion Mining On Social Media Data: 2013 IEEE 14th International Conference On Mobile Data ManagementsenthilnathanNessuna valutazione finora
- SemanticcDocumento2 pagineSemanticcErma Farani SinagaNessuna valutazione finora
- Temporal and Social Context Based Burst Detection From FolksonomiesDocumento6 pagineTemporal and Social Context Based Burst Detection From FolksonomiesDonalNessuna valutazione finora
- LPKM 2018 PDFDocumento9 pagineLPKM 2018 PDFKheir eddine DaouadiNessuna valutazione finora
- Classification and Analysis On Fake News in Social Media Using Machine LearningDocumento10 pagineClassification and Analysis On Fake News in Social Media Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- Active Online Learning For Social Media Analysis To Support Crisis ManagementDocumento10 pagineActive Online Learning For Social Media Analysis To Support Crisis Managementrock starNessuna valutazione finora
- Unsupervised User Stance Detection On TwitterDocumento12 pagineUnsupervised User Stance Detection On TwitterdfghfNessuna valutazione finora
- TweetDocumento63 pagineTweetaltafNessuna valutazione finora
- Sentiment Analysis of TwitterDocumento9 pagineSentiment Analysis of TwitterIJRASETPublicationsNessuna valutazione finora
- Predicting Covid-19 Misleading Information Using Sentiment AnalysisDocumento7 paginePredicting Covid-19 Misleading Information Using Sentiment AnalysisIJRASETPublicationsNessuna valutazione finora
- A Socio-Linguistic Model For Cyberbullying Detection: Sabina Tomkins, Lise Getoor, Yunfei Chen, Yi ZhangDocumento8 pagineA Socio-Linguistic Model For Cyberbullying Detection: Sabina Tomkins, Lise Getoor, Yunfei Chen, Yi ZhangSufiarli GemilangNessuna valutazione finora
- ETCW26Documento6 pagineETCW26Editor IJAERDNessuna valutazione finora
- Precedent-Based Approach For The Identification of Deviant Behavior in Social MediaDocumento7 paginePrecedent-Based Approach For The Identification of Deviant Behavior in Social MediaNiklasNessuna valutazione finora
- A Review On Twitter Sentiment Analysis Using MLDocumento6 pagineA Review On Twitter Sentiment Analysis Using MLIJRASETPublicationsNessuna valutazione finora
- Irjet Fake News Prediction Using MachineDocumento5 pagineIrjet Fake News Prediction Using Machinealperen.unal89Nessuna valutazione finora
- Sin Review-2 PDFDocumento14 pagineSin Review-2 PDFJOSHITHANessuna valutazione finora
- Large-Scale Multi-Agent-based Modeling and Simulation of Microblogging-Based Online Social NetworkDocumento12 pagineLarge-Scale Multi-Agent-based Modeling and Simulation of Microblogging-Based Online Social NetworkJoaquim MorenoNessuna valutazione finora
- Author Profiling Using Semantic and Syntactic FeaturesDocumento12 pagineAuthor Profiling Using Semantic and Syntactic FeaturesKarthik KrishnamurthiNessuna valutazione finora
- Who Gives A Tweet? Evaluating Microblog Content Value: Paul André, Michael S. Bernstein, Kurt LutherDocumento4 pagineWho Gives A Tweet? Evaluating Microblog Content Value: Paul André, Michael S. Bernstein, Kurt Luthermisafirem3798Nessuna valutazione finora
- Ontological Technologies For User Modelling 2010Documento40 pagineOntological Technologies For User Modelling 2010openid_APAKwdRcNessuna valutazione finora
- 1 s2.0 S1877050915020694 MainDocumento9 pagine1 s2.0 S1877050915020694 MainHISAN ARIQNessuna valutazione finora
- Event Detection, Tracking and Visualization in Twitter A Mention-Anomaly-Based ApproachDocumento18 pagineEvent Detection, Tracking and Visualization in Twitter A Mention-Anomaly-Based Approachياسر سعد الخزرجيNessuna valutazione finora
- S U R J S S: Indh Niversity Esearch Ournal (Cience Eries)Documento6 pagineS U R J S S: Indh Niversity Esearch Ournal (Cience Eries)adsNessuna valutazione finora
- 07516129Documento6 pagine07516129Govind UpadhyayNessuna valutazione finora
- KDD 2015 Dissertation AwardDocumento6 pagineKDD 2015 Dissertation AwardCollegePapersForSaleSingapore100% (1)
