Potrebbero piacerti anche
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Da EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Valutazione: 4.5 su 5 stelle4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDa EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryValutazione: 3.5 su 5 stelle3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDa EverandGrit: The Power of Passion and PerseveranceValutazione: 4 su 5 stelle4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDa EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaValutazione: 4.5 su 5 stelle4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDa EverandNever Split the Difference: Negotiating As If Your Life Depended On ItValutazione: 4.5 su 5 stelle4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDa EverandThe Emperor of All Maladies: A Biography of CancerValutazione: 4.5 su 5 stelle4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDa EverandThe Little Book of Hygge: Danish Secrets to Happy LivingValutazione: 3.5 su 5 stelle3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDa EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeValutazione: 4 su 5 stelle4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDa EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyValutazione: 3.5 su 5 stelle3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDa EverandShoe Dog: A Memoir by the Creator of NikeValutazione: 4.5 su 5 stelle4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDa EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreValutazione: 4 su 5 stelle4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDa EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersValutazione: 4.5 su 5 stelle4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDa EverandTeam of Rivals: The Political Genius of Abraham LincolnValutazione: 4.5 su 5 stelle4.5/5 (234)
- Her Body and Other Parties: StoriesDa EverandHer Body and Other Parties: StoriesValutazione: 4 su 5 stelle4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDa EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceValutazione: 4 su 5 stelle4/5 (895)
- The Unwinding: An Inner History of the New AmericaDa EverandThe Unwinding: An Inner History of the New AmericaValutazione: 4 su 5 stelle4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDa EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureValutazione: 4.5 su 5 stelle4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDa EverandOn Fire: The (Burning) Case for a Green New DealValutazione: 4 su 5 stelle4/5 (74)
- Web Quest IttotbDocumento2 pagineWeb Quest Ittotbapi-244383152100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)Da EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Valutazione: 4 su 5 stelle4/5 (98)
- Kali Linux Assuring Security by Penetration Testing Sample ChapterDocumento43 pagineKali Linux Assuring Security by Penetration Testing Sample ChapterPackt PublishingNessuna valutazione finora
- Big ESB Session - You Are Not AloneDocumento4 pagineBig ESB Session - You Are Not AloneLa Esperanza Maderas La Esperanza Maderas50% (4)
- Declination and Equation of TimeDocumento3 pagineDeclination and Equation of TimeFulki Kautsar SNessuna valutazione finora
- Declination and Equation of TimeDocumento3 pagineDeclination and Equation of TimeFulki Kautsar SNessuna valutazione finora
- Robbins Organization Behaviour Chapter 11Documento28 pagineRobbins Organization Behaviour Chapter 11Aya TurkNessuna valutazione finora
- PhotoVoltaic General CatalogDocumento20 paginePhotoVoltaic General CatalogCourtney HernandezNessuna valutazione finora
