Potrebbero piacerti anche
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Kolban's Book On C.H.I.P.Documento317 pagineKolban's Book On C.H.I.P.thiagocabral88Nessuna valutazione finora
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5795)
- For Purposeful and Meaningful Technology Integration in The ClassroomDocumento19 pagineFor Purposeful and Meaningful Technology Integration in The ClassroomVincent Chris Ellis TumaleNessuna valutazione finora
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- Tips Experiments With MatlabDocumento190 pagineTips Experiments With MatlabVishalNessuna valutazione finora
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- Kina23744ens 002-Seisracks1Documento147 pagineKina23744ens 002-Seisracks1Adrian_Condrea_4281Nessuna valutazione finora
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Lesson 2 (Locating Main Ideas)Documento18 pagineLesson 2 (Locating Main Ideas)Glyneth Dela TorreNessuna valutazione finora
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- InheretanceDocumento8 pagineInheretancefarhan.mukhtiarNessuna valutazione finora
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Saint Albert Polytechnic College, Inc. Bachelor of Science in Office AdministrationDocumento15 pagineSaint Albert Polytechnic College, Inc. Bachelor of Science in Office AdministrationAustin Grey Pineda MacoteNessuna valutazione finora
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- Meeting Wise Agenda TemplateDocumento1 paginaMeeting Wise Agenda Templateapi-416923934Nessuna valutazione finora
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- Evolution of Management TheoriesDocumento20 pagineEvolution of Management TheoriesKanishq BawejaNessuna valutazione finora
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- MATH 6 Q4 Module 8Documento17 pagineMATH 6 Q4 Module 8Amor DionisioNessuna valutazione finora
- EnglishFile4e Intermediate Plus TG PCM Vocab 1BDocumento1 paginaEnglishFile4e Intermediate Plus TG PCM Vocab 1Bayşe adaliNessuna valutazione finora
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Protein Dot BlottingDocumento4 pagineProtein Dot BlottingstcosmoNessuna valutazione finora
- The Saga of Flying Objects - La Saga de Los Objetos VoladoresDocumento15 pagineThe Saga of Flying Objects - La Saga de Los Objetos VoladoresCiborgSeptiembreNessuna valutazione finora
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Kelompok 5Documento16 pagineKelompok 5bintangNessuna valutazione finora
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Oral Com Mods Except 6Documento4 pagineOral Com Mods Except 6ninjarkNessuna valutazione finora
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- RsidllDocumento99 pagineRsidllJp GuevaraNessuna valutazione finora
- Learn C++ Programming LanguageDocumento322 pagineLearn C++ Programming LanguageAli Eb100% (8)
- BC-2800 Maintenance Manual For EngineersDocumento3 pagineBC-2800 Maintenance Manual For EngineersIslam AdelNessuna valutazione finora
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Bao Nguyen - Internship Report v1Documento41 pagineBao Nguyen - Internship Report v1Giao DươngNessuna valutazione finora
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- Mutants & Masterminds 1st Ed Character Generater (Xls Spreadsheet)Documento89 pagineMutants & Masterminds 1st Ed Character Generater (Xls Spreadsheet)WesleyNessuna valutazione finora
- Strong PasswordDocumento2 pagineStrong PasswordluciangeNessuna valutazione finora
- 500 Grammar Based Conversation Question12Documento16 pagine500 Grammar Based Conversation Question12Ivo Barry Ward100% (1)
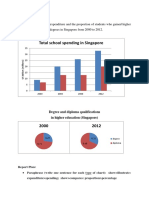
- Total School Spending in Singapore: Task 1 020219Documento6 pagineTotal School Spending in Singapore: Task 1 020219viper_4554Nessuna valutazione finora
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- Control Panel Manual 1v4Documento52 pagineControl Panel Manual 1v4Gustavo HidalgoNessuna valutazione finora
- Swarm Intelligence PDFDocumento7 pagineSwarm Intelligence PDFGanesh BishtNessuna valutazione finora
- ch03 PowerpointsDocumento35 paginech03 PowerpointsBea May M. BelarminoNessuna valutazione finora
- 02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxDocumento1 pagina02.03.2017 SR Mechanical Engineer Externe Vacature InnoluxMichel van WordragenNessuna valutazione finora
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- WMS WIP PickDocumento14 pagineWMS WIP PickAvinash RoutrayNessuna valutazione finora
- ббббббббббббDocumento7 pagineббббббббббббhug1515Nessuna valutazione finora
- Stepping Stones Grade 4 ScopeDocumento2 pagineStepping Stones Grade 4 ScopeGretchen BensonNessuna valutazione finora
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)