- HS Detection+twitter 2018 SpringerDocumento13 pagineHS Detection+twitter 2018 SpringerAkshatha ShettyNessuna valutazione finora
- Computer Literature ReviewDocumento8 pagineComputer Literature Reviewafdtywqae100% (1)
- Multi-Party Privacy Risks in Social Networks: AbstractDocumento36 pagineMulti-Party Privacy Risks in Social Networks: AbstractyashvantNessuna valutazione finora
- A Batch Based Approach For Tweeting Geotags of Social Media AttributesDocumento13 pagineA Batch Based Approach For Tweeting Geotags of Social Media AttributesIJRASETPublicationsNessuna valutazione finora
- Monkeylearn ThesisDocumento19 pagineMonkeylearn ThesisvideepsinghalNessuna valutazione finora
- Ijet V3i6p32Documento9 pagineIjet V3i6p32International Journal of Engineering and TechniquesNessuna valutazione finora
- Sarcastic Tweet - MGRDocumento26 pagineSarcastic Tweet - MGRvikramgandhi89Nessuna valutazione finora
- Crowd Based Live Emotion Response Decoder Using Social Media Platforms - TwitterDocumento5 pagineCrowd Based Live Emotion Response Decoder Using Social Media Platforms - TwitterInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- How Others Affect Your Twitter #Hashtag Adoption? Examination of Community - Based and Context-Based Information Diffusion in TwitterDocumento4 pagineHow Others Affect Your Twitter #Hashtag Adoption? Examination of Community - Based and Context-Based Information Diffusion in TwitterjaquefariNessuna valutazione finora
- Sentiment Analysis Tool Using Machine Learning AlgorithmsDocumento5 pagineSentiment Analysis Tool Using Machine Learning AlgorithmsInternational Journal of Application or Innovation in Engineering & ManagementNessuna valutazione finora
- Group - 5 MIS Assignment 3Documento7 pagineGroup - 5 MIS Assignment 3yogendra choukikerNessuna valutazione finora
- A Comprehensive Study of Twitter Social NetworksDocumento7 pagineA Comprehensive Study of Twitter Social NetworksviniciuscarpeNessuna valutazione finora
- Topic Models From Twitter Hashtags: 1 Problem DefinitionDocumento2 pagineTopic Models From Twitter Hashtags: 1 Problem DefinitionEmmanuel MecanosaurioNessuna valutazione finora
- Deep Neural Networks For Bot DetectionDocumento35 pagineDeep Neural Networks For Bot Detectionneha janghelNessuna valutazione finora
- Research Paper On Social Network AnalysisDocumento7 pagineResearch Paper On Social Network Analysisafedpmqgr100% (1)
- Rumor Detection From Social MediaDocumento4 pagineRumor Detection From Social MediaSageerNessuna valutazione finora
- Challenges in Developing Opinion Mining Tools For Social MediaDocumento8 pagineChallenges in Developing Opinion Mining Tools For Social MediaBalazsovicsNessuna valutazione finora
- Digital Assignment-1 Literature Review On Twitter Sentiment Analysis Name: G.Tirumala Reg No: 16BCE0202 1)Documento9 pagineDigital Assignment-1 Literature Review On Twitter Sentiment Analysis Name: G.Tirumala Reg No: 16BCE0202 1)guntreddi tirumalaNessuna valutazione finora
- CCL MiniProjectDocumento8 pagineCCL MiniProjectSakshi PawarNessuna valutazione finora
- Hate Speech Detection Using Machine LearningDocumento5 pagineHate Speech Detection Using Machine LearningIJRASETPublicationsNessuna valutazione finora
- Evaluation of Deep Learning Methods in Twitter Statistics Emotion EvaluationDocumento7 pagineEvaluation of Deep Learning Methods in Twitter Statistics Emotion EvaluationEditor IJETBSNessuna valutazione finora
- Data Science Fundamentals and Practical Approaches: Understand Why Data Science Is the NextDa EverandData Science Fundamentals and Practical Approaches: Understand Why Data Science Is the NextNessuna valutazione finora
- Using Fingerprint Authentication To Reduce System Security: An Empirical StudyDocumento15 pagineUsing Fingerprint Authentication To Reduce System Security: An Empirical StudySikkandhar JabbarNessuna valutazione finora