- IGBT Vs MOSFET - Which Device To Select PDFDocumento40 pagineIGBT Vs MOSFET - Which Device To Select PDFFulki Kautsar SNessuna valutazione finora
- DiscoveryDocumento12 pagineDiscoverySharjeel MaLikNessuna valutazione finora
- Cloud Training Plan AWSDocumento10 pagineCloud Training Plan AWSRajesh Chowdary ParaNessuna valutazione finora
- Online Gaming Addiction Among BSIT Students of Leyte Normal University Philippines Its Implications Towards Academic PerformanceDocumento11 pagineOnline Gaming Addiction Among BSIT Students of Leyte Normal University Philippines Its Implications Towards Academic PerformanceAnonymous PcPkRpAKD5100% (1)
- Longrod Vs CAP and PIN Insulators PDFDocumento11 pagineLongrod Vs CAP and PIN Insulators PDFFulki Kautsar SNessuna valutazione finora
- Wind-PV-Storage Optimal Environomic Design Using Multi-Objective Artificial Bee ColonyDocumento5 pagineWind-PV-Storage Optimal Environomic Design Using Multi-Objective Artificial Bee ColonyFulki Kautsar SNessuna valutazione finora
- AftaDocumento25 pagineAftaSheryll Joy Lopez CalayanNessuna valutazione finora
- Power System Seminar 20th April CombinedDocumento51 paginePower System Seminar 20th April CombinedFulki Kautsar SNessuna valutazione finora
- Economic Dispatch Thermal Units and Methods of SolutionDocumento15 pagineEconomic Dispatch Thermal Units and Methods of SolutionFulki Kautsar SNessuna valutazione finora
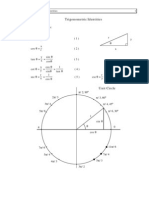
- Trig IdentDocumento6 pagineTrig Identberickson_14Nessuna valutazione finora
- Power System Seminar 20th April CombinedDocumento51 paginePower System Seminar 20th April CombinedFulki Kautsar SNessuna valutazione finora
- IEC 1109 Design Test Report Silicone Rubber Ohio Brass 222kN (50K LBS) SML Hi Lite XLDocumento27 pagineIEC 1109 Design Test Report Silicone Rubber Ohio Brass 222kN (50K LBS) SML Hi Lite XLchandansinghdeiNessuna valutazione finora
- Nur Farhanah Wakiman (CD 5295)Documento24 pagineNur Farhanah Wakiman (CD 5295)Fulki Kautsar SNessuna valutazione finora
- Measuring PV Efficiency Solar PanelsDocumento2 pagineMeasuring PV Efficiency Solar PanelsMahmood AhmedNessuna valutazione finora
- H0714954 PDFDocumento6 pagineH0714954 PDFFulki Kautsar SNessuna valutazione finora
- Trig IdentDocumento6 pagineTrig Identberickson_14Nessuna valutazione finora
- Mounting and Project Planning - Mounting Instructions V4 I400001GBDocumento36 pagineMounting and Project Planning - Mounting Instructions V4 I400001GBFulki Kautsar SNessuna valutazione finora
- 9.18 Lightning and Surge Protection For Photovoltaic (PV) SystemsDocumento9 pagine9.18 Lightning and Surge Protection For Photovoltaic (PV) SystemsFulki Kautsar SNessuna valutazione finora
- High Voltage Insulators: Porcelain Pin Type InsulatorsDocumento0 pagineHigh Voltage Insulators: Porcelain Pin Type InsulatorsChetankumar ChaudhariNessuna valutazione finora
- 02-2 Excitation CourseDocumento31 pagine02-2 Excitation CourseFulki Kautsar S0% (1)
- 9.18 Lightning and Surge Protection For Photovoltaic (PV) SystemsDocumento9 pagine9.18 Lightning and Surge Protection For Photovoltaic (PV) SystemsFulki Kautsar SNessuna valutazione finora
- Longrod Vs CAP and PIN Insulators PDFDocumento11 pagineLongrod Vs CAP and PIN Insulators PDFFulki Kautsar SNessuna valutazione finora
- Performance Model For Grid Connected Photovoltaic Inverters PDFDocumento47 paginePerformance Model For Grid Connected Photovoltaic Inverters PDFFulki Kautsar SNessuna valutazione finora
- Specification Grid Tie SPV PlantDocumento24 pagineSpecification Grid Tie SPV Plantjegadish1Nessuna valutazione finora
- Optimal Design Methods For Hybrid RenewableDocumento13 pagineOptimal Design Methods For Hybrid RenewableFulki Kautsar SNessuna valutazione finora
- Energies 09 00002Documento23 pagineEnergies 09 00002Fulki Kautsar SNessuna valutazione finora
- 01-Pricelist Modul SuryaDocumento3 pagine01-Pricelist Modul SuryaFulki Kautsar SNessuna valutazione finora
- GA TutorialDocumento19 pagineGA TutorialYugal KumarNessuna valutazione finora
- Measuring PV Efficiency Solar PanelsDocumento2 pagineMeasuring PV Efficiency Solar PanelsMahmood AhmedNessuna valutazione finora
- Timos 5.0 MC Lag PW RedDocumento127 pagineTimos 5.0 MC Lag PW RedjosmurgoNessuna valutazione finora
- Seven Days A Week - Barney Wiki - FandomDocumento4 pagineSeven Days A Week - Barney Wiki - FandomchefchadsmithNessuna valutazione finora
- DLOS8 LoRaWAN Gateway User Manual v1.2Documento52 pagineDLOS8 LoRaWAN Gateway User Manual v1.2amin rusydiNessuna valutazione finora
- UT Dallas Syllabus For Opre6302.0g1 06u Taught by Milind Dawande (Milind)Documento10 pagineUT Dallas Syllabus For Opre6302.0g1 06u Taught by Milind Dawande (Milind)UT Dallas Provost's Technology GroupNessuna valutazione finora
- VERITAS Cluster Server Commands: VCS OperationsDocumento3 pagineVERITAS Cluster Server Commands: VCS Operationsdeepaksaini420Nessuna valutazione finora
- Personas - ResumeDocumento7 paginePersonas - Resumeapi-387871360Nessuna valutazione finora
- Keys From The Golden Vault Fully Revealed, Releases February 21 - DndnextDocumento1 paginaKeys From The Golden Vault Fully Revealed, Releases February 21 - DndnextergwergNessuna valutazione finora
- Just Dial STP AnalysisDocumento19 pagineJust Dial STP AnalysisAfzal Anwar50% (2)
- Final Research PaperDocumento5 pagineFinal Research PaperIcram DokuNessuna valutazione finora
- BCN 4th and 5th Chapter NotesDocumento21 pagineBCN 4th and 5th Chapter NotesM.n KNessuna valutazione finora
- Process-to-Process Delivery: Udp and TCP: (Chapter 23)Documento41 pagineProcess-to-Process Delivery: Udp and TCP: (Chapter 23)Giri Tharan RockNessuna valutazione finora
- Internet BasicsDocumento23 pagineInternet BasicsNurhayati Fakhruzza Binti Sulaiman100% (1)
- Course File BceDocumento20 pagineCourse File Bceyatendra kashyapNessuna valutazione finora
- Admission Procedure Letter 20211204001701Documento2 pagineAdmission Procedure Letter 20211204001701Magah maxwellNessuna valutazione finora
- Export Crystal Report To PDF in VB Net 2008Documento2 pagineExport Crystal Report To PDF in VB Net 2008AmandaNessuna valutazione finora
- The Study of Impact On Digital Marketing On Amazo1Documento8 pagineThe Study of Impact On Digital Marketing On Amazo1Saurabh VihwakarmaNessuna valutazione finora
- HTTPDocumento13 pagineHTTPXavi IndrewNessuna valutazione finora
- The Marketing Mix - Promotion & PlaceDocumento20 pagineThe Marketing Mix - Promotion & PlaceKalsoom SoniNessuna valutazione finora
- Skyworldtravel - Uk Web Development Proposal 1.1Documento10 pagineSkyworldtravel - Uk Web Development Proposal 1.1taimoorNessuna valutazione finora
- TPACK Creating Assignment Template: Content Knowle Dge Subject Grade Level Learning ObjectiveDocumento4 pagineTPACK Creating Assignment Template: Content Knowle Dge Subject Grade Level Learning Objectiveapi-470968774Nessuna valutazione finora
- Quality EducationDocumento3 pagineQuality EducationKITNessuna valutazione finora
- Continuous Integration With Jenkins - TutorialDocumento9 pagineContinuous Integration With Jenkins - TutorialNinjaDragonXNessuna valutazione finora
- 6.2.3.8 Lab - Configuring Multiarea OSPFv2 FinalDocumento13 pagine6.2.3.8 Lab - Configuring Multiarea OSPFv2 FinalJoseph Ryan WolfNessuna valutazione finora