- Bandwidth and Time Estimation - Image - SharingDocumento13 pagineBandwidth and Time Estimation - Image - SharingSikkandhar JabbarNessuna valutazione finora
- Data Flow Diagram: Admin LoginDocumento2 pagineData Flow Diagram: Admin LoginSikkandhar JabbarNessuna valutazione finora
- Cbir Image Processing ScreensDocumento11 pagineCbir Image Processing ScreensSikkandhar JabbarNessuna valutazione finora
- Module Description PreprocessingDocumento45 pagineModule Description PreprocessingSikkandhar JabbarNessuna valutazione finora
- Car Rental ScreenDocumento23 pagineCar Rental ScreenSikkandhar JabbarNessuna valutazione finora
- Blood Bank Management System - CorrectedDocumento55 pagineBlood Bank Management System - CorrectedSikkandhar JabbarNessuna valutazione finora
- MessageDocumento1 paginaMessageSikkandhar JabbarNessuna valutazione finora
- Full Fee Payer Filled PDFDocumento2 pagineFull Fee Payer Filled PDFSikkandhar JabbarNessuna valutazione finora
- Web Based Student Attendance SystemDocumento2 pagineWeb Based Student Attendance SystemSikkandhar JabbarNessuna valutazione finora
- MessageDocumento1 paginaMessageSikkandhar JabbarNessuna valutazione finora
- Neural NWDocumento11 pagineNeural NWSikkandhar JabbarNessuna valutazione finora
- Atkins - Meal Plan - Week - Onephase One PDFDocumento3 pagineAtkins - Meal Plan - Week - Onephase One PDFTakacs AndreaNessuna valutazione finora
- Rice Mill ManagementDocumento1 paginaRice Mill ManagementSikkandhar JabbarNessuna valutazione finora
- Meena - First 4 ChaptersDocumento29 pagineMeena - First 4 ChaptersSikkandhar JabbarNessuna valutazione finora
- Job Appointment LetterDocumento11 pagineJob Appointment LetterSikkandhar JabbarNessuna valutazione finora
- Library PPT 1 RevDocumento12 pagineLibrary PPT 1 RevSikkandhar JabbarNessuna valutazione finora
- Virtual Exam RegulatorDocumento13 pagineVirtual Exam RegulatorSikkandhar JabbarNessuna valutazione finora
- Trending Topics Jasist2014 - Preprint PDFDocumento16 pagineTrending Topics Jasist2014 - Preprint PDFSikkandhar JabbarNessuna valutazione finora
- Job Appointment Letter FormatDocumento4 pagineJob Appointment Letter FormatSikkandhar JabbarNessuna valutazione finora
- Android SyllabusDocumento5 pagineAndroid SyllabusSikkandhar JabbarNessuna valutazione finora
- New Titles 17Documento23 pagineNew Titles 17Sikkandhar JabbarNessuna valutazione finora
- Abstract Mi Projects 2017Documento89 pagineAbstract Mi Projects 2017Sikkandhar JabbarNessuna valutazione finora
- VB TitlesDocumento1 paginaVB TitlesSikkandhar JabbarNessuna valutazione finora
- Abstract 2Documento119 pagineAbstract 2Sikkandhar JabbarNessuna valutazione finora
- Ramya ScreenDocumento11 pagineRamya ScreenSikkandhar JabbarNessuna valutazione finora
- Event Management System VB Net ReportDocumento67 pagineEvent Management System VB Net ReportSikkandhar Jabbar100% (2)
- An Improved Machine Learning Algorithm For Liver Disorder MiningDocumento1 paginaAn Improved Machine Learning Algorithm For Liver Disorder MiningSikkandhar JabbarNessuna valutazione finora
- Credit CardDocumento7 pagineCredit CardSikkandhar JabbarNessuna valutazione finora
- 1Documento5 pagine1Sikkandhar JabbarNessuna valutazione finora
- Students Online Usage Global Trends Report 2013 NCDocumento23 pagineStudents Online Usage Global Trends Report 2013 NCRachelNessuna valutazione finora
- Effectiveness of Social Media Networks As A Strategic ToolDocumento10 pagineEffectiveness of Social Media Networks As A Strategic ToolVisshen BabooNessuna valutazione finora
- How Social Media Affects The Tourism Industry of Calapan City Adolph Lance RicoDocumento12 pagineHow Social Media Affects The Tourism Industry of Calapan City Adolph Lance RicoRynjeff Lui-PioNessuna valutazione finora
- 10 11648 J Ajad 20170204 13 PDFDocumento5 pagine10 11648 J Ajad 20170204 13 PDFJunalyn BonifacioNessuna valutazione finora
- Research Chapter 1 3 1Documento23 pagineResearch Chapter 1 3 1Arianne MarjesNessuna valutazione finora
- Social Engineering For Pentester PenTest - 02 - 2013Documento81 pagineSocial Engineering For Pentester PenTest - 02 - 2013Black RainNessuna valutazione finora
- Advanced Photoshop Issue 043 PDFDocumento81 pagineAdvanced Photoshop Issue 043 PDFDipesh BardoliaNessuna valutazione finora
- Impact of Social Media On Administrative Staff Employees in Case of Woldia UniversityDocumento6 pagineImpact of Social Media On Administrative Staff Employees in Case of Woldia UniversityInternational Journal of Innovative Science and Research TechnologyNessuna valutazione finora
- Windows Phone 8S by HTC User GuideDocumento102 pagineWindows Phone 8S by HTC User GuideandrodacostaNessuna valutazione finora
- Impact of Social Media On Youth: October 2019Documento3 pagineImpact of Social Media On Youth: October 2019pradeep aroraNessuna valutazione finora
- Christine Ritter: Evisu Banbu ReportDocumento32 pagineChristine Ritter: Evisu Banbu ReportUtkan AlpNessuna valutazione finora
- Thesis Report For ART 203Documento39 pagineThesis Report For ART 203Masum BillahNessuna valutazione finora
- Negative Effects of Social Networking Research PaperDocumento5 pagineNegative Effects of Social Networking Research PaperxtojbbhkfNessuna valutazione finora
- Windows The Official Magazine 2013 09 - CompressDocumento100 pagineWindows The Official Magazine 2013 09 - CompressSoninho FelizNessuna valutazione finora
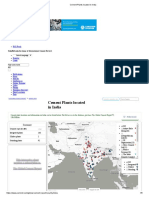
- Cement Plants Located in India Part 1Documento5 pagineCement Plants Located in India Part 1hemanthillipilliNessuna valutazione finora
- Jin, Dal Yong (Edit.) - Mobile Gaming in Asia. Politics, Culture and Emerging Technologies (2017)Documento245 pagineJin, Dal Yong (Edit.) - Mobile Gaming in Asia. Politics, Culture and Emerging Technologies (2017)Luis Carlos Ruiz CoronaNessuna valutazione finora
- Selfie Expectancies Among Adolescents Construction PDFDocumento14 pagineSelfie Expectancies Among Adolescents Construction PDFGisell De La RosaNessuna valutazione finora
- Infant Jesus Learning Academy of Rodriguez, RizalDocumento29 pagineInfant Jesus Learning Academy of Rodriguez, RizalAngel May SenseNessuna valutazione finora
- Expedia Case StudyDocumento2 pagineExpedia Case StudyYashvanthra A/P ArujananNessuna valutazione finora
- CS6010 - SOCIAL NETWORK ANALYSIS - Unit 1 NotesDocumento25 pagineCS6010 - SOCIAL NETWORK ANALYSIS - Unit 1 NotesDinesh Krishnan67% (6)
- English Q2, Week5, Day1 - Selection - Social MediaDocumento1 paginaEnglish Q2, Week5, Day1 - Selection - Social MediaNova Penera EscobarNessuna valutazione finora
- Chapter 1: Introduction of The Project 1.1conceptDocumento37 pagineChapter 1: Introduction of The Project 1.1conceptanand guptaNessuna valutazione finora
- Btled 3a - Abella Merry Grace - Module 3 - Educ 322Documento10 pagineBtled 3a - Abella Merry Grace - Module 3 - Educ 322jovelyn dahangNessuna valutazione finora
- Social Media and Freedom of Speech Ad ExpressionDocumento16 pagineSocial Media and Freedom of Speech Ad Expressionurvesh bhardwajNessuna valutazione finora
- 50 IELTS Speaking Part 3 Topics & Questions & Suggested Answers PDFDocumento29 pagine50 IELTS Speaking Part 3 Topics & Questions & Suggested Answers PDFInder Shakhar AroraNessuna valutazione finora
- Locke Lim Chrisryan PR2 M2Documento15 pagineLocke Lim Chrisryan PR2 M2Ira Jane Caballero33% (3)
- 4 Role of ICT in Rural Development FinalDocumento82 pagine4 Role of ICT in Rural Development FinalGeetesh SharmaNessuna valutazione finora
- History of Social Media PDFDocumento13 pagineHistory of Social Media PDFMuhammad Ainul YaqinNessuna valutazione finora
- Sales Users Guide PDFDocumento626 pagineSales Users Guide PDFRishi KamalNessuna valutazione finora
- Home Design MagazineDocumento5 pagineHome Design Magazinehttp://www.indianhomedesign.com/100% (